Apache MapReduce
Apache MapReduce is a framework developed to write applications that process large amounts of data across large clusters of common hardware. It ensures reliability, parallelism, fault tolerance, and facilitates data locality (the ability for a program to run where the data is stored).
MapReduce was developed from a technology disclosed by Google, created by Jeffrey Dean and Sanjay Ghemawat, to optimize the indexing and cataloging of web data.
Despite Hadoop's evolution from its initial version, the high-level flow of the MapReduce processor has remained constant.
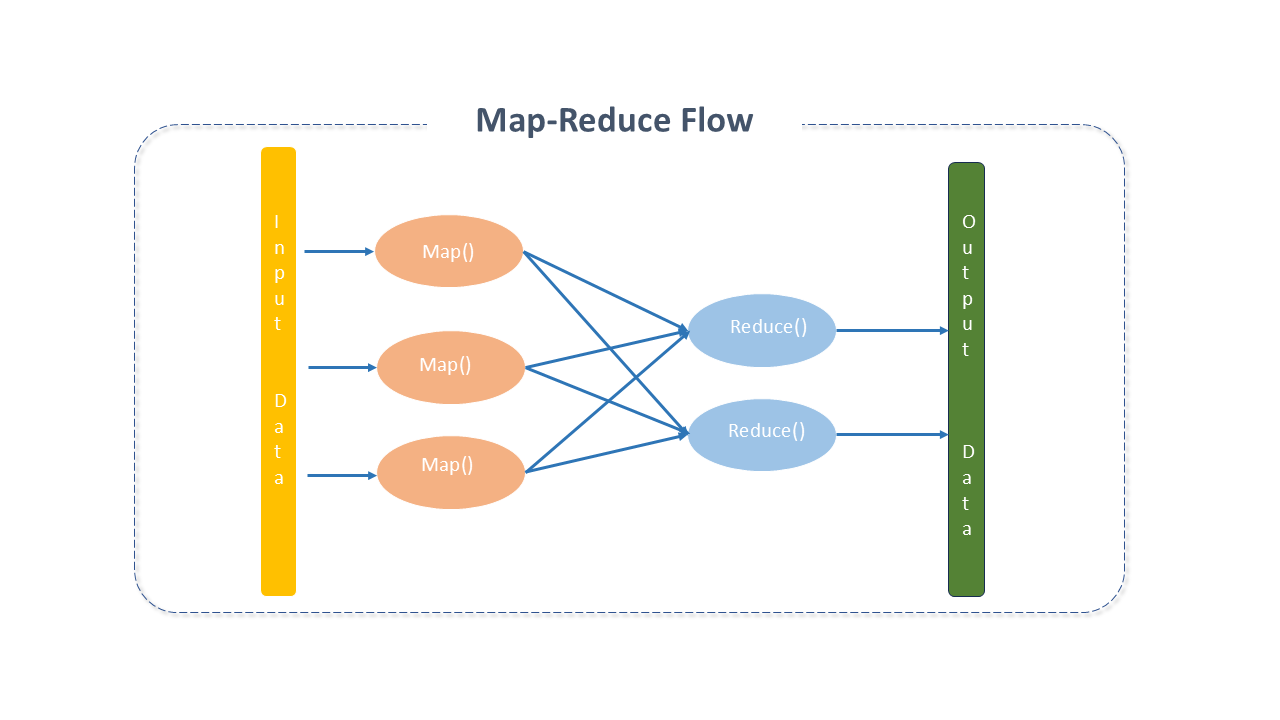
Apache MapReduce Architecture
MapReduce organizes processing into two main processes — Map and Reduce — with several smaller tasks integrated into the process flow. A typical MapReduce job divides the input dataset into independent parts processed in parallel by Map tasks. The results are then sorted and passed to the Reduce tasks.
Input and output of the job are usually stored in a file system. Typically, the compute and storage nodes are the same, allowing for efficient scheduling of tasks at the nodes where the data is stored, resulting in higher cluster bandwidth.
The MapReduce framework includes a single Resource Manager master, one NodeManager worker per cluster node, and one MRAppMaster per application.
Applications specify input and output locations and provide map and reduce functions through appropriate interfaces or abstract classes. These and other job parameters comprise the job configuration.
The client submits the job (jar/executable, etc.) and configuration to the ResourceManager, which manages distribution to workers, task scheduling, and monitoring, providing status and diagnostics.
Inputs and Outputs
MapReduce operates exclusively on key-value pairs, treating the input as a set of pairs and producing a set of pairs as output. Key and value classes must be serializable, implementing the WritableComparable interface to facilitate sorting.
Process Components
-
InputFileFormat: The MapReduce process starts by reading the file stored in the HDFS, which can be of any type, and its processing is controlled by the Inputformat.
-
RecordReader and Input Split: The file is divided into "parts" known as input splits. Their sizes are controlled by the mapred.max.split.size and mapred.min.split.size parameters. By default, the size of the input split is the same as the block size and cannot be changed, except in very specific cases. For non-splittable format files like .gzip, the input split will be equal to the file size.
The RecordReader function is responsible for reading data from the input split stored in HDFS. The default format is TextInputFileFormat and the RecordReader delimiter is /n, meaning only one line will be treated as a record by the RecordReader. Sometimes the behavior of the RecordReader can be customized by creating a custom RecordReader.
-
Mapper: The Mapper class is responsible for processing the input split. The RecordReader function passes each read record to the Map function of the Mapper. The Mapper contains the setup and cleanup methods.
- The setup is executed before the Mapper processing, so any initialization operations must be performed within it.
- The cleanup method is executed once all records in the input split are processed, so any cleanup operations must be performed within it.
The Mapper processes the records and emits the output using the object context, which enables the Mapper and Reducer to interact with other Hadoop systems, allowing communication between Mapper, Combiner, and Reducer.
- The output pairs do not need to be of the same type as the input pairs.
- Applications can use the counter to report their statistics.
- The number of maps is usually determined by the total input size (total number of output file blocks).
-
Partitioner: The Partitioner assigns a partition number to the record emitted by the Mapper so that records with the same key always get the same partition number, ensuring that records with the same key always go to the same Reducer.
-
Shuffling and Sorting: The process of transferring data from the Mapper to the Reducer is known as shuffling. The Reducer starts threads to read data from the Mapper machine and reads all partitions belonging to it for processing using the HTTP protocol.
-
Reducer: The number of Reducers that Hadoop can have depends on the number of Map outputs and several other parameters, and this can be controlled.
The Reducer contains reduce() which is executed for each unique key emitted by the Mapper.-
The total number of reduces is usually calculated as:
(0.95 or 1.75) * (number of nodes * max number of containers per node)
noteWith 0.95, all reduces can start immediately and begin transferring map outputs as they finish. With 1.75, the faster nodes will finish their "first round" of reduces and launch a second wave, doing a better job of load balancing.
-
-
Combiner: Also called mini reducer or localized reducer, it is a process executed on the Mapper machines that takes the intermediate key emitted by the Mapper and applies the user-defined Combiner reduce function on the same machine.
For each Mapper there is a Combiner available on the Mapper machines. The Combiner significantly reduces the volume of data shuffling between Mapper and Reducer and thus helps in performance improvement. However, there is no guarantee they will be executed. -
Output format: Translates the final key/value pair from the Reduce function and writes it to a file in HDFS via the record writer. By default, the output key values are separated by tab and the records are separated by a newline character. This can be modified by the user.
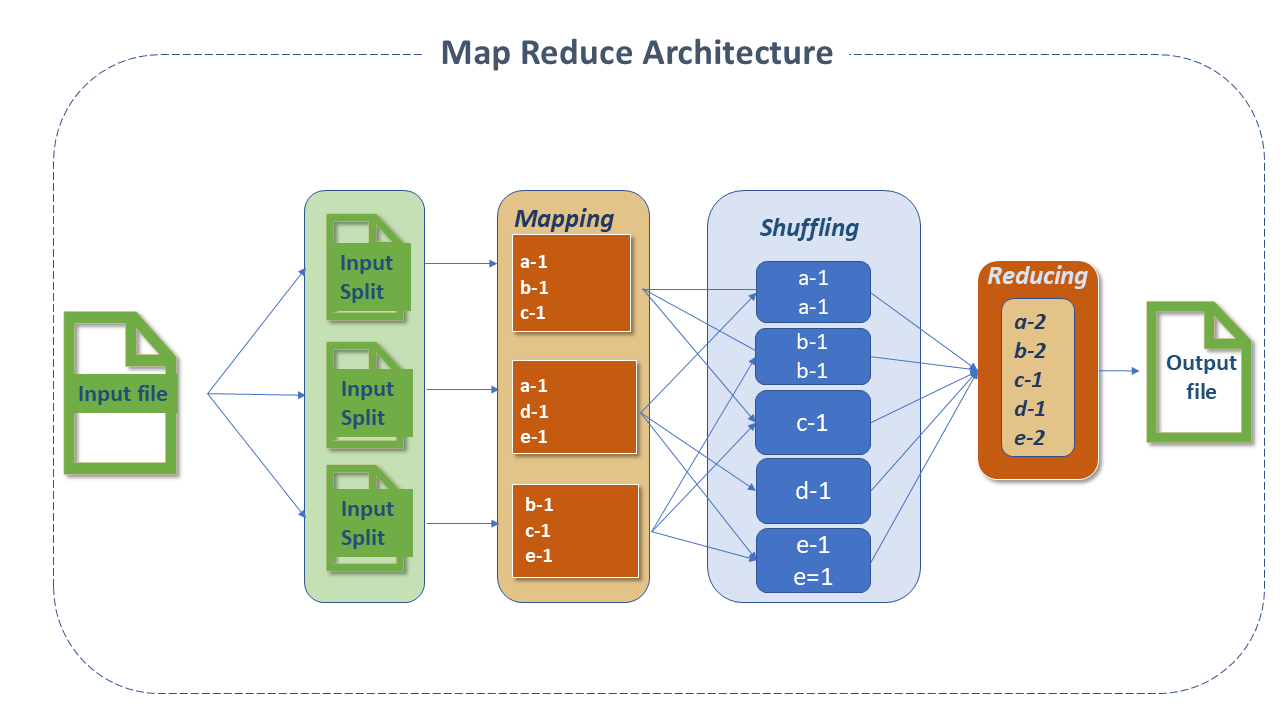
Apache MapReduce Patterns
There are template solutions developed by people who solved specific problems and that can be reused:
-
"Summarization" patterns:
- Word Count.
- Minimum and maximum
-
"Filtering" patterns:
- Reduce "top-k" algorithm: A popular MapReduce algorithm where the mappers are responsible for emitting the top-k records at their level, and then the reducer filters the top-k records from all received from the mappers.
-
"Join" patterns:
-
Reduce side join: Process where the "join" operation is performed in the "reducer" phase. Mapper reads the input data which is combined based on a common column or join key.
-
Composite Join:
- Sorting and partitioning
-
Best Practices for Apache MapReduce
-
Hardware Configuration:
- Hardware configuration is very important for performance. A system with more memory will always perform better.
- Bandwidth is also critical since MapReduce jobs may require data shuffling from one machine to another.
-
Operating System Tuning:
-
Transparent Huge Pages (THP): Machines used in Hadoop should have THP disabled. THP does not work well in a Hadoop cluster and causes high CPU costs. It is recommended to disable it on each job node.
-
Avoid unnecessary memory swapping: In Hadoop, swapping can affect job performance and should be avoided unless absolutely necessary. The swappiness setting can be set to 0 (zero).
-
CPU Configuration: In most Operating Systems, the CPU is configured to save power and is not optimized for systems like Hadoop. By default, the scaling governor is set to power-saving mode and needs to be changed with the following command:
Terminal inputcpufreq-set -r -g
-
-
Network Adjustments: Shuffling consumes significant Hadoop time as it requires frequent master and worker connections. The net.core.somax.conn should be set to a higher value, which can be done by adding or editing
/etc/sysctl.confwith thenet.core.somaxconn=1024. entry. -
File System Choice:
- The Linux distribution comes with a default file system designed for heavy I/O loads, which can significantly impact Hadoop performance. The latest Linux distribution comes with
EXT4as the default file system, which performs better thanEXT3. - The file system records the last access time for each read operation on the file, causing a disk write for each read. This setting can be disabled by adding a
noatimeattribute to thefile system mountoption. Some use cases have observed a performance improvement of over 20% withnoatime.
- The Linux distribution comes with a default file system designed for heavy I/O loads, which can significantly impact Hadoop performance. The latest Linux distribution comes with
-
Optimizations:
-
Combiner: Shuffling data over the network can be expensive as transferring more data always takes more processing time.
Reduce cannot be used in all use cases, but in most cases, we can use the Combiner, which reduces the size of the data transferred over the network during shuffling as it acts as a mini reduce and is executed on the Mapper machines. -
Map output compression: The Mapper processes the output and stores it on the local disk.
When generating a large amount of output, this intermediate result can be compressed with the LZO function, reducing disk I/O during shuffling.
This is done by setting Isto é feito definindo omapred.compress.mapoutputtotrue. -
Record filtering: Filtering records on the Mapper side results in fewer data written to the local disk and faster subsequent stages (with less data to operate on).
-
Avoiding many small files: Very small files can take a long time to execute.
HDFS stores these files as a separate block, which can overload file processing with the initialization of many Mappers.
It is good practice to compact small files into a single large file and then run MapReduce on it.
In some cases, this can result in a 100% performance optimization. -
Avoiding non-splittable file formats: Non-splittable formats (e.g., gzip) are processed all at once.
If they are very small files, it will take a lot of time because for each file, a Mapper will be started.
The best practice is to use a splittable format like Text, AVRO, ORC, etc.
-
-
Runtime Configurations
-
Java Memory: Map and Reduce are JVM processes that, therefore, use JVM memory for execution.
The memory size can be adjusted in themapred.child.java.optsproperty. -
Map spill memory: The output records of the Mapper are stored in a circular buffer whose default size is 100MB.
When the output exceeds 70% of this size, the data will be written to disk.
To increase the buffer memory, use theio.sort.mbproperty. -
Map adjustment: The number of Mappers is controlled by the mapred.min.split.size.
If there are many tasks running one after another, it is ideal to setmapred.job.reuse.jvm.num.tasks to -1.
warningThis should be used very carefully as in the case of long-running tasks, JVM overhead will not increase performance, but rather the opposite.
-
-
File System Optimization:
-
Mount option: There are some efficient mount options for Hadoop clusters, such as the noatime configured for
Ext4andXFS. -
HDFS block size: Block size is important in NameNode performance and job execution.
The NameNode maintains metadata for each block it stores in the DataNode and therefore occupies a lot of memory with block sizes much smaller than recommended.
The recommended value for dfs.blocksize should be between134,217,728and1,073,741,824. -
Short circuit read: The HDFS read operation goes through the DataNode, which, after the client's request, sends the file data over the TCP socket to the client.
In short circuit read, the client reads the file directly, thus bypassing the DataNode.
This only happens if the client is on the same node as the data. -
Stale Datanode: The DataNode sends a heartbeat to the NameNode at regular intervals to indicate it is active.
To avoid sending read and write requests to inactive DataNodes, adding the following properties in hdfs-site.xml is efficient:Terminal input_dfs.namenode.avoid.read.stale.datanode=true_Terminal input_dfs.namenode.avoid.write.stale.datanode=true_
-
Apache MapReduce Project Details
Although Hadoop is implemented in Java, MapReduce applications can use any language that supports Hadoop Streaming or Hadoop Pipes.
Sources: