Apache Sqoop
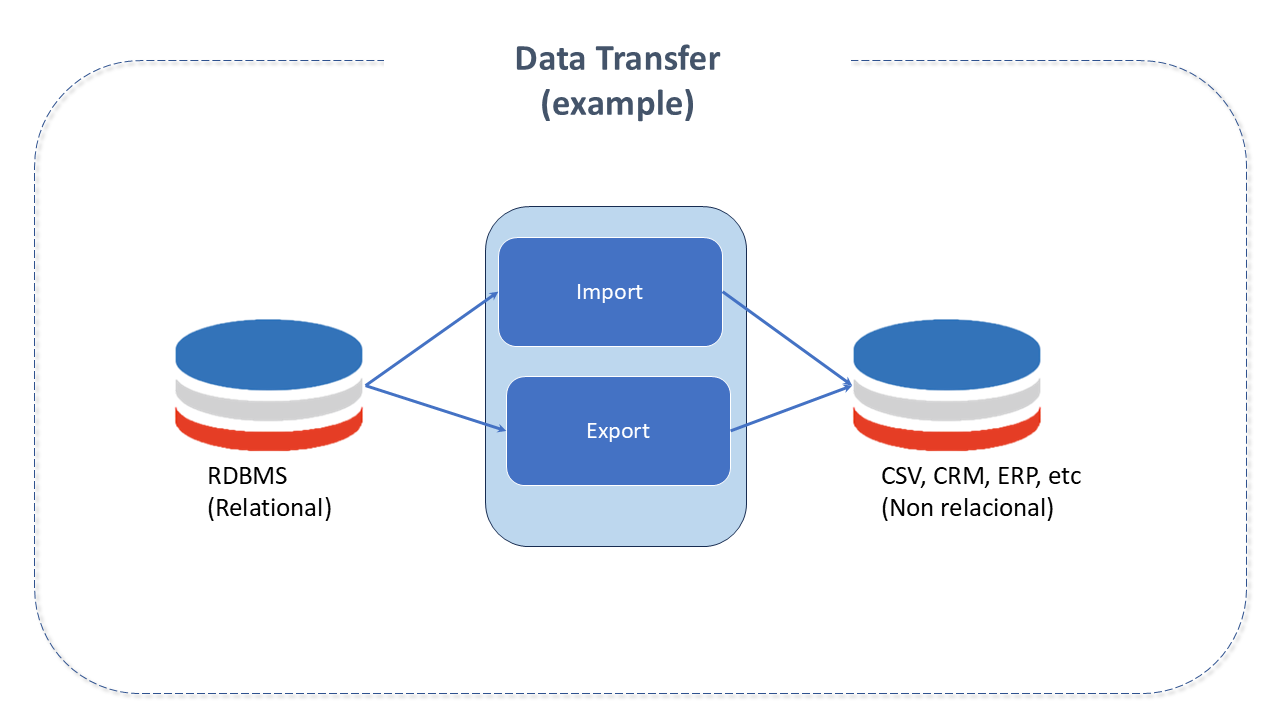
Data Transfer
Before being processed by a machine learning system, data needs to be imported. Likewise, they need to be exported to other applications before being used externally.
A data transfer engine enables the movement "to" or "from" different storage devices. The actual import work is done by processing mechanisms, which run the import jobs and then persist the imported data into the storage device.
Unlike other data processing systems, where the input data conforms to a schema and is almost always structured, the source data for a machine learning system can include a mix of sources and formats.
Features of Apache Sqoop
Apache Sqoop is a command-line tool designed to facilitate bulk data transfer between Apache Hadoop and structured datastores such as relational databases (RDBMS).
The integration of these environments is Sqoop's role, and its main purpose is to import/export data between the relational environment and Hadoop.
Data stored in external databases cannot be directly accessed by MapReduce applications. This approach would put the system at the Cluster nodes at high risk of stress.
Sqoop simplifies loading large amounts of data from RDBMS to Hadoop, addressing this issue.
Most of the process is automated by Sqoop, which relies on the database to specify the data import structure. It imports and exports data using the MapReduce architecture, which provides a parallel and fault-tolerant approach.
Sqoop graduated from the incubator in March 2012, becoming a top-level project at Apache.
Some of its features include:
- Reads tables row by row and writes the file to HDFS.
- Imports data and metadata from relational databases directly into Hive.
- Provides parallel and fault-tolerant processing by using MapReduce in import/export activities.
- Uses the YARN framework for data import and export, making it fault-tolerant with parallelism.
- Allows selecting the range of columns to be imported.
- Allows specifying delimiters and file formats.
- Parallelizes database connections by executing SQL commands like SELECT (import) and Insert/Update (export).
- The default format for imported files in HDFS is CSV.
- Data type conversion:
- Imports individual tables or entire databases into HDFS files.
- A generic JDBC connector is provided to connect to any database supporting the JDBC standard. It has several plugins for connection to PostgreSQL, Oracle, Teradata, Netezza, Vertica, DB2, SQL Server, and MySQL.
- Creates Java classes that allow users to interact with the imported data.
Architecture of Apache Sqoop
Sqoop provides a command-line interface for end-users and can also be accessed via the Java API.
Data migration between Sqoop Hadoop and an external storage system is possible through Sqoop connectors, which enable it to use various well-known relational databases such as MySQL, PostgreSQL, Oracle, etc. Each of these connections can communicate with the DBMS to which it is linked.
During the execution of Sqoop, the transferred dataset is divided into several parts, and a map-only job is created with distinct mappers responsible for loading each partition. Sqoop uses the database information to deduce data types, handling each record securely.
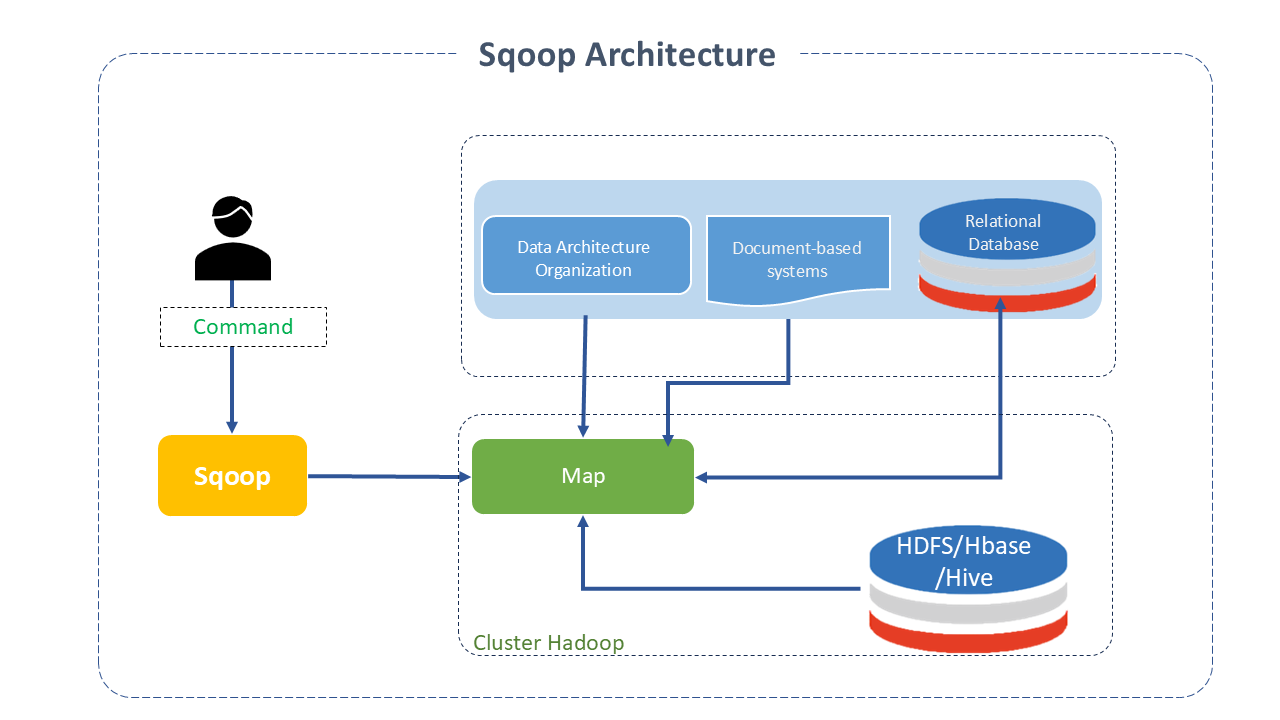
Sqoop is therefore composed of two main operations:
-
Sqoop Imports
This procedure is performed with the Sqoop import command. Each record loaded into the Hadoop DBMS as a single record is stored in text files as part of the Hadoop structure. When importing data, it is also possible to load and split Hive. Sqoop also allows incremental data import.
-
Sqoop Exports
Facilitates the task with the export command, which performs the operation in the opposite direction. Data is transferred from the Hadoop file system to the relational DBMS. Before completing the operation, the exported data is transformed into records.
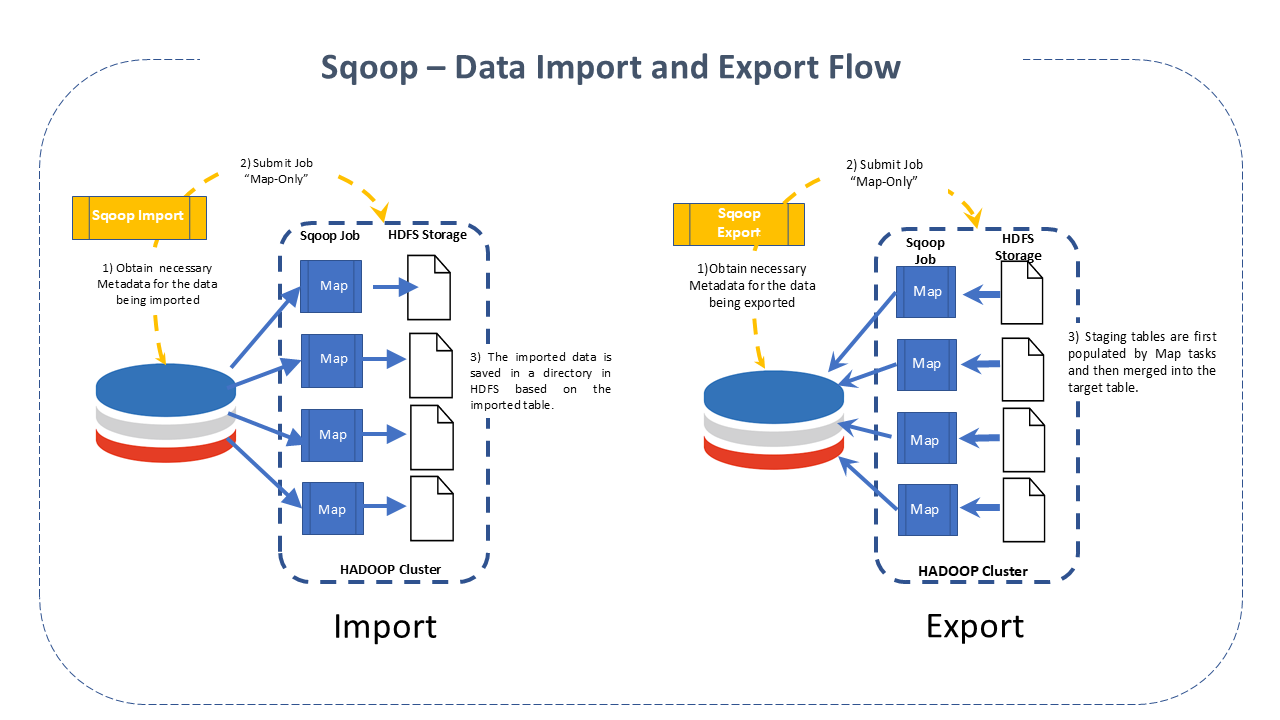 Sqoop Flow
Sqoop Flow -
Apache Sqoop Resources
- It is possible to import the results of an SQL query into HDFS with Sqoop.
- Offers connectors for most RDBMS, such as MySQL, Microsoft SQL Server, PostgreSQL, etc.
- Supports Kerberos network authentication protocol, allowing nodes to authenticate users while communicating securely over an insecure network.
- With a single command, Sqoop can reload the entire table or specific sections of the table.
When to use Apache Sqoop
- Processing OLTP databases using a Big Data tool.
- Integration of OLTP with Hadoop.
- Data ingestion into Hadoop.
How it works
The command entered by the user is parsed by Sqoop and executes the Hadoop Map only to import or export data, as the Reduce phase is only necessary when aggregations are required.
Sqoop parses the arguments entered on the command line and prepares the Map task. A map job that runs several mappers depends on the number defined by the user on the command line.
During an import, each map task receives a portion of the data to be imported based on the command line.
Sqoop distributes the data evenly among the mappers to ensure high performance.
Then each mapper creates a connection with the JDBC database.
Best Practices for Apache Sqoop
-
Import to binary format: Although imports to CSV file format are easy to test, some issues may arise when text stored in the database uses special characters. Importing to a binary format like Avro will avoid this problem and can speed up processing in Hadoop.
-
Control parallelism: Sqoop works in the MapReduce programming model. It imports and exports data from most relational databases in parallel. The number of Map tasks per job determines this parallelism. Controlling parallelism allows dealing with database load and performance. There are two ways to explore parallelism in Sqoop:
-
Changing the number of mappers: Typical Sqoop jobs start with four mappers by default. To optimize performance, it is recommended to increase the Map tasks (parallel processes) to an integer value of 8 or 16. This can show a performance increase in some databases. Using -m or --num--mappers you can define the degree of parallelism in Sqoop.
Terminal inputSqoop import \
--connect jdbc:postgresql://postgresql.example.com/Sqoop \
--username Sqoop \
--password Sqoop \
--table _table_name_ \
--num-mappers 10 -
Splitting by query: When performing parallel imports, Sqoop needs a criterion to split the workload. It uses a split column to divide the workload. By default, it will identify the primary key column (if present) in a table and use it as the split column. The low and high values for the split column are retrieved from the database, and the map tasks operate on uniformly sized components of the total range. The split-by parameter divides the data in the column evenly based on the number of specified mappers. The split by syntax is:
Terminal inputSqoop import \
--connect jdbc:postgresql://postgresql.example.com/_database_name_ \
--username _username_ \
--password _password_ \
--table _table_name_ \
--split-by _id_field_warningThe number of map tasks must be less than the maximum number of possible parallel database connections. The increase in the degree of parallelism should be less than that available within your MapReduce Cluster.
-
-
Control data transfer process: A popular method of improving performance is managing the path where we import and export data. Below we summarize some paths. To see the existing arguments, check Tables "Table 3" and "Table 29" -> import/export control arguments, in the User Guide
-
Batch: Which means that SQL statements can be batched when exporting data.
noteThe JDBC interface provides an API for batching in a prepared statement with multiple sets of values. This API is present in all JDBC drivers because it is required by the JDBC interface.
Batch is disabled by default in Sqoop. Enable JDBC batching using the batch parameter.
Terminal inputSqoop export \
--connect jdbc:postgresql://postgresql.example.com/_database_name_ \
--username _username_ \
--password _password_ \
--table _table_name_ \
--export-dir /data/_database_name_ \
--batch -
Fetch size: The default number of records that can be imported at once is 1,000. This can be altered by the fetch-size parameter, which is used to specify the number of records that Sqoop can import at once.
Terminal input--connect jdbc:postgresql://postgresql.example.com/_database_name_ \
--username _username_ \
--password _password_ \
--table _table_name_ \
--fetch-size=nwhere n represents the number of entries Sqoop should fetch at a time.
Based on available memory and bandwidth, the value of the fetch-size parameter can be increased relative to the volume of data that needs to be read.
-
Direct Mode:
By default, the Sqoop import process uses JDBC, which provides reasonable support. However, some databases may achieve higher performance by using database-specific utilities optimized to provide the best possible transfer speed, placing less pressure on the database server.By providing the --direct argument, Sqoop is forced to attempt to use the direct import channel. This channel may perform better than using JDBC.
Terminal inputSqoop import \
--connect jdbc:postgresql://postgresql.example.com/_database_name_ \
--username _username_ \
--password _password_ \
--table _table_name_ \
--directwarningThere are several limitations that come with this faster import. Not all databases have native utilities available, and this mode is not available for all databases.
Sqoop has direct support for MySQL and PostgreSQL.
-
Custom Split Queries: As seen, split by distributes data evenly for import. If the column has non-uniform values, the boundary query can be used if we do not get the desired results by only using the split-by argument. Ideally, configure the boundary query parameter as min(id) and max(id) along with the table name.
Terminal inputSqoop import \
--connect jdbc:postgresql://postgresql.example.com/_database_name_ \
--username _username_ \
--password _password_ \
--query 'SELECT... FROM... JOIN ... USING ... WHERE $CONDITIONS' \
--split-by id \
--target-dir _table_name_ \
--boundary-query "select min(id), max(id) from _normalized_table_name_"
-
Apache Sqoop Project Details
Apache Sqoop was developed in JAVA.
Sources:
- https://Sqoop.apache.org/[Apache Sqoop.org,window=read-later]
- https://blogs.apache.org/[Blogs Sqoop.org, window=later]