Apache Zookeeper
Centralized Coordination Service
Distributed applications consist of multiple software components that operate simultaneously on various scalable physical servers, potentially spanning hundreds or thousands of machines.
Obviously, this system is subject to hardware failures, crashes, system failures, communication failures, and so on. These are failures that do not follow a pattern and, therefore, make it difficult to apply fault tolerance code to the application logic or system design.
Additionally, achieving correct, fast, and scalable Cluster coordination is difficult and often prone to errors, potentially leading to inconsistencies in the Cluster.
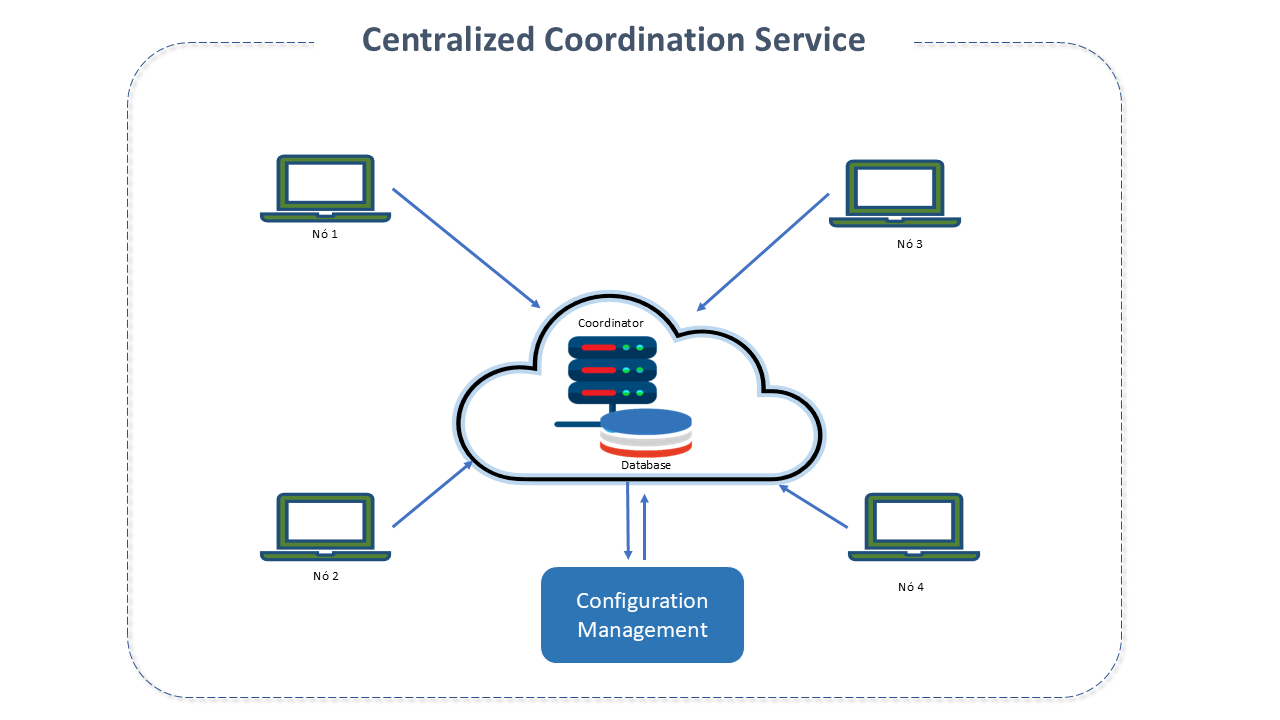
Centralized coordination ensures the maintenance of the consistent "state" and performance of these systems (such as computers and software), avoiding undocumented changes in the environment and helping to avoid performance problems, inconsistencies, or compliance issues.
Performing these tasks manually is complex work in large systems like Big Data. It can involve thousands of components for each application.
For this, there are tools that provide a plan and a single version and the desired state of the organization's systems, as well as visibility of any configuration changes, through audit trails and change tracking.
Apache Zookeeper Features
Apache Zookeeper is a volunteer open-source project by Apache, originally developed by YAHOO and now widely used by major organizations such as Yahoo, Netflix, and Facebook (a complete list of organizations and projects that use Zookeeper can be seen here).
It is an open-source centralized service for the coordination of distributed applications.
It provides a set of "primitives" accessible through simple APIs on which applications can be built to implement high-level services, making less complicated:
-
Cluster association operations (detection of node exit or joining).
-
Distributed synchronization (locks and barriers).
-
Naming (identifying nodes in a Cluster by name, similar to DNS).
-
Configuration management (most recent and updated configuration information of the system for a joining node).
The main intention of Apache Zookeeper is to allow application developers to focus on business logic and rely entirely on Zookeeper for correct coordination:
-
Unlike conventional file systems, Zookeeper provides high throughput and low latency.
-
It runs on a collection of machines and is designed for high availability, avoiding the introduction of points of failure in systems.
-
Order is very important. Its ordering allows sophisticated synchronization primitives to be implemented on the client side.
All updates are ordered. Each update is marked with a number reflecting this order, called zxid (Zookeeper Transaction Id), which is unique for each update.
Reads (and watches) are ordered concerning updates. Read responses are stamped with the last zxid processed by the server that serves the read.
-
The performance aspects of Zookeeper allow it to be used in large distributed systems.
Performance and scalability are achieved through the watches mechanism, which allows clients to register to receive notifications whenever a znode undergoes some change (creation or deletion, changes in data held by the znode, creation or deletion of one of the children in a _znode's subtree).
-
It facilitates loosely coupled interactions.
Apache Zookeeper Architecture
Zookeeper is a distributed and highly reliable centralized coordination application, following the client-server model and operating on a set of replicated servers, known as an ensemble, similar to the management of services such as DNS.
Zookeeper has a simple architecture, with a standard hierarchical namespace (which resembles the Unix filesystem) of data registers, called znodes (each node of the tree), making it an efficient solution for configuration information management.
Clients are nodes that consume services, and servers are nodes that provide services.
Paths to the nodes are expressed as canonical paths (shortest access to a file from the root directory), absolute, and separated by slashes.
There are no relative references.
The main difference between Zookeeper and a standard file system is that every znode can have associated data as children (every file can also be a directory and vice versa), and znodes are limited to the volume of data they hold.
Zookeeper was designed to store coordination data: status information, configuration, location information, etc.
This type of meta-information is usually measured in kilobytes, if not bytes.
Therefore, it has an integrated "sanity" check of 1M, to prevent it from being used as a large data store, but in general, it is used to store much smaller data parts.
The main components of Zookeeper's architecture are:
-
Clients: that connect to the service, using Zookeeper client library APIs (responsible for the interaction of an application with the Zookeeper service), through any member of the Ensemble.
They can send and receive requests and responses, as well as notifications and heartbeats, through a TCP connection.
If the connection is interrupted, the client will connect to a different server.
When it connects for the first time, the first server will set up a session for the client.
Read requests are processed locally on the server to which it is connected and served from the local replicas of each server's database.
If the request registers a watch on a znode, this will also be tracked locally on the server.
Write requests, which change the state of the service, are processed by an agreement protocol and forwarded to other Zookeeper servers. They pass consensus before a response is generated.
Synchronization requests are also forwarded to another server, but they do not pass consensus.
-
Leader: is the server that automatically recovers failed nodes. All client write requests are forwarded to the Leader.
-
Followers: are non-leader servers that receive message proposals from the leader and agree to the delivery of messages.
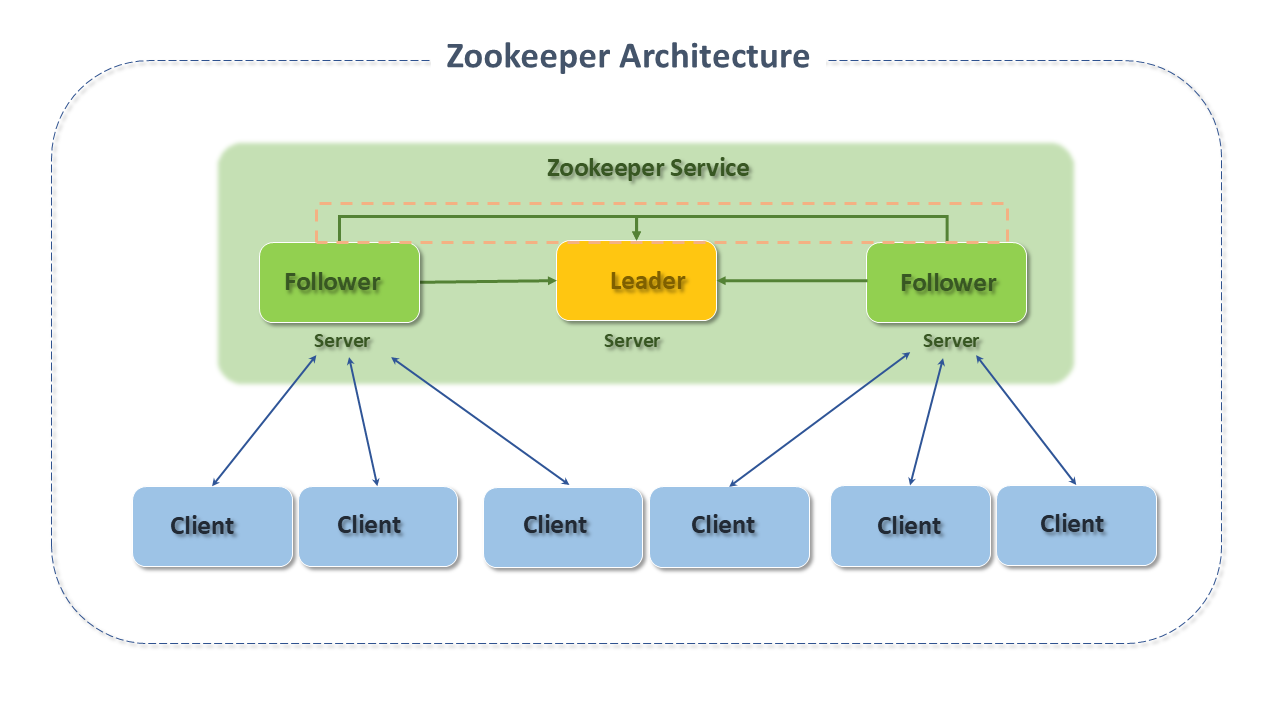
The messaging layer handles leader replacement in case of failure and synchronization between followers and leaders.
Zookeeper uses the standard atomic messaging protocol to ensure data consistency among nodes throughout the system. This ensures that local replicas never diverge.
After receiving a data change request, the leader writes the data to disk and then to memory.
Zookeeper follows a shared and hierarchical storage model similar to a traditional file system. The abstractions provided by the service allow znodes to be manipulated simply and efficiently.
The Zookeeper service is replicated across the set of machines that comprise it.
These machines maintain an in-memory image of the data tree along with transaction logs and snapshots in persistent storage. Once the data is held in memory, it achieves high throughput and low latency.
The disadvantage is that the size of the database that Zookeeper can manage is limited by memory.
This limitation is another reason to keep the amount of data stored in znodes small.
The servers that make up the Zookeeper service must know each other.
As long as the majority is available, Zookeeper will be available. Clients must also know the list of servers because they create an identifier for the service using this list.
Znodes
The Zookeeper namespace is composed of data registers known as znodes, similar to files and directories. The Znode maintains the statistical structure that includes version number for data changes, ACL changes, timestamps, to allow cache validations and coordinated updates. Every time a znode's data changes, the version number increases.
There are two types of Znodes:
-
Persistent: Persistent Znodes only stop being part of the namespace when they are deleted. They exist to store data that needs to be highly available and accessible by all components of a distributed application.
-
Ephemeral: Ephemeral Znodes are deleted by Zookeeper when the client's session ends, which can occur due to a failure disconnection or a connection termination. Although linked to the client's session, they are visible to all clients, depending on the associated Access Control List (ACL) policy. They can also be deleted by the creating client or any other authorized one.
Ephemeral znodes can be used to build distributed applications where it is necessary for components to know each other's state or the state of constituent resources.
-
Sequential: There is a third node, pointed out by some as another type of znode - the sequential. However, this znode should be understood as a qualifier of the two main ones.
noteA sequence number is assigned by Zookeeper as part of its name during creation. The value of a counter maintained by the parent znode is appended to the name.
These znodes are used to implement a global distributed queue because sequence numbers can impose an ordering. Also, to design a locking service for a distributed application.
Best Practices with Apache Zookeeper
Things to Avoid:
There are some issues that should be avoided through proper Zookeeper configuration:
-
Inconsistent server list: The Zookeeper server list used by clients must match the Zookeeper server list that each Zookeeper server has. The client list must be a subset of the actual list. Additionally, the server lists in each Zookeeper server configuration file must be consistent with each other.
-
Incorrect transaction log placement: The most critical part for Zookeeper performance is the transaction log. Zookeeper synchronizes transactions with the media before returning a response. A dedicated transaction log device is key to good and consistent performance.
The log should never be placed on a busy device as this will impair performance. If there is only one storage device, we suggest placing the trace files on NFS and increasing the snapshotCount. This does not eliminate the problem but can mitigate it.
-
Swap to disk:
-
Special care is needed when configuring the Java heap size. The situation where Zookeeper performs a swap to disk should be avoided. Everything is ordered, so if processing a request "swaps" to disk, all other requests in the queue are likely to do the same.
-
It is advisable to be conservative in estimates: With 4G of RAM, a maximum Java heap size should not exceed 3G, for example, because the operating system and cache also need memory.
-
The best practice is to perform load tests, ensuring to stay well below the limit that could cause a swap.
-
System monitoring like vmstat can be used to monitor virtual memory statistics and decide on the optimal memory size depending on the application's needs. In any case, always avoid swapping.
-
Things to do:
-
It is advisable to periodically clean the Zookeeper data directory if the autopurge option is not enabled. This directory contains the snapshot and transactional log files.
-
Additionally, it is important to assess the need for a backup, which, being Zookeeper a replicated service, is only necessary on one of the ensemble servers.
-
Zookeeper uses Apache log4j as the logging infrastructure. It is advisable to set up automatic rollover using the built-in Log4j feature for Zookeeper logs as the log files grow.
Zookeeper Project Details
Zookeeper is implemented in Java and offers bindings for various other programming languages such as C, Java, Perl, and Python.
The full list of available client bindings in the community can be accessed here.
Sources: