Apache HBase
NoSQL database
The NoSQL ("no SQL" or "not only SQL") model represents a non-relational databases (or not only relational, according to more recent definitions). It is a class of database that provides mechanisms for storing and retrieving data modeled in ways other than the tabular relationships used by relational databases.
These databases have been around since the 1960s but gained popularity in the 2000s, triggered by the needs of companies like Facebook, Google, and Amazon.com. They are increasingly used in Big Data and real-time web applications.
NoSQL databases can support query languages similar to SQL.
Apache HBase Features
HBase is an open-source, non-relational ("NoSQL"), column-orienteddatabase that runs on top of the HDFS, created to provide efficient random access and real-time read/write on large distributed datasets.
It was created by Powerset to host very large tables and was later absorbed by the Apache Foundation as part of the Hadoop Project, becoming a great option for combining and storing multi-structured and sparse data.
HBase is natively integrated with Hadoop and works seamlessly alongside other data access "engines" through YARN. It has many features that support linear and modular scalability.
Its clusters expand by adding RegionServers that are hosted on "commodity class" servers (common hardware). If a cluster expands from 10 to 20 RegionServers, for example, it doubles its storage and processing capacity.
Its main features are:
- A Consistent Reads and Writes: HBase is a consistent DataStore, which makes it very suitable for tasks like high speed counter aggregation.
- Automatic Sharding: HBase tables are distributed in the cluster via Regions, and these regions are automatically split and redistributed as data grows.
- Automatic RegionServer Failover: Incoming data "resides" in regions made available by RegionServers. If a RegionServer fails, the master server will designate another to take over the regions that were handled by the failed RegionServer.
- Hadoop/HDFS Integration: HBase supports HDFS "out of the box" as its distributed file system.
- MapReduce Support: HBase supports heavily parallelized processing via MapReduce, acting as both a source and a sink.
- Java Client API: HBase supports an "easy to use" Java API for programmatic access.
- Thrift/REST API: HBase supports Thrift and REST for non-Java front-ends.
- Block-cache and Bloom Filters: HBase supports high volume query optimization.
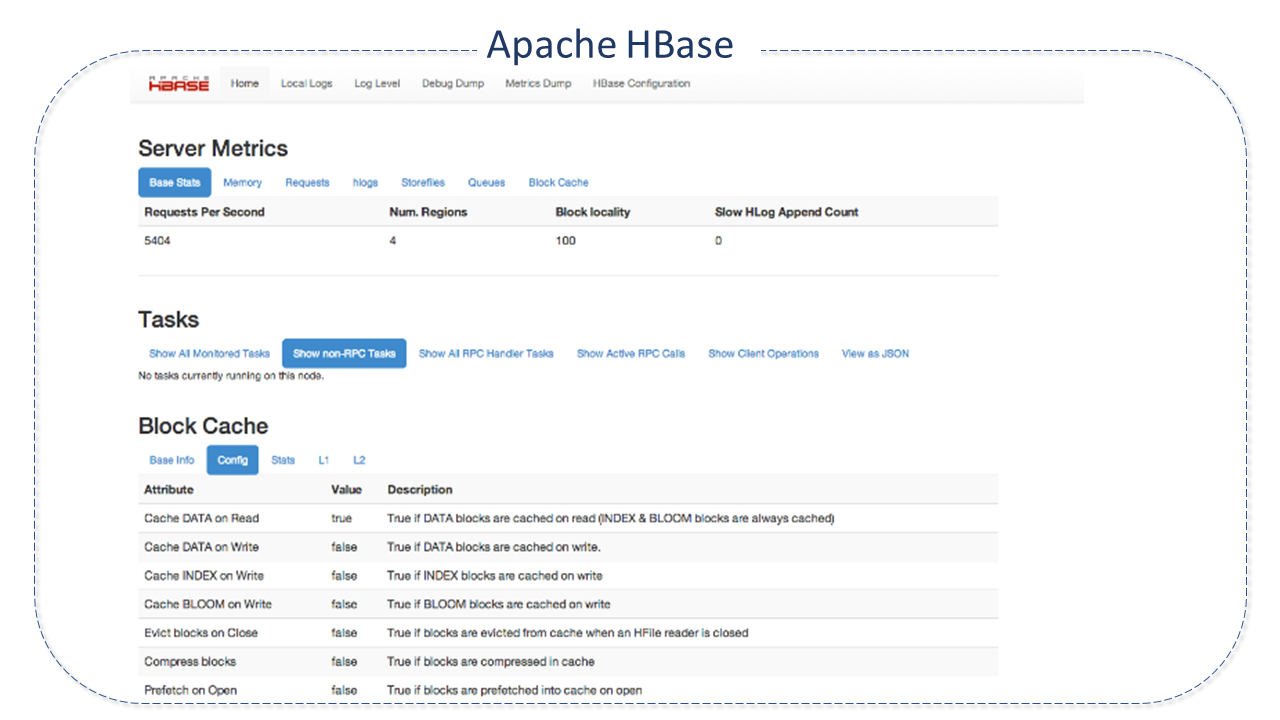
- Operational Management: HBase provides integrated web pages for operational insight and JMX metrics.
- High Availability: HBase provides high availability with:
- Highly available cluster topology information through production deployments with multiple HMaster and Zookeeper instances.
- Data distribution across multiple nodes ensuring that the loss of a single node only affects the data stored on that node.
- HBase HA allows data storage, ensuring that the loss of a single node does not result in the loss of data availability.
- The HFile format stores data directly in HDFS and can be read or written by Apache Hive, Apache Pig, MapReduce, and Apache Tez, enabling deep analysis in HBase without data movement.
Apache HBase Architecture
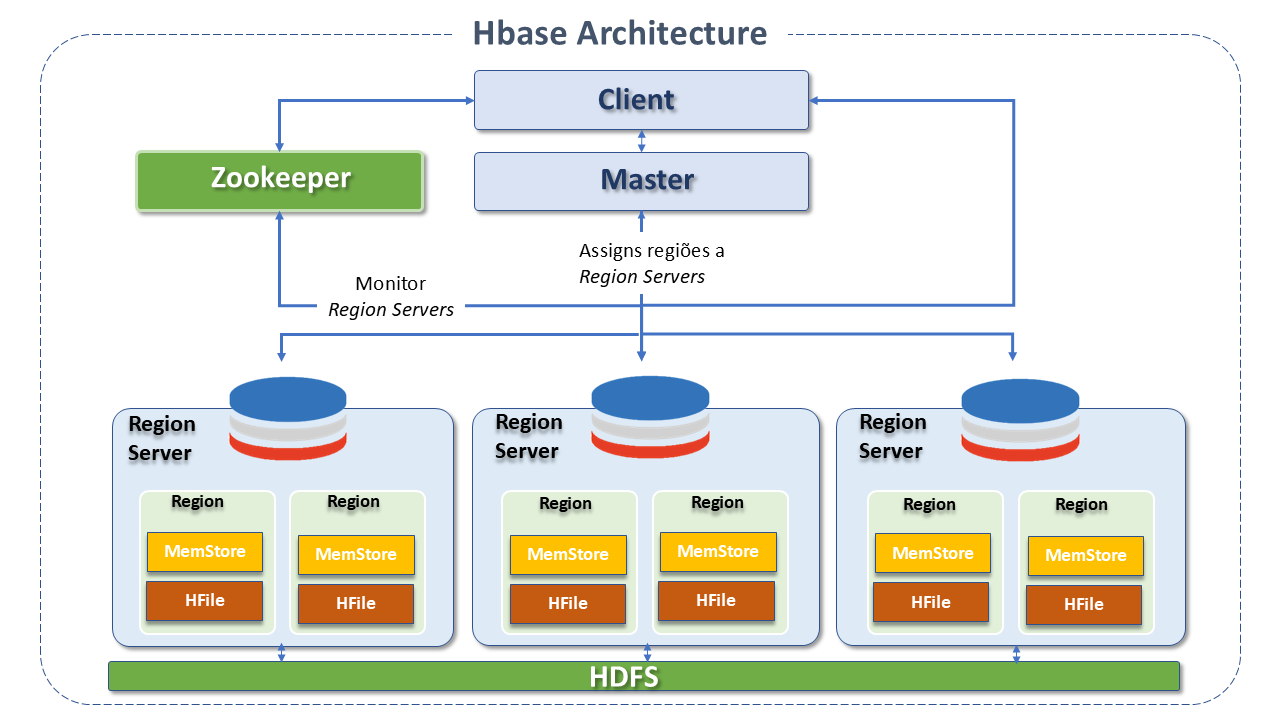
The HBase architecture also follows the master/slave model and is made up of three main components:
-
HMaster(Master Server): Is a process responsible for assigning regions to RegionServers in the Hadoop cluster for load balancing. It is responsible for monitoring all Region Server instances in the HBase cluster and acts as an interface for all metadata changes.
The master typically runs on a dedicated server within the Hadoop cluster.
There are other masters in standby available for replacement in case of unavailability, and Zookeeper takes care of this.noteIt is possible for the master to be idle for some time, and it is possible for the Hadoop cluster to work without it during this period, but it is always good to reactivate the master as soon as possible because it drives some critical functionalities such as:
- Management and monitoring of the Hadoop Cluster;
- Failover control
- Assignment of regions to RegionServers, with the support of Zookeeper.
- Load balancing of regions between RegionServers.
- Schema changes and other metadata operations.
- DDL operations, such as creating and deleting tables.
-
Regionservers: maintain the multiple regions designated by the HMaster. Several regions are combined into a single RegionServer.
They are responsible for client communication and for performing all data-related operations. Any read or write request to the regions is handled by the RegionServer.
The RegionServer is implemented by the HRegionServer and runs on every data node in the HBase cluster. It is composed of the following components:- Write-Ahead Log (WAL): The WAL records all HBase data changes. In a normal situation, it is not needed, as data changes are moved from the MemStore to the StoreFiles. However, if a RegionServer crashes or becomes unavailable before the MemStore is flushed, the WAL ensures that changes can be replayed. If the write to the WAL fails, the entire operation fails.The WAL is appended to each RegionServer. Usually, there is only a single WAL instance per RegionServer. The exception is the RegionServer that loads the HBase:meta table. The table has its own dedicated WAL.
- Block Cache:: The Block Cache resides in the RegionServer and is responsible for storing frequently accessed data in memory, helping to increase performance.
The Block Cache follows the least-recently -used (LRU) concept, where least-recently -used records will be removed. - MemStore: It is a write cache. A temporary memory for all incoming data. Responsible for storing data not yet written to disk. There are multiple MemStores in the HBase cluster.
- HFile: These are the files or cells in which the data is stored. When the MemStore is full, it writes data to the HFile on disk.
-
Regions: These are the basic element of table availability and distribution.
They are composed of a Column Family. HBase tables are divided by Rowkey ranges into regions.
All rows between region start key and region end key will be available in the region. Each region is assigned to a RegionServer, which manages the read/write requests for that region.
As regions are basic blocks of scalability in HBase, a low number of regions per RegionServer is recommended to ensure high performance.
The HBase architecture uses an automatic splitting process to maintain the data. In this process, whenever an HBase table gets too long, it is distributed throughout the system with the help of the HMaster. -
Zookeeper: Zookeeper performs distributed coordination, providing regions to the RegionServers and also recovering regions in case of RegionServer failure, loading them onto other RegionServers. If a client wants to share or swap with regions, they need to contact Zookeeper first.
The HMaster service and all RegionServers are registered with the ZooKeeper service.
The client accesses ZooKeeper to connect with RegionServers and HMaster. In case of failure of a node in the HBase cluster, the Zookeeper ZKquorum will trigger an error message and start the repair failed nodes.
The ZooKeeper service maintains and tracks all RegionServers in the HBase cluster and collects information such as the number of RegionServers, assigned datanodes, etc. It is also responsible for establishing client communication with RegionServers, maintaining control of server failures and network partitions, configuration information, etc.
How Apache HBase Works
HBase scales linearly, requiring all tables to have a primary key. The key space is divided into sequential blocks which are then assigned to a region. RegionServers have one or more regions, so the load is distributed evenly across the cluster. If the keys within a region are frequently accessed, HBase can subdivide the region so that manual data slicing is not necessary.
The Zookeeper and HMaster servers provide cluster topology information to clients. The clients connect to these and download:
- the list of RegionServers,
- the regions contained in those RegionServers, and
- the key ranges hosted by the regions.
Since clients know exactly where each piece of information is in HBase, they can contact the RegionServer directly without the need for a "central coordinator."
Regionserver includes a memstore to cache frequently accessed rows in memory.
HBase Data Model
In HBase, data is stored in tables, which have rows and columns, and its structure can be understood as a multidimensional map.
Its main components are:
-
As the HBase architecture is column-oriented, data is stored in tables that are in tabular format. These tables are declared in advance at the time of "schema" definition. A table consists of multiple rows.
-
Rowkey: A row in HBase corresponds to a Rowkey and one or more columns with values associated with it. The rows are sorted alphabetically by the Rowkey as they are stored. The purpose of the Rowkey is to store data so that related rows are close to each other.
-
Columns: A column in HBase consists of a column-family (column-family) and a column qualifier delimited by a ":" (colon) character. They are the different attributes of the dataset. Each Rowkey can have an unlimited number of columns.
- The columns are not defined beforehand in the structure, as in the Relational Database.
- It is not mandatory that all columns are present in all rows.
- Columns do not store null values.
- All columns in a Column-Family are stored together in one file (HFile) along with the Rowkey.
-
Column Family: These are the grouping of multiple columns. A simple read request to a column-family gives access to all columns in that family, making it quick and easy to read the data. A table must have at least one Column-Family, which is created with the table.
-
Column Qualifiers (Column Qualifiers): These are like column headings or attribute names in a normal table. A column qualifier is added to a column-family to provide the index for a particular piece of data.
-
Cell
It is a combination of row, column-family, and a column qualifier and contains a value and a timestamp, which represents the version of the value. -
Timestamp: Data is stored in the HBase data model with a Timestamp. The_timestamp_is written next to each value and is the identifier for a particular version of the value. By default, the timestamp represents the time on the RegionServer when the data was written, but this can be configured when putting the data into the cell.
Namespace
It consists of a logical grouping of tables analogous to a Database in RDBMS systems. This abstraction lays the groundwork for multi-tenancy resources:
-
Quota Management: Restricting the amount of resources (regions, tables) that a namespace can consume.
-
Security Administration: Providing another level of security management for "tenants."
-
Groups of RegionServers: A table/namespace can be fixed in a subset of RegionServers, ensuring a certain level of isolation.
-
Namespace Security Management: A Namespace/table can be pinned to a subset of RegionServers, ensuring isolation.
Data Model Operations
Like any database, HBase supports a set of basic operations referred to as CRUD (Create, Read, Update, and Delete).
Versions
A tuple (row, column, version) specifies a cell. There can be an unlimited number of cells where the row and columns are the same but the cell address differs in its version dimension.
Joins
HBase does not support joins in the same way as RDBMS. HBase reads are Get and Scan. To enable the join, there are two strategies:
- Denormalize the data when writing to Hbase.
- Have lookup tables and do the join between the HBase tables and an application or MapReduce code.
The best strategy depends on what you want to do.
HBase and Schema Design
Designing a Schema for Bigtable is different from designing a schema for a relational database.
In Bigtable, a schema is a blueprint or model of a table, including the structure of the following table components:
- Rowkeys
- Column families (including garbage collection policies)
- Columns
The main concepts that apply to schema design in Bigtable are:
- Bigtable is a key/value store, not a relational store. It is not compatible with "merging" and transactions are only compatible with a single row.
- Each table has only one index: the Rowkey. There are no secondary indexes. Each Rowkey needs to be unique.
- Rows are sorted lexicographically by Rowkey, from the string that has fewer bytes to the one with more.
- Column families are not stored in any specific order.
- Columns are grouped by group and sorted lexicographically within that group.
- The intersection of a row and column can contain multiple cells with date/time timestamp. Each cell contains a unique and timestamped version of the data for that row and column.
- All operations are atomic at the row level. An operation affects an entire row or no rows.
- Ideally, reads and writes should be evenly distributed across the row space of a table.
- Bigtable tables are sparse. A column does not take up space in a row that does not use the column.
The Hbase community indicates, to address this issue, the website Google Cloud Bigtable Schema Design for more details.
Apache HBase Resources
-
Security in Apache HBase
-
Web User Interface Security: HBase provides mechanisms to secure various components and aspects in its relationship with the Hadoop infrastructure, as well as clients and resources external to Hadoop.
-
Security of client access to Apache HBase: Recent versions of Apache HBase support optional SASL authentication of clients. The community recommends reading the article Understanding User Authentication and Authorization in Apache HBase, for more details.
-
Transport Level Security (TLS) in HBase RPC communication: As of version 2.6.0, HBase supports TLS encryption in client-server and Master-RegionServer communication. TLS is a standard cryptographic protocol designed to provide communication security over computer networks.
-
Securing access to HDFS and Zookeeper: HBase requires secure Zookeeper and HDFS to prevent access or modification of metadata and data. HBase uses HDFS to keep its data files, write-ahead logs (WALs) and other data. And it uses Zookeeper to store some metadata for operations (master address, table locks, recoveries, etc.)
-
Securing access to your client data: The security of client data should also be considered. Some strategies are offered for this:
-
Role-based Access Control (RBAC): Where users and groups can read and write to a specific resource or execute a coprocessor endpoint, using the role paradigm.
-
Visibility labels that enable cell labeling and access control to labeled cells, aiming to restrict who can read and write to a certain subset of data.
-
Transparent encryption of data at rest in the underlying file system, both HFiles and Wal, protecting data at rest from an invasion.
-
-
-
In-memory compaction: In-memory compaction (Aka Acordion) is a new feature of HBase - 2.0.0. It was first introduced in the blog post Accordion: HBase breathes with in-memory compaction.
-
A RegionServer Offheap Read-Write Path: To help reduce P99/P999 RPC latencies, Hbase 2.x made the read and write path use an offheap buffer pool. Cells are allocated in offheap memory, out of reach of the JVM garbage collector (GC), reducing GC pressure.
-
Backup and Restore: HBase Backup and Restore provides the ability to create full and incremental backups of tables in the HBase cluster.
-
Synchronous Replication: Replication in HBase is asynchronous. Therefore, if the Cluster Master fails, the slave Cluster may not have the most current data. To ensure consistency, the user will not be able to switch to the slave Cluster.
-
APIs: In addition to the native APIs, HBase supports external APIs.
-
Coprocessors: (Co-processadores) The Coprocessors framework provides mechanisms to execute custom code directly on the RegionServers that manage the data.
When to Use Apache HBase
Apache HBase is not suitable for all situations.
-
It is a good candidate only for situations with a large volume of data. For small and medium volumes of data, traditional RDBMS may be better, as their data can be concentrated on one or two nodes.
-
It does not have as many extra resources as RDBMS (typed columns, secondary indexes, transactions, advanced query languages, etc.).
-
It requires adequate hardware structure. Even HDFS does not work well with less than 5 DataNodes and 1 NameNode.
Difference between Apache HBase and HDFS
HDFS is a distributed file system suitable for storing large files. However, it is not a general-purpose file system and does not provide fast lookups of individual records in files.
HBase, on the other hand, is built on top of HDFS and provides fast record lookups (and updates) for large tables.
HBase internally arranges its data in indexed HDFS StoreFiles for high-speed lookups.
Best Practices for Apache HBase
-
Hotspotting: As HBase rows are lexicographically sorted by row key (a process that optimizes scans, allowing related rows to be stored close to each other), when poorly designed, row keys can be a source of hotspotting (when a large amount of client traffic is directed to one node or just a few nodes, overloading a single (or few) machines). It is recommended to design data access patterns so that the Cluster is used fully and evenly.
To avoid hotspots on writes, it is important to design row keys so that they are in the same region when they really need to be, but overall, the data is written to multiple regions in the Cluster.
The community suggests some techniques to avoid hotspotting, which can be seen here.
-
Selecting Number of Regions:
When creating tables in HBase, you can explicitly define the number of regions for the table or HBase will calculate it based on an algorithm. It is good practice to define the number of regions for the table and this also helps in improving performance. -
Choosing the number of column families:
Almost always, we have one Rowkey and one column-family, but sometimes we can have more than one column-family. It is good practice to keep the number of column-families as low as possible and never exceed 10. -
Balanced Cluster: An HBase cluster is considered "balanced" when most of the RegionServers have an equal number of regions. You may want to enable the balancer, which will balance the Clusters every 5 minutes.
-
Avoid running other jobs on the HBase Cluster: The integration frameworks used to configure HBase come with other tools like Hive, Spark, etc. However, HBase consumes CPU and memory intensively and sporadically performs large sequential I/O access. Therefore, running other jobs will result in a significant decrease in performance.
-
Avoid "major" compaction and split: HBase has two forms of compaction: the "minor" compaction, which combines a configurable number of small Hfiles into a larger one, and the "major" compaction, when all store files are read for a region and written to a single file. This takes time and prevents writes to the region until it finishes. It is good practice to avoid "major" compaction.
-
Rules of thumb for table schemas and RegionServer sizing: There are different datasets with different access patterns and service level expectations. However, the community presents some general rules that can be seen here.
In addition to the above, the HBase Community provides a series of recommendations for tuning HBase performance, which can be read here.
Apache HBase Project Details
HBase was modeled after Google BigTable and written in Java.
Sources: