Apache Spark
Distributed Computing Platform
Distributed Computing
With the evolution of computer networks, a new computational paradigm emerged and became extremely powerful: the possibility of distributing processing across different computers.
Distributed computing allows the partitioning and specialization of computational tasks, according to the nature and function of each computer.
This paradigm emerged to solve a major problem in computing, which is the need for computers with sufficient processing power to analyze the large volume of data available today.
Apache Spark Features
Apache Spark is a unified analytics engine for large-scale data processing in distributed computing.
Created in 2009 at the University of California by Berkeley's AMPLab, Spark quickly gained a large community, leading to its adoption by the Apache Software Foundation in 2013.
Developers from over 300 companies helped implement it, and a vast community with more than 1,200 developers from hundreds of organizations continue to contribute to its ongoing refinement.
It is used by organizations in a range of sectors and has one of the largest existing developer communities.
The power of Spark comes from its in-memory processing.
It uses a distributed set of nodes with a lot of memory and compact data encoding, along with an optimized query planner to minimize execution time and memory demand.
By performing in-memory calculations, it can process up to 100 times faster than disk-processing frameworks.
It is ideal for processing large volumes of data in Analytics, training models for machine learning and AI.
Additionally, Spark runs a stack of native machine learning libraries and graph processing and SQL-like data structures, enabling exceptional performance.
It features over 80 high-level operators, making it easy to create parallel applications.
Spark shares some similarities with Hadoop. Both are open-source frameworks for processing analytical data, live at the Apache Software Foundation, contain machine learning libraries, and can be programmed in several different languages.
However, Spark extends the number of possible calculations with Hadoop, enhancing Hadoop's native data processing component, MapReduce.
Spark uses the Hadoop Distributed File System (HDFS) infrastructure but improves its functionalities and provides additional tools, such as implementing applications in a Hadoop Cluster (with SIMR - Spark Inside MapReduce) or YARN.
Apache Spark Architecture
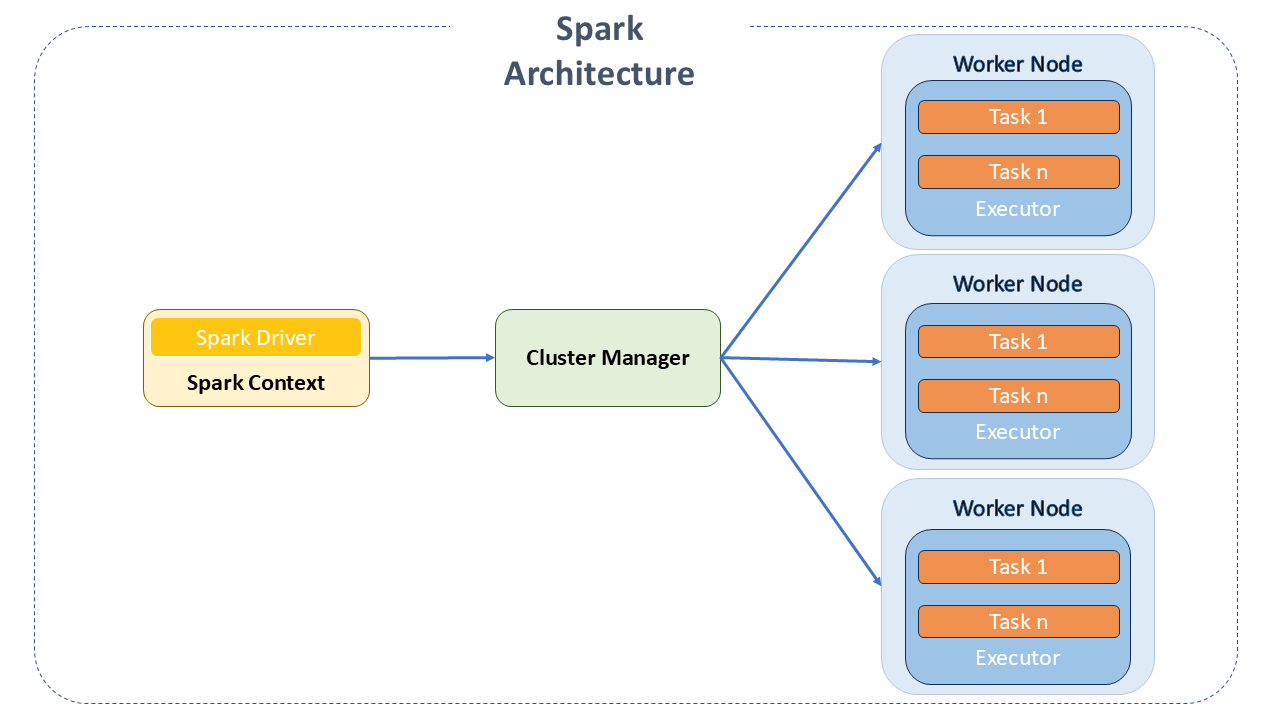
Apache Spark is a distributed processing engine that operates on the coordinator/worker principle.
Its architecture consists of the following main components:
-
Spark Driver: It is the master of the Spark architecture. It is the main application that manages the creation and execution of the processing defined by the programmer.
-
Cluster Manager: An optional component only necessary if Spark is run in a distributed manner. It is responsible for managing the machines that will be used as workers.
-
Spark Workers: These are the machines that actually execute the tasks sent by the Driver Program. If Spark is run locally, the machine can act as both Driver and Worker.
Fundamental Components of the Spark Programming Model
-
Resilient Distributed Datasets (RDD): The main object of the Spark programming model. It is in these objects that the data is processed. They store the data in memory to perform various operations such as loading, transforming, and actions (calculations, writing, filtering, joining, and map-reduce) on the data. They abstract a set of distributed objects in the Cluster, usually executed in main memory. They can be stored in traditional file systems, HDFS, and some NoSQL databases like HBase.
-
Operations: Represent transformations (grouping, filtering, mapping data) or actions (counting and persistence) performed on an RDD. A Spark program is typically defined as a sequence of transformations or actions performed on a dataset.
-
Spark Context: The context is the object that connects Spark to the program being developed. It can be accessed as a variable in a program.
Apache Spark Libraries
In addition to APIs, there are libraries that make up its ecosystem and provide additional capabilities:
-
Spark Streaming: Can be used to process streaming data in real-time based on microbatch computing. For this, it uses DStream, which is basically a series of RDDs to process data in real-time. It is scalable, has high throughput, fault-tolerant, and supports batch or streaming workloads. Spark Streaming allows reading/writing from/to Kafka topics in text, csv, avro, and json formats.
-
Spark SQL: Provides the ability to expose Spark datasets through a JDBC API. This allows executing SQL-style queries on these datasets, making use of traditional BI and visualization tools. Additionally, it allows the use of ETL to extract data in different formats (Json, Parquet, or Database), transform them and expose them for ad-hoc queries.
-
Spark MLlib: Spark's machine learning library, consisting of learning algorithms, including classification, regression, clustering, collaborative filtering, and dimensionality reduction.
-
Spark GraphX: A new API for Spark for graphs and parallel computation. Simply put, it extends Spark RDDs for graphs. To support graph computation, it exposes a set of fundamental operators (subgraphs and adjacent vertices), as well as an optimized variant of Pregel. Additionally, it includes a growing collection of algorithms to simplify graph analysis tasks.
-
Shared Variables: Spark offers two types of shared variables to make it more efficient when running on Clusters:
-
Broadcast: Read-only variables that are cached on all nodes of the Cluster for access or use by tasks. Instead of sending the data with each task, Spark distributes the broadcast variables to the machine using efficient broadcast algorithms to reduce communication costs.
-
Accumulator: Shared variables added only through an associative and commutative operation, used to perform counters (similar to MapReduce counters) or sum operations.
-
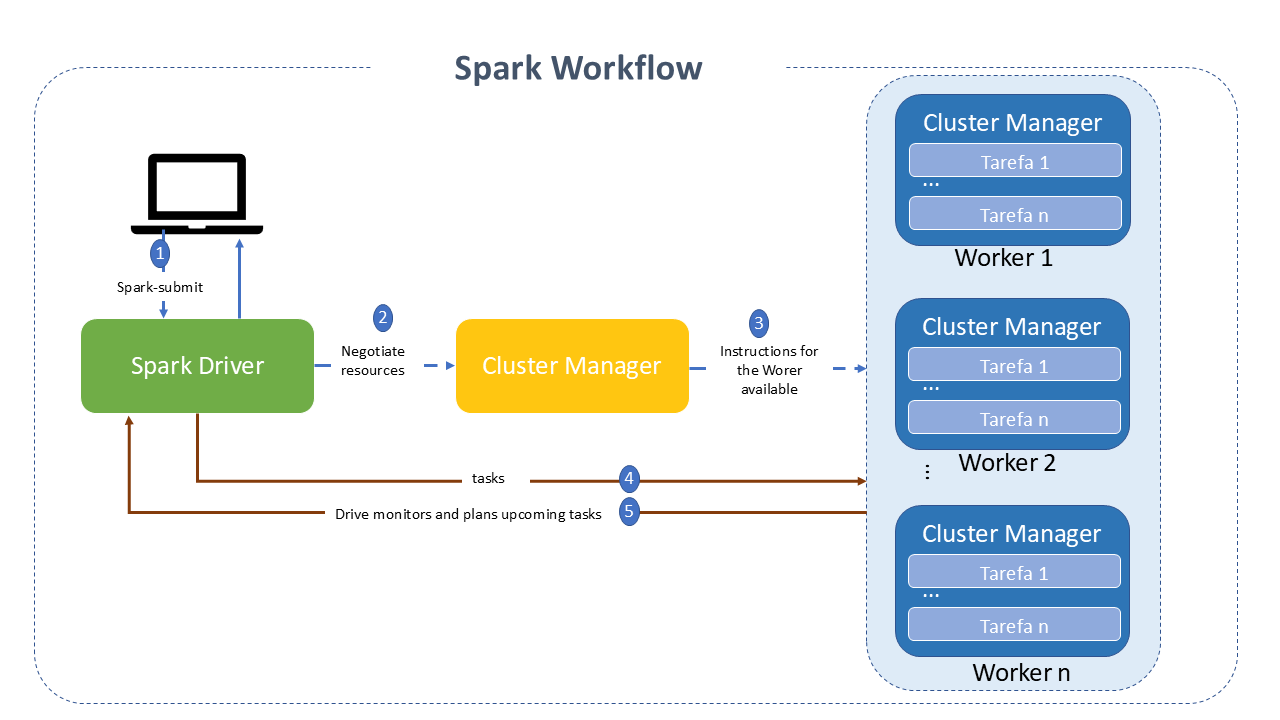
Apache Spark Workflow
Its lifecycle involves several intermediate steps, each responsible for handling specific responsibilities.
- The process begins with the job submission by the client, using the spark-submit option.
- The main class, specified during job submission, is called, and the Spark driver program is started on the master node, responsible for managing the application's lifecycle.
- The driver program requests resources from the Cluster manager to start the Executors based on the application's configuration.
- The Cluster manager activates the executor on the worker node on behalf of the Spark driver, which now takes ownership of the application's lifecycle.
- The Spark driver creates a DAG based on the RDD. The task is then divided into stages. The Spark driver sends tasks to the executor, which executes them.
- The executor sends a task completion request to the driver through the Cluster manager. After all tasks are completed on all executors, the driver sends a completion status to the Cluster manager.
Other Features of Apache Spark
- Spark can access variable data sources and run on various platforms, including Hadoop.
- Provides high-level functional APIs in Java, Scala, Python, and R for:
- large-scale data manipulation
- in-memory data caching
- reusing datasets
- Supports various formats and sets of APIs to handle any type of data in distributed mode.
- Offers an optimized engine with support for general execution graphs.
- Utilizes the concept of direct acyclic graph (DAG), through which it is possible to develop pipelines composed of several complex stages.
- The ability to store data in-memory and near real-time processing makes Spark faster than the MapReduce framework and provides an advantage for iterative use cases where the same dataset is used multiple times in different executions.
Best Practices for Apache Spark
-
Use Dataframe/Dataset over RDD: RDD serializes and deserializes whenever it distributes data between Clusters. These operations are very costly. On the other hand, Dataframe stores data as binaries, using off-heap storage, without the need for serialization and deserialization of data in distribution to Clusters, making it a great advantage over RDD.
-
Use Coalesce to Reduce Number of Partitions: Whenever it is necessary to reduce the number of partitions, use coalesce, as it makes the minimum data movement across the partition. On the other hand, repartition recreates the entire partition, making data movement very high. To increase the number of partitions, we have to use repartition.
-
Use Serialized Data Formats: Generally, whether it's a streaming or batch job, Spark writes the calculated results to an output file, and another Spark job consumes it, performs some calculations, and writes it again to an output file. In this scenario, using a serialized file format, such as Parquet, gives us a significant advantage over CSV and JSON formats.
-
Avoid User-Defined Functions: Use Spark's pre-built functions whenever possible. UDFs (User Defined Functions) are a black box for Spark, preventing it from applying optimizations. Thus, we lose all optimization features offered by Spark's Dataframe/Dataset.
-
Cache Memory Data: Whenever we perform a sequence of Dataframe transformations and need to repeatedly use an intermediate Dataframe for additional calculations, Spark provides a feature to store a specific DF in memory in the form of a cache.
Apache Spark Project Details
Spark is written in the Scala language and runs on a Java virtual machine. It currently supports the following languages for application development:
- Scala
- Java
- Python
- Clojure
- R