Apache Flink
Distributed Computing Engines
The concept of distributed computing is not new and has become even more well-known with the "explosion" of data in recent years and the growing need to process large flows of information with predictive capabilities.
Among its main benefits, we can mention the ability to add more processing nodes (scalability), in proportion to the growth of data, without compromising the performance or availability of systems, and the ability to process in real-time - the distribution of work across several nodes streamlines and provides efficiency to decision-making.
In the Big Data era, several programming models and frameworks emerged for executing batch jobs in an optimized and distributed way, such as Map Reduce and others, with the ability to process data on a large scale, in parallel, and with fault tolerance, which are very useful for ETL (Extract, Transform, Load), like Apache Hadoop, Apache Spark, Apache Beam, and Apache Flink.
Another way of processing data arising from the Big Data era is streaming, a type of data processing "engine" designed to handle infinite datasets (data arises infinitely and there is no guarantee of the order of arrival). Among the main distributed processing frameworks/engines coded for streaming, we can mention Apache Flink, Apache Storm, Apache Flume, and Apache Samza. These mechanisms receive messages by reading a messaging system (source) - such as Apache Kafka - process them in real-time, filtering those that contain the desired data, and sending them to an output.
Apache Flink
Apache Flink is a framework and distributed processing engine for stateful computation (functions that assume a state and return a new state) of unlimited and limited data streams. It was created by the research team at Berlin Technical University, led by Stephan Ewen. It started as an academic project called Stratosphere, around 2009. In 2014, the project was incorporated into the Apache Software Foundation, becoming an incubation project. It was later promoted to a top-level Apache project. Since then, Flink has evolved significantly, becoming one of the leading platforms for real-time data stream processing.
Apache Flink Features
Apache Flink supports multiple notions of time for state-based stream processing.
Among its main features, we highlight:
-
State processing: Manages complex states, even in large-scale operations.
-
Correctness and consistency: Offers data accuracy guarantees (exactly-once).
-
Event-time processing: Allows handling real-time data, considering the time when events occur.
-
Layered APIs: Modular and flexible approach to building applications. It provides several APIs at different levels of abstraction, including SQL, DataStream, and DataSet:
- DataStream API: Used for real-time data stream processing applications.
- DataSet API: Aimed at batch data processing.
- SQL and Table API: Allows users to write queries in SQL or a similar table language for data manipulation.
These APIs allow developers to choose the level of abstraction that best suits their needs.
Apache Flink Architecture
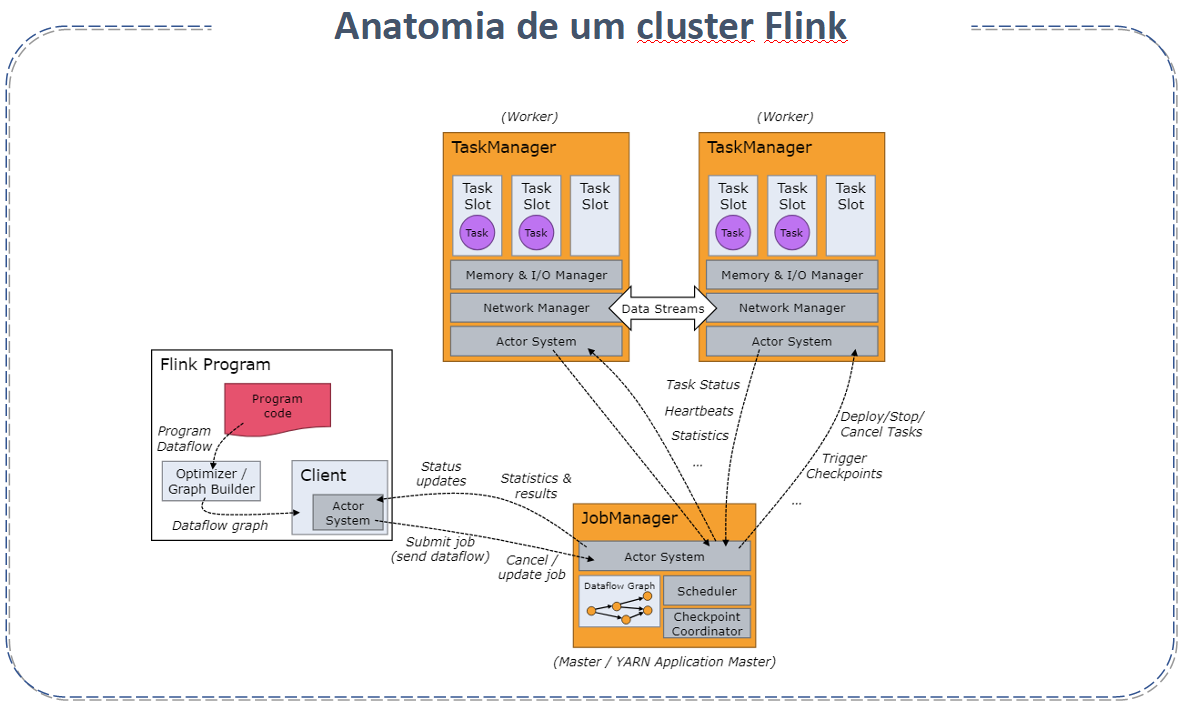
The architecture of Apache Flink is composed of several components:
- JobManager: Coordinates the distribution of tasks and resource management. It also handles checkpointing to ensure fault tolerance.
- TaskManager: Executes the tasks (or jobs) effectively. Each TaskManager can execute multiple tasks simultaneously.
- Dispatcher: Offers a REST interface to submit Flink applications and start a new JobMaster for each job, in addition to running the Flink WebUI.
- Flink Client: Prepares and sends a data stream to the JobManager. It can disconnect or remain connected to receive progress reports.
- Resource Manager: Responsible for resource allocation and provisioning in the Flink cluster, managing task slots.
- JobMaster: Manages the execution of a single JobGraph.
- Sources and Sinks: Connect with external storage systems for data input and output.
This architecture allows for distributed and scalable processing of large volumes of data. For more detailed information, visit the official Apache Flink documentation at Apache Flink Architecture.
Apache Flink Resources
- Stream and batch analysis: Supports both real-time and batch processing.
- Event-driven applications: Ideal for systems that react to events in real-time.
- High performance: Designed to be fast, with low latency and high throughput.
When to use Apache Flink
- Apache Flink is ideal for applications that require real-time data stream processing and event analysis.
- It is recommended for scenarios with fault tolerance requirements and data consistency guarantees.
- It is suitable for systems that require large-scale data processing with low latency.
When Apache Flink is not applicable
- Apache Flink is not the best option for simple data manipulation projects where lighter solutions, such as scripts or traditional ETL tools, would suffice.
- It can be excessive for applications that do not require advanced data stream processing or real-time analysis capabilities.
- It is less efficient for tasks where batch processing, without the need for real-time processing, is sufficient.
Main differences between Apache Spark and Apache Flink
- Processing Model: One of the main differences between the two tools is the processing model. Spark uses the RDD (Resilient Distributed Datasets) data processing model - a distributed and immutable collection of objects. Apache Flink uses the stream-based data processing model - a collection of events processed in real-time as they arrive.
- Speed: Apache Flink is generally faster than Apache Spark for real-time data processing, because its processing model eliminates the need to transform data into RDDs before processing it.
- Fault tolerance: Both tools are fault-tolerant, but Spark uses a disk-based checkpointing mechanism to maintain data integrity, and Flink uses a memory-based approach, storing data in cache, which allows faster recovery in case of failures.
- Support for complex events: Apache Flink offers native support for complex event processing, which allows the analysis of patterns and correlations in real-time data streams, unlike Spark, which requires additional libraries and configuration adjustments.
In short, Apache Spark is often used for batch data processing and applications that do not require very low latency, such as log analysis and historical data processing. Apache Flink is often used for real-time data processing, such as fraud analysis and IoT monitoring.
Main differences between Apache Storm and Apache Flink
The comparison between Apache Flink and Apache Storm involves several aspects:
- Use: Flink is more for unified batch and stream processing, while Storm is focused on real-time stream processing.
- Data Processing: Apache Flink offers batch and stream data processing; Storm is great for stream processing.
- Data Transformation: Apache Flink has rich options for data transformation; Storm is more limited.
- Machine Learning Support: Apache Flink supports Machine Learning, while Apache Storm does not.
- Query Language: Apache Flink uses a language similar to SQL; Storm does not have a native query language.
- Deployment Model: Both offer different deployment options.
- Integration with Other Services: Both integrate well with other services.
- Scalability: Apache Storm excels in high scalability.
- Performance and Reliability: Both have good performance and are reliable.
Best Practices for Apache Flink
- Efficient State Management: Structure and manage states efficiently to optimize performance and ensure data consistency.
- Performance Optimization: Monitor performance metrics, fine-tune settings, and use data partitioning strategies to maximize efficiency.
- Failure Recovery Strategies: Implement robust checkpointing and recovery strategies to ensure fault tolerance.
- Scalability and Load Balancing: Develop applications with scalability in mind, ensuring effective load balancing between cluster nodes.
- Testing and Validation: Perform extensive testing to ensure the reliability and accuracy of Flink applications in different scenarios.
- Updates and Maintenance: Stay up-to-date with the latest Flink versions and best practices to leverage improvements and fixes.
Apache Flink Project Details
Apache Flink is predominantly used with the Java programming language. It also offers support for Scala, as its Scala API integrates seamlessly with the Java API. Additionally, for data query operations, Flink supports SQL through its Table and SQL API. This flexibility allows developers to choose the language that best suits their needs and preferences.
Sources: