Apache HDFS
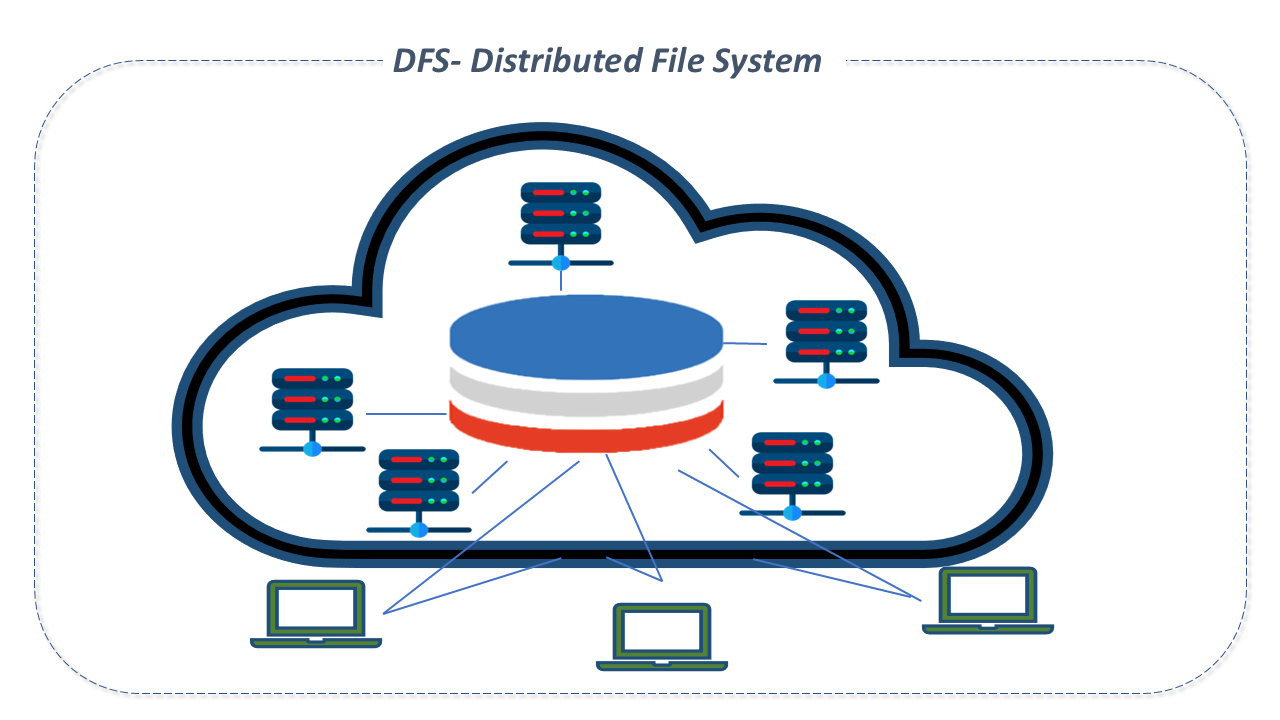
Distributed File System
A distributed file system (DFS) is a file system that enables client access to data stored on multiple servers, through a computer network, as if accessing local storage.
Files are distributed across multiple storage servers and in multiple locations, which allows for the sharing of data and resources.
DFS groups several storage nodes and logically distributes data sets on them, each with its own configuration. Data may reside on various types of devices, such as solid-state drives and hard disks.
Data is replicated, which facilitates redundancy to achieve availability.
To expand the infrastructure, the organization needs only to add more nodes to the system.
Apache HDFS Features
HDFS (Hadoop Distributed File System) is the primary storage system used by Hadoop.
It is an extremely reliable distributed file system, designed to run on commodity hardware that works with high data transfer rates between nodes.
HDFS was originally built as infrastructure for the Apache Web Nutch search engine project and today is part of the core of the Apache Hadoop project. It has many similarities with existing distributed file systems. However, its differences are significant:
- it is highly fault-tolerant
- it is designed for low-cost hardware
- it offers high throughput for data access
- it is suitable for handling large data sets.
We highlight below some of its main features:
-
Fault tolerance:
An instance of HDFS can consist of thousands of servers storing part of the data of a file system, which involves a large number of components. This increases the likelihood of failures because, at some point, one or more components may become non-functional. For this reason, fault tolerance is the primary premise of HDFS. The detection of failures and quick, automatic recovery is its central architectural goal. -
Streaming data access:
The data access pattern is streaming data, i.e., data generated in real time and in continuous flow. -
Support for large data sets:
A common file in HDFS can easily reach terabytes in size, as applications running on HDFS handle large data sets. HDFS has been tuned to provide high aggregate bandwidth, scale to hundreds of nodes in a single cluster, and support tens of millions of files in a single instance. -
Simple Coherence Model:
HDFS was designed based on the write-once-read-many principle. Once data is written, there is no support for updates at an arbitrary point or changes except for appends and truncates. This premise simplifies data coherence issues and ensures high throughput in data access. A MapReduce application or a web crawler fits perfectly into this model. -
Interfaces that bring applications closer to data:
Computing requested by an application is always more efficient if executed close to the data it operates on. Especially when the dataset size is large, it minimizes network congestion and increases the overall system throughput. HDFS provides interfaces for applications to be close to the data. -
Portability across heterogeneous hardware and software platforms:
HDFS was designed to be easily "portable" from one platform to another. This facilitates its widespread adoption as a platform for a large set of applications.
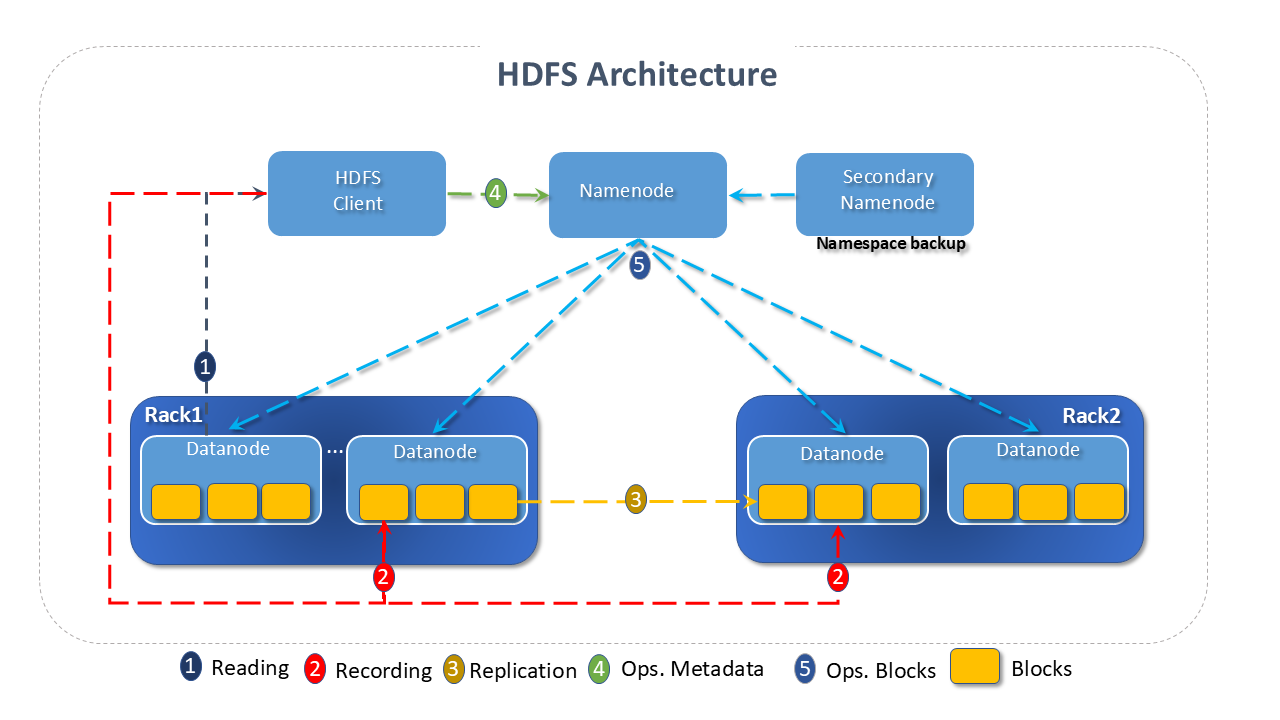
Architecture of Apache HDFS
The architecture of HDFS is a master/slave type, in which a single master (the Namenode) controls the operation of the others, the slaves (DataNodes).
HDFS divides a file into blocks, which are stored as independent units, facilitating the processes of distribution, replication, recovery, and processing.
-
Namenode:
The Namenode is the central piece of the HDFS file system. It is responsible for mapping the blocks to the DataNodes, determining where they and their replicas should be stored, and registering to which file each block belongs. The Namenode operates through the files:- fsimage: which stores which blocks belong to each file
- edit log: which stores write operations on the system.
noteWhen the system is initialized, the Namenode loads all the information from the fsimage into its memory, registering the current state of the system. It then records modifications through the edit log to update the system.
-
Client applications interact with the Namenode whenever they want to locate or work with a file (copy, move, delete), and the Namenode responds to the requests by returning a list of servers where the data resides.
-
When a client executes a write operation, it is recorded in the edit log, and then the filesystem namespace is modified (where the file information is stored). The filesystem namespace is stored locally.
-
The Namenode performs operations on the filesystem namespace, such as opening, closing, renaming files, and directories. Additionally, any changes to the namespace are recorded by the Namenode.
-
An HDFS cluster consists of a single Namenode, which greatly simplifies the system architecture.
-
The community has developed several guidelines that are noteworthy regarding the Namenode:
In the new HA (High Availability) architecture, the cluster consists of Namenodes in three distinct states: active, standby, and observer.
-
Datanodes:
The DataNodes are responsible for responding to read and write requests from the file system's clients and for storing the blocks. -
The DataNodes are spread throughout the cluster, usually one per node:
- They are responsible for creating, deleting, and replicating blocks, under instructions from the Namenode.
- Blocks are usually read from the disk, however, frequently accessed blocks may be cached within the DataNode. Thus, scheduling managers can run tasks on nodes where the block is cached, improving performance.
noteA heartbeat indicates that the DataNode is operational. A block report indicates which blocks are stored on the DataNode. These data allow the Namenode to know in advance which DataNodes are available for storage and for reading, thus avoiding directing the client to DataNodes that are not operational.
Namenodes and Datanodes are software components designed to run on common machines. These machines generally run a GNU/Linux operating system.
-
A typical deployment has one dedicated machine that runs only the NameNode software.
-
Each of the other machines in the cluster runs an instance of the DataNode software.
-
The architecture does not prevent multiple DataNodes from running on the same machine, but in a real deployment, this case is very rare.
Apache HDFS Resources
-
File System Namespace: HDFS supports the traditional hierarchical organization of files. A user or an application can create directories and store files within these directories.
noteThe file system namespace hierarchy is similar to most other existing file systems: one can create and delete files, move a file between directories, or rename it.
-
Userquotas (User Quotas Support) Allows the administrator to set quotas for the number of names and the volume of space used for individual directories. Name quotas and space quotas operate independently, but their administration and implementation are parallel.
-
Access Permissions (Access Permissions Support) Implements a permissions model for files and directories that shares much with the POSIX model.
-
Data Replication: HDFS is designed to store large files across machines in a large cluster. Each file is stored as a sequence of blocks that are replicated to ensure fault tolerance. Block size and replication factor are configurable per file. All blocks of a file, except the last one, are the same size, and users can start a new block without filling the last one to the configured size, after support for variable-length block was added for append and hsync. An application can specify the number of replicas of a file. This number is called the replication factor and can be set at creation and modified later. The replication factor is stored by the NameNode, which is responsible for making all decisions about data replication. By default, the number of replicas is 3 (three), and the blocks are placed so that the first is on a different rack from the others, and the second is on the same rack as the third but on separate nodes. This way, the system can handle two types of failures: DataNode failures and rack failures. Additionally, this policy improves write operations by reducing bandwidth, considering that between distinct racks, it is lower than within the same rack since the data is in two distinct racks, not three, which would be the simplest policy. HDFS tries to satisfy requests with a replica closest to the client.
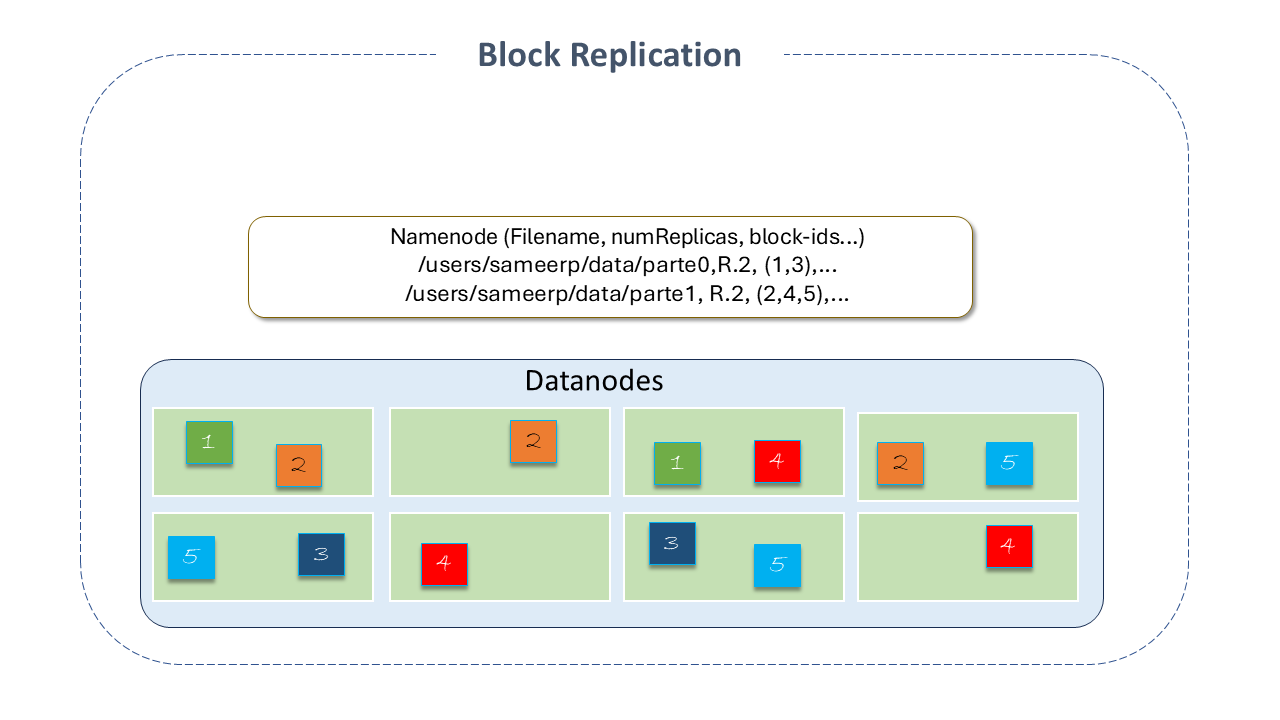 Figure 1 - Block Replication
Figure 1 - Block Replication-
Replica Placement: The placement of replicas is critical to ensuring HDFS reliability and performance. Optimizing their placement distinguishes HDFS from most other distributed file systems. It is a feature that requires much tuning and experience. The implementation of the replica placement policy is a first effort in this direction.
After support for Storage Types and Storage Policies was added to HDFS, the NameNode takes into account the policy for replica placement, besides the rack awareness.
Details on this can be found in "Replicas Placement: The First Baby Steps" on the community site. -
Replica Selection:
To minimize global bandwidth consumption and latency, HDFS tries to satisfy a read request from a replica that is closest to the reader. If there is one on the same rack as the reader node, this replica will be preferred to satisfy the request. If the HDFS cluster spans multiple datacenters, the replica in the local datacenter will be preferred over remote ones. -
Block Placement Policies: When the replication factor is 3 (three), the HDFS placement policy is to place one replica on the local machine, if the writer is on a DataNode, otherwise, on a random DataNode in the same rack as the writer, another replica on a node in a different remote rack, and the last on a different node in the same remote rack.
When the replication factor is greater than 3, the placement of the additional replicas is determined randomly, keeping the number of replicas per rack below the upper limit (calculated as: replicas-1/racks+2). Additionally, HDFS supports four distinct pluggable block placement policies.
Users can choose the policy based on their infrastructure and use case. By default, HDFS supports BlockPlacementPolicyDefault. -
Safemode: Upon startup, the NameNode enters an initial state called safemode. Block replication does not occur in this situation. The NameNode receives Heartbeat and Blockreport messages (with the list of data blocks a DataNode is hosting) from the DataNodes.
Each block has a specified minimum number of replicas. A block is considered safely replicated when the minimum number of replicas for the data block is verified with the NameNode. After a configurable percentage of safely replicated data blocks check in with the NameNode (plus an additional 30 seconds), the NameNode exits safemode and then determines the list of data blocks (if any) that still have fewer than the specified number of replicas. The NameNode then replicates these blocks to other DataNodes.
-
-
HDFS Federation: HDFS Federation adds support for multiple NameNodes/NameSpaces to HDFS.
-
Viewfs: ViewFs (View File System) provides a way to manage multiple Namespaces (or Namespace volumes). It is particularly useful for clusters with multiple NameNodes and also multiple NameSpaces in HDFS Federation. It is analogous to client-side mount tables in Unix-Linux systems. It can be used to create personalized views of Namespaces and also common views across the cluster.
-
Snapshots: Snapshots are read-only "point-in-time" copies of the file system. Common use cases for snapshots are data backup, protection against user errors, and disaster recovery.
-
Edits Viewer: Allows analysis of the edits log file. It operates on files only and does not require the Hadoop cluster to be running.
-
ImageViewer: A tool that dumps the content of HDFS fsimage files into a "readable" format and provides a read-only WebHDFS API for offline analysis and examination of a Hadoop cluster's Namespace.
-
Centralized Cache Management: Allows specifying paths to be cached by HDFS.
-
NFS Gateway: Allows HDFS to be mounted as part of the client's local file system. It supports NFSv3.
-
Transparent Encryption: HDFS implements end-to-end transparent encryption. Once configured, data read from and written to special HDFS directories are encrypted and decrypted transparently without requiring changes to the user's application code.
-
Multihomed Networks: HDFS supports multihomed networks, where cluster nodes are connected with more than one network interface. There are several reasons to use it, such as security, performance, and fault tolerance.
-
Memory Storage Support: HDFS supports writing to off-heap memory (managed by the developer) managed by DataNodes.
-
Synthetic Load Generator: A testing tool that allows verifying the NameNode's behavior under different client loads.
-
Disk Balancer: A command-line tool that distributes data evenly across all DataNode disks. It is different from the Balancer, which takes care of data balancing in the cluster. The Disk Balancer operates by creating and executing a plan on the DataNode. It is enabled by default in a cluster.
-
DataNode Administration Guide: A tool that allows operations such as:
- DataNode maintenance mode, created to allow repairs/maintenance.
- Decommissioning DataNodes.
- Recommissioning.
-
Router Federation: Adds a software layer to "federate" the Namespaces, allowing users to access any sub-cluster transparently.
-
Provided Storage: Allows data stored outside HDFS to be mapped and addressed from HDFS.
-
Observer NameNode: In an HDFS cluster enabled for high availability (HA), there is a single Active NameNode and one or more Standby NameNodes. The Active NameNode is responsible for serving all client requests, while the Standby NameNode only keeps up-to-date information about the Namespace and block locations, receiving reports from all DataNodes. The Observer NameNode feature addresses these functions via a new NameNode called "Observer NameNode." Like the Standby NameNode, the Observer NameNode stays updated on the Namespace and block location information. But additionally, it has the ability to produce consistent reads like the Active NameNode. Since read requests constitute a large part of a typical environment, this helps balance the NameNode traffic load and improve overall throughput.
Important Notes
-
Although HDFS follows the Filesystem naming convention, some paths and names (e.g., /.reserved and .snapshot) are reserved. Features like transparent encryption and snapshot use reserved paths.
-
Currently, HDFS does not support hard links (the link acting as a pointer to a file or directory inode) or soft links (or symbolic link - acting as a pointer or reference to the file name). However, its architecture does not prevent the implementation of these features.
Details of Project Apache HDFS
HDFS was built in the Java language, highly portable, which makes it implementable on a wide variety of machines. Any machine that supports Java can run the NameNode or DataNode software.
Sources: Hadoop Documentation