Apache MapReduce
Apache MapReduce é um framework desenvolvido para escrever aplicativos que processam grandes quantidades de dados em grandes clusters de hardware comum. Ele assegura confiabilidade, paralelismo, tolerância a falhas e facilita o data locality (possibilidade de um programa executar onde os dados estão armazenados).
O MapReduce foi desenvolvido a partir de uma tecnologia divulgada pelo Google, criada por Jeffrey Dean e Sanjay Ghemawat, para otimizar a indexação e catalogação de dados da web.
Apesar de o Hadoop ter evoluído desde sua versão inicial, o fluxo de alto nível do processador MapReduce manteve-se constante.
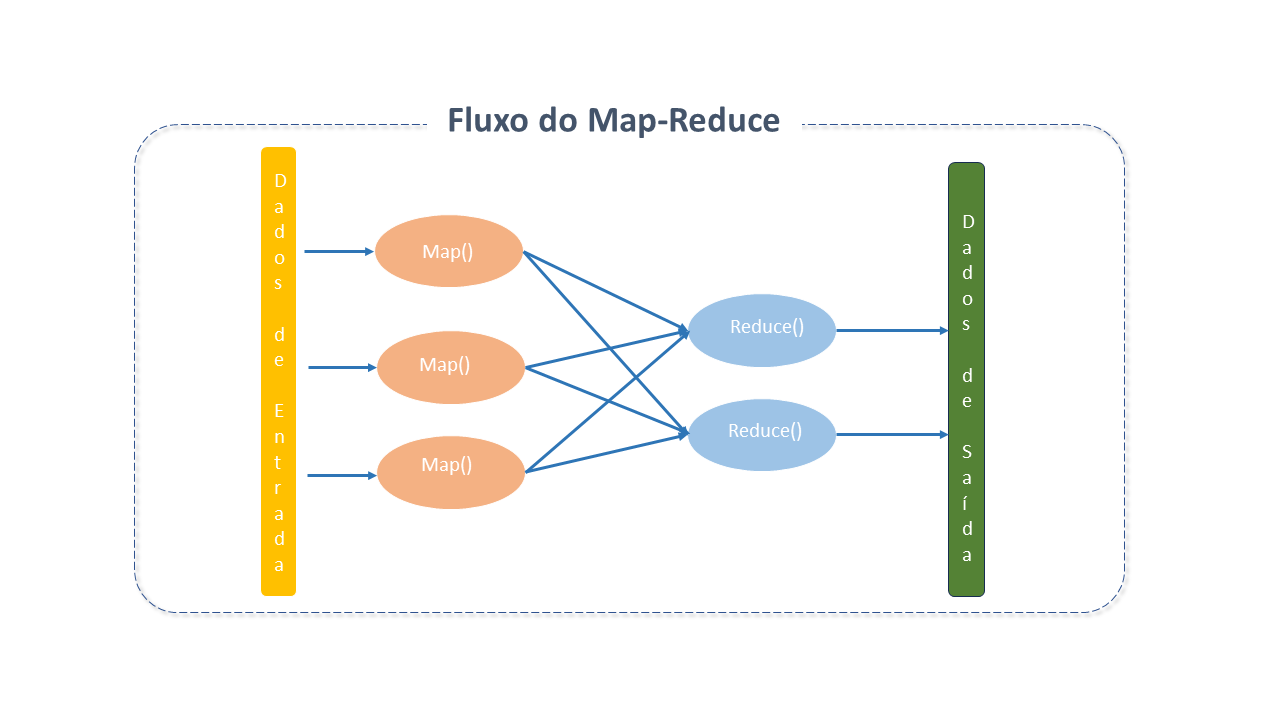
Arquitetura do Apache MapReduce
O MapReduce organiza o processamento em dois processos principais — Map e Reduce — com várias tarefas menores integradas ao fluxo do processo. Um trabalho MapReduce tipicamente divide o dataset de entrada em partes independentes processadas em paralelo pelas tarefas Map. Os resultados são então classificados e passados para as tarefas Reduce.
A entrada e a saída do job normalmente são armazenadas em um sistema de arquivos. Geralmente, os nós de computação e armazenamento são os mesmos, permitindo uma programação eficiente das tarefas nos nós onde os dados estão armazenados, resultando em maior largura de banda do cluster.
O framework MapReduce inclui um único Resource Manager master, um NodeManager worker por nó do cluster e um MRAppMaster por aplicação.
Os aplicativos especificam locais de entrada e saída e fornecem funções de map e reduce por meio de interfaces ou classes abstratas apropriadas. Esses e outros parâmetros do job formam a configuração do job.
O cliente submete o job (jar/executável, etc.) e a configuração para o ResourceManager, que gerencia a distribuição aos workers, o agendamento das tarefas e o monitoramento, fornecendo status e diagnósticos.
Entradas e Saídas
MapReduce funciona exclusivamente com pares chave-valor, tratando a entrada como um conjunto de pares e produzindo um conjunto de pares como saída. As classes de chave e valor devem ser serializáveis, implementando a interface WritableComparable para facilitar a ordenação.
Componentes do Processo
-
InputFileFormat: O processo do MapReduce inicia com a leitura do arquivo armazenado no HDFS, que pode ser de qualquer tipo e cujo processamento é controlado pelo Inputformat.
-
RecordReader e Input Split: O arquivo é dividido em "partes" que são conhecidas como input split. Seus tamanhos são controlados pelos parâmetros mapred.max.split.size e mapred.min.split.size. Por default, o tamanho do input split é o mesmo que o do bloco e não pode ser mudado, exceto em casos muito específicos. Para arquivos com formato não-divisíveis, como .gzip, o input split será igual ao tamanho do arquivo.
A função RecordReader é responsável por ler dados do input split armazenado no HDFS. O formato default é TextInputFileFormat e o delimitador do RecordReader é /n, o que significa que apenas uma linha será tratada como um registro pelo RecordReader. Algumas vezes o comportamento do RecordReader pode ser customizado, com a criação de um RecordReader proprio.
-
Mapper: A classe Mapper é responsável pelo processamento do input split. A função RecordReader passa cada registro lido para a função Map do Mapper. O Mapper contém os métodos setup e cleanup.
- O setup é executado antes do processamento do Mapper e, portanto, qualquer operação de inicialização deve ser feita dentro dele.
- O método de limpeza cleanup é executado assim que todos os registros na input split forem processados e, portanto, qualquer operação de limpeza deve ser executada dentro dele.
O Mapper processa os registros e emite a saída (output) usando o object context, que habilita o Mapper e o Reducer a interagir com outros sistemas Hadoop, permitindo, ainda, a comunicação entre Mapper, Combiner e Reducer.
- Os pares de saída não precisam ser do mesmo tipo que os de entrada.
- Os aplicativos podem usar o counter para relatar suas estatísticas.
- O número de mapas geralmente é determinado pelo tamamho total de entradas (número total de blocos dos arquivos de saída).
-
Partitioner: O Partitioner atribui um número de partição ao registro emitido pelo Mapper para que os registros com a mesma chave obtenham sempre o mesmo número de partição, assegurando que os registros com a mesma chave sempre irão para o mesmo Reducer.
-
Shuffling e Sorting: O processo de transferir dados do Mapper para o Reducer é conhecido como shuffling. O Reducer inicia threads para leitura de dados da máquina Mapper e lê todas as partições que pertencem a ela para processamento usando o protocolo HTTP.
-
Reducer: O número de Reducers que o Hadoop pode ter depende do número de saídas do Map e vários outros parâmetros, e isto pode ser controlado.
O Reducer contém reduce() que é executado para cada chave única emitida pelo Mapper.-
O número total de reduções geralmente é calculado como :
(0,95 ou 1,75) * (num. de nós * núm máximo de contentores por nó.
noteCom 0,95 todas as reduções podem ser iniciadas imediatamente e começar a transferir as saídas do mapa à medida que terminam. Com 1,75 os nós mais rápidos terminarão sua "primeira rodada" de reduções e lançarão uma segunda onda, fazendo um melhor trabalho de balanceamento de cargas.
-
-
Combiner: Também chamado mini reducer ou localized reducer é um processo executado nas máquinas Mappers que obtém a chave intermediária emitida pelo Mapper e aplica a função reduce definida pelo usuário do Combiner na mesma máquina.
Para cada Mapper existe um Combiner disponível na máquina Mappers. O Combiner reduz significativamente o volume de data shuffling entre Mapper e Reducer e ajuda, portanto, na melhoria da performance. Entretanto, não há garantia que sejam executados. -
Output format: Traduz o par final chave/valor da função Reduce e o grava em um arquivo, no HDFS, por meio do record writer . Por default, os valores chave de saída são separados por tab e os registros são separados por um caracter newline. Isto pode ser modificado pelo usuário.
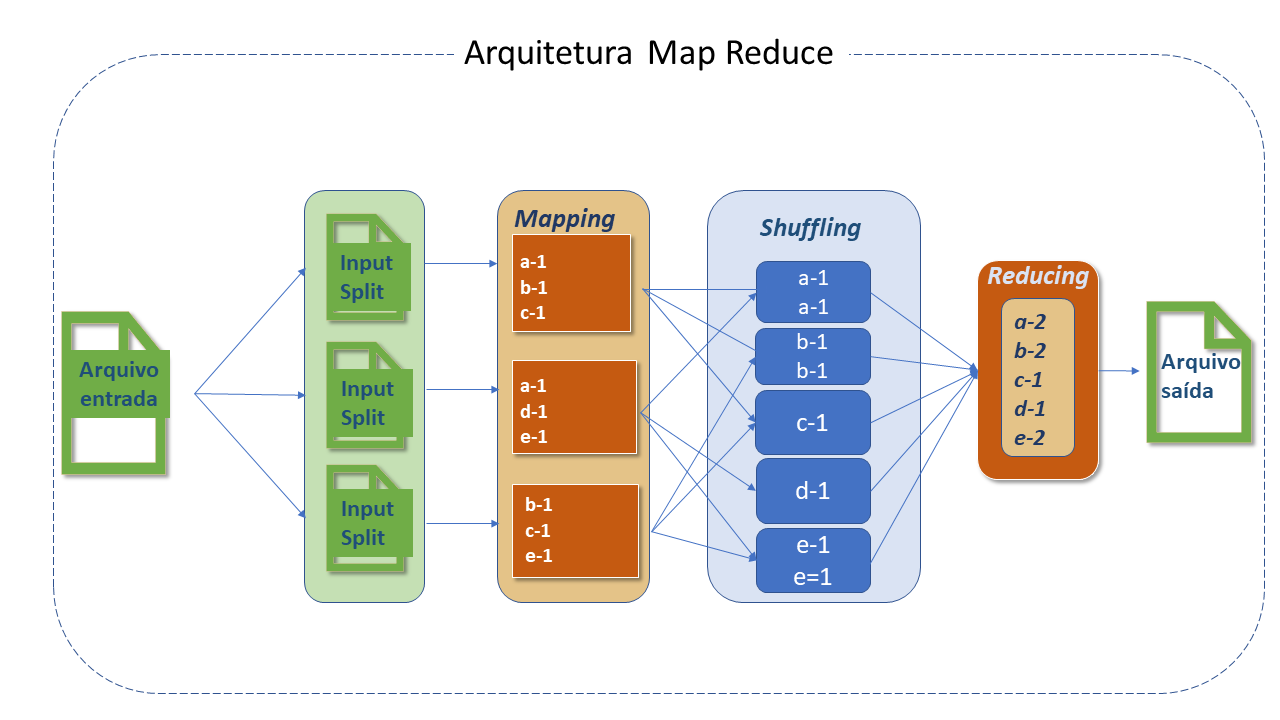
Padrões do Apache MapReduce
Existem soluções de template desenvolvidas por pessoas que resolveram problemas específicos, e que podem ser reutilizados:
-
Padrões de "sumarização":
- Contagem de palavras.
- Minimo e máximo
-
Padrões de "filtragem":
- Algoritmo reduce "top-k": Algoritmo popular do MapReduce em que os mapeadores são responsaveis por emitir os registros tok-k em seu nível e, em seguida, o redutor filtra os registros top-k de todos os recebidos do mapeador.
-
Padrões de "junção":
-
Reduce side join: processo onde a operação de "junção" é feita na fase "reducer". Mapper lê o dado de entrada que é combinado baseado em uma coluna comum ou uma chave de junção.
-
Junção Composta:
- Classificação e particionamento
-
Boas Práticas para o Apache MapReduce
-
Configuração do Hardware:
- A configuração do Hardware é muito importante para a performance. Um sistema com mais memória sempre apresentará melhor desempenho.
- A largura de banda também é crítica, uma vez que os job MapReduce podem exigir shuffling de dados de uma máquina para outra.
-
Tunning do Sistema Operacional:
-
Transparent Huge Pages (THP): Máquinas usadas no Hadoop devem ter o THP desabilitado. O THP não funciona bem em um cluster Hadoop e causa alto custo de CPU. A recomendação é desabilitá-lo em cada nó do job.
-
Evitar swapping de memória desnecessária: No Hadoop, o swapping pode afetar a performance de jobs e deve ser evitado a menos que seja absolutamente necessário. A configuração de swappiness pode ser definida como 0(zero).
-
Configuração da CPU: Na maioria dos Sistemas Operacionais, a CPU é configurada para economizar energia e não é otimizada para sistemas como o Hadoop. Por padrão, o scaling governor está configurado para o modo de economia de energia e precisa ser alterado com o seguinte comando:
Terminal inputcpufreq-set -r -g
-
-
Ajustes na rede: O shuffling consome um tempo significativo do Hadoop pois demanda a conexão master e worker com muita frequência. O net.core.somax.conn deve ser definido com um valor mais alto, o que pode ser feito adicionando ou editando
/etc/sysctl.confno arquivonet.core.somaxconn=1024. -
Escolha do sistema de arquivos:
- A distribuição Linux vem com um sistema de arquivos padrão projetado para cargas intensas de E/S, o que pode impactar de forma significativa o desempenho do Hadoop. A distribuição mais recente do Linux vem com o
EXT4como sistema de arquivos padrão, que funciona melhor que oEXT3. - O Sistema de arquivos registra o último horário de acesso para cada operação de leitura no arquivo, e, portanto, causa uma gravação em disco para cada leitura. Esta configuração pode ser desabilitada adicionando um atributo noatime à opção file system mount. Alguns casos de uso observaram uma melhoria de desempenho em mais de 20% com o noatime.
- A distribuição Linux vem com um sistema de arquivos padrão projetado para cargas intensas de E/S, o que pode impactar de forma significativa o desempenho do Hadoop. A distribuição mais recente do Linux vem com o
-
Otimizações:
-
Combiner: O shuffling dos dados pela rede pode ser caro pois a transferência de mais dados sempre consumirá mais tempo de processamento.
O reduce não pode ser usado em todos os casos de uso, mas na maioria dos casos podemos usar o Combiner, que reduz o tamanho dos dados que serão transferidos pela rede durante o shuffling pois atua como um mini reduce e é executado na máquina dos Mappers. -
Compactação do Map output: O Mapper processa a saída e a armazena no disco local.
Quando gera uma grande quantidade de saídas, este resultado intermediário pode ser compactado com a função LZO, reduzindo I/O no disco durante o shuffling.
Isto é feito definindo omapred.compress.mapoutputcomotrue. -
Filtro de registros: Filtrar registros no lado do Mapper resulta em menos dados gravados no disco local e maior rapidez nas próximas etapas (com menos dados para operar).
-
Evitando muitos arquivos pequenos: Arquivos muito pequenos podem exigir muito tempo para executar.
O HDFS armazena estes arquivos como um bloco separado, o que pode sobrecarregar o processamento dos arquivos com a inicialização de muitos Mappers.
É uma boa prática compactar arquivos pequenos em um único arquivo grande e então executar o MapReduce nele.
Em alguns casos isto pode trazer uma otimização em 100% da performance. -
Evitando formato de arquivo não divisível: O formato não divisível (p.ex: gzip) é processado de uma só vez.
Se forem arquivos muito pequenos, consumirá muito tempo, pois para cada arquivo, um Mapper será iniciado.
A melhor prática é usar um formato divisível como Texto, AVRO, ORC, etc.
-
-
Configurações Runtime
-
Memória Java: Map e Reduce são processos JVM que, portanto, usam memória JVM para execução.
O tamanho da memória pode ser ajustado na propriedade mapred.child.java.opts. -
Memória Map spill: Os registros de saída do Mapper são armazenados num buffer circular cujo tamanho default é 100MB.
Quando a saída excede 70% deste tamanho, os dados serão levados para o disco.
Para aumentar a memória do buffer, use a propriedade io.sort.mb. -
Ajuste no Map: O número de Mappers é controlado pelo mapred.min.split.size.
Se existirem muitas tarefas executando uma após a outra, é ideal configurar mapred.job.reuse.jvm.num.tasks para -1.
warningIsto deve ser usado com muito cuidado pois em caso de tarefas com longa execução, a sobrecarga de JVM não aumentará o desempenho, pelo contrário.
-
-
Otimização do File System:
-
Mount option: Existe algumas opções de montagem eficientes para clusters Hadoop, como por exemplo o noatime configurado para Ext4 e XFS.
-
Tamanho do bloco HDFS: O tamanho do bloco é importante no desempenho do NameNode e da execução do job.
O Namenode mantém os metadados para cada bloco que armazena no Datanode e, portanto, ocupa muita memória em tamanhos de bloco muito menores que o recomendado.
O valor recomendado para dfs.blocksize deve estar entre 134.217.728 e 1.073.741.824. -
Leitura short circuit: A operaçao de leitura do HDFS passa pelo DataNode, que, após a solicitação do cliente, envia os dados do arquivo pelo socket TCP para o cliente.
Na leitura short circuit o cliente lê diretamente o arquivo, e, portanto, ignora o DataNode.
Isto só acontece se o cliente estiver no mesmo local que os dados. -
Stale Datanode: O Datanode envia um heartbeat para o Namenode em intervalos regulares para informar que está ativo.
Para evitar enviar solicitações de leitura e gravação para os Datanodes inativos, a adição das propriedades abaixo no hdfs-site.xml é eficiente:Terminal input_dfs.namenode.avoid.read.stale.datanode=trueTerminal input_dfs.namenode.avoid.write.stale.datanode=true
-
Detalhes do Projeto Apache MapReduce
Embora o Hadoop seja implementado em Java, os aplicativos MapReduce podem usar qualquer linguagem que suporte Hadoop Streaming ou Hadoop Pipes.
Fontes: