Apache Kafka
Data Streaming Platform
Traditional batch processing methods require that data be collected in batches before it can be processed, stored, or analysed.
In contrast, data streaming involves the continuous flow of data, which can be processed as soon as it arrives. This allows for dynamic, contextual, and real-time decision making, thereby enabling businesses to harness the full value and potential of their data and applications.
Data streaming captures time-ordered data elements from various event sources such as databases, sensors, mobile devices, cloud services, and software applications.
The captured streams can be processed in real time or retrospectively and routed to different technologies as needed. They can be stored for later retrieval, manipulation, or processing.
Data streaming involves technologies that have emerged in recent years. A real-time data analytics system, for instance, is designed for high data generation, based on events that quickly spread across the network.
Features of Apache Kafka
Kafka is the most commonly used event streaming platform. It is employed for collecting, processing, storing, and integrating data at scale. Kafka supports a variety of use cases including distributed logging, stream processing, data integration, and message publishing/subscribing.
Originally developed as a solution for a LinkedIn software that collected user activity data and used it to display on a web portal, Kafka was built as a fault-tolerant, distributed system that combines three key capabilities:
- Publishing (writing) and subscribing (reading) of event streams, including continuous data import/export from other systems.
- Durable and reliable storage of event streams for as long as necessary.
- Real-time or retrospective event stream processing.
Kafka was built with the following principles in mind:
- Low coupling between producers and consumers.
- Data persistence to support various consumption scenarios and failure handling.
- Maximum end-to-end throughput with low-latency components.
- Handling of diverse data formats and types using binary data formats.
Kafka is commonly utilized in stream processing architectures. With its reliable message delivery semantics, it assists in managing high rates of event consumption. Additionally, it provides message replay features for various types of consumers.
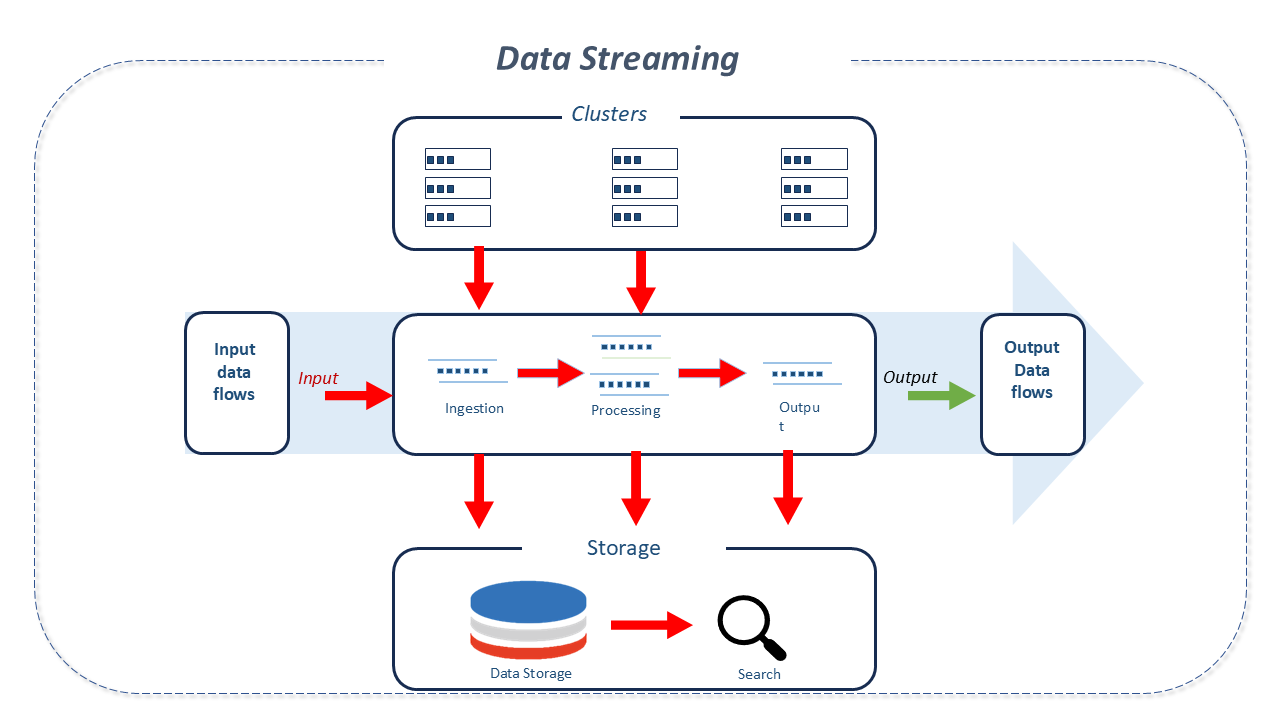
Architecture of Apache Kafka
- Communication System:
Kafka is a distributed system consisting of servers and clients communicating over a high-performance TCP network protocol.
It can be deployed on bare-metal hardware, virtual machines, containers, and cloud environments.
Kafka clusters are highly scalable and fault-tolerant. Its communication model uses a Write-Ahead Log (WAL) system where every message is logged before being available to consumer applications so that subscribers and consumers can access it when needed.
Kafka simplifies system-to-system communication by acting as a centralized communication hub. The implemented publish-subscribe pattern ensures that streams flow in one direction, unlike the bidirectional communication in client-server models.
Designed as a simple and lightweight client library, it can be easily incorporated into any Java application and integrated with any package.
It has no external dependencies in the messaging layer. The messaging layer partitions the data for storage and transport.
This partitioning enables locality, scalability, high performance, and fault tolerance.
-
Key Components of Kafka:
-
Clients: Enable the writing of microservices and distributed applications that read, write, and process event streams in parallel, at scale, and fault-tolerantly.
Kafka includes several built-in clients, supplemented by many others provided by the community.
Clients are available for Java and Scala, including the high-level Kafka Streams library, and for languages like Go, Python, C/C++, and more, as well as REST APIs. -
Servers: Kafka runs as a cluster of one or more servers that can span multiple datacenters or cloud regions. Some of these servers, called brokers, form the storage layer.
- Brokers:
A typical Kafka cluster consists of multiple brokers. This facilitates load balancing for read and write operations across the cluster.
Each broker is stateless, with Zookeeper managing its state.
- Brokers:
A typical Kafka cluster consists of multiple brokers. This facilitates load balancing for read and write operations across the cluster.
-
Topics: Organize events similarly to database tables by grouping related data, albeit without enforcing a specific schema.
They store messages as raw bytes, providing flexibility to handle homogeneous or heterogeneous data.
Topics are divided into partitions, and physically, each topic is distributed across different brokers, which host one or more partitions for each topic. -
Partitions: Store messages in the order they arrive. Events with the same key (ID) are written to the same partition.
The number of partitions for a topic is configurable, as is their size.
Having more partitions generally translates to more parallelism and higher throughput.
Kafka pipelines should have a uniform number of partitions per broker and all topics on each machine.
In each partition, one of the brokers acts as the leader, and one or more act as followers.
Leaders handle read and write requests for their partitions, while followers replicate the leader.
Followers do not interfere in the leader's operations but act as backups, ready to replace the leader in case of a failure.
Each Kafka Cluster can simultaneously be a leader for some topic partition or a follower in others. Thus, the load on any server is equally balanced.
The leader election is conducted with the help of Zookeeper, which manages and coordinates the brokers and consumers.
Zookeeper keeps track of any additions or failures of brokers in the Cluster, notifying their state to the producers or consumers of the Kafka queues.
It also assists producers and consumers in coordinating the active brokers, recording which are the leaders for each topic partition and passing this information on to producers and consumers. -
Producers are the applications responsible for sending data to the topic partition for which they are producing data.
The producer does not write data to the partition. It only creates write requests for messages and sends them to the lead broker.
Depending on the configuration, the producer waits for a confirmation of messages. -
Consumers are applications or processes that subscribe to (read and process) events.
They fetch messages from log files belonging to a topic partition. They are the ones who distribute the work across multiple processes.
-
Kafka UI
Kafka UI is a versatile, fast, and lightweight web interface for managing and monitoring Kafka clusters.
It is an open-source tool that assists in observing data flows, troubleshooting, managing, and analyzing performance.
Its dashboard enables tracking of key metrics for Brokers, Topics, Partitions, and Event Production and Consumption.
Key Features of Kafka UI
-
Message exploration - navigate through topic messages using Avro, Protobuf, JSON, or plain text encoding.
-
Consumer group visualization - view per-partition parked offsets and delays.
-
Setup assistant - configure Kafka clusters through a web interface (UI).
-
Multi-cluster management - monitor and manage all clusters in one place.
-
Performance monitoring with a metrics dashboard - track and display key Kafka metrics.
-
Visualization of Kafka Brokers - view topic and partition assignments and controller status.
-
Kafka topics visualization - view counters, replication status, and custom configurations.
-
Dynamic topic configuration - create and configure new topics with dynamic settings.
-
Role-based access control - manage permissions to access the UI with granular precision.
-
Data masking - obscure sensitive data in topic messages.
Resources of Apache Kafka
-
Open-source tools for large ecosystems:
A wide range of community-driven tools.
-
Kafka APIs: In addition to command-line tools, Apache Kafka provides five APIs for Java and Scala for management and administration tasks:
-
Admin API Manage and inspect topics, brokers, etc.
-
Producer-API Publish (write) streams of events to one or more topics.
-
Consumer-API: Subscribe (read) one or more topics and process the stream of events produced.
-
Kafka Streams API: Once data is stored as an event in Kafka, it can be processed with the Kafka Streams client library for Java/Scala, which enables the implementation of real-time, mission-critical applications and microservices where the inputs and/or outputs are stored in Kafka topics.
Kafka Streams combines the simplicity of writing and deploying Java and Scala client-side applications with the benefits of server-side cluster technology, making these applications highly scalable, elastic, fault-tolerant, and distributed. -
Kafka Connect API: Build and run data import/export connectors that consume or produce event streams.
-
-
Operational Monitoring: Kafka is often used for Operational Monitoring, involving statistics from distributed applications for production of centralized sources of operational data.
-
Log Aggregation Solution Kafka can be used as a Log Aggregation Solution, collecting physical log files from servers and placing them in a centralized location (such as HDFS) for processing.
Compared to log-centered systems like Flume and Scribe, it offers similar performance with stronger durability guarantees due to replication and lower end-to-end latency. -
Event Sourcing Kafka can be used in Event Sourcing, storing changes to the application state as a sequence of events that can not only be queried but also used to reconstruct past states and retroactively change them.
-
Log Compaction Kafka can serve as an external commit-log for distributed systems.
The log helps replicate data between nodes and acts as a resynchronization mechanism for failed nodes. The Kafka Log Compaction feature supports this use.
In this respect, Kafka is similar to the Apache Bookkeeper project. -
Replication Apache Kafka replicates the log for each topic partition across a configurable number of servers (this replication factor can be set on a per-topic basis).
This helps in automatic failover for these replicas when a server in the cluster fails, so messages remain available in the presence of failures. -
Quotas The Kafka cluster has the capability to "enforce" quotas on requests to control the resources of the broker used by the client.
Two types of client quota can be applied to each client group that shares a quota:- Network bandwidth quotas: define the limits of the byte rate (from 0.9).
- Request rate quotas: define the limits of CPU utilization as a percentage of network and I/O threads (from 0.11).
Best Practices for Apache Kafka
-
Data Validation: During the recording of a producer system, it is essential to conduct validation tests on the data that will be recorded in the cluster (non-null values for key fields, for example).
-
Exceptions: During the recording of a Producer or Consumer, it is important that exception classes be defined and the actions to be taken in accordance with business requirements are established.
This helps not only in debugging but also mitigates risks (alerts for defined situations, for example). -
Number of retries: Generally, there are two types of error in a producer application: errors that are "solvable" with a new attempt (such as network timeouts and "leader not available") and errors that need to be handled by the producer.
Configuring the number of retries helps mitigate risks related to message loss due to Kafka cluster or network errors. -
Number of bootstrap URLs: It is important to have more than one broker listed in the bootstrap broker configuration in the producer program.
This assists producers in adjusting when there are failures due to unavailability of a broker.
Producers try to use all the brokers listed until they find one with which they can connect.
Ideally, all the brokers in the Kafka cluster should be listed to accommodate all connection failures.
However, in the case of very large clusters, a smaller number that can significantly represent the brokers in the cluster may be chosen.
Note that the number of retries can affect end-to-end latency and cause duplication of messages in the Kafka queue. -
New partitions in existing topics: New partitions in existing topics should be avoided when using key-based partitioning for message distribution.
Adding new partitions can change the hash calculated for each key because it considers the number of partitions as one of its inputs.This would result in different partitions for the same key.
-
Rebalancing: Whenever a new consumer joins consumer groups or an old one becomes inactive, a rebalance of partitions in the cluster is triggered.
Whenever a consumer is losing ownership of its partition, it is important to commit the offsets of the last event received from Kafka. -
Commit offsets at the right time: In the case of commit offset for messages, it is necessary to do so at the right time. A batch processing application takes more time to complete the processing.
It is not a rule, but if the processing lasts more than a minute, it is reasonable to perform the commit the offset at regular intervals to avoid duplicate data processing in case of application failure.
For more critical applications where this duplication may cause financial problems, the time to commit offset should be as short as possible if throughput is not an important factor.
Other recommendations
The blog.kafka.br provides a series of discussions and recommendations that are worth knowing.
Details of Project Apache Kafka
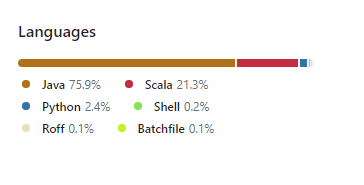
Kafka was written in the programming languages Java and Scala.
Sources: