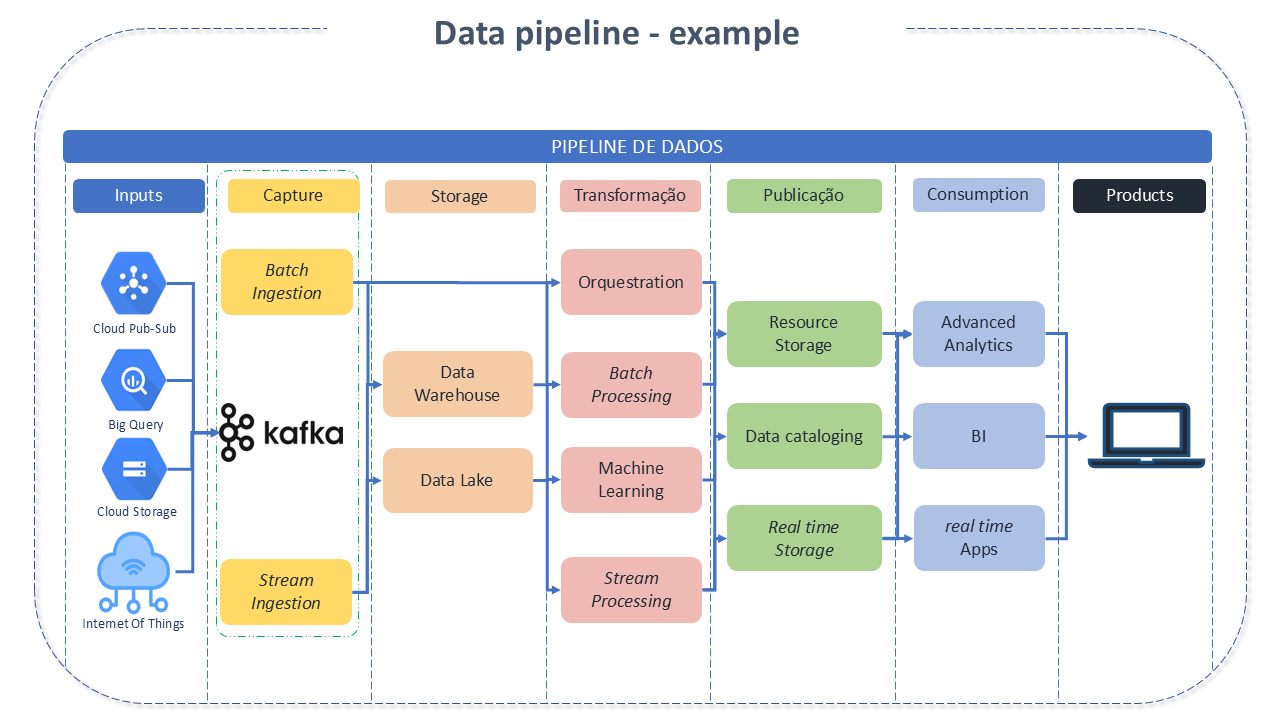
Apache Airflow
Pipeline Orchestration
A data pipeline consists of a set of tasks or actions that need to be executed in a certain order or logical sequence (Workflow) to achieve a desired result.
Data pipelines can be represented as DAGs - _Directed Acyclic Graph - which consist of blocks that follow a sequence, as the previous one is executed, allowing forking at various points, without the possibility of returning to the starting point. In DAGs, it's possible to define operators (which become tasks) and relationships between operators programmatically.
Although many Pipeline Orchestrators have been developed over the years to execute tasks (DAGs), Airflow has several important features that make it particularly suitable for implementing efficient and batch-oriented data pipelines.
Apache Airflow Features:
Apache Airflow was created at Airbnb in 2014 as a solution to manage their complex workflows. From the beginning, the project has been open-source, becoming an Apache incubator project in 2017 and a top-level Apache project in 2019.
It is a feature-rich tool and has a set of fundamental resources for a Big Data solution:
- Versatility: The ability to implement pipelines using Python code allows the creation of complex pipelines with anything compatible with Python.
- Easy Integration: Airflow's Python base makes it easy to extend and add integrations with many different systems. The Airflow community has already developed a rich collection of extensions for different databases, cloud services, etc.
- Rich programming semantics: It allows the execution of pipelines at regular intervals and the creation of efficient pipelines using incremental processing to avoid costly recalculations of existing results.
- Backfilling: Allows easy reprocessing of historical data and recalculation of any derived datasets after code changes.
- Rich Web Interface: Airflow's rich web interface provides easy visualization for monitoring pipeline execution results and debugging any failures.
- Open Source: Ensures job creation without any vendor dependency.
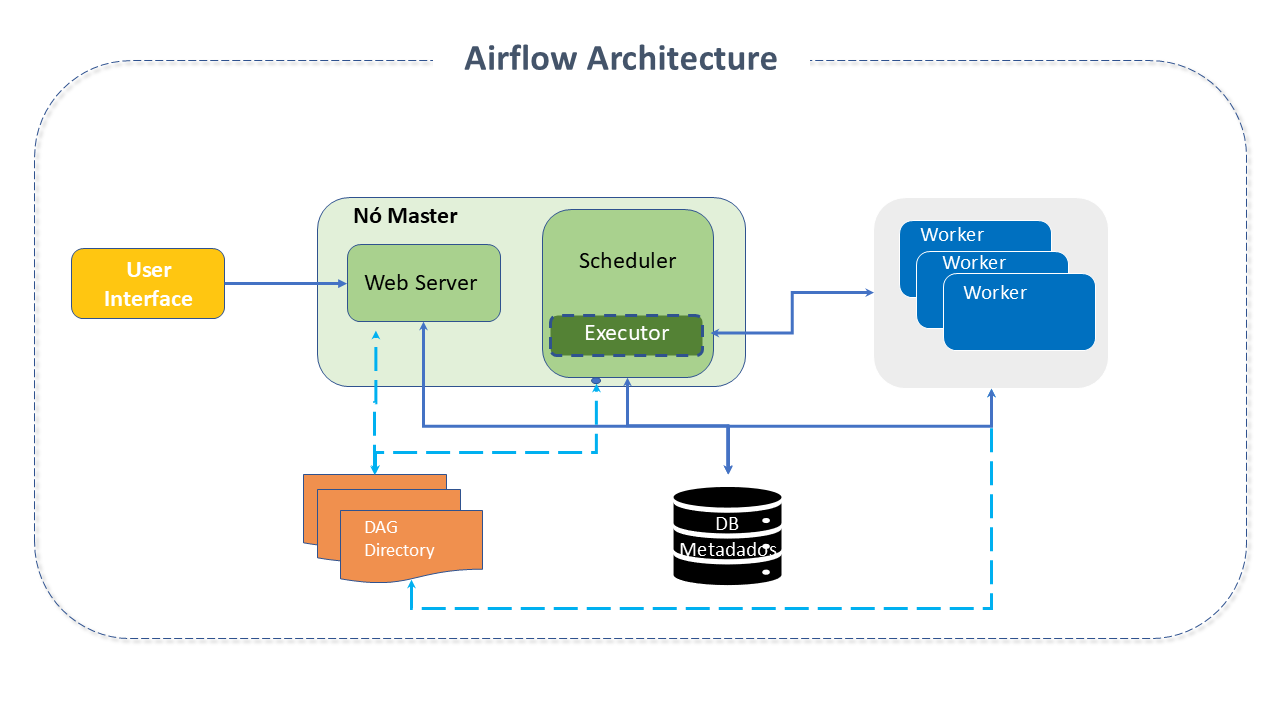
Apache Airflow Architecture
Airflow is organized from the following main components:
-
**DAGs - _Directed Acyclic Graph: The DAG is the main concept in Airflow. It represents a workflow (a collection of individual tasks , organized with their respective dependencies and data flows - the tasks themselves describe what will be done, such as data fetching, analysis, triggering another app, etc.).
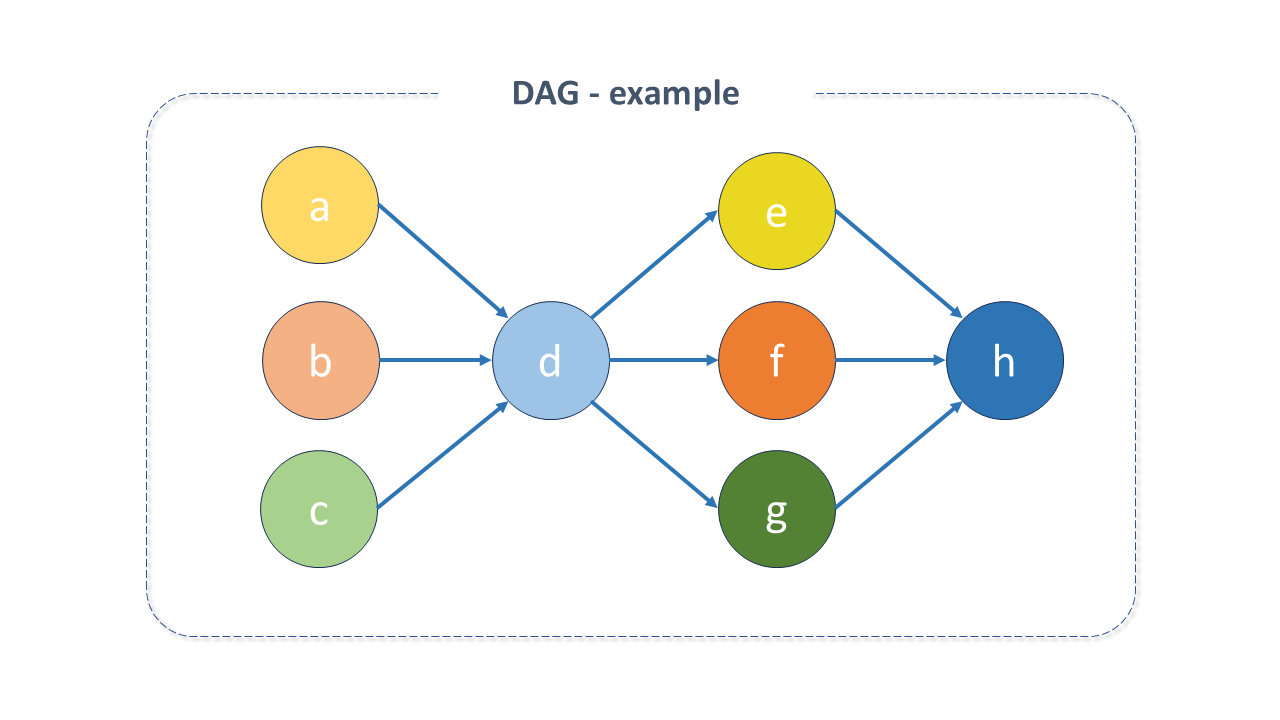 Figure 3 - Example of the structure of a DAG
Figure 3 - Example of the structure of a DAGThe DAG doesn't care about what happens inside a task, but rather how to execute it (the order of execution, how many times to repeat them, if there is a timeout, etc.). The DAG structure is composed of the declaration of dependencies between tasks.
Besides that, DAG files contain some additional metadata about the DAG, informing Airflow how and when it should be executed. This programmatic approach offers a lot of flexibility to create DAGs and allows customization in the way pipelines are created.
DAGs do not require scheduling, but it is very common for them to be defined, which is done by the Scheduler A DAG is executed in two ways: triggered manually or through an API or on a defined schedule, as part of the DAG.
Its most important parameters are:
-
Scheduler: The Scheduler handles the triggering of scheduled workflows and the submission of tasks to the Executor.
-
Webserver: Presents a user interface that allows for the visualization of DAGs and tasks, their inspection, triggering, debugging, and analysis of their results.
-
Executor: A process that handles tasks in execution. In a standard installation, it runs within the Scheduler. However, most production-suitable Executors send task execution to Workers.
Most Executors will introduce other components to communicate with their Workers (such as the task queue). However, we can understand the Executor and its Workers as a single logical component handling task execution.
The Executor is configurable, and depending on the requirements, you can choose from a few options:
-
Local:
-
Sequential Executor: This is the default executor. It will execute one task instance at a time.
-
Local Executor: Executes tasks by generating processes in a controlled manner in different modes. Since the BaseExecutor has the option to receive a parallelism parameter to limit the number of generated processes, when this parameter is 0, the number of processes that the Local Executor can generate becomes unlimited.
-
-
Remote:
-
Dask Executor: Allows the execution of Airflow tasks in a Dask Distributed Cluster. Dask Clusters can run on a single machine or remote networks.
-
Celery Executor: It is one way to scale the number of workers.
-
Kubernetes Executor: Introduced in Apache Airflow 1.10.0, it allows Airflow to be scaled very easily as tasks are executed in Kubernetes.
-
Celery Kubernetes Executor: Allows simultaneous execution of Celery Executor and Kubernetes Executor. It inherits the scalability of the Celery Executor to handle high loads during peak hours and runtime isolation of the KubernetesExecutor.
-
-
-
Workers: These are separate processes that execute scheduled tasks.
-
DAG files: Store the files that are read by the Scheduler and Executor (and by the Workers that the Executor has).
-
Metadata Database: SQL database used by the Scheduler, Executor, and Webserver to store metadata about the data pipelines being executed.
Apache Airflow Resources
-
Pooling: Pooling is an additional feature that provides resource management mechanisms. Pools limit the execution of parallelism on the resource when many processes demand it at the same time, avoiding overload.
-
Queuing: All tasks go to the default queue. It is possible to define queues and workers to consume tasks from one or more queues. Queues are especially useful when some tasks need to be executed in a specific environment or resource.
-
Plugins: Airflow has a simple plugin manager that can integrate external resources into its core by simply "dropping" files into the $Airflow_home/plugins folder. Python modules in the plugins folder are imported, and web macros and views are integrated into Airflow's main collections and become available for use.
Important Concepts:
-
Dag Runs: Every time a DAG is executed, a new instance of it is created, called a Dag-Run by Airflow. DAG runs can be executed in parallel for the same DAG, and each one has a defined data interval that identifies the data period and which tasks it should operate on.
-
Tasks: Although from the user's point of view, tasks and operators are equivalent, in Airflow, there are Tasks components that manage the operating state of the operators (define a unit of work within a DAG through the operators). They are represented as a node in the DAG.
There are three common types of tasks:
-
Operators: Conceptually, they are a template for predefined tasks that can be declared within the DAG. They are the components specialized in executing a single, specific task within the workflow. It is a step in the workflow and is usually (not always) atomic, not carrying information from previous operators. In this way, it has autonomy. As they are the ones that actually execute the tasks, both terms are often used interchangeably. Airflow has an extensive set of Operators available, some integrated into the core or pre-installed. The most popular are:
-
PythonOperator: Calls a Python function.
-
EmailOperator: Sends an email.
-
BashOperator: Executes a Bash script, command, or set of commands.
-
-
Sensors: A special subclass of Operators that "waits" for an external event.
-
Taskflow-decorated @task: A custom Python function packaged as a task. It makes creating DAGs much easier for those who use simple Python code instead of Operators to write DAGs.
-
note
- If two operators need to share information, they can be combined into a single operator. If this is not possible, there is a cross-communication feature called xcom.
- Operators do not need to be assigned to DAGs immediately (but once assigned, they cannot be transferred or unassigned).
:::
-
Task instances: Represent the state of a task -> at what stage of the lifecycle the task is in. It instantiates a task - which has been assigned to a DAG and has a state associated with a specific execution. The possible states are:
- None: The task has not been added to the execution queue (scheduled) because its dependencies have not yet been met.
- Scheduled: The dependencies have been met, and the task can be executed.
- Queued: The task has been linked to a worker by the executor and is waiting for availability to be executed.
- Running: The task is running.
- Success: The task was executed without errors.
- Failed: The task encountered errors during execution and failed.
- Skipped: The task was bypassed due to some mechanism.
- Upstream failed: The dependencies failed, and therefore the task was not executed.
- Up for retry: The task failed, but there are defined mechanisms for retries, and therefore it can be rescheduled.
- Sensing: The task is a smart sensor.
- Removed: The task has been removed from the DAG since its last execution.
Best Practices for Apache Airflow
The Apache community provides a series of Best practices recomendations, some of which we summarize below:
- Writing a DAG: Although creating a new DAG in Airflow is a fairly simple task, the community warns of a number of cautions necessary to ensure that its execution does not produce unexpected results.
- Generating Dynamic DAGs: Sometimes writing a DAG manually is not practical. The dinamic DAG generation feature can be useful on these occasions.
- Triggering DAGs after Changes: The system needs enough time to process changed files. It is recommended that you avoid triggering DAGs immediately after their modification or the modification of accompanying files.
- Reducing DAG Complexity: Although Airflow is good at handling large volumes of DAGs with many tasks and dependencies, very complex and large numbers of DAGs can affect the Scheduler's performance. It is recommended to simplify and optimize them whenever possible.
- Testing a DAG: DAGs should be treated as production-level code and have numerous associated tests to ensure they produce the desired results. It is possible to write a wide variety of tests for a DAG.
- Metadata DB Maintenance: Over time, the Metadata database increases its storage coverage. Airflow's CLI allows you to clean up old data with the command airflow db clean.
- Handling Conflicting/Complex Python Dependencies: Airflow has many Python dependencies that sometimes conflict with what the code wants. The community offers some strategies that can be employed to mitigate the risks.
Apache Airflow Project Details
Airflow is written in Python. Its workflows are created using Python scripts. It was designed under the principle of "configuration as code." Although there are other tools that adopt this principle, the use of Python is what allows developers to import libraries and classes.
Source(s):