Apache YARN
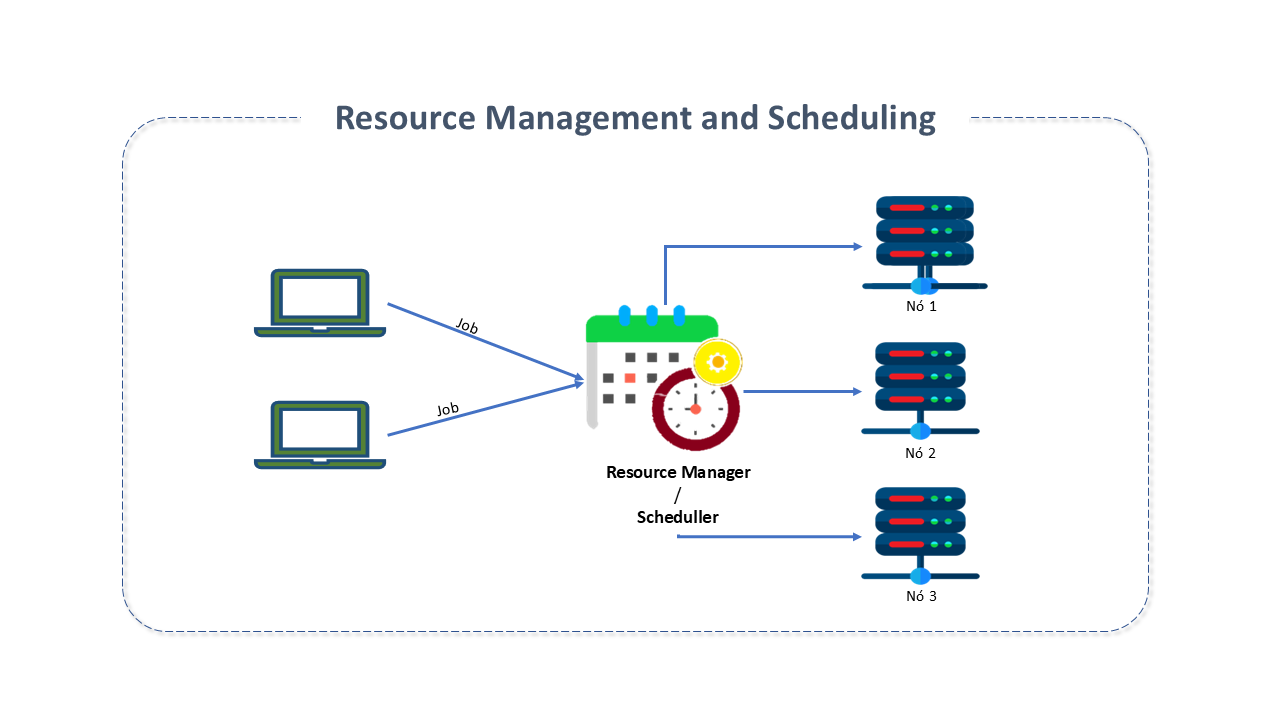
Resource Management
Big Data Processing is a challenging task and is not feasible in a centralized system. Distributed computing solutions need to be adopted to enable the parallel processing required by the technology.
In this environment, multiple tenants with different demands can share computing resources such as data, storage, network, memory, and CPU, making resource management a critical task in this technology.
Big Data users can request multiple processing jobs, each with different requirements.
The Resource Manager acts as a "scheduler," which schedules and prioritizes requests according to the requirements. It essentially acts as a referee, managing and allocating available resources.
In the early versions of Hadoop, there was no Resource Manager. Hadoop consisted of two main parts:
-
Storage: Handled by HDFS
-
Processing: Handled by MapReduce. The only job that could be executed and submitted to Hadoop until version 2.
The tasks of resource allocation and scheduling were handled by the MapReduce JobTracker service.
With the evolution of solutions where real-time and near-real-time processing became predominant, it became essential to have an application executor and a resource manager to schedule and execute all types of applications, including MapReduce, in real time.
Apache YARN Features
The Yet Another Resource Negotiator (YARN) was introduced in Apache Hadoop 2.0 to meet these needs and also solve scalability and management capacity issues that existed in the previous version of Hadoop. It is responsible for helping manage resources among the Clusters, taking on the responsibility for scheduling and resource allocation for the Hadoop System, tasks previously performed by the MapReduce JobTracker.
Today, Apache YARN has gained popularity due to the advantages it offers in scalability and flexibility, as well as its versatility and low cost, as it can be used on common hardware. It is successfully implemented at eBay, Facebook, Spotify, Xing, Yahoo, etc.
Among its main features, we highlight:
-
Multitenancy: A comprehensive set of limits is provided to prevent a single application, user, or queue from monopolizing the queue or Cluster resources, thus avoiding Cluster overload.
-
Docker for YARN: The Linux Container Executor (LCE) allows the YARN NodeManager to start YARN containers for execution directly on the host machine or within Docker containers.
Docker containers provide a custom execution environment in which the application code runs, isolated from the NodeManager's execution environment and other applications.
Docker for YARN provides consistency (every YARN container will have the same software environment) and isolation (no interference with what is installed on the physical machine).
-
Scalability: Apache YARN's scalability is known for scaling to thousands of nodes. It is determined by the Resource Manager and is proportional to the number of nodes, active applications, active containers, and heartbeat frequency (of nodes and applications).
-
High availability for components: Fault tolerance is a fundamental principle of Apache YARN. This responsibility is delegated to the Resource Manager (NodeManager and Application Master failures) and ApplicationMaster (container failures).
-
Flexible Resource Model: In Apache YARN, a resource request is defined in terms of memory, CPU, locality, etc., resulting in a generic definition. The capacity of NodeManager and Worker nodes is calculated based on the installed memory and CPU cores.
-
Multiple data processing algorithms: Apache YARN was developed to run on a wide variety of data processing algorithms. It is a framework for generic resource management and allows the execution of various algorithms over data.
-
Log aggregation and resource localization: To manage user logs, Apache YARN uses log aggregation. Once the application is completed, the NodeManager service aggregates the user logs related to an application and writes the aggregated logs into a single log file in HDFS.
-
Efficient and reliable resources: Apache YARN provides a generic resource management framework with support for data analysis through various data processing algorithms.
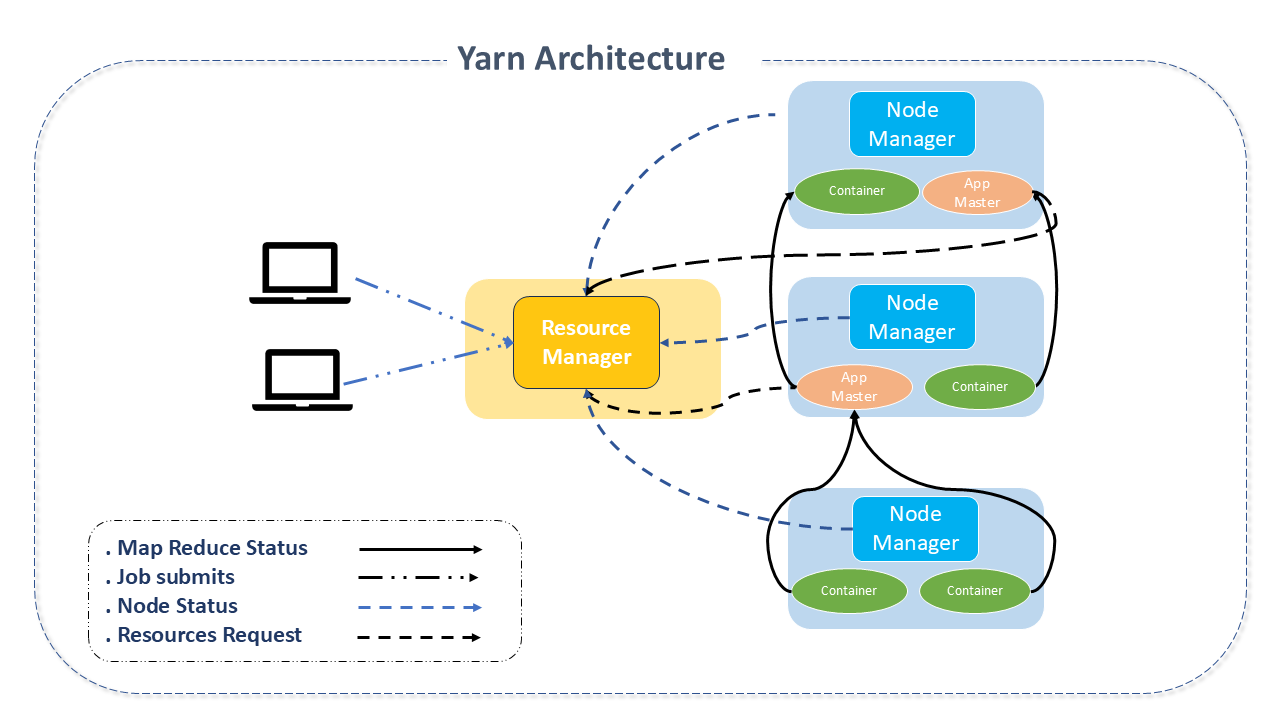
Apache YARN Architecture
Apache YARN consists of three components:
-
Resource Manager: It is the master node, responsible for resource management in the Cluster. It is the "ultimate authority" that arbitrates resources among all applications in the system.
There is one Resource Manager per Cluster, and it "knows" the location and resources of all slaves, which includes information such as GPU, CPU, and memory needed to run applications. The Resource Manager acts as a proxy between the client and all other nodes.
It has two main components:
-
Scheduler: Responsible for resource allocation for the various running applications.
The Scheduler does not monitor or track the application status and does not provide guarantees about restarting tasks affected by application or hardware failure. Its function is performed based on the resource requirements of the applications and the abstract notion of a resource container, which incorporates elements such as memory, CPU, disk, network, etc.
noteContainers are portions of resources (CPU, memory, etc.) of a Cluster machine that can be reserved for running an application, whether this application is Hadoop Map Reduce or not.
Starting from Hadoop version 2.0, the coordination of a Job does not occur on the Master node but in a container instantiated on a worker machine, which usually has two components (it may have three, in the case of the application management instance): Node Manager, Application Master, and DataNode.
The Scheduler has a "pluggable" policy responsible for partitioning the Cluster resources among various queues, applications, etc.
The Scheduler receives requests from the Application Masters for resources and performs its scheduling function. The scheduling strategy is configurable and can be chosen based on the needs of each application.
There are, by default, three schedulers in Apache YARN:
-
Scheduler FIFO: Uses the simple first-in, first-out strategy. Memory is allocated based on the request time sequence, with the first application in the queue receiving the necessary memory, then the second, and so on. If memory is not available, the applications will wait for availability. In this option, Apache YARN creates a request queue, adding applications to it and starting them one by one.
-
Capacity Scheduler: Ensures that the user gets the minimum amount of resources. Helps economically share the Cluster's resources among different users. In other words, the Cluster's resources are shared among various user groups. It works with the concept of queues. A Cluster is divided into partitions (queues), and each queue receives a percentage of resources.
-
Fair Scheduler: All applications get almost identical amounts of available resources. When the first application is sent to Apache YARN, it will allocate all available resources to it. If a new application is sent, Apache YARN starts allocating resources to it until both have almost the same amount. Unlike the previous ones, the Fair Scheduler prevents applications from running out of resources and ensures that all applications in the queue get the necessary memory for execution.
-
-
Application Manager: The main task of the Application Manager is to accept job submissions, negotiate the first container for executing the specific Application Master, and provide the service to restart the ApplicationMaster container when it fails.
-
-
NodeManager: Responsible for starting and monitoring job containers. It is the machine-level framework responsible for the containers, monitoring their resource usage and reporting to the ResourceManager/Scheduler.
-
Containers: Hadoop 2.0 improved its parallel processing with the addition of containers, which are an abstract concept that supports multitenancy on a data node.
This was how Hadoop found to define memory, CPU, network requirements: dividing the resources on the data server into containers. Thus, the data server can host multiple jobs, hosting multiple containers.
The Resource Manager is responsible for scheduling resources by allocating containers.
This is done based on an algorithm, from the input provided by the client, the Cluster's capacity, and the resource queues and prioritizations in the Cluster.
A general rule is to start the container on the same node as the data required by the job to facilitate its location.
-
-
Application Master: It is a framework-specific library responsible for negotiating resources from the ResourceManager and working with the NodeManager(s) to run and monitor jobs. Upon receiving an application, the ResourceManager will start the ApplicationMaster in an allocated container, which will communicate with the YARN Cluster to handle the application's execution. The main tasks of the ApplicationMaster are:
- Communicate with the ResourceManager to negotiate and allocate resources for future containers.
- After container allocation, communicate with NodeManagers to start the application's containers.
The Resource Manager and the Node Manager form the data computing framework.
The main idea of Apache YARN is to separate resource management and job scheduling/monitoring functionalities into separate daemons, thus existing a global ResourceManager (RM) and an ApplicationMaster (AM) per application. An application is a single job or a Directed Acyclic Graph (DAG) of jobs.
With the implementation of Apache YARN in Hadoop version 2.0, MapReduce maintains compatibility with the previous stable version (Hadoop version 1.x). All MapReduce tasks continue to be executed in Apache YARN.
Apache YARN Supported Features
-
Extensible Resource Model: Apache YARN supports an extensible resource model. By default, it tracks CPU and memory for all nodes, applications, and queues, but the resource definition can be extended to include "accountable" resources (resources consumed while the container is running but released later, such as memory and CPU), which means that the resource definition can be extended from its default values (such as CPU and memory) to any type of resource that can be consumed when the task "runs" in the container. Additionally, YARN supports the use of "resource profiles," allowing a user to specify multiple resource requests through a single profile, similar to Amazon Web Services Elastic Compute Cluster instance types. It is an easy way to request resources from a single profile and a means for administrators to regulate consumption.
-
Resource Reservation: Apache YARN supports resource reservation through the ReservationSystem, a component that allows the user to specify a resource profile over time and temporal constraints (e.g., deadlines) and reserve resources to ensure predictable execution of important jobs. The ReservationSystem tracks extra resources, performs admission control for reservations, and dynamically instructs the underlying Scheduler to ensure the reservation is met.
-
Federation: Apache YARN supports Federation through the YARN Federation feature, which allows transparently connecting multiple YARN (sub)Clusters and making them appear as a single massive Cluster. It can be used to achieve greater scale and/or allow multiple independent Clusters to be used together for very large jobs or for tenants who have capacity across all of them. The approach is to divide a large Cluster into smaller units called sub-clusters. Each unit has its own YARN Resource Manager and compute-node (Node_manager).
-
REST APIs: Apache YARN offers RESTful APIs to allow client applications to access different metric data such as Cluster metrics, schedulers, nodes, application state, priorities, resource managers, etc. It also provides information and statistics about the NameNode instance and statistics about applications and containers. These services can be used by remote monitoring applications. Currently, the following components support RESTful information:
- Resource Manager
- Application Master
- History Server
- Node Manager.
-
High Availability: A failure in the resource manager will cause a failure in Apache YARN, and therefore, it is important to implement high availability for the Resource Manager. The High Availability (HA) feature adds redundancy to remove single points of failure.
-
High Availability Resource Manager Architecture: The high availability of the Resource Manager works in an Active/Standby architecture. The Standby Resource Manager takes over when it receives the signal from ZooKeeper.
-
High Availability Resource Manager Features:
-
Resource Manager state storage: In case of failure, the Standby Resource Manager will reload the storage state and start from the last execution point. Cluster information will be rebuilt when the NodeManager sends a heartbeat to the new Resource Manager.
-
Resource Manager restart and failover: The Resource Manager loads the internal application state from the Resource Manager state storage. The Resource Manager's Scheduler rebuilds its cluster information state when the NodeManager sends a heartbeat. The checkpoint process avoids restarting already completed tasks.
-
Failover and fencing: In high availability YARN Clusters, there may be two or more Resource Managers in active/Standby mode. A split brain can occur when two Resource Managers assume themselves as active. If this happens, both will control Cluster resources and handle client requests. Failover fencing allows the active Resource Manager to restrict the operation of others. The previously discussed state storage provides the ZooKeeper-based ZKResourceManager StateStore, which allows only a single Resource Manager to write at a time.
-
Leader Elector: Based on the ZooKeeper ActiveStandbyElector, it is used to elect a new active Resource Manager and implement fencing internally. When a Resource Manager becomes inactive, a new Resource Manager is elected by the ActiveStandbyElector and will take over. If automatic failover is not enabled, the administrator must manually transition the active RM to standby mode and vice versa.
-
-
Nodelabels: It is a marker for each machine, so that machines with the same label name can be used in specific jobs.
Nodes with more powerful processing resources can be labeled with the same name, and then jobs requiring more machine power can use the same label during submission. Each node can have only one label assigned to it, meaning the Cluster will have a disjoint set of nodes. We can say that a cluster is partitioned based on node labels.
Apache YARN also provides features to define queue-level configuration, which defines how much of a partition or queue can be used. There are currently two types of node labels available:
-
Exclusive: ensures that it is the only queue allowed to access the node label. The application submitted by the queue with an exclusive label will have exclusive access to the partition so that no other queue can obtain resources.
-
Non-exclusive: allows sharing of idle resources with other applications. Queues receive node labels, and applications submitted to these queues will have priority over the respective node labels. If there is no application or job in a queue for these labels, resources will be shared among other non-exclusive node labels. If the queue with the node label submits an application or job during processing, resources will be taken from running tasks and assigned to the associated queues based on priority.
-
-
Node Attributes: They are a way to describe attributes of a node without guaranteeing resources. They can be used by applications to select the correct nodes for their container based on the expression of several such attributes.
-
Proxy Web Application: Its main purpose is to reduce the possibility of web-based attacks through Apache YARN.
-
Timeline Server and Timeline Server 2: The Timeline Server is responsible for storing and retrieving current and historical application information. It basically has two responsibilities:
- Persistence of application-specific information:
- Persistent generic information about completed applications.
Timeline Server 2 is the next major iteration of Timeline Server, created to address scalability issues and improve usability over Timeline Server 1.
Apache YARN Project Details
Apache YARN was developed in Javascript, Shell, PHP, TypeScript, and HTML.
Source(s): Hadoop.apache.org