Trino
Distributed Query Engine
A distributed query engine is designed to execute complex SQL queries on large volumes of data spread across multiple sources. It eliminates the need to move or duplicate data, allowing analytics to be performed directly where the data is stored, increasing efficiency and scalability.
Key Features of a Distributed Query Engine:
- Parallel Execution: Breaks queries into smaller tasks, which are processed simultaneously across different nodes in a cluster, optimizing execution time.
- Connection to Multiple Data Sources: Provides integration with data lakes, data warehouses, and relational databases, enabling federated query execution.
- SQL as a Universal Language: Analysts can perform queries using SQL without the need to learn specific languages.
- Optimized Performance: Uses techniques like predicate pushdown and in-memory storage to reduce latency and maximize performance.
Common use cases for distributed query engines include:
- Federated queries across multiple data sources.
- Real-time analysis of large volumes of data.
- Unifying data lakes and data warehouses to simplify governance and auditing.
Its basic operation involves:
- The client sends a query to the engine.
- The engine interprets the query, creates an execution plan, and distributes tasks to the workers.
- Each worker processes its part, accessing data sources directly.
- The results are consolidated and sent back to the client.

Key Features of Trino
Trino is an open-source distributed query engine designed to execute SQL queries on large volumes of data stored in diverse sources such as data lakes, data warehouses, and relational databases.
Initially developed as Presto by Facebook engineers to meet its internal data analysis needs, Trino emerged in 2020 after a split from the Presto Foundation. Since then, it has become a benchmark for high-performance solutions in distributed data analytics.
Key Features:
- Speed: Designed for low-latency analytics, Trino uses highly parallel and distributed execution to process queries efficiently.
- Horizontal Scalability: Enables adding workers to increase processing capacity, capable of handling workloads at the exabyte scale, such as in large data lakes and data warehouses.
- Simplicity: Compatible with ANSI SQL, facilitating integration with BI tools like R, Tableau, Power BI, Superset, and more.
- Versatility: Supports interactive ad hoc analyses, long-running batch queries, and high-volume applications, ensuring sub-second response times in critical scenarios.
- Local Analysis: Queries data directly from sources like Hadoop, S3, Cassandra, and MySQL, eliminating the need to copy or move data, simplifying processes and reducing errors.
- Federated Queries: Enables executing queries across multiple data sources, such as HDFS, S3, relational databases, and data warehouses.
- High Performance: Its architecture is optimized for interactive workloads, ensuring minimal latency.
- Extensibility: Supports custom connectors, allowing integration with new data sources.
- Reliability: Widely used in mission-critical operations, such as financial reporting for public markets, by some of the largest global organizations.
- Support for Various Formats: Compatible with formats like Parquet, ORC, Avro, JSON, and CSV.
- Open Community: Developed under the leadership of the Trino Software Foundation, a nonprofit organization.
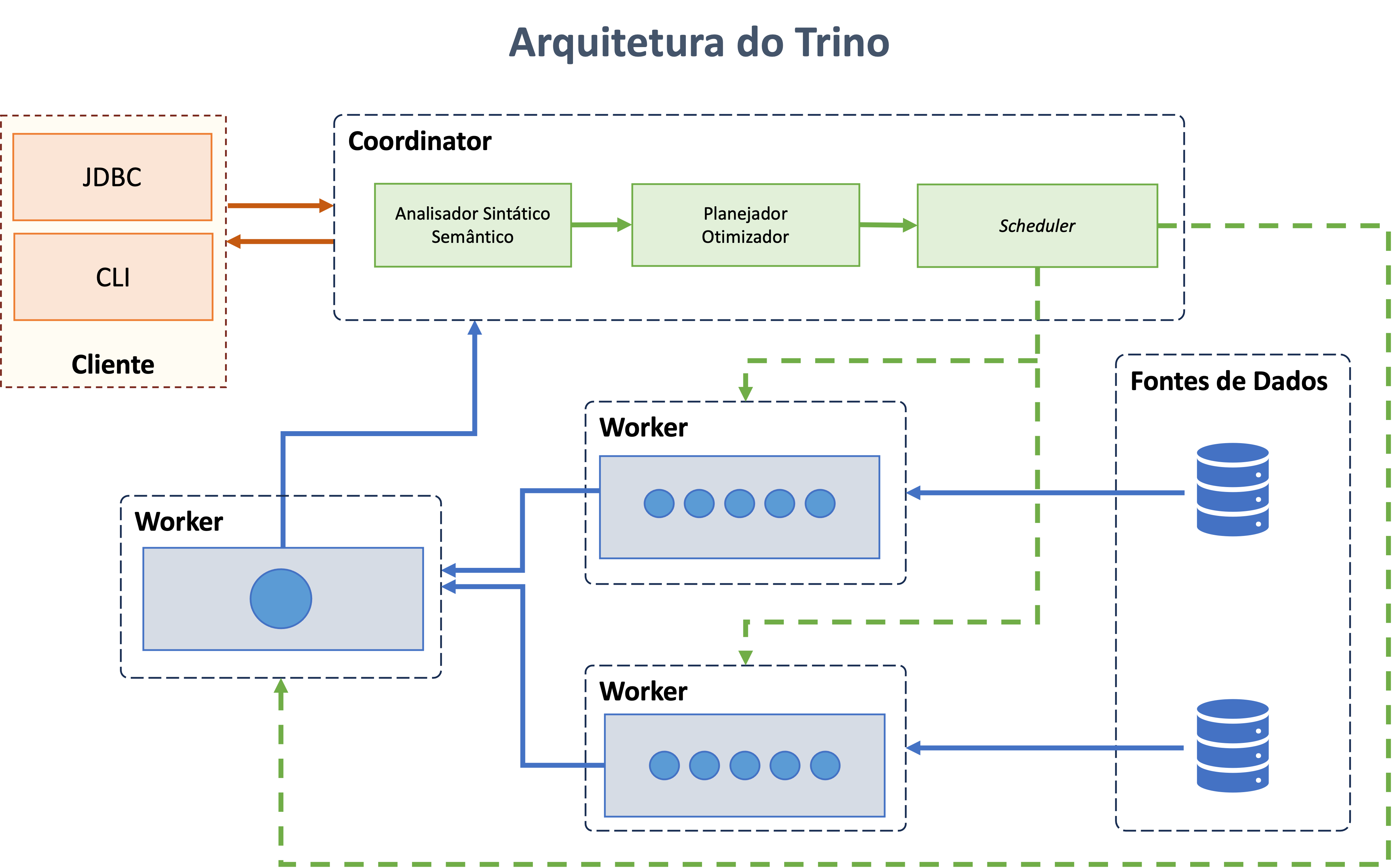
Trino Architecture
Trino is a distributed query engine that processes data in parallel across multiple servers. Trino Clusters Servers are classified as Coordinators and Workers.
The following sections describe the main components of Trino's architecture.
Cluster
A Trino cluster consists of multiple nodes, including a Coordinator and zero or more Workers. Users connect to the Coordinator through SQL query tools. The Coordinator orchestrates tasks among the Workers and accesses connected data sources through configured catalogs.
Each query is processed as a stateful operation. The Coordinator distributes the workload among the Workers in parallel. Each node runs a single JVM instance, with additional parallelization using threads.
Node
A Node in Trino refers to any server within a cluster running a Trino process. It typically corresponds to a single machine since only one Trino process is recommended per machine.
Coordinator
The Coordinator is the central server responsible for parsing instructions, planning queries, and managing Worker nodes. Acting as the "brain" of the cluster, it tracks Worker activity, coordinates query execution, and communicates with clients and Workers via the REST API.
For development or testing, a single Trino instance can be configured to function as both a Coordinator and a Worker.
Worker
A Worker is a server responsible for executing tasks and processing data. Workers fetch data from connectors, exchange intermediate data, and communicate with the Coordinator via the REST API. Upon startup, a Worker registers with the Coordinator's discovery server for task allocation.
Client
Clients connect to Trino to send SQL queries and retrieve results. They can access configured data sources through catalogs and include tools such as command-line interfaces, desktop applications, and web-based systems. Some clients also support interactive query authoring, visualizations, and reports.
Data Source
Trino supports querying various data sources, including data lakes, relational databases, and key-value stores. Access to these data sources is configured using catalogs, which define the necessary connectors, credentials, and other parameters.
Below are the fundamental concepts associated with Data Sources in Trino:
-
Connector: Connectors allow Trino to interact with specific data sources, functioning like database drivers. Examples include connectors for Hive, Iceberg, PostgreSQL, MySQL, and Snowflake. Each catalog in Trino is associated with a connector.
-
Catalog: A catalog is a collection of configuration properties for accessing a data source. Catalogs are defined in property files stored in Trino’s configuration directory. A catalog can contain schemas and tables, enabling access to multiple data sources within a single cluster.
-
Schema: Schemas organize tables and other objects within a catalog. They correspond to similar concepts in databases like Hive and MySQL.
-
Table: A table consists of unordered rows organized into named columns with specific types. Tables are accessed by fully qualified names rooted in catalogs.
Trino Query Execution Model
Trino executes SQL statements by transforming them into distributed queries executed across the cluster.
Below are more details about the terms used in Trino's query execution model:
-
Statement: A statement refers to the SQL text sent to Trino. It is converted into a query plan during execution.
-
Query: A query encompasses the components and configuration needed to execute a statement. It includes stages, tasks, splits, and operators.
-
Stage: Stages represent sections of a distributed query plan, organized hierarchically. Each query has a root stage that aggregates outputs from other stages.
-
Task: Tasks execute stages in parallel on Workers. They operate on splits and involve multiple drivers to process data.
-
Split: A split is a segment of a larger dataset processed by a task. The Coordinator assigns splits to tasks based on availability.
-
Driver: Drivers are the smallest units of parallelism, combining operators to process data within a task.
-
Operator: Operators perform transformations on data, such as table scans or filters, and are combined within drivers.
-
Exchanges: Exchanges transfer data between nodes during query execution, allowing communication between stages through output buffers and exchange clients.
Trino Project Details
Trino was developed in Java, leveraging the robustness of the JVM for distributed processing.

Sources:
Trino - Overview