Apache NiFi
Data Flow Automation
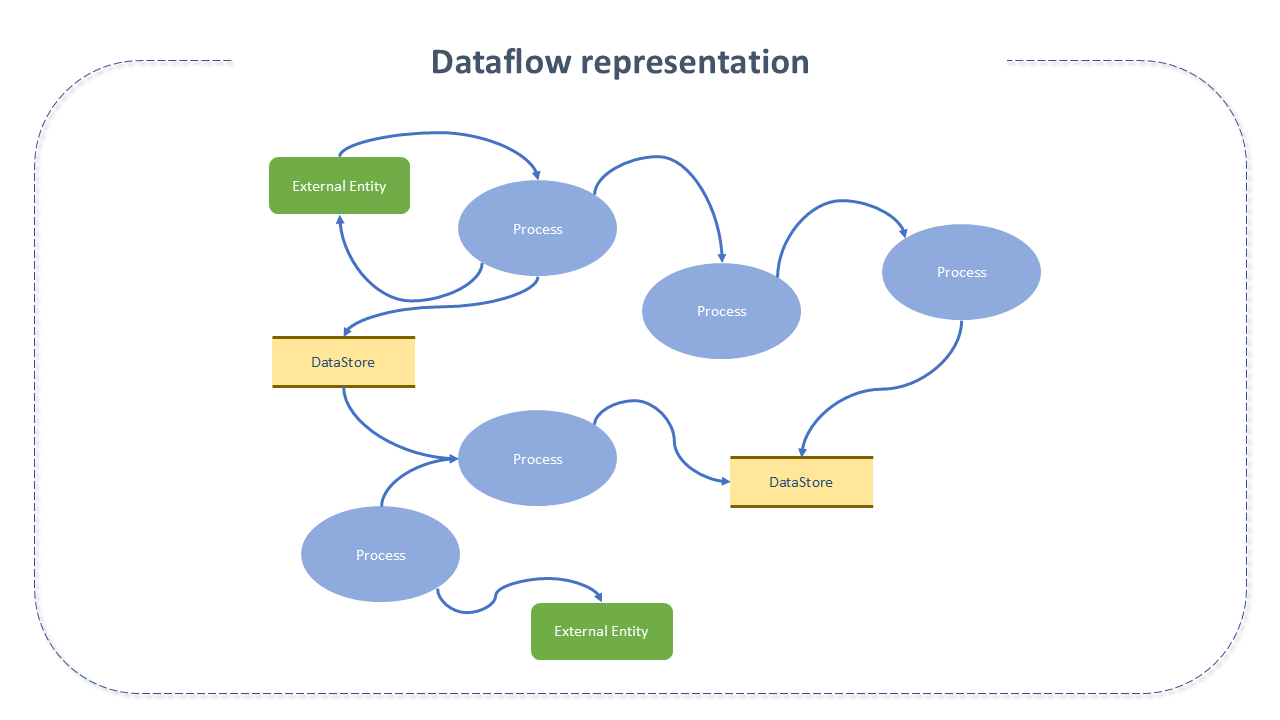
Data flow automation is a software paradigm based on the idea of computing as a directed graph, representing the automated and managed flow of information between systems.
Data flow automation helps in capturing, building, and collaborating at scale through automated tools, ensuring greater system efficiency through optimized and controllable reports.
Features of Apache NiFi
NiFi was built to automate data flows, support and meet the level of rigor necessary to achieve compliance, privacy, and security in data exchange between systems.
NiFi has become especially valuable for edge solutions that have emerged in recent years, for which data flow is vital, such as SOA (Service Oriented Architecture), APIs (Application Protocol Integration), IoT (Internet of Things), and Big Data.
The fundamental design concepts of Apache NiFi are closely related to the ideas of Flow Based Programming - fbp.
| NiFi Term | FBP Term | Description |
|---|---|---|
| FlowFile | Packet Information | The FlowFile represents each object moved between/within systems. |
| FlowFile Processor | Black Box | It is the Processors that actually perform the work. |
| Connection | Bounded Buffer | Connections provide the actual link between processors. |
| Flow Controller | Scheduler | Provides threads for extensions to execute and manages the schedule for when extensions receive resources for execution. |
Table D - NiFi - Concepts Associated with FBP
This design model makes the NiFi platform very effective for building powerful and scalable data flows, enabling:
- Visual creation and management of directed graphs (with directions associated with each edge) of processors.
- High throughput and a natural data buffer, despite fluctuations in processing and flow rates.
- Highly concurrent models, with the ability to execute several distinct tasks simultaneously (or apparently simultaneous), allowing the developer to disregard the typical complexities of this topic.
- The development of cohesive, low-coupling components, reusable in other contexts, and testable units.
- The simplification of critical data functions, such as back-pressure and pressure release, becoming natural and intuitive (through the constrained connections feature).
- Error handling as naturally as the happy path.
- Easy understanding and tracking of points where data "enters" and "exits" the system.
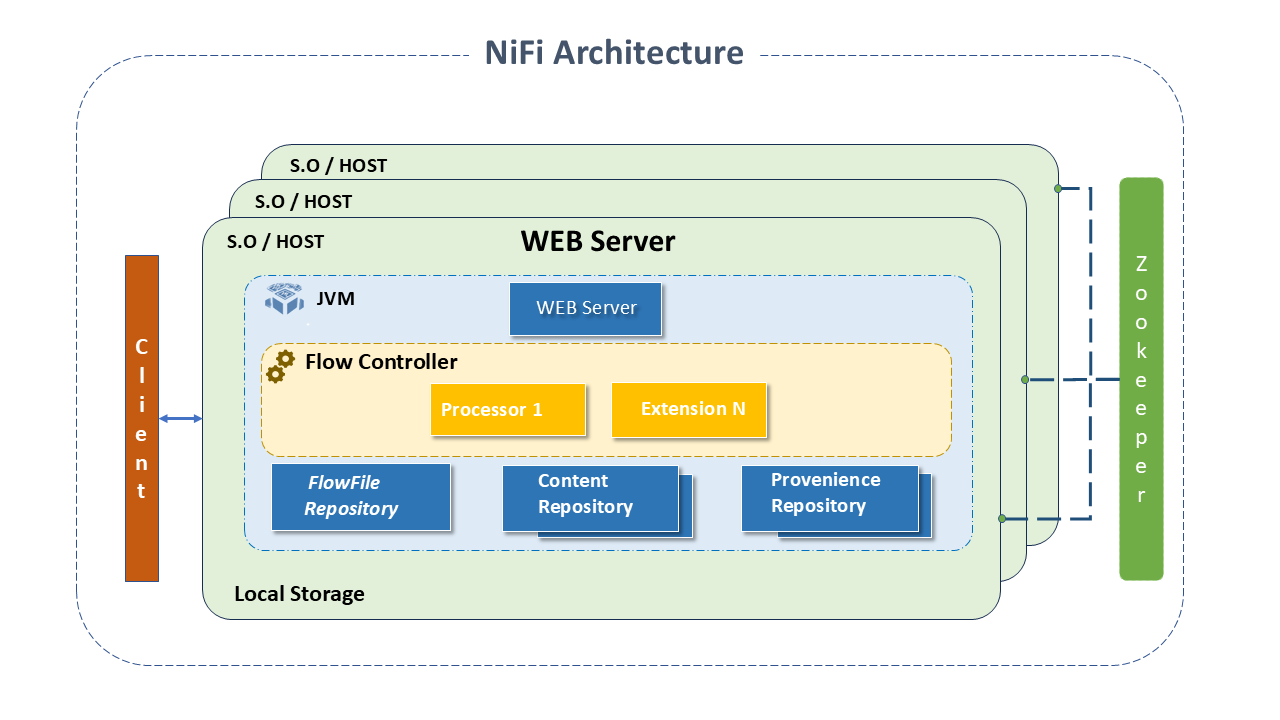
Apache NiFi Architecture
NiFi runs within a JVM virtual machine, on a host operating system. Its main components in the JVM are:
- Web Server: Executes visual control and monitors events. Hosts the HTTP-based command and control API.
- Flow Controller: The "brain" of the operation. Provides threads for extensions to execute and manages the schedule for when extensions receive resources for execution.
- Extensions: Plugins that allow interaction between NiFi and other Systems. NiFi provides several "extension" points for developers to add functionalities. All operate and execute within the JVM:
- Processor: The processor interface provides access to FlowFiles, their attributes, and contents.
- ReportingTask: Provides metrics, monitoring information, and the internal state of NiFi to endpoints such as log files, email, and remote web services.
- ParameterProvider: Provides parameters for use by external sources.
- ControllerService: Provides a mechanism to create services shared among all Processors, ReportingTasks, and other ControllerServices in a single JVM.
- FlowFilePriorizer: Provides a mechanism by which FlowFiles in a queue can be prioritized or sorted for subsequent processing in a more effective order in case of specific use.
- AuthorityProvider: Determines what privileges and roles, if any, should be granted to a given user.
- FlowFile Repository: Where NiFi keeps/tracks the status of active FlowFiles. The repository implementation is pluggable. The default is a persistent write-ahead log located on a specific disk partition.
- Content Repository: Where data "in transit" is kept. It is pluggable. The default approach is a simple mechanism that stores data blocks on the file system. More than one file system storage location can be specified to involve different partitions in reducing contention on any single volume.
- Provenance Repository: Stores all information about the provenance of data that circulates through the system. The repository is pluggable, with the default implementation using one or more physical disk volumes. Within each location, event data is indexed and enabled for search.
NiFi is also enabled to operate within a Cluster.
Since NiFi version 1.0, NiFi employs the Zero-Leader paradigm: each NiFi Cluster node performs the same tasks on the data, but each operates on a distinct data set.
Apache Zookeeper elects a single node as the Coordinator. All Cluster nodes report heartbeat and status to the Coordinator, who is responsible for disconnecting and connecting nodes.
Additionally, every Cluster has a primary Node, also elected by Zookeeper.
Failover is handled automatically by Zookeeper.
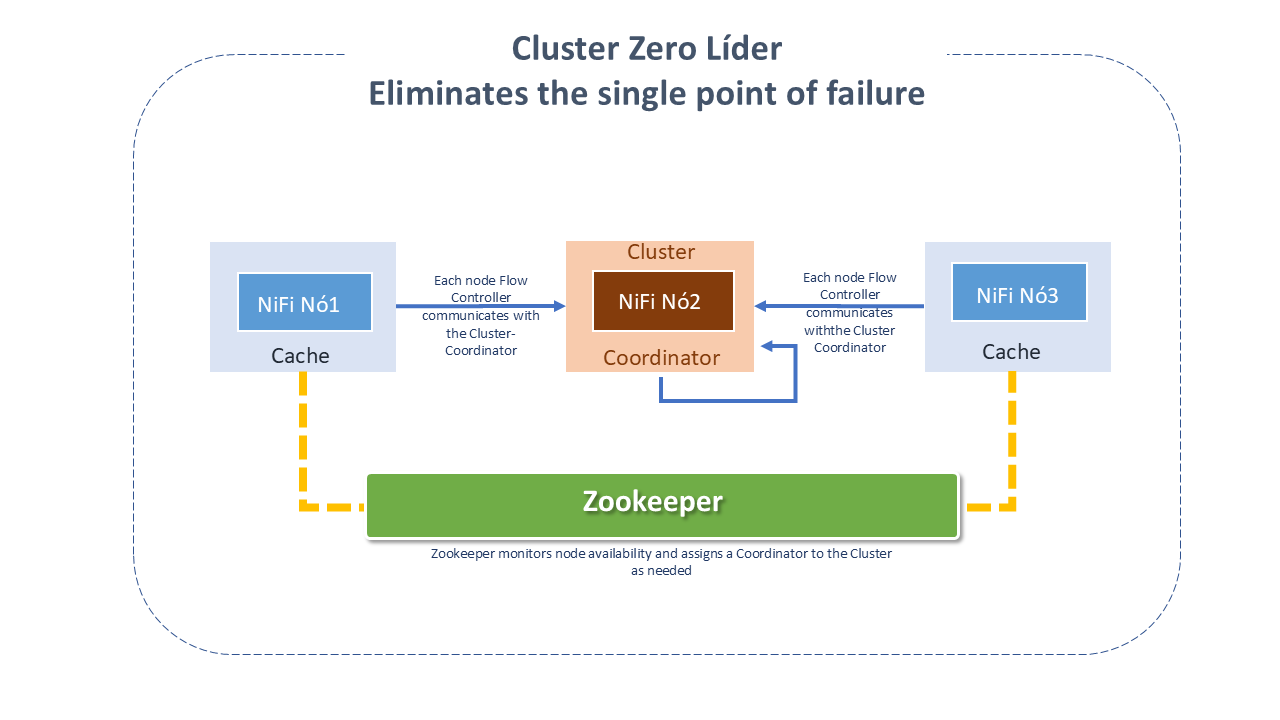
Just like the Dataflow manager, interaction with the NiFi Cluster can be done through the user interface (UI) of any node. Any changes are replicated to all nodes in the Cluster, allowing multiple entry points.
Performance Expectations
Apache NiFi was designed to fully leverage the resources of the host system it is operating on. This resource maximization is particularly strong concerning CPU and disk.
I/O:
Transfer rates or latency may vary depending on system configuration. Considering there are pluggable approaches for most NiFi subsystems, performance will depend on implementation. Consider using ready-to-use default implementations.
We can assume a read/write rate of 50MB per second on modest RAID disks within a common server. For large classes of data flows, NiFi is enabled to achieve 100MB per second or more of throughput, as linear growth is expected for each physical partition and content repository added to NiFi.
CPU:
The flow controller allocates and manages threads for processors. It acts as an engine dictating when a processor will receive the thread to execute.
Additionally, it allows adding controller services, which facilitate resource management, such as database connections or cloud service provider credentials.
The controller services are daemons (executed in the background) and provide configuration, resources, and parameters for processors to execute.
The ideal number of threads to be used depends on the resources of the host system in terms of the number of cores, if that system is running other services, and the nature of the processing in the flow. For heavy I/O flows, it is reasonable to provide many dozens of threads.
RAM:
NiFi resides in the JVM and is limited by the memory space provided by it. JVM garbage collection becomes a very important factor both in restricting the total heap size and in optimizing the application's execution over time.
NiFi jobs can be I/O intensive when reading the same content regularly. Configure a sufficiently large disk to optimize performance.
Most Interesting Features of Apache NiFi
NiFi Registry
It is a subproject of Apache NiFi - a complementary application that provides "centralized location" for storing and managing resources shared by one or more NiFi or MiNiFi instances.
It offers the following features:
- Implementation of Flow Registry to store and manage versioned flows.
- Integration with NiFi to allow storage, retention, and updating of versioned flows from the Flow Registry.
- Registry administration for defining users, groups, and policies.
The first implementation of the Registry supports versioned flows. Data flows at the process group level created in NiFi can be version-controlled and stored in a registry. The registry organizes where the flows are stored and manages permissions to access, create, modify, or delete them.
The NiFi Registry UI displays the available shared resources and provides mechanisms to create and manage users/groups, buckets, and policies. Once the NiFi Registry is installed, a compatible web browser can be used to view the UI.
Buckets are containers that store and organize versioned items, such as flows and bundles (binary artifacts containing one or more extensions that can be run in NiFi or MiNiFi).
MiNiFi
It is a subproject of Apache NiFi - a complementary data collection approach that supplements the core principles of NiFi in data flow management, with a focus on data collection at the point of its creation.
Apache NiFi MiNiFi provides the following features:
- Small size and low resource consumption.
- Centralized agent management.
- Generation of data provenance with the entire information custody chain.
- Integration with NiFi for subsequent data flow management.
Flow Management
- Guaranteed Delivery: NiFi's main philosophy is that, even at a very high scale, guaranteed delivery is the rule. This is achieved through the effective use of WAL (write-ahead log) and persistent content repository. Together they are designed to enable high transaction rates, effective load distribution, copy-on-write, and to "play" with the strengths of traditional read-writes on the disk.
- Data Buffering with Back Pressure and Pressure Release: NiFi supports buffering all queue data and has the ability to provide back pressure to those queues that have reached their limits or to "age" data when it reaches a specified age (its value has perished).
- Prioritized Queuing: NiFi allows configuring one or more prioritization schemes for retrieving data from a queue. The default is "oldest first," but there are times when "newer" data, larger, or some other custom scheme is the rule.
- Flow Specific QoS: (latency vs throughput, low tolerance, etc.): There are points in the Dataflow where data is absolutely critical and intolerant to failures. There are also times when it must be processed and delivered in seconds to generate some value. NiFi enables refining the flow configuration.
Ease of Use
- Visual Command and Control: Dataflows can become complex. Providing good visual expression can help reduce complexity and identify areas that need to be simplified. NiFi enables visual establishment of Dataflows in real-time. Changes to the dataflow take effect immediately. Changes are refined and isolated to the impacted components. It is not necessary to interrupt an entire flow or set of flows just to make a specific modification.
- Templates: Dataflows tend to be highly pattern-oriented, and although there are many different paths to solve a problem, sharing best practices by subject matter experts benefits everyone, as well as allowing the experts themselves to benefit from others' collaboration.
- Data Provenance: NiFi automatically records, indexes, and makes provenance data available as objects flow through the system, even in fan-in, fan-out, transformations, and others. This information becomes extremely critical in supporting compliance, troubleshooting, optimizations, and other scenarios.
- Recovery/continuous buffering of refined history: The NiFi content repository is designed to act as a continuous history buffer. Data is removed from the content repository only when it "ages" or more space is needed. This combined with provenance capability creates an incredibly useful base to enable "click-to-content," content download, replay, all at a specific point in the object's lifecycle, which can span generations.
Security
- System to System: A Dataflow is only good if it is secure. NiFi, at any point in the Dataflow, offers secure exchange using encryption protocols such as two-way SSL. Additionally, it allows the flow to encrypt and decrypt content and use shared keys or other mechanisms on both sides of the sender/receiver equation.
- User to System: NiFi allows two-way SSL authentication and provides pluggable authorization to control user access at specific levels (read-only, dataflow manager, administrator). If a user enters a confidential property (such as a password) in the flow, it will be immediately encrypted on the server side and never exposed on the client side, even in its encrypted form.
- Multi-tenant Authorization: The level of authority of a Dataflow is applied to each component, enabling the admin user to have a refined level of access control. This means that each NiFi cluster can handle the requirements of one or more organizations. Compared to isolated topologies, multi-tenant authorization allows a self-service model for dataflow management and enables each team or organization to manage flows with full awareness of the rest of the flow, for which they do not have access.
Extensible Architecture
- Extension: NiFi is built for extension, and as such, it is a platform on which Dataflow processes can be executed and interact in a repetitive and predictable manner.
- Classloader Isolation: For any component-based system, dependency problems can occur. NiFi addresses this by providing a custom class-loading model, ensuring that each extension package is exposed to a very limited set of dependencies. As a result, extensions can be built without worrying about conflicts with other extensions. The concept of these extension packages is called "NiFi files."
- Site-to-Site Communication Protocol: The preferred communication protocol between NiFi instances is the NiFi Site-to-Site (s2s) Protocol. S2S facilitates the transfer of data from one NiFi instance to another efficiently and securely. NiFi client libraries can be easily built and bundled into other applications or devices to communicate with NiFi via S2S. Both socket-based and HTTP(s) protocols are supported in S2S as the underlying transport protocol, making it possible to incorporate a proxy server into S2S communication.
Flexible Scaling Model
- Scale-out (Clustering): NiFi is designed for horizontal scalability through the use of clustering multiple nodes. If a single node is provisioned and configured to handle hundreds of MB per second, a modest cluster can be configured to handle GB per second. This brings load balancing and failover challenges between NiFi and the systems from which data is obtained. The use of asynchronous queue-based protocols, such as messaging services, kafka, etc., can help. The site-to-site feature is also very effective, as it is a protocol that allows NiFi and a client (including another Cluster) to talk to each other, share loading information, and exchange data through specific authorized ports.
- Scale-up and down: NiFi is also designed for very flexible scale-up and scale-down. In terms of throughput, from the NiFi framework perspective, it is possible to increase the number of simultaneous tasks in the processor on the scheduling tab during configuration. This allows more processes to be executed simultaneously, providing great throughput. On the other end of the spectrum, NiFi can be scaled to run on edge devices where hardware resources are limited.
Difference between Apache Airflow and Apache NiFi
By nature, Airflow is an orchestration framework and not a data processing framework.
While NiFi's main goal is related to the stream processing category, automating data transfer between two systems, Airflow is more related to workflow management.
It is important to note that the two tools are not mutually exclusive and both offer interesting features that help solve data silos within the organization.
NiFi is a perfect tool for Big Data. There is no better choice when it comes to the "configure and forget" pipeline type.
Airflow, on the other hand, is perfect for scheduling specific tasks, configuring dependencies, and managing programmatic workflows.
It allows for easy visualization of dependencies, code, trigger tasks, progress, logs, and success status of data pipelines.
Best Practices for Apache NiFi
Separate Environments
- Separate environments for development: It is essential to maintain separate environments for development, testing, and production to ensure data integrity and system stability.
Consider the User
One of the most important concepts in developing a "processor" or any other component is the user experience:
- Documentation should always be provided so that everyone can use the component easily.
- Consistency (naming conventions), simplicity, and clarity are fundamental principles to make this experience adequate.
Cohesion and Reusability
To create a unique and cohesive unit, developers are tempted to combine several functions into a single processor.
Adopting the approach of formatting data for a specific endpoint and then sending it to this point in the same processor may not be advantageous because:
- It can make the processor very complex.
- If the processor cannot communicate with a remote service, it will forward the data to a failure relationship and will be responsible for translating the data again, and again...
- If we have 5 different processors translating input data into a new format before sending it, we will have a large amount of duplicated code. If the scheme changes, many processors must be updated.
- These intermediate data are discarded when the processor finishes sending them to the remote service. The intermediate format may be useful for other processors.
To avoid these problems and make processors more reusable, a processor should always follow the principle: "do one thing and do it well."
It should be divided into two separate processors: one to convert the data from format X to Y and another to send data to the remote resource.
Naming Conventions
To provide a consistent appearance to users, it is advisable for processors to maintain standard naming conventions:
- Processors that extract data from a remote system are named:
Get<Service>(search data from arbitrary sources via known protocol, like GetHTTP, GetFTP) orGet<Protocol>(search data from a known service like GetKafka).
- Processors that send data to a remote system are named:
Put<Service>orPut<Protocol>.
- Relationship names are lowercase and use spaces to delineate words.
- Property names should use meaningful words, like a book title.
Processor Behavior Annotations
When creating a processor, the developer must provide hints to the framework on how to use it more efficiently.
This is done by applying annotations to the processor class.
The annotations that can be applied are in three sub-packages of org.apache.nifi.annotation:
- documentation subpackage: Provides documentation to the user.
- lifecycle subpackage: Instructs the framework on which methods to call on the processor to respond to appropriate lifecycle events.
- behavior subpackage: Helps the framework understand how to interact with the processor in terms of scheduling and general behavior.
The following annotations from the package can be used to modify how the framework will handle your processor (for more details, click here):
- EventDriven: Instructs the framework that the processor can be scheduled using the event-driven scheduling strategy.
- SideEffectFree: Indicates that the processor has no external side effects to NiFi.
- SupportsBatching: Indicates that it is okay for the framework to batch multiple ProcessSession commits into a single commit.
- TriggerSerially: Prevents the user from scheduling more than one concurrent thread to run the onTrigger method at a time.
- PrimaryNodeOnly: Restricts the processor's execution to only the Primary Node.
- TriggerWhenAnyDestinationAvailable: Indicates that the processor should run if any relationship is "available" even if one of the queues is full.
- TriggerWhenEmpty: Ignores the size of the input queues and triggers the processor regardless of whether there is data in an input queue or not.
- InputRequirement: By providing a value through this annotation (INPUT_REQUIRED, INPUT_ALLOWED, or INPUT_FORBIDDEN), the framework will know when it should be invalidated or whether the user should be able to establish a connection to the processor.
Data Buffering
NiFi provides a generic data processing capability. Data can be in any format.
Processors are usually scaled with multiple threads.
A common developer mistake is to buffer all the content of a FlowFile in memory.
Unless absolutely necessary, this should be avoided, especially if the data format is known.
Instead of buffering this data in memory, it is advisable to evaluate the data as it is streamed from the Content Repository (i.e., the inputStream content provided by the ProcessSession.read callback).
Apache NiFi Project Details
Apache NiFi is developed in Java.