Apache Zeppelin
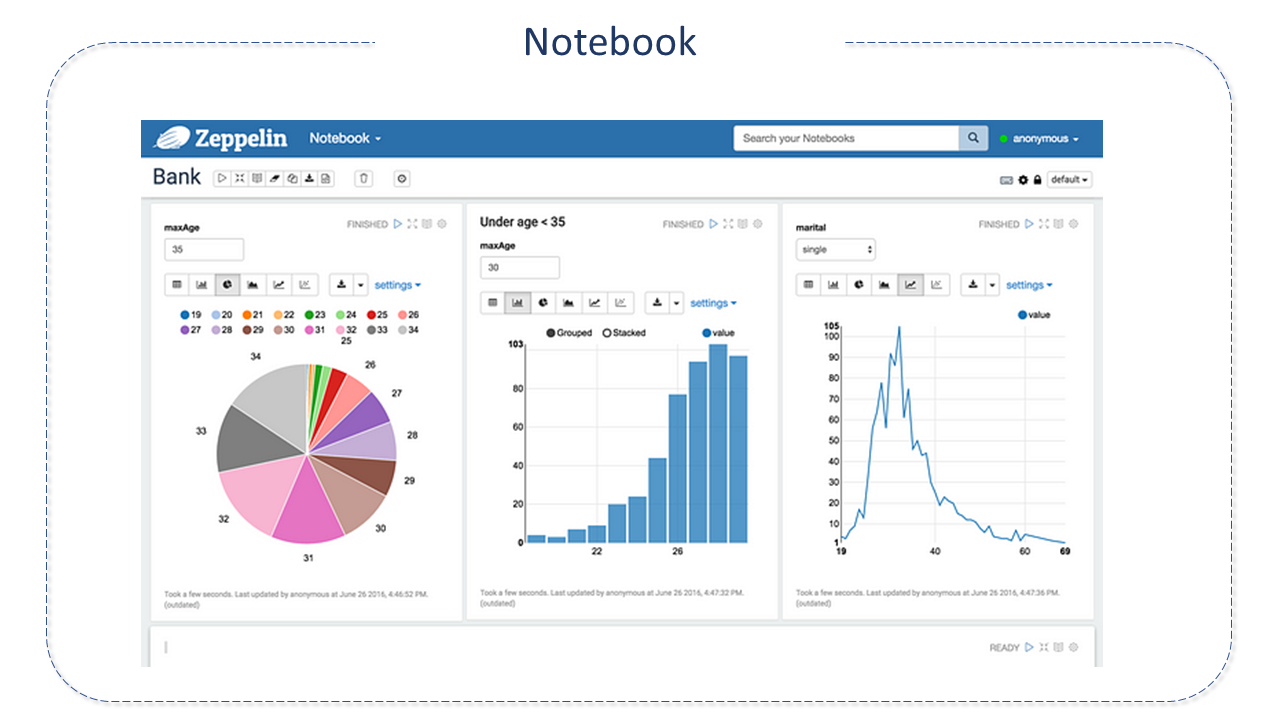
Notebook
Typically used by data scientists in experiments and exploratory tasks, the notebook is an interactive computing tool that allows users to write and execute code, visualize results, and share insights.
The concept was created by Stephan Wolfram, a computer scientist and physicist, who introduced Mathematica - the first computational notebook interface. Since then, the tool has proliferated and moved from academia to industry.
- Apache Zeppelin is a web-based "notebook" that provides ingestion, exploration, visualization, sharing, and interactive collaboration capabilities for Hadoop and Spark.
Apache Zeppelin began as a project named Zeppelin, from the company ZEPL (formerly known as NFLabs), led by Moon Sool Lee. In 2014, it became an incubator project at the Apache Software Foundation, and soon after, in 2016, it became a top-level project at Apache.
According to its creators, the term "notebook" given to Zeppelin is an analogy to a notebook, basing its functions on "paragraphs."
Apache Zeppelin Features
Zeppelin's interactive notebooks allow engineers, analysts, and data scientists to optimize their work with data. In this way, it can be seen as an interface that connects users with the technologies they want to use for data processing.
Zeppelin is very useful for working interactively with data science workflows, developing, organizing, and executing analyses and visualizing their results, without the need to use the command line or query Cluster details.
It also offers support for multiple language backends and a growing ecosystem of data sources.
-
Multiple language backends: The software stands out for its ability to integrate various other technologies through a functionality called interpreter, which is a layer for backend integration (working behind the application), already having more than 20 interpreters in its official distribution package.
Among the various interpreters it supports, we can mention Apache Spark, Python, JDBC, Markdown, and Shell.
-
Integration with Apache Spark: Zeppelin is integrated with Apache Spark. There is no need to create a separate module, plugin, or library for it. This integration provides:
- Automatic SparkContext and SQLContext.
- Runtime dependency JAR loading from the local filesystem or Maven repository.
- Job cancellation with progress display.
-
Data Visualization: Some basic charts can also be used.
Visualizations are not limited to SPARKSQL queries.
Any output from any backend language can be recognized and visualized.
-
Dynamic Charts: Apache Zeppelin aggregates values and displays them in dynamic charts. With a simple drag-and-drop, it is possible to create a chart with multiple aggregated values, including sum, count, average, minimums, and maximums.
-
Dynamic Forms: Apache Zeppelin can dynamically create some input forms in your notebook.
-
-
Notebook and Paragraph Collaboration: The notebook URL can be shared, and then Zeppelin can broadcast all changes in real-time, as well as collaborate like Google Docs.
It can also provide a URL to display only the result, on a page without menu or button, within the Notebook, which can be easily embedded as an iframe on the user's site.
-
100% Open Source: Apache Zeppelin is licensed under Apache2. It has a very active development community.

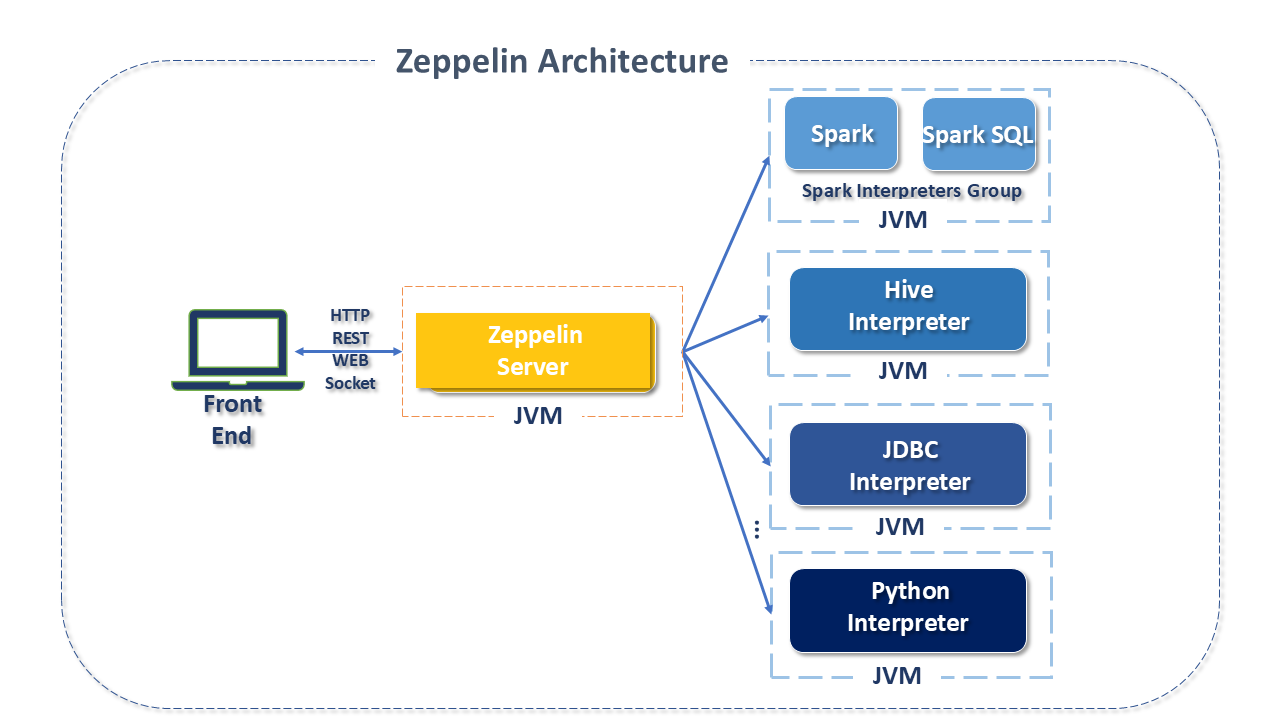
Apache Zeppelin Architecture
Apache Zeppelin is divided into 03 layers:
-
Front-end: From a Web Browser, the user interacts with Zeppelin's Frontend, which is based on AngularJS (a platform for building web applications based on Ecmascript) and Twitter Bootstrap (a CSS framework) that make the web application interface more fluid and dynamic.
The front-end layer communicates with the Apache Zeppelin server through two possible interfaces:
- REST: An architectural style to define HTTP protocol constraints and properties.
- Web Socket: A technology for bidirectional communication over full-duplex channels - transmitter and receiver can simultaneously transmit data in both directions over a single TCP socket.
-
Zeppelin Server: The server operates on a Virtual Machine (JVM - Java Virtual Machine) which also acts as the Notebook interpreter.
-
Interpreter: The interpreter communicates with a program running in Zeppelin's background via Apache Thrift, a technology that allows defining data types and service interfaces in a simple definition file.
Taking this file as input, the compiler generates the code to be used to easily create clients and servers that communicate easily between programming languages.
The interpreter is a feature that makes Zeppelin "pluggable" to other technologies. Each interpreter process belongs to a group of interpreters that act as a start and stop unit of the interpreter.
To learn about all the interpreters that Apache Zeppelin supports, click https://zeppelin.apache.org/docs/latest/#available-interpreters.
Data Visualization with Zeppelin
The Notebook is composed of paragraphs.
Each paragraph is a box that receives some type of predefined script in the interpreters.
The interpreted text has a "%" mark to determine the interpreter and script to be executed.
Through the interface built with Angular and Bootstrap, the user can customize their visualization, placing paragraphs in columns to allow simultaneous display of the result.
The interaction between the user, the tool, and the data is provided by the front-end.
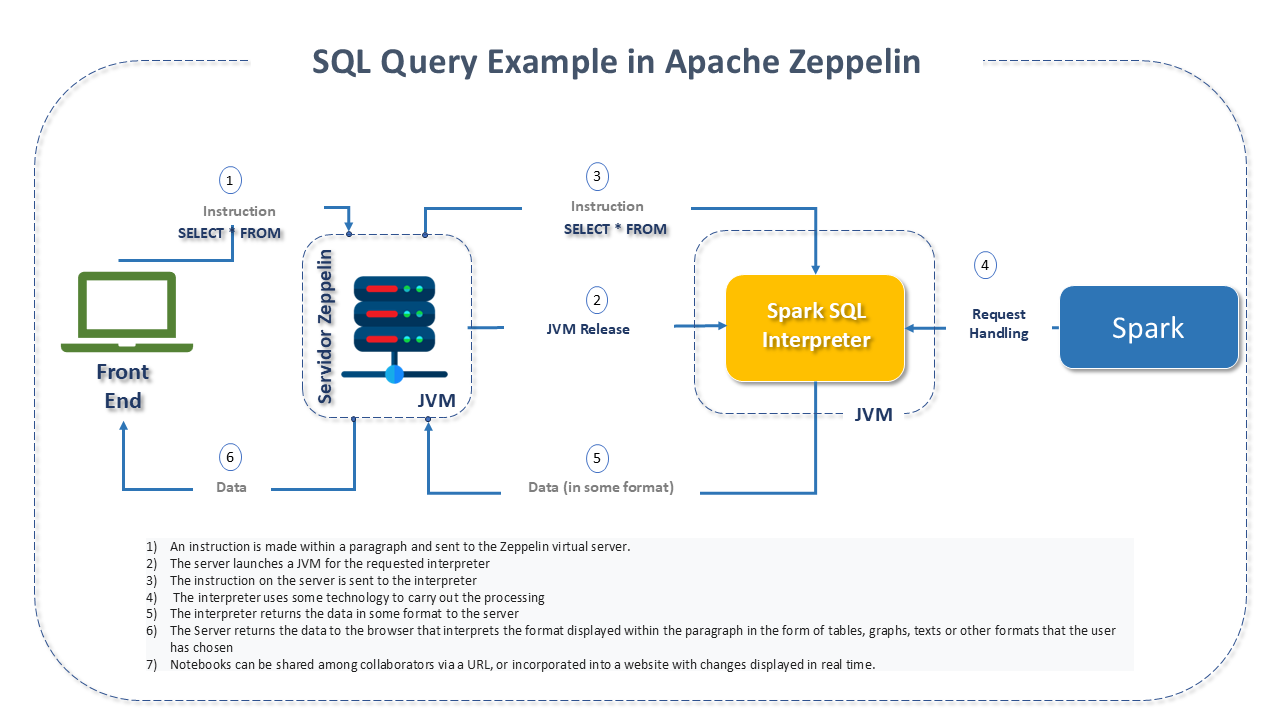
The figure below is an example of Zeppelin's workflow, using a Spark Backend to handle an SQL query.
Apache Zeppelin Best Practices
-
Installation and Versions: It is recommended to install Zeppelin with Ambari and always use the latest version of Zeppelin, ensuring alignment with security and stability fixes.
-
Implementation Choices: Although any node can be selected, the best place to install Zeppelin is on a gateway node when the Cluster firewall is turned off and protected externally.
-
Hardware Requirements: More memory and more cores always benefit performance: a minimum of 64 GB and 8 cores is recommended. Number of users: A Zeppelin node can support 8 to 10 users. For more users, multiple instances can be configured.
-
Security: Like any software, security depends on the threat matrix and deployment options:
- Authentication
- Kerberize the Cluster using Ambari
- Configure Zeppelin to leverage corporate LDAP
- Do not use Zeppelin's local user-based authentication except for demonstrations.
-
Interpreters:
-
Avoid using the Shell interpreter, as the security isolation is not ideal.
-
Do not use the interpreter UI for representations. It works only for Livy and JDBC (Hive) interpreters.
-
Users should restart their own interpreter sessions from the button on the Notebook page, and not on the interpreter page, which would restart sessions for all users.
-
Leverage the Livy interpreter for Spark jobs on the Cluster, as it provides optimal identity propagation.
-
Choosing the interpreters: By default, Zeppelin will register and show all interpreters under the $ZEPPELIN_HOME/interpreters folder. However, there is an option to specify which interpreters should be included or excluded through the zeppelin.interpreter.include and zeppelin_interpreter.exclude properties. Only one of them can be specified.
-
It is possible to criate a new Interpreter, and the task is simple. Just extend the abstract class org.apache.zeppelin.interpreter and implement some methods.
-
Apache Zeppelin Project Details
Apache Zeppelin is based on JVM, functioning as a web application through Jetty and allows paragraphs in notebooks to be written in dozens of different languages such as Scala, Python, R, Markdown, and SQL.
Sources: