Apache Iceberg
Table Formats
Table Formats are table structures used to organize and manage complex data, allowing it to be viewed and interacted with as a single, understandable "table" accessible to multiple users and tools simultaneously.
Table Formats add a table-like abstraction layer over native file formats, serving as a metadata layer and providing the primitives needed for computing engines to interact with stored data more efficiently, ensuring enhanced ACID compliance, the ability to log transactional data efficiently, scalability, and the ability to update or delete records.
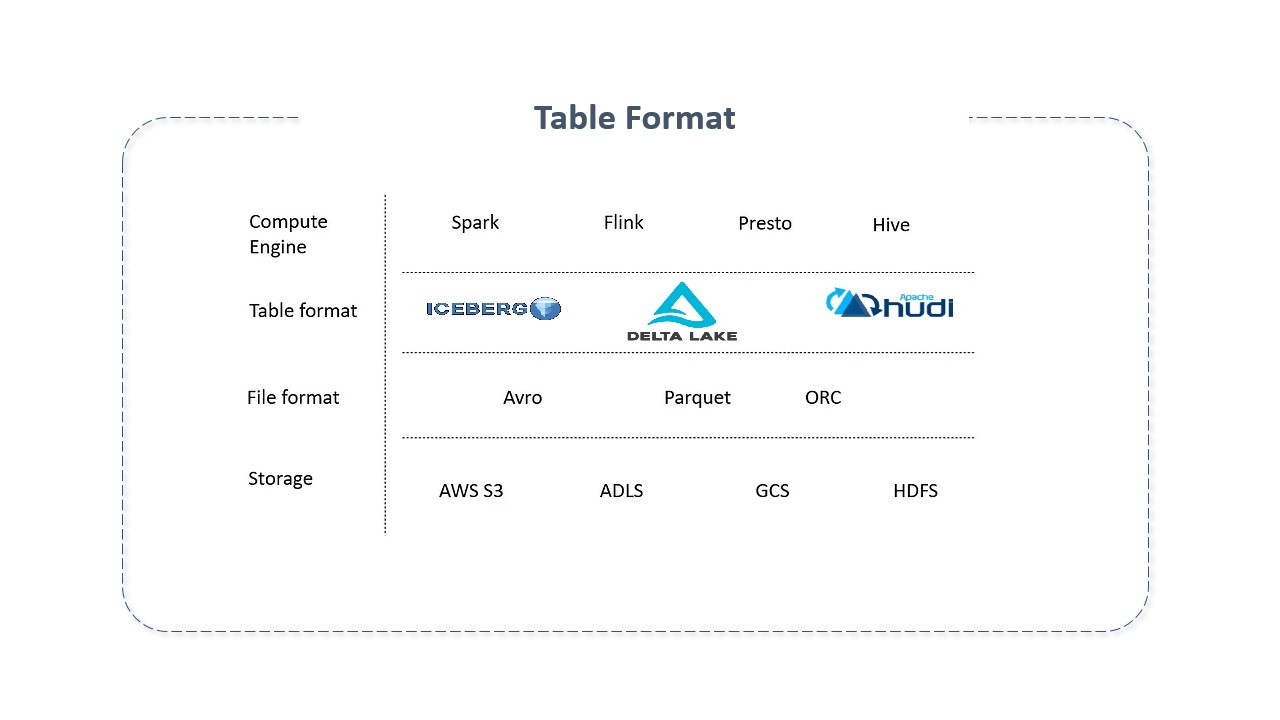
Table formats evolved in response to a critical need: to combine the data management advantages of warehouses (OLAP databases) with the greater scalability and cost-effectiveness of data lakes. In essence, they combine the versatility of data lakes for handling raw and semi-structured data with the capability to process transactional workloads.
In simple terms, table formats are a way to organize data files. They attempt to bring database features to the data lake. Their primary goal is to provide the table abstraction to people and tools, allowing them to efficiently interact with their underlying data.
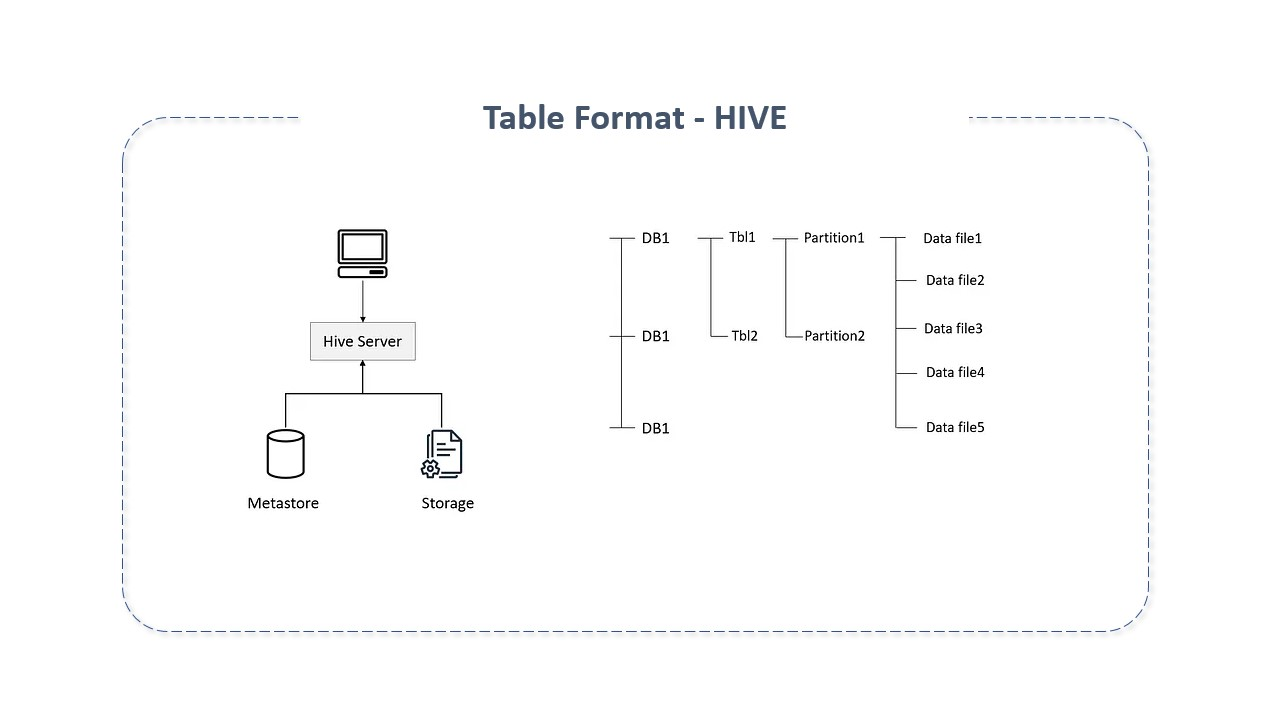
Although it wasn't the name used at the time, table formats have existed since System R, Multics and Oracle first implemented Edgar Codd's relational model. When we talk about a group of files being a collection, we're talking about table formats. When a file is viewed as a table, the directory is viewed as a table, which facilitates tracking it and its files. This is done with the help of catalog systems. Under it, files are written in versions, and the latest ones corresponding to a table are tracked with the help of the metastore. The metastore is accessed to know the current state of the table and which files are related.
Apache Hive is one of the oldest table formats used. However, since Hive was written in the pre-cloud era, it didn't anticipate object storage, impacting its performance as Hive's metadata tables grow rapidly. To address these issues, new table formats were created.
Apache Iceberg
Apache Iceberg is an open-source table format for large analytic datasets, with a specification that ensures compatibility between languages and implementations. It adds tables to computing engines like Spark, Trino, Flink, Hive, etc., using a high-performance table format that works just like a SQL table.
Apache Iceberg allows cohesive real-time access to historical data, ensuring data integrity and consistency. Its main innovation lies in its ability to support read, write, update, and delete operations on data without rewriting entire datasets.
Apache Iceberg quickly gained adoption among large companies like Apple, Netflix, Amazon, etc. Its completely open nature, engaging multiple companies and the community, makes it ideal for data lake architecture.
Apache Iceberg Features
Apache Iceberg was developed in 2017 by Netflix, donated to the Apache Software Foundation in November 2018. It became a top-level project in 2020. It is used by numerous companies including Airbnb, Apple, LinkedIn, Adobe, etc. It was specifically created to address problems and challenges related to file-formatted tables in data lakes, such as data and schema evolution and concurrent writes, consistently, in parallel. It introduces new features that allow multiple applications (like Dremio) to work together on the same data transactionally, consistently, and define additional information about the state of datasets as they evolve and change over time.
Apache Iceberg adds tables to computing engines like Spark, Trino, Flink and Hive using a high-performance table format that works like a SQL table.
Its main features include:
-
Schema Evolution: Supports adding, deleting, updating, or renaming without side effects;
-
Hidden Partitionin: Prevents user errors from causing incorrect results silently or extremely slow queries;
-
Partition Layout Evolution: Allows updating the layout of a table as data volume or query patterns change.
Architecture of Apache Iceberg
In practice, Apache Iceberg is a table format specification and a set of APIs and libraries that enable engines to interact with tables following this specification.
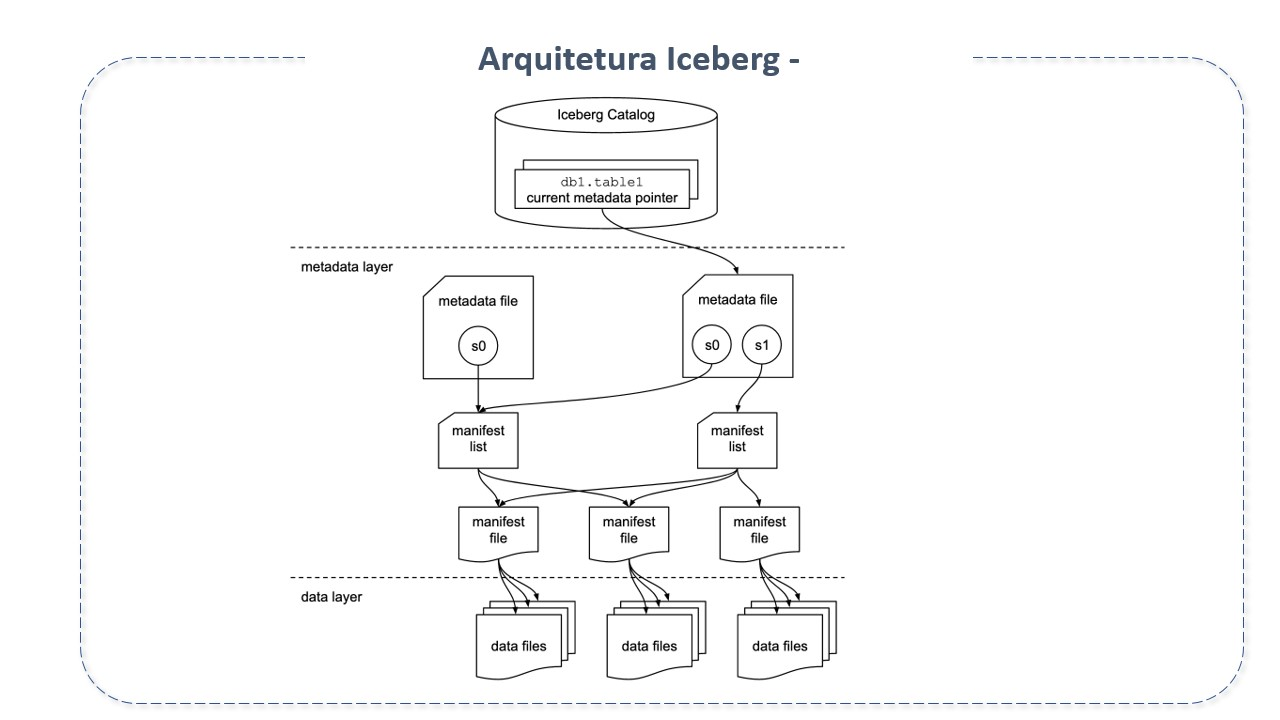
Its main components are:
-
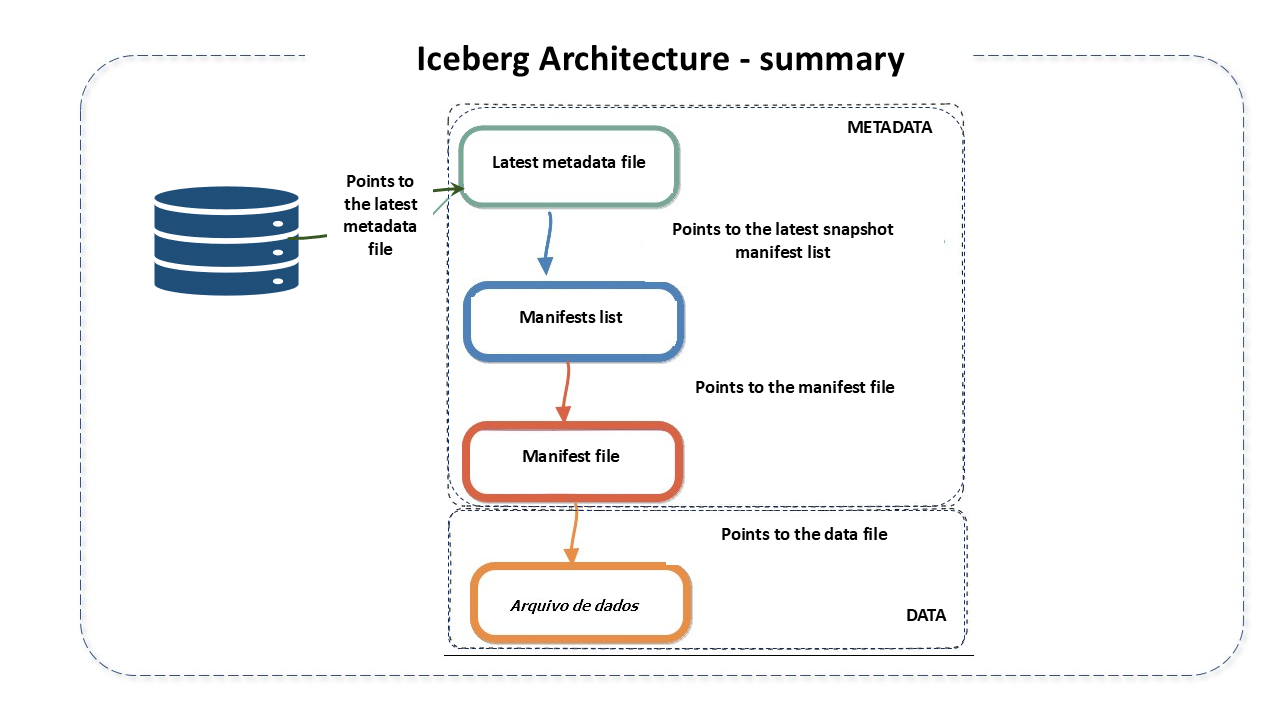
Iceberg Catalog: The catalog is a central repository where the reference to each table's metadata file is stored. Its main goal is to support atomic operations to update pointers. For this, it keeps the current location of the metadata pointer (within the catalog there is a reference or pointer to the current metadata file of each table. The pointer value is the location of the metadata file).
-
Metadata Layer: Metadata is tracked in three files: metadata files, manifest lists, and manifest files.
-
Metadata files: .json file containing information about the table's metadata at a given point in time. It stores the state of the tables. It includes details about the table schema, partition information, current snapshot ID (current-snapshot_id), path to the manifest list, etc. When the state of the tables changes, a new metadata file is created and replaces the old one with an atomic swap. It has the following subsections:
- Snapshot: : A complete list of all files in the snapshot table. It represents the state of a table at a given moment and is used to access the complete set of data files in the table. It includes information about the table schema, partition specifications, and the location of the manifest list;
- Schemas: All table schemas altered are tracked by the "schema matrix";
- Partition Specifications: tracks information about the partition;
- Sort Orders.
-
Manifest List (manifest list): Avro file that contains all manifests and their metrics. They store metadata about the manifests that make up a snapshot, including partition statistics and data file counts. These statistics are used to avoid reading unnecessary manifests for the operation. Acts as a link between the manifest and the snapshot.
-
Manifest Files: Keep track of all data files, along with details and statistics like their formats, location, and metrics.
-
- Data Layer
- Data File: The actual physical file. Where the data actually resides.
Apache Iceberg was built for huge tables that can be read without a distributed SQL engine. Each table can contain tens of petabytes of data.
Apache Iceberg Resources
-
User Experience Resources:
Apache Iceberg improves the user experience in that:
-
With schema evolution support, it supports additions, deletions, updates, renaming, and reordering of columns in a table without needing to rewrite the table. This makes schema evolution side-effect-free, assigning a unique ID to each newly created column and automatically adding it to the column metadata. It also ensures the uniqueness of each column;
-
With hidden partitioning, it ensures users no longer need to know the structural layout of files before running queries. This avoids user errors causing silently incorrect results or extremely slow queries. Iceberg evolves the table's schema and partition as data scales;
-
With time travel the version control feature, Iceberg ensures that any data changes are saved for future reference, whether adding, deleting, or updating data. Thus, any issue with data versioning can be easily reverted to an older, stable version, ensuring data is not lost and can be compared over time.
-
-
Reliability:
-
Snapshot isolation ensures that any read of the dataset sees a consistent "snapshot." In essence, it reads the last confirmed value present at the time of reading. This avoids conflicts. After commits, the record is updated, and a new snapshot is created, reflecting the most recent update;
-
With atomic commits, it ensures that data remains consistent across all queries. To avoid partial changes, any update must be completed on the dataset, or no changes will be saved. This ensures that only correct data is returned, preventing users from seeing incomplete or inconsistent data;
-
Reads are reliable because each transaction (update, addition, deletion) creates a new snapshot. Thus, readers can use the various latest versions of each update to create a reliable query for the table;
-
Operations are at the file level, unlike traditional catalogs that track records by position or name, which requires reading directories and partitions before updating a single record. In Apache Iceberg, it is possible to directly target a single record and any record update without any folder change. This is because the records are stored in their metadata.
-
-
Reliability:
-
Each file that belongs to a table has metadata stored for any transaction that occurred, along with extra statistics. This allows users to locate only the files that correspond to the query they want at the time;
-
Iceberg uses two levels of metadata to track files in a snapshot - manifest files and the manifest list. The first level contains the data files, along with their partition data and column-level statistics. The second stores the list of manifest snapshots with a range of values for each partition;
-
For fast scan planning, Iceberg uses minimum and maximum values from the partition in the manifest list to filter the manifests. Subsequently, it reads all the returned manifests to get the data file. Thus, it is possible to plan without reading all the manifest files, using the manifest list to restrict the number of manifest files needed for reading.
With this, it is possible to achieve efficient and economical queries on files.
-
Best Practices for Using Apache Iceberg
Apache Iceberg is a powerful tool for managing large analytical datasets. To maximize its efficiency and effectiveness, here are some best practices:
-
Data Structure and Schemas: Keep data schemas simple and evolutionary. Utilize Iceberg's schema evolution functionality to maintain compatibility and minimize disruptions;
-
Efficient Partitioning: Use logical partitioning to organize data in a way that optimizes the most common queries. Iceberg's hidden partitioning can help avoid performance issues;
-
Metadata Management: Keep metadata clean and up-to-date. This includes removing old snapshots and unused manifest files to avoid overloading the catalog;
-
Testing and Validation: Implement rigorous testing when evolving schemas or modifying tables to ensure data integrity;
-
Monitoring and Optimization: Regularly monitor query performance and optimize tables as needed. This can include adjusting partitioning or modifying indexes;
-
Documentation: Maintain clear documentation of table structures, schemas, and any associated business logic to facilitate maintenance and collaboration;
-
Security and Access Control: Implement appropriate access controls and security practices to protect data;
-
Resource Usage and Cost: Be aware of resource usage and associated costs, especially in cloud environments. Optimize storage and compute usage to maintain cost efficiency;
-
Updates and Compatibility: Stay updated with the latest versions of Apache Iceberg to take advantage of improvements and security fixes.
Using Apache Iceberg according to these practices can significantly improve data management and operational efficiency.
When to Use Apache Iceberg
-
Large Datasets: When dealing with petabytes of data in huge tables;
-
Modern Data Lakes: For modern data lake architectures that require robust data and schema management;
-
Scalability and Reliability: When scalability and reliability are critical for data operations and analysis;
-
ACID Transactions in Data Lakes: To support ACID transactions in data lakes, ensuring data integrity;
-
Schema Evolution: When there is a need to evolve data schemas without interruption or data loss;
-
Efficient Updates and Deletions: If you need to perform efficient updates and deletions in large datasets;
-
Working with Multiple Data Formats: If working with various data formats and needing a uniform abstraction layer;
-
Concurrent Reads and Writes: When needing support for concurrent reads and writes without locking;
-
Compliance and Data Governance: To meet strict compliance and data governance requirements;
-
Integration with Analytics Platforms: If you want to integrate with analytics platforms like Spark, Trino, Flink, and others;
-
Snapshot and Data Traveling: When snapshot and data traveling functionality is needed for auditing or rollback;
-
Improving Read Performance: To improve read performance through indexing and file optimizations.
These items highlight ideal scenarios for implementing Apache Iceberg, maximizing its features for efficient data lake management.
When Not to Use Apache Iceberg
Apache Iceberg is not the right tool for:
-
Small Data Volumes: If the data universe is small and does not require a data lake, Apache Iceberg will not bring benefits.
-
Real-Time Ingestion: Apache Iceberg does not support real-time data ingestion as it uses batch processing.
-
Centralized Structure: If the goal is not to use a distributed computing structure, Apache Iceberg is not ideal, as it is designed to use a distributed computing structure to process data.
Development Project Details
Apache Iceberg is primarily developed in Java. Therefore, a good understanding of Java is essential to effectively contribute to the project or customize it. This also implies the need to maintain standard Java coding practices, such as efficient exception handling and using common Java libraries for I/O operations and data manipulation.