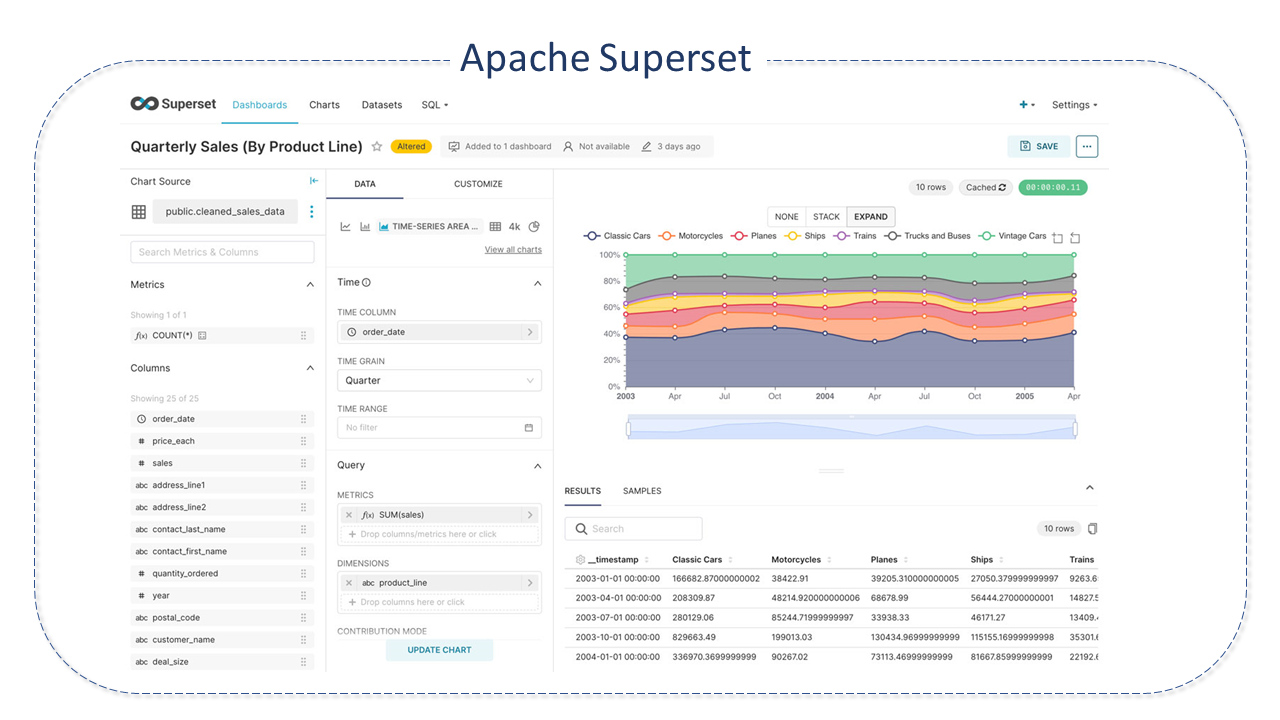
Apache Superset
Visualization
Data visualization consists of the graphical representation of information and data. Visual elements such as charts and maps facilitate the storytelling about specific data, making it more comprehensible, highlighting trends, exceptions, and generating new insights.
With the advent of "Big Data," it has become an incredibly relevant tool for interpreting and understanding the volume of data generated daily.
There are various tools for data visualization, among them is Apache Superset, a simple, easy-to-use tool that offers a range of options for all skill levels.
It is one of the best tools for data exploration and machine learning. Additionally, it offers a very user-friendly interface at a more affordable cost.
Features of Apache Superset
Built on popular open-source technologies such as JDBC and H2O, Apache Superset offers robust features for data visualization, exploration, and analysis. It is a fast, lightweight, intuitive business intelligence (BI) web application, filled with options that facilitate data exploration and visualization for users with any skill set.
It was created by Maxime Beauchemin, a data engineer, CEO, and founder of PRESET, who used an internal Airbnb hackathon (an event that brings together programmers, designers, and other software development professionals for a programming marathon) to create a BI tool from scratch.
The project, initially called "Caravel," became Apache Superset. Quickly adopted by dozens of companies, it increasingly took on more use cases. It was established as a complete open-source project and incubated with the Apache Software Foundation in 2016. Today, it is the leading open-source analytics platform, with one of the fastest-growing communities on GitHub.
Among its main features, we can cite:
-
Intuitive Interface: Allows visualizing data sets and creating interactive dashboards.
-
SQL IDE: Facilitates the preparation of data for visualization, including a rich metadata browser.
-
Security: It is one of its main advantages, as it offers complete control over data access. Allows adding users to the Database, providing access, and tracking behaviors.
-
Light Semantic Layer: Empowers data analysts to quickly define custom dimensions and metrics.
-
Support for SQL Databases: Compatible with most databases that use SQL.
-
Cache and Asynchronous Queries: Improves performance by reducing the direct query load on databases.
-
Extensibility: With complete access control to data, allowing the configuration of complex rules on who can access which resources and data sets.
-
Integration with major authentication backends: Such as OpenID, LDAP, OAuth, Remote_user, etc.
-
Ability to add custom visualization plugins.
-
API for programmatic customization.
-
Cloud Native Architecture: Designed for high availability and scalability in distributed environments.
- Designed for High Availability and Scale in large and distributed environments.
- Flexible in the choice of:
- Web Server (Gunicorn, Nginx, Apache),
- Metadata Database (MySQL, Postgres, MariaDB, etc),
- Message Queue (Redis, RabbitMQ, SQS, etc),
- Results Backend (S3, Redis, Memcached, etc),
- Cache Layer (Memcached, Redis, etc).
-
Works well within Containers.
-
Allows the creation of Interactive Queries: With selection of database, tables, and schema.
-
Requires no coding knowledge: Designed for people who do not know code, such as business and financial analysts.
-
Accessible via Web and App: That operate independently.
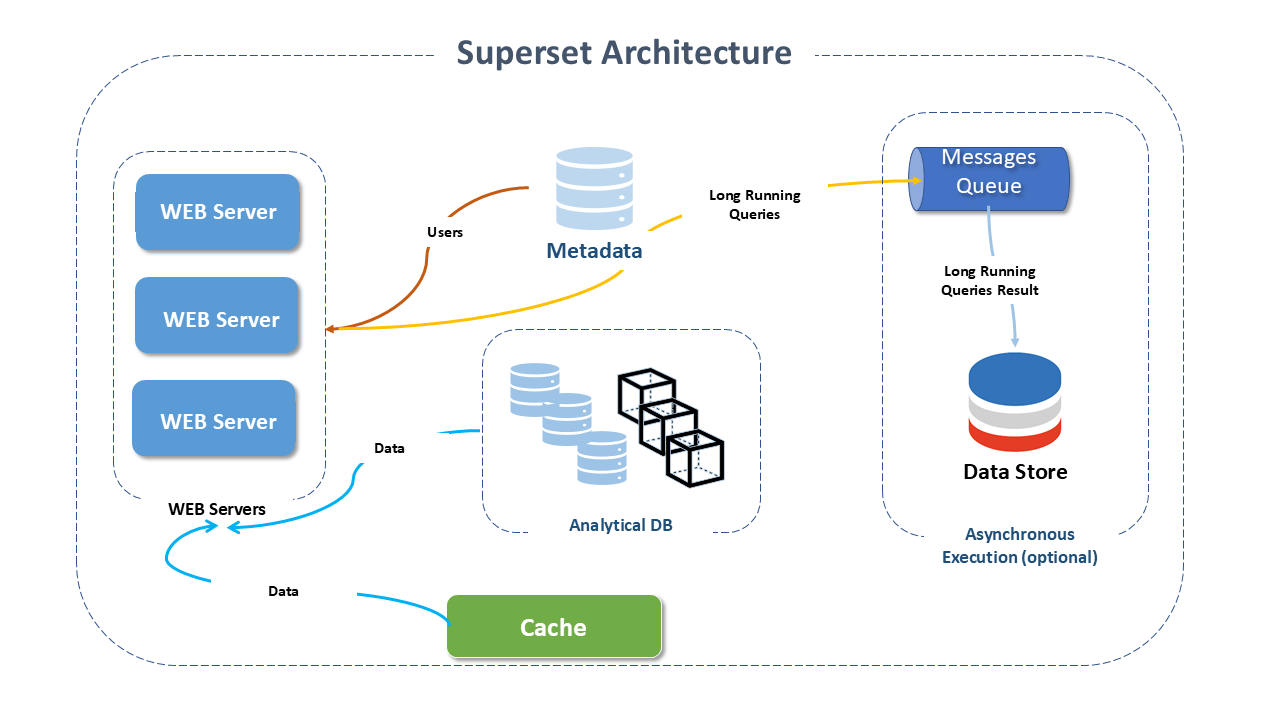
Architecture of Apache Superset
Apache Superset operates with a data-centered architecture, using a Dataset-Centric methodology that promotes the use of datasets similar to a Dataframe, that is, a tabular structure enriched with a subset of semantic features.
Apache Superset can be run in sequential mode for quick queries or distributed mode, where it distributes queries among workers.
The main components involved in the Apache Superset solution are:
- Web Servers: Flask Python app used to connect to any database. Superset allows the choice of the Web Server and integrates with various options, such as Gunicorn, NGINX, Apache HTTP. The Superset web servers and the optional Superset Celery workers can expand to as many servers as needed.
- Metadata Database: (Metadata Database): Superset allows the choice of the metadata database engine and integrates with various options, such as MySQL, Postgres, MariaDB, etc.
- Cache Layer: Superset allows the choice of the cache layer and integrates with various options like Memcached, Redis, etc.
- Message Queue for async queries: Superset allows the choice of the message queue and integrates with various options like S3, Redis, Memcached, etc.
- Results Backend: For storing and retrieving query results.
- Dashboard and Slices: The Dashboard is a user interface that allows viewing various charts and data. Each section within the Dashboard is called a Slice, which in turn can be in various formats: text, chart, or, for example, a function.
- SQL Lab: SQL Lab is an SQL IDE with a wide range of features, with which it is possible to convert data into charts, for example.
Superset works very well with metric and statistics services like NewRelic, StatsD, DataDog, and has the capability to perform analytical workloads on the most popular Database technologies.
Currently, it runs at scale in many companies, for example, in the Airbnb production environment, where, within Kubernetes, it serves more than 600 active daily users who view over 100,000 charts per day.
The main sectors and companies that adopt Superset can be seen here.
Resources of Apache Superset
Superset is enriched with features that support everything from creating dynamic visualizations to complex analyses, offering:
- Custom visualizations to explore and understand the data.
- SQL queries on the SQL Tab for data investigation.
- Code-free visualization building, or the SQL IDE for quick data integration and analysis.
- Lightweight and scalable data ingestion that works on existing data infrastructure, without requiring a separate ingestion layer.
- Basic semantic layer, where it is possible to control how data sources are displayed and handled.
Integration with Databases
Superset provides functionalities for connecting with various databases. It connects with almost all major databases, which facilitates the visualization and analysis of your data. It is compatible with Apache Spark SQL, PostgreSQL, Google Sheets, Amazon Athena, Amazon Redshift, Azure MS SQL, etc.
Types of Visualization
Apache Superset provides a wide variety of charts, tables, and layouts. Some examples are:
- Scatter Plot.
- Grids.
- Polygons.
- Path.
- Screen Grids.
- Arcs.
Details of Project Apache Superset
Developed predominantly in Python, Apache Superset also uses technologies such as Typescript and Flask App Builder internally. It supports Python version > 3.6 and can be installed in a variety of methods. The most common are:
- locally: where Python must be installed first and then pip installs the dependencies.
- virtually: Installation in a virtual environment is strongly recommended. Pyenv-virtualenv can be installed if pyenv is being used.
- Docker: The simplest way to experiment with Superset locally is using Docker and Docker Compose on Linux or Mac OSX.