Apache Solr
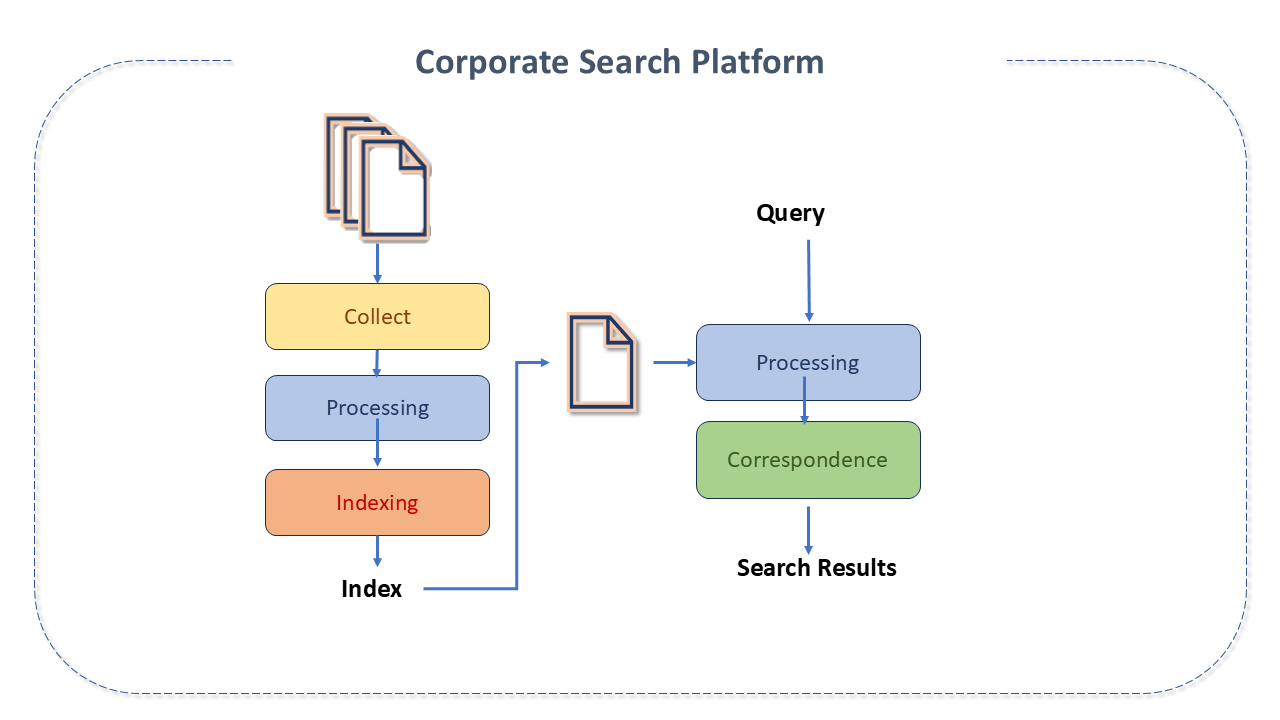
Corporate Search Platform
Enterprise Search Platforms have the function of creating a secure, powerful and easy-to-use search function.
When applied to business contexts, they generally integrate with business intelligence and data management solutions, and are used to "cleanse" and structure data, making information easier to locate, and can extract information from different sources, such as CRM, ERP, etc.
To qualify as a corporate search platform, the product must:
- Handle information from different sources, data types and formats.
- Index or archive data.
- Provide intelligent search options.
- Offer an interface for searching and retrieving data.
- Allow users to refine their searches using advanced filters.
- Set permissions for access to information.
Apache Solr features
Apache Solr is an open source enterprise search platform, built on top of Apache Lucene, designed for document retrieval.
Apache Solr was created in 2004 by Yonik Seeley, at CNET Networks, as an internal project to add search capabilities to the company's website.
- In January 2006, its source code was donated to the Apache Software Foundation and, by 2007, it was already considered a top-level autonomous project (TLP), having grown steadily with accumulated resources, attracting users, collaborators and commiters.
- It was released by Apache in 2008, in version 1.3, and in 2010 it was merged with Lucene (its versioning scheme was changed in 2011 to match Lucene's).
- In 2020, Bloomberg donated the Solr operator to the Lucene/Solr project, which made it possible to deploy and run Solr on Kubernetes.
- In 2021 Solr was established as a separate Apache project (TLP), independent of Lucene. Its first independent version was 9.0.
Solr is widely used for enterprise research and analysis use cases. It is developed openly and collaboratively by the Apache Solr Project at the Apache Software Foundation. It has a very active development community with regular releases.
Its main features include:
-
Advanced Full-Text Search Features. Enabling advanced search features, including phrase matching, use of wildcards to make searches more flexible, as well as supporting joins and groupings on any type of data.
-
Optimized for high-volume traffic. Proven on extremely large scales around the world.
-
Open interfaces: Based on XML, JSON and HTTP standards.
-
Comprehensive administration interfaces: Featuring an integrated responsive administrative user interface to make it easier to control your instances.
-
Easy monitoring: Publishing metric data loads via JMX.
-
Highly scalable and fault-tolerant:
- Built on Apache Zookeeper, it makes it easy to scale up or down.
- Offers replication, distribution, rebalancing and fault tolerance.
-
Flexible and adaptable with simple configuration: Flexible schema configurations, allowing almost any type of data to be stored in Solr.
-
Real-time _near indexing: Allowing changes to be seen at any time.
-
Extensible plugin architecture. Publishes many extension points that make it easy to incorporate index and query time plugins, allowing your code to be changed at will (as it is an open-source license).

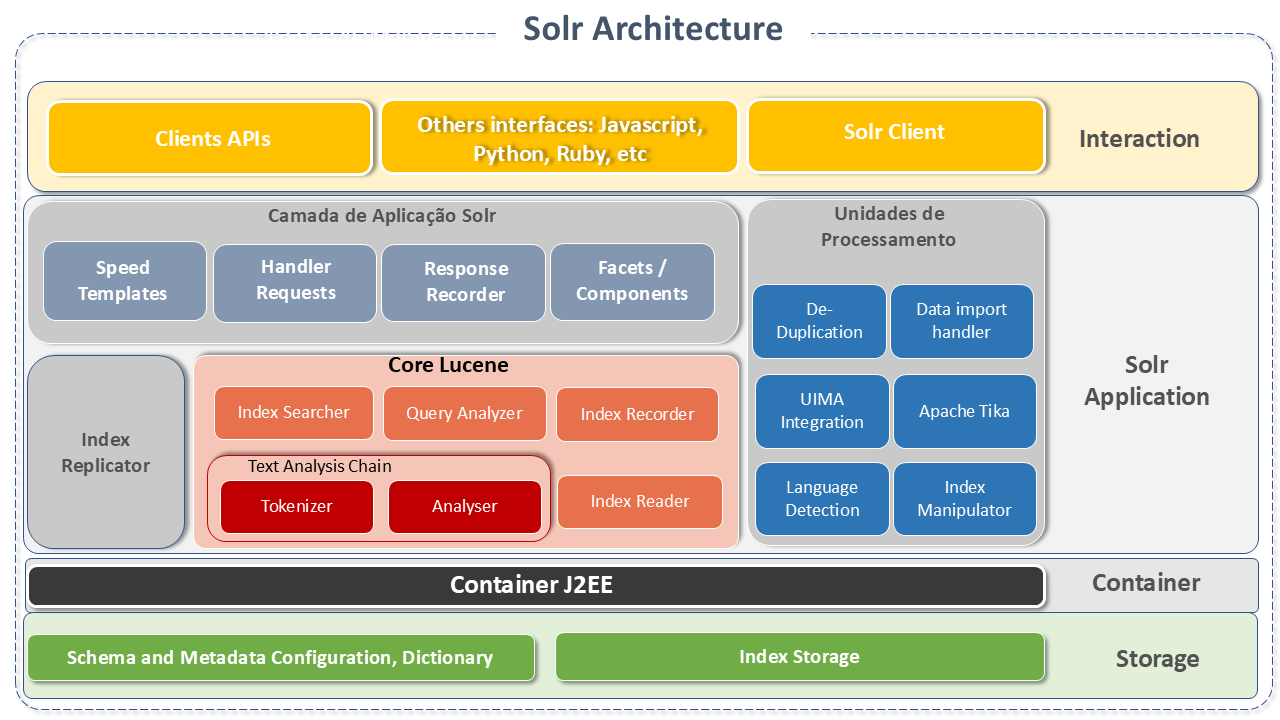
Apache Solr Architecture
Apache Solr is designed for scalability and fault tolerance. It runs as a standalone text search server.
Apache Solr runs on top of the Lucene software library which is, in fact, the engine that powers it. The Solr core is an instance of the Lucene index, where all the configuration files needed to use it are located. The Lucene Java Search Library is used for indexing and full-text searching and has HTTP/XML and JSON REST-like APIs that make Solr usable in the most popular programming languages.
Its external configuration allows it to adapt to many types of applications without Java coding and its plug-in architecture supports more advanced customizations.
SOLR queries are simple HTTP request URLs and the responses are a structured document in JSON, XML, CSV or other format. The documents (indexing) are placed in it via JSON, XML, CSV or binary over HTTP. It is queried via HTTP GET and receives JSON, XML, CSV or binary results.
Solr runs on a non-slave architecture, as every node is its own master. The nodes use Zookeeper to learn about the state of the Cluster and each node (JVM) can host several cores (where Lucene runs).
Queries are configured and managed in the schema.xml and solrconfig.xml files.
The main components of the Apache Solr architecture are:
-
RequestHandler: Requests received in Apache Solr are processed by the Request Handler. The request can be a query or an index update. Based on the request, the request handler is selected. The handler is usually mapped to an end-point URI through which the request will be fulfilled.
-
Search Resource: Provides the search facility to Apache Solr. This can be spell checking, querying, faceting, hit highlighting, etc.
-
Query Parsers. They analyze queries and check for syntax errors. After analysis, they translate the queries into a format understood by Lucene. Solr supports several query parsers.
-
Response Writer: This is the component that generates the formatted output for the user's query. The supported formats are XML, JSON, CSV, etc. There are different response writers for each type of response.
-
Parser / tokenizer: Lucene recognizes data in the form of tokens. Apache Solr analyzes the content, divides it into tokens and passes these tokens on to Lucene. An Analyzer in Apache Solr examines the text of fields and generates a "token stream". A tokenizer divides the token stream prepared for the parser into tokens.
-
Update Request Processors: Every update request will execute through a set of plugins (signing, logging, indexing), collectively known as an "update request processor". This processor is responsible for modifications such as "field removal, field addition, etc."
Apache Solr terminology
-
Cluster Solr nodes operating in coordination with each other via Zookeeper and managed as a unit. A Cluster can contain several collections.
-
Collections:** One or more documents grouped together in a single logical index using a single configuration and Schema. In the cloud, the collection can be divided into multiple logical fragments, which in turn can be distributed over several nodes or on a single node.
-
Node In the Solr cloud, each unique Solr instance is considered a node.
Commit: Enables permanent changes to the index.
-
Core:** An individual Solr instance (representing a logical index). Several cores can run on a single node.
-
Shard(fragment): This is a logical partition of the collection that holds a subset of its documents, so that each document in a collection is contained in exactly one Shard.
When a document is sent to a node for indexing, the system first determines which "shard" the document belongs to, and then which node hosts its Leader, forwarding the document to this leader for indexing, which in turn forwards it to all the other replicas. -
Replication: When the index is too large for a single machine and there is a volume of queries that single shards can't keep up with, it's time to replicate each shard. In the Solr core, the replica is a copy of the shard that is executed on a node.
Leader: This is the shard replica that distributes the Solr Cloud requests to the other replicas.
Apache Solr features
Solr offers rich and flexible search capabilities. Its main features include:
Text search: Powered by Lucene, Solr allows matching features such as phrases, wildcards, joins, clusters and more on any type of data.
-
Highlighting: Allows document fragments that match the query to be included in your answer.
-
Faceting: Organizing search results into categories based on indexed terms.
-
Real-time indexing:: Solr allows you to create an index with many different fields or input types. A Solr index can accept data from many different sources, such as XML, CSV or data extracted from tables in databases and files in common formats such as Word or PDF.
-
Result Collapsing and Expanding: Groups documents (collapsing the result set) according to parameters and provides access to the document in the "collapsed" grouping for use in a "display" or application.
-
SpellChecking: Designed to provide online query suggestions based on other similar terms.
-
Database integration
-
NoSQL features:** The realtime get unique-key feature allows retrieval of the latest version of any documents without the cost of reopening a searcher. This is especially useful when using Solr as a NoSQL data store and not just a search index.
Real Time Get depends on the update log feature, which is enabled by default and can be configured in
solrconfig.xml.
Some of the most famous sites on the Internet use Solr, such as Macy, Ebay, Zappo.
Best Practices for Apache Solr
-
Indexed fields:** The use of cloud storage can be greatly optimized by controlling the number of indexed fields.
Indexes represent a critical factor between quality, performance and cost, and too many can degrade performance and increase costs.
In the field definition, try not to mark fields as indexed=true if they are not used in a query.
The number of indexed fields increases:- Memory usage during indexing.
- Segment merging time.
- Optimization time.
- The size of the index.
-
Storing fields: Retrieving stored fields from the query result can be costly. This cost is affected by the number of bytes stored per document. The higher the byte count, the more sparse the distribution of documents on disk - which requires more I/O bandwidth to retrieve the desired fields.
These costs increase in cloud implementations. Obviously, their use must weigh up quality, performance and cost.
-
Use of the Solr Cache: Solr caches various types of information to ensure that similar queries are not repeated unnecessarily.
The Document Cache helps improve the time it takes to answer requests.
There are three main types of cache:- Query cache: stores document IDs returned by queries.
- Filter cache: stores filters created by Solr in response to filters added to queries.
- Document cache: stores the fields of the document requested when query results are displayed.
-
Autowarming: Enabling autowarming can significantly increase the performance of a search for any of the three cache types.
By increasing autowarmCount, Solr will pre-fill or autowarm the cache with the cache objects created by the search result.
This setting indicates the number of items in cache that will be copied to the new "searcher". -
Streaming Expressions: Solr offers a simple but powerful streaming processing language for the Solr Cloud.
Streaming expressions are a set of functions that can be combined to perform many parallel computing tasks. -
JVM Memory Heap: The heap is an area of memory in which application objects, created from classes (with reference semantics), are stored. Objects that are referenced somewhere are allocated there.
This area is managed by the garbage collector and occupies space as needed. At some point in the future, the GC will release the spaces when the data in a given portion is no longer needed.
In the case of JVM (Java Virtual Machine) memory, much of the allocation is already reserved in advance by the GC, which tries to manage the memory in the best possible way.
The heap settings of JVM memory directly affect the use of system resources.
In a cloud environment, resource usage and costs can increase rapidly, which can directly affect performance and the success or failure of a search implementation.- Adding enough space
Several tools, usually included in standard Java installations, show the minimum amount of memory consumed by the JVM when running Solr (including jconsole).
Without enough memory for heap, the JVM can increase resource consumption due to frequent execution of the garbage collection process.
An additional 25% to 50% of the minimum memory required to operate at maximum performance is recommended.
O.S. memory:
Care must be taken when allocating heap JVM memory, as Solr makes extensive use of the org.apache.lucene.store.MMapDirectory component.
This component takes advantage of the Operating System (OS) that is used by the MMapDirectory component.
In this way, the more heap JVM memory is allocated, the less memory is available for the Operating System, which also impairs search performance. - Adding enough space
Several tools, usually included in standard Java installations, show the minimum amount of memory consumed by the JVM when running Solr (including jconsole).
It is necessary to find a balance.
The ideal size of the JVM memory heap:
A range between 8 and 16 Gb is adequate. It is recommended to start with the smallest value and run tests, monitoring memory usage and gradually adjusting the size until the ideal size is reached.
- Garbage Collector:**
This is a term used for the process in which memory freed in a Java program is returned to the memory pool for reuse.
The collector used before Java version 9 was ParallelGCf. The G1GC Collector operates in a simultaneous multi-threaded manner and addresses latency problems that exist in ParallelGC.
Its use is therefore recommended.
In addition, the Solr control script comes with a set of pre-configured Java garbage collection configurations that work well for many different workloads. But these settings may not work so well for a particular use.
In this case, the GC settings can be changed, which should also be done with the GC_TUNE variable in /etc/default/solr.in.sh.
Recommended fine-tuning of the production configuration
-
Memory and GC settings
By default, script bin/solr sets the maximum Java heap size to 512M (-Xmx512m), which is a reasonable number to start working with Solr.
For production, it is appropriate to adjust the maximum size based on the memory requirements of the search applications. Values between 10 and 20 Gb are common. To change these settings, use the SOLR__JAVA__MEM variable:Terminal inputsolr_java_mem="-Xms10g -Xmx10g" -
Shutdown_ due to lack of memory: The script bin/solr registers script bin/oom_solr.sh to be called by the JVM if an OutOfMemory error occurs, which will issue a kill -9 to the Solr process.
This behavior is recommended when running in SolrCloud mode so that Zookeeper is immediately notified that a node is showing an unrecoverable error.
It is recommended to inspect the contents of script /opt/solr/bin/oom_solr.sh to familiarize yourself with the actions that script will perform if called by the JVM. -
SolrCloud mode:
To run Solr in SolrCloud mode you need to set the ZK_HOST in the include file to point to the Zookeeper assembly.
Running the embedded Zookeeper is not supported in production environments. If a Zookeeper set is hosted, for example, on three hosts on the default client port 2181(zk1, zk2, zk3), you will need to set:Terminal inputzk_host=zk1,zk2,zk3When the ZK__HOST variable is set, Solr will start in cloud mode.
-
Zookeeper:
When using a Zookeeper instance shared by other systems, it is recommended to isolate the SolrCloud znode "tree" using Zookeeper's chroot support.
To ensure that all znodes created by SolrCloud are stored in /solr, for example, use:Terminal inputzk_host=zk1,zk2,zk3/solrBefore using a chroot for the first time, you need to create the root path (znode) in Zookeeper using the Solr control script. The mkroot command can be used:
Terminal inputbin/solr zk mkroot /solr -z <ZK_node>:<ZK_PORT> -
Hostname Solr:
Use the SOLR_HOST variable in the include file to set the hostname of the Solr server.Terminal inputsolr_host=solr1.example.comThis is especially recommended when running in SolrCloud mode, as it determines the node's address when it registers with Zookeeper.
-
Replacing settings in solrconfig.xml:
Solr allows configuration properties to be overridden using Java system properties passed at startup via the -Dproperty=value syntax. -
Running multiple Solr nodes per host: bin/solr is capable of running multiple instances on one machine, but for a typical installation, this configuration is not recommended.
Extra CPU and memory resources will be required for each additional instance.warningThis rule does not apply when discussing extreme scalability. Running several Solr nodes on one host is a good alternative when you want to reduce the need for extremely large heaps. For more details see here.
Apache Solr language
Solr is written in Java.