Delta Lake
Storage Structure
In modern data architectures, the storage layer is the foundation that enables storing large volumes of data in a scalable and cost-effective way. It uses systems like Amazon S3, Azure Data Lake Storage, or HDFS to store files in formats such as Parquet, ORC, or Avro. However, this layer does not enforce structure, version control, schema validation, or transactions — it only stores data.
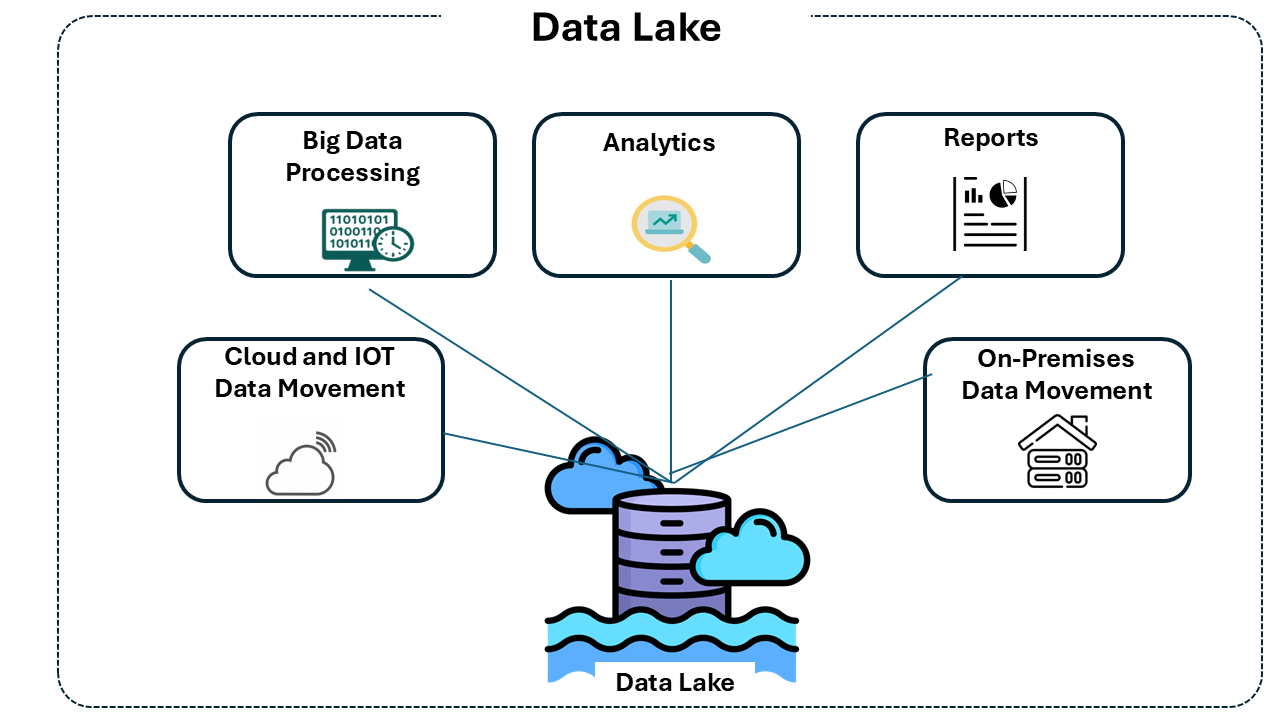
On top of this foundation, the concept of the Data Lake emerged: an architecture designed to store raw data at scale, coming from multiple sources in different formats. The promise of data lakes was to centralize everything in one place — making future analyses easier, integrating varied data, and reducing costs. This made them popular in data science projects and massive ingestion pipelines.
Why Data Lakes Became Popular
Even with technical limitations, data lakes became popular for their flexibility and cost savings. They allow:
- Storing data in its original format, without the need for prior modeling.
- Collecting data in batch and real-time, with virtually unlimited scalability.
- Serving multiple user profiles and tools, supporting ad hoc analysis, machine learning, reports, and dashboards.
- Consolidating and democratizing access to data, breaking down legacy system silos.
Limitations of Data Lakes
Despite the benefits, traditional data lakes do not offer the necessary controls for reliable analytical environments:
- No ACID transactions: multiple writes can cause inconsistency or corruption.
- No version control of data: it's not possible to query or restore a previous table state.
- No schema consistency validation: structural errors may go unnoticed, compromising analyses.
- No performance optimization for queries: small and disorganized files affect performance.
These limitations prevent data lakes from being a reliable base for critical analytical applications. To overcome these issues, a new layer was created — the Delta Lake.
What is Delta Lake
Delta Lake is a transactional layer that operates on top of an existing data lake. It does not replace the data lake — it complements it. By adding ACID transactions, version control, schema management, and integration with tools like Apache Spark, Delta Lake turns raw data lakes into a more reliable, robust, and auditable platform — known as a Lakehouse1.
Delta Lake Features
Delta Lake introduces essential functionalities that fix the deficiencies of traditional data lakes and enable a reliable and scalable data architecture. Key features include:
-
ACID Transactions: ensure atomicity, consistency, isolation, and durability even in distributed environments. Reads and writes are safe and predictable.
-
Version Control and Time Travel: all data changes are automatically versioned, enabling queries on any past state, rollback of changes, and historical audits.
-
Schema Management and Validation: prevents ingestion of data with incorrect structures. Schema can evolve in a controlled way without compromising table integrity.
-
Unification of Batch and Streaming: the same Delta table can receive batch and streaming data, offering consistency across ingestion modes.
-
Optimized Query Performance: includes techniques like small file compaction, column ordering (Z-order), and data skipping to dramatically speed up analytical queries.
-
Spark Ecosystem Integration: allows SQL operations, structured APIs, and real-time processing directly on Delta tables.
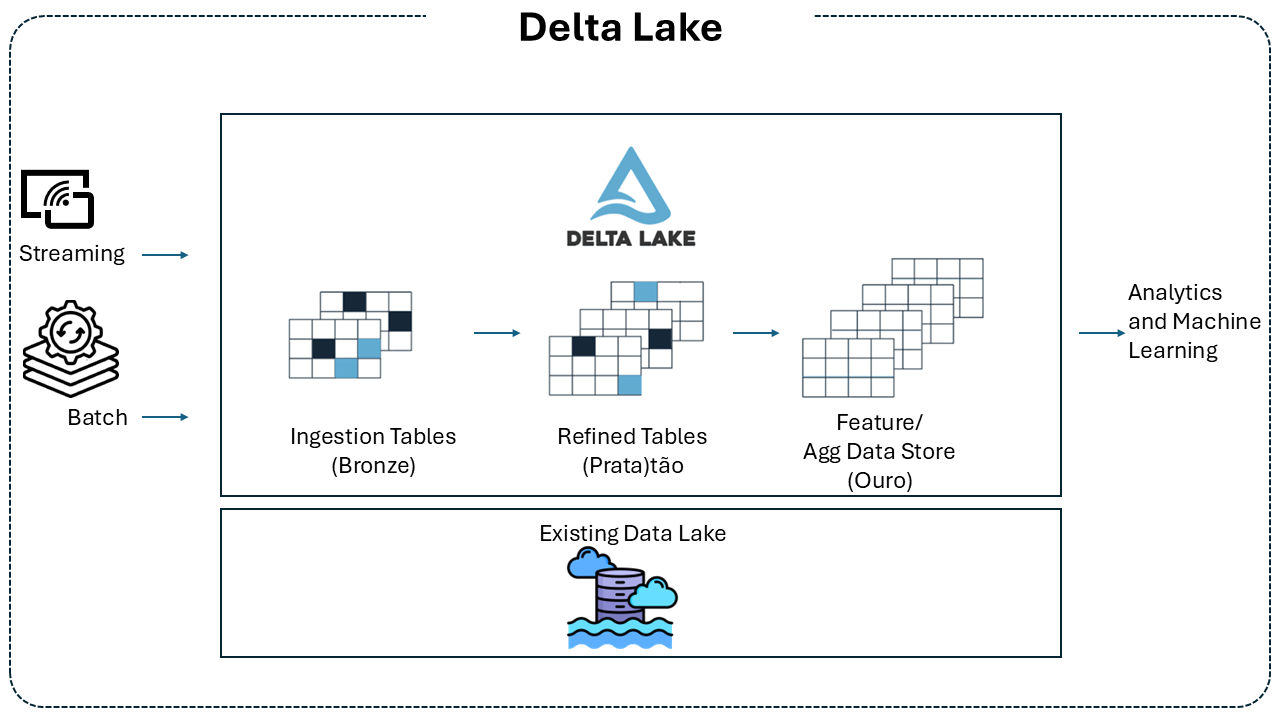
Delta Lake Architecture
Delta Lake’s architecture builds on top of traditional data lakes, introducing a transactional layer that ensures reliability and performance. This layer consists of three key components:
-
Storage Layer: Uses the same repository as the data lake, such as Amazon S3, Azure Data Lake Storage, or HDFS, where data is stored in Parquet format. This physical layer continues to provide scalability and cost-effectiveness.
-
Delta Log: A transaction log that records all table changes. This log enables version control, ensuring every change is tracked and enabling time travel and auditing.
-
Delta Tables: Logical abstractions that unify the stored data and the Delta Log. Through this integration, Delta tables provide ACID transactions, schema management and evolution, and unified batch and streaming ingestion.
How Delta Lake Works
Delta Lake continuously operates on physical storage, managing data changes and ensuring secure and trackable transactions. Its operation is organized into three main areas:
Data Ingestion
Delta Lake supports multiple ingestion modes:
-
Streaming: Integrates with Apache Spark Structured Streaming for continuous ingestion, enabling real-time updates with exactly-once semantics.
-
Batch: Supports large-scale batch ingestion with operations like
MERGE,UPDATE,DELETE, andINSERT, without compromising table integrity.
Query Processing
Delta tables can be queried using:
- SQL: Interactive or analytical queries directly on versioned data.
- High-level APIs: Compatible with Apache Spark APIs (DataFrame, SQL, Structured Streaming).
- Time Travel: By navigating the Delta Log, it’s possible to query the state of data at any point in time.
Data Management
Delta Lake offers mechanisms for continuous optimization:
- Small File Compaction: Operations like
OPTIMIZEreorganize data to improve query performance. - Z-order Sorting: Organizes data in high-selectivity columns, reducing read costs.
- Obsolete Data Cleanup: With
VACUUM, unreferenced files are safely removed, freeing up space and preserving performance.
These features work in an integrated way, maintaining data integrity even under high concurrency or continuous ingestion scenarios.
Delta Lake Capabilities
- ACID Transactions in Spark: serializable isolation levels ensure readers never see inconsistent data.
- Scalable Metadata Handling: leverages Spark’s distributed processing to manage metadata for petabyte-scale tables with billions of files.
- Unified Streaming and Batch: one Delta table is both a batch table and a streaming source and sink. Streaming ingestion, batch backfill, and interactive queries work seamlessly.
- Schema Enforcement: automatically handles schema variations to prevent invalid record insertion during ingestion.
- Time Travel: data versioning allows rollback, full historical audit trails, and reproducible machine learning experiments.
- Upserts and Deletes: supports merge, update, and delete operations for complex use cases like change data capture, slowly changing dimensions (SCD), and streaming upserts.
- Connector Ecosystem: connectors are available to read and write Delta tables from various engines such as Apache Spark, Flink, Hive, Trino, AWS Athena, etc.
When to Use Delta Lake
Delta Lake is ideal for scenarios requiring:
- Data in various formats coming from multiple sources;
- Use of the data in many different downstream tasks, such as analytics, data science, machine learning, etc.;
- Flexibility to run many different types of queries without having to ask questions in advance;
- Real-time Data Processing: real-time ingestion and analysis with consistency guarantees.
- Management of Large Data Volumes: supports petabytes of data with optimized performance.
- Audit and Versioning Needs: access to previous data versions for auditing and recovery.
When Delta Lake May Not Apply
Delta Lake may not be the best choice for:
- High-concurrency OLTP Systems: applications requiring low-latency and high-concurrency transactions may benefit more from traditional relational databases.
- Complex Constraint Requirements: such as foreign keys and triggers, which are not natively supported by Delta Lake.
Interaction with Apache Spark
Delta Lake is fully compatible with Apache Spark APIs and was designed for complete integration with Structured Streaming, allowing unified data operations across batch and streaming, and supporting scalable incremental processing. It enables:
- Real-time Data Ingestion and Processing: using Spark Structured Streaming.
- SQL Queries and DML Operations: with support for ACID transactions.
- Performance Optimizations: leveraging Spark’s distributed processing capabilities.
Delta Lake X Traditional RDBMS
- Storage: Delta Lake uses Parquet files in distributed file systems, while RDBMSs use block storage.
- Transactions: Delta Lake provides ACID transactions in distributed environments, whereas RDBMSs handle them in centralized systems.
- Schema Evolution: Delta Lake allows flexible schema evolution, while RDBMSs require more rigid structural changes.
Best Practices for Delta Lake
- Small File Compaction: use the OPTIMIZE command to improve query performance.
- Z-order Sorting: apply Z-ordering on frequently filtered columns to accelerate queries.
- Version Management: use time travel for audits and data recovery.
Delta Lake Project Details
- Programming Language: developed in Scala and Java.
- License: open source under Apache 2.0 license.
- Integration: compatible with Apache Spark, Flink, Presto, Trino, among others.
References
https://docs.delta.io/latest/delta-intro.html
https://github.com/delta-io/delta
Footnotes
-
A lakehouse architecture combines the advantages of data lakes and data warehouses in a single platform. It uses the low-cost, scalable storage of a Data Lake, provides ACID transactions, versioning, schema enforcement, and catalogs like a Data Warehouse, supports batch and streaming processing in the same place, and enables SQL and machine learning on the same data. ↩