Apache Hive
Analytics
A database is a set of data belonging to the same context, systematically stored within a structure built to support them. In this structure, the necessary business rules coexist to achieve specific goals.
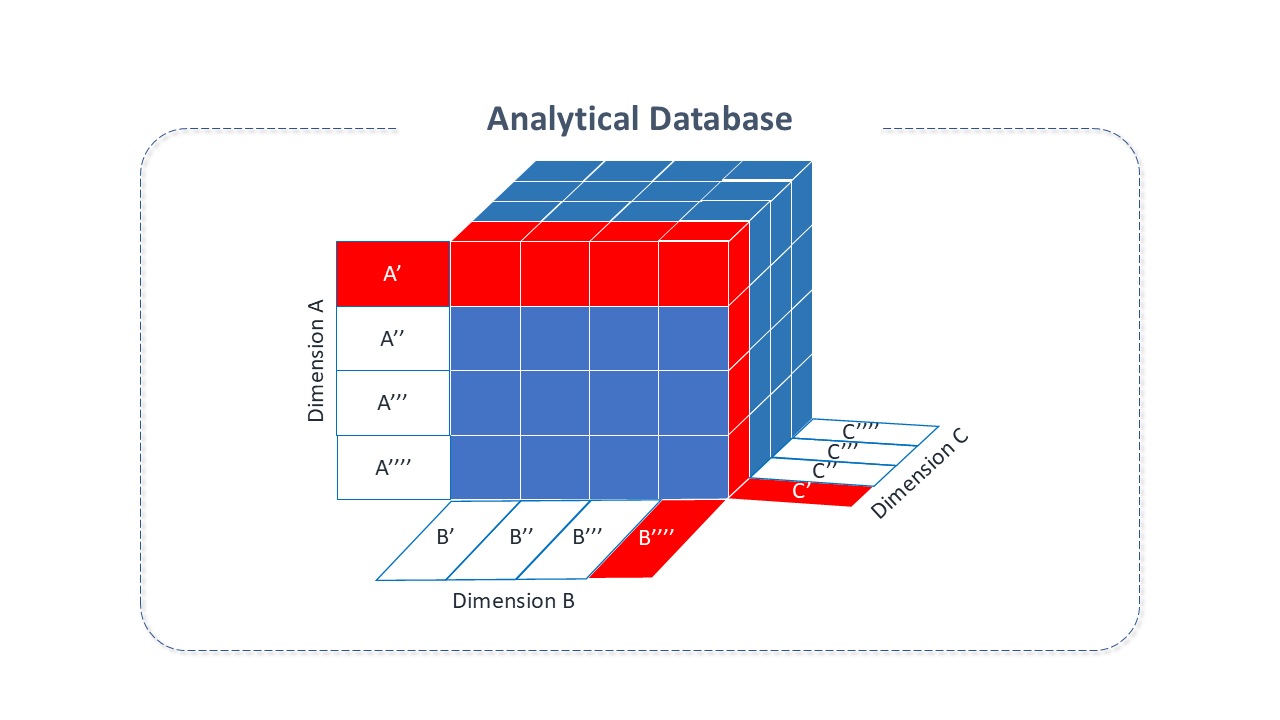
An analytical database is a type of database created to store, manage, and consume data, designed for specific solutions in Business Analysis, Big Data, and BI.
Unlike a typical database, which stores data by transactions or process, an analytical database stores historical data in business metrics. It is based on multidimensional models that use relationships with data to generate multidimensional matrices called "cubes". These models can be directly queried by combining their dimensions, avoiding complex queries that would be performed in conventional databases.
Apache Hive Features
Apache Hive is an analytical database (Datawarehouse) based on APACHE Hadoop, designed to facilitate data-warehouse users who are proficient in SQL queries but find it challenging to adopt Java or other languages.
It provides a SQL-like interface between the user and the distributed file system of Hadoop-HDFS.
It was designed to facilitate summarization, analysis, querying, reading, writing, and handling large datasets.
With it, it has become possible to define tables with data stored in HDFS and then run queries for transformation or report generation.
-
Apache Hive offers standard SQL functionalities, including many features from SQL 2003, SQL 2011, SQL 2016, and later, for analysis.
-
Apache Hive can also be extended through "user-defined functions (UDFs), user-defined aggregate functions (HDAFs) and user-defined table functions (UDTFs)".
-
There isn't a single "Hive format." Hive includes built-in connectors for:
- Text files with comma and tab separations (CSV/TSV)
- Apache Parquet (a columnar storage format available for any project in the Hadoop ecosystem)
- Apache ORC (a self-describing type-aware columnar file format designed for Hadoop workloads)
- other formats.
-
Users can extend Hive with connectors for other formats from the following profiles:
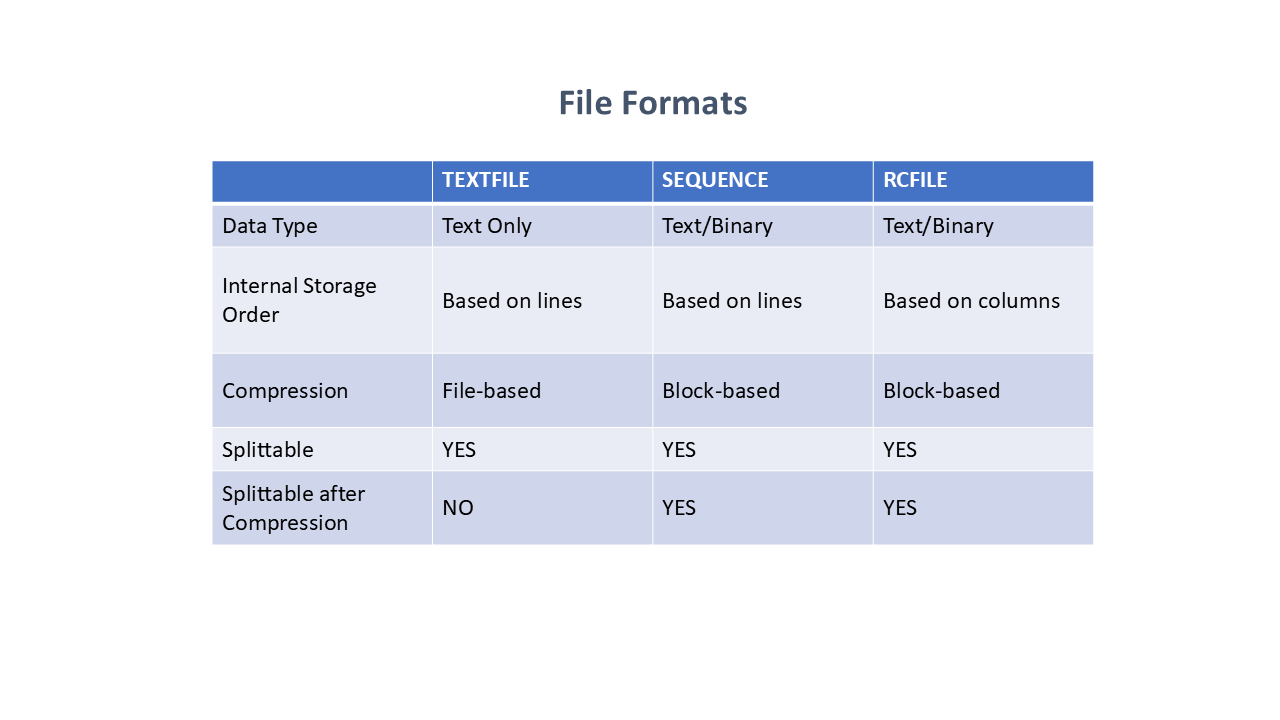 Figure 2 - HIVE File Formats
Figure 2 - HIVE File Formats -
The query and storage operations are similar to traditional DBMS. However, there are many differences in the structure and functioning of Hive.
-
Apache Hive is not designed for online transaction processing (OLTP). It is best used for traditional Data Warehousing tasks.
-
It was designed to maximize scalability, performance, extensibility, fault tolerance, and flexible coupling, with its input formats.
-
The simplicity of the Hive query language (HQL) has helped Hive gain popularity in the Hadoop community, being used in many projects worldwide. HQL provides
explainandanalyzecommands that can be used to check and identify the performance of queries. Additionally, Hive logs contain detailed information for performance investigation and troubleshooting.
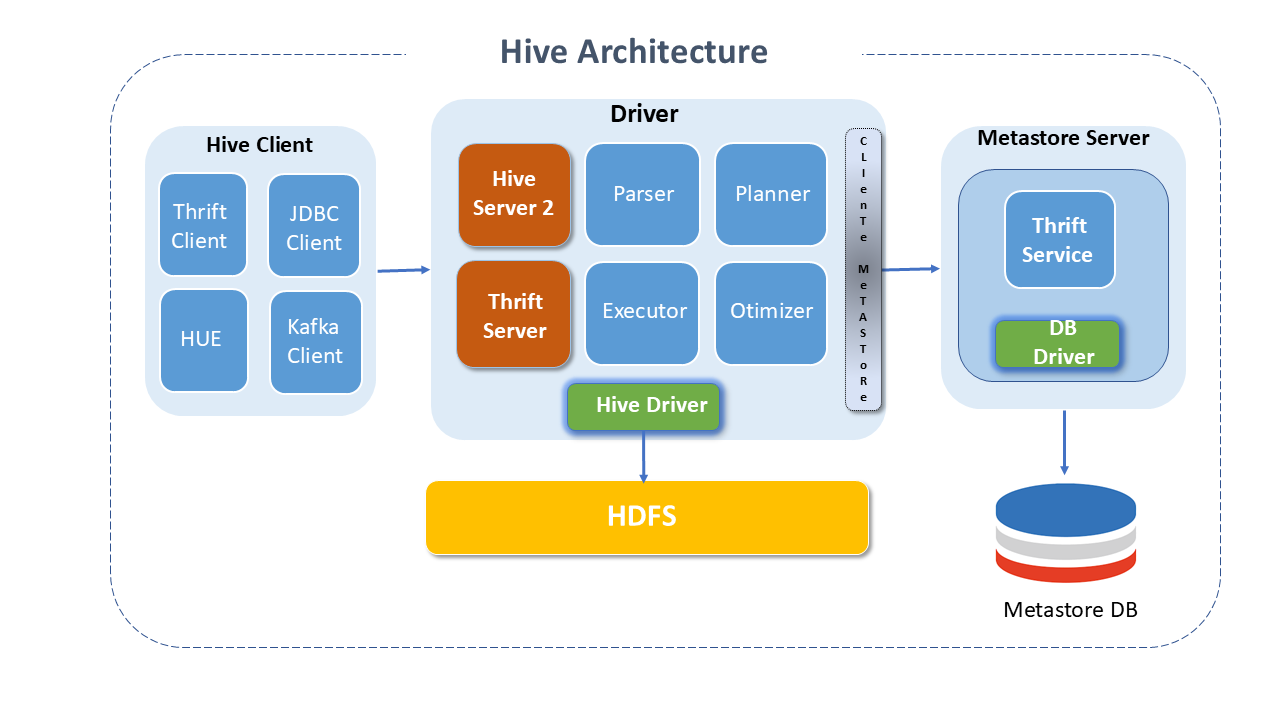
Architecture of Apache Hive
Hive consists of multiple components, with the main ones being:
-
Hive Client: Hive provides different drivers for communication with various types of applications.
- For Thrift-based applications, it provides the Thrift client.
- For Java applications, it provides JDBC Drivers.
- For other types of applications, it provides ODBC drivers.
-
Metastore server: Stores metadata for each table, such as schema and location, including partition metadata, which helps the driver track the progress of various data sets distributed across the Cluster.
- Maintains details about tables, partitions, schemas, columns, etc. The data are stored in a traditional RDBMS format.
- The metadata helps the "driver" to track the data.
- A backup server regularly replicates the data that can be recovered in case of data loss.
- Provides a Thrift Service interface for access to information and metadata.
-
Driver: Responsible for receiving the Hive queries submitted by clients.
- Initiates the execution of the statement by creating sessions and monitors the lifecycle and progress of the execution.
- Stores the necessary metadata generated during the execution of a HIVEql statement.
The driver also serves as a collection point for data or query results obtained after the reduce operation. It has four components:
- Parser: Responsible for checking syntax errors in queries. It is the first step in query execution and returns an error to the client via the Driver if irregularities are found.
- Planner: Successfully parsed queries are forwarded to the planner that generates the execution plans using tables and other metadata information from the metastore.
- Optimizer: Responsible for analyzing the plan and generating a new optimized DAG plan. Optimization can be done on joins, reducing shuffling data, etc., aiming for performance optimization.
- Executor: Once the parser, planner, and optimizer have completed their tasks, the executor will start executing the job in the order of dependencies. The optimized plan is communicated to each task using a file. The executor takes care of the lifecycle of tasks and monitors their execution.
Interaction of Hive with Hadoop
In general, the interaction between Hive and Apache Hadoop occurs as follows:
"1 " - The UI calls the execution interface of the Driver.
"2 " - The Driver creates a session identifier for the query and sends it to the compiler to generate an execution plan.
"3 e 4 " - The compiler obtains the necessary metadata from the metastore, which are used to check the type of expressions in the query tree and to remove partitions based on the query predicates (when a boolean result is expected).
-
The Plan generated by the compiler is a DAG of stages, with each stage being a map or reduce job, a metadata operation, or an HDFSoperation.
-
Map/reduce stages: The plan includes map operator trees (operator trees executed on mappers) and a reduce operator tree (for operations using reducers).
"6 " - The execution engine submits these stages to the appropriate components (steps 6, 6.1, 6.2, 6.3).
- In each map or reduce, the deserializer associated with the table or intermediate outputs is used (to read the lines from HDFS files passed through the associated operator tree).
The output is written to a temporary HDFS file through the serializer (which happens in the mapper if the operation does not require reduce).
Temporary files are used to provide data for subsequent map/reduce stages of the plan.
For DML operations, the final temporary file is moved to the table's location.
The following figure illustrates how a common query "flows" through the system:
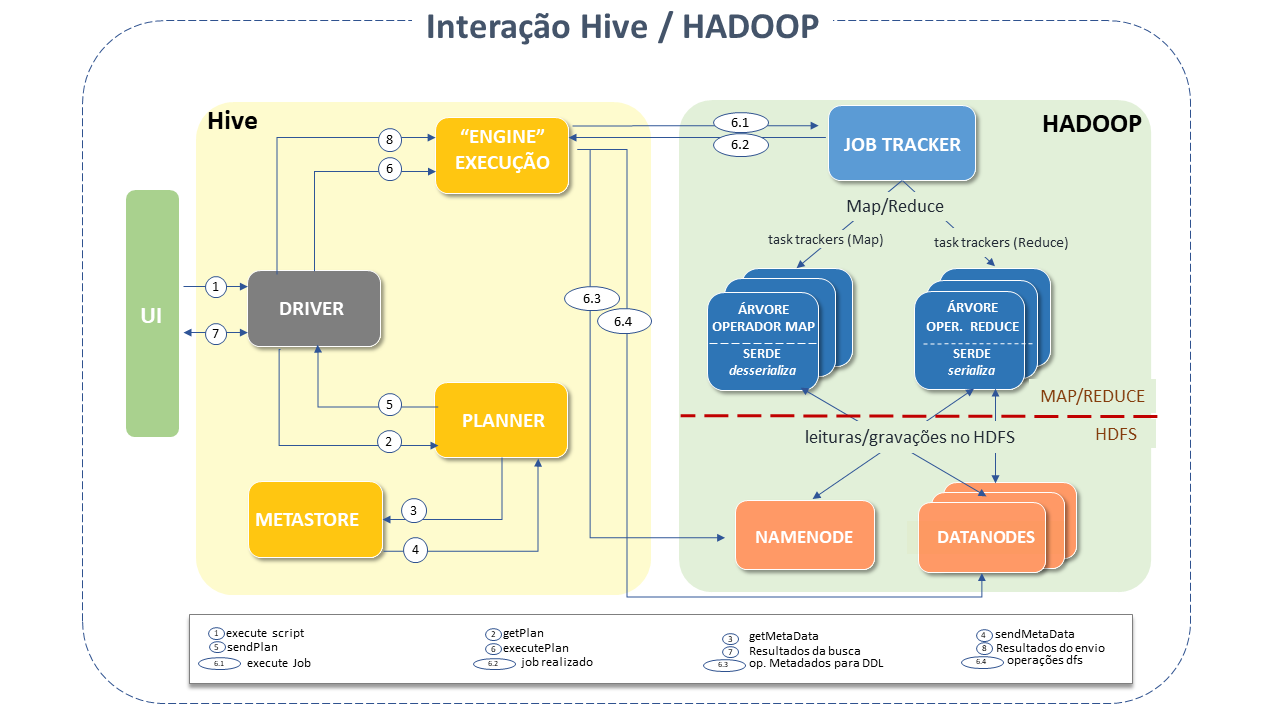
How Apache Hive Works
-
HCatalog: A table and storage management layer for Hadoop that enables tools like Hive and MapReduce to read data from tables.
It is built "on top" of the Hive Metastore service and thus supports file formats for which Hive SerDe (serialization and deserialization) can be done.
HCatalog enables viewing data as relational tables, without the need to worry about the location or format of the data.
Supports text file, ORC file, sequence file, and RCFile formats, and SerDe can be written for formats like AVRO (an open-source data format that enables grouping serialized data with the schema in the same file).
HCatalog tables are "immutable," which means that data in the table and partition cannot be appended. In the case of partitioned tables, data can only be appended to a new partition, not affecting the old partition.
Interfaces for MapReduce applications are HCatInputFormat and HCatOutputFormat, both are Hadoop-compatible Input and Output Formats for Hive. HCatalog is evolving new interfaces to interact with other components of the Hadoop ecosystem.
-
WebHCat provides a service for executing Hadoop MapReduce (or YARN), Pig, and Hive tasks. It also allows the execution of Hive metadata operations using an HTTP (REST-style) interface.
Data Organization
By default, Hive stores metadata in an embedded Apache Derby database. Other client-server databases can optionally be used, such as Postgree.
The first four file formats supported by Hive were just plain text, sequential files, ORC, and RCFile formats. Apache Parquet can be read via a plug-in in versions later than 0.1, originally starting in 0.13. Parquet's compressed data representation reduces the amount of data Hive has to traverse, consequently speeding up the execution of queries.
Additional plugins support querying the Bitcoin Blockchain.
Data Units
Hive is organized into:
-
Databases: Namespaces exist to avoid name conflicts in tables, views, partitions, columns, and all else. Databases can also be used to enforce security for a user or group of users.
-
Tables: Homogeneous units of data that have the same schema.
-
Partitions: Each table can have one or more partition keys that determine how the data is stored. Partitions, in addition to being storage units, also enable the user to efficiently identify rows that satisfy a specific criterion. Each unique value of a partition key defines a partition of the table.
-
Buckets or Clusters: Data in each partition can be divided into "buckets" based on the hash function value of some table column. For example, a table can be "broken" by userid, which is one of the table's columns.
Apache Hive Resources
Built on Apache Hadoop, Hive provides the following resources:
-
SQL Access, facilitating data warehousing tasks such as extraction/transformation/loading (ETL), report generation, and data analysis.
-
Support for concurrency and authentication of multiple clients with Hive-Server 2 (HS2), designed to provide better support for open API clients such as JDBC and ODBC.
-
Full support for ACID properties for ORC tables and insertion to all other formats**.
-
Support for initialization and incremental replication for data backup and recovery.
-
Central repository of metadata for Hive tables and partitions in a relational DBMS with access to this information via the MetaStore service API.
-
Mechanism to establish structure in a variety of data formats.
-
Access to files stored directly in Apache HDFS or others, such as Apache Hbase.
-
Query execution via Apache Tez, Apache Spark, or Mapreduce.
-
Sub-second query retrieval via Hive LLAP and Apache YARN.
-
Beeline-Command Line Shell HiveServer2 supports Beeline Shell, a JDBC-based SQL CLI client that operates both in embedded mode (with an integrated Hive - similar to the Hive CLI) and remotely (connecting to a separate HS2 process via Thrift).
Main Differences Between Hive and Traditional DBMS
In traditional DBMS, a schema is applied to a table when data is loaded into it. This allows the DBMS to check if the inserted data follows the table's representation as specified in its definition. This design is called "schema on write".
Hive does not check data against the table schema on write. It performs checks at read time. This model is called "schema on read". Both approaches have their advantages and disadvantages. Checking during load adds overhead, burdening data load time, but ensures data is not corrupted. Early detection ensures early handling of exceptions. As tables are forced to match the schema during/after data load, they perform better at query time.
Hive, on the other hand, can load data dynamically without schema verification, ensuring a quick initial load but slower performance at query time.
Transactions are fundamental operations in traditional DBMS.
Like any typical RDBMS, Hive supports the four properties of transactions (ACID): Atomicity, Consistency, Isolation, Durability. Transactions were included in Hive 0.13, but only limited to partition level.
Version 0.14 of Hive was fully added to support complete ACID properties. From this version, different line-level transactions such as insert, delete, update are possible. Enabling these commands requires setting appropriate values for configuration properties such as hive.support.concurrency, hive.enforce.bucketing, hive.exec.dynamic.partition.mode
Apache Hive Security
Version 0.7.0 of Hive added integration with Hadoop security, which in turn began using Kerberos authorization support to provide security. Kerberos allows mutual authentication between client and server. In this system, the client's request for a ticket is passed along with the request.
Permissions for newly created files in Hive are dictated by HDFS. The distributed file system's authorization model of Hadoop uses three entities: user, group, and others with three permissions: read, write, execute. Default permissions for newly created files can be configured by changing the unmask value for the Hive configuration variable hive.files.umask.value.
Best Practices for Apache Hive
-
Tables Partitioning: Apache Hive addresses the inefficiency of executing MapReduce jobs with large tables by offering an automatic partitioning scheme at the time of table creation.
- In this method, all table data are divided into multiple partitions, each corresponding to specific value(s) of the partition column(s), which are maintained in HDFS records (as sub-directories).
- A query with partition filtering will only load data from specific partitions (subdirectories), bringing more speed to the process. The choice of partition key is an important factor, always should be a low "cardinal" attribute to avoid overloads.
noteCommonly used attributes as partition keys are:
- partitions by date and time: date-time, year-month-day (even hours)
- partitions by location: country, territory, city, state.
- partitions by business logic: department, customers, sales region, applications.
-
Denormalization: Normalization is a standard process used to model data tables dealing with redundancies and other anomalies. Joins are expensive and complicated operations and generate performance issues. It's a good idea to avoid highly normalized table structures, as they require joining queries.
-
Map/Reduce output compression: Compression significantly reduces the volume of intermediate data and minimizes the amount of data transfer between Mapper and Reducer.
- Compression can be applied to the output of Mapper and Reducer individually. Important to remember that gzip compressed files cannot be split. It means that it should be applied cautiously.
- The file size should not be larger than a few hundred Mb, at the risk of producing unbalanced work.
- Compression codec options can be snappy, izo, bzip, etc.
-
Map Joins: Map Joins are efficient if the table "on the other side of the join" is small enough to reside in memory.
- With the parameter hive.auto.convert.join=true, Hive tries the map join automatically. When using this parameter, it is appropriate to make sure that auto-convert is enabled in the Hive environment.
- It is essential, still, the parameter hive.enforce.bucketing = true. This setting will cause Hive to reduce scan cycles to find a specific key because bucketing will ensure that the key is in a specific bucket.With the parameter hive.auto.convert.join=true, Hive automatically attempts to use map join. When using this parameter, it is advisable to ensure that auto-convert is enabled in the Hive environment. Additionally, the parameter hive.enforce.bucketing=true is essential. This configuration will reduce the scan cycles required to find a specific key because bucketing ensures that the key is in a specific bucket.
-
Selection of input format: Input formats play a critical role in Hive's performance. The text type, for example, is not suitable for a system with high data volume because these readable types of formats take up a lot of space and bring overhead to analysis.
- To address this, Hive introduces columnar input formats like RCFile, ORC, etc. These formats allow reducing read operations in analytical queries, enabling access to each column individually.
- Other binary formats like Avro, sequence files, Thrift, and ProtoBuf can also help.
-
Parallel execution: Hadoop can execute MapReduce jobs in parallel, and many queries run in Hive utilize this parallelism automatically.
-
However, single and complex Hive queries are often converted into multiple MapReduce jobs, which, by default, are executed sequentially.
-
Some of the MapReduce stages of a query are not interdependent and can be run in parallel, leveraging "the available" capacity of the Cluster, improving its utilization, and reducing the overall execution time.
-
The Hive configuration to change this behavior is to toggle the flag
´´´shell Set hive.exec.parallel=true ´´´
-
-
Vectorization: Vectorized query execution improves the performance of Hive.
- It is a technique that works with processing data in batches, rather than one line at a time, resulting in efficient CPU usage.
- To enable vectorization, the appropriate parameter is Set hive.vectorized.execution.enabled=true.
-
Unit Testing: Unit testing determines if the smallest testable part of the code functions. Detecting problems early is very important.
- Hive allows testing units like UDFs, SerDes, Streaming Scripts, Hive Queries, etc., through quick tests in local mode.
- Several tools are available that assist in testing Hive queries, such as HiveRunner, Hive_test, and Beetest.
-
Sampling: Sampling allows a subset of data to be analyzed without the need to analyze the entire set.
- With a representative sample, a query can return significant results much more quickly, consuming fewer resources.
- Hive offers the TABLESAMPLE, which allows tables to be sampled, at various levels of granularity - returning subsets or HDFS blocks or just the first n records of each input split.
- A UDF can be implemented to filter the records according to a sampling algorithm.
Details of Project Apache Hive
Apache Hive was predominantly developed in Java. HiveQL is Hive's SQL-based language. It "applies" SQL syntax in creating tables, loading data, and querying. It also allows the incorporation of custom MapReduce scripts. These scripts can be written in any language using a simple streaming interface (reading lines on standard input and writing on standard output).
Sources: