Apache Druid
Real-Time Analytical Database
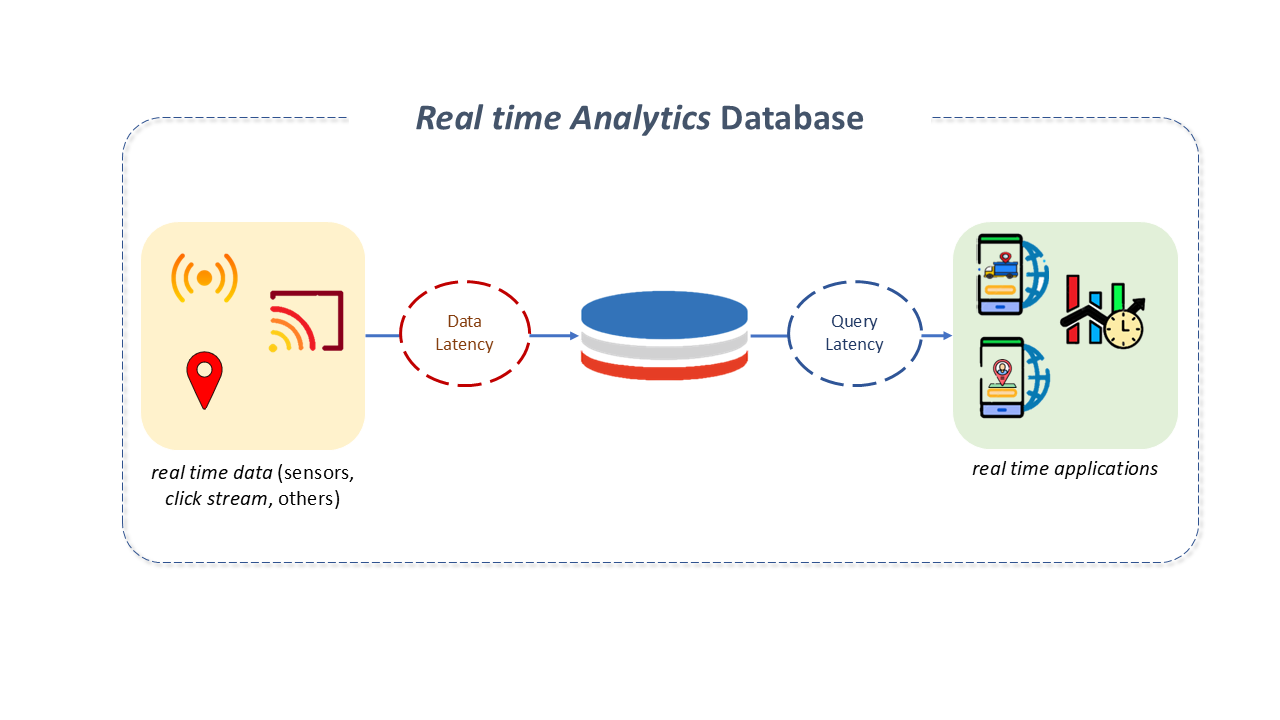
The ability to store, process, and retrieve data at very high speeds is one of the main requirements met by a Real-Time Analytical Database.
In traditional DBMSs, deriving value from data is a difficult task because the data needs to be moved, transformed, and loaded into a Data Warehouse or Data Lake before consumption. This takes time, sometimes hours, often days.
Streaming mechanisms, like Kafka, help, but only to a certain extent, as the fundamental need is a database with the power to process large amounts of data in real time.
Real-time analytical databases optimize resources to allow for heavy workloads. They feature lightweight ingestion protocols and efficient disk storage structures to allow very fast ingestions. Their architecture uses massively parallel processing with a high degree of concurrency, avoiding high infrastructure costs.
Apache Druid Features
Apache Druid is a real-time analytical database management system designed for fast, fragmented analyses (OLAP queries) on large datasets. It empowers use cases where real-time ingestion, fast query performance, and high productivity are important.
Its origin dates back to 2011 when a tech company's data team decided to create their own database after trying several market alternatives to solve a real-time data aggregation and query problem from the Internet to analyze digital ad auctions. The first version of Druid scanned, filtered, and aggregated a billion rows in 950 milliseconds.
Druid became open source after a few years and an Apache Software Foundation top-level project in 2016.
In 2023, more than 1400 organizations use Druid, and the tool has over 10,000 active developers in its community.
Among its main features, we highlight:
-
Scalability and Flexibility: Its elastic and distributed architecture allows the creation of any application at any scale.
-
Efficiency and Integration: Druid's motto is "do it only if necessary," minimizing the Cluster's work:
- Does not load data from disk to memory (or vice versa) when not needed.
- Does not decode data if it can operate directly on encoded data.
- Does not read the entire dataset if it can read a smaller index.
- Does not start new processes for each query if it can use a long-running process.
- Does not send unnecessary data between processes or servers.
- The Druid query engine and storage format are fully integrated and designed together to minimize the work done by data servers.
- Generally used as a backend database for GUI ("Graphical User Interface") analytical applications or for highly concurrent APIs demanding fast aggregations.
-
Resilience and Durability: Druid is "self-healing," "self-balancing," and fault-tolerant. It is designed to operate continuously without downtime, even during configuration changes and software updates, preventing data loss, even in case of major system failures. Its Cluster rebalances itself automatically in the background without downtime. When a server fails, the system "absorbs" the failure and continues operating.
-
High Performance: Druid's combine features to allow high performance in high concurrency, avoiding unnecessary work.
-
High Concurrency: This was one of the original goals of the Druid project. Many Clusters support hundreds of thousands of queries per second. The key to this is the unique relationship between storage and computing resources. Data is stored in segments, which are checked in parallel by scatter/gather queries.
-
High-Speed Data Ingestion: For streaming ingestion, middle managers and indexers are enabled to respond to queries in real-time. All tables are always fully indexed, making index creation unnecessary.
-
Druid works best with event-oriented data. Common application areas for Druid include:
- Clickstream analysis, including web and mobile analytics.
- Network telemetry analysis, including network performance monitoring.
- Server metrics storage.
- Supply chain analysis, including manufacturing metrics.
- Application performance metrics.
- Digital marketing/advertising analysis.
- Business intelligence (OLAP).

Apache Druid Architecture
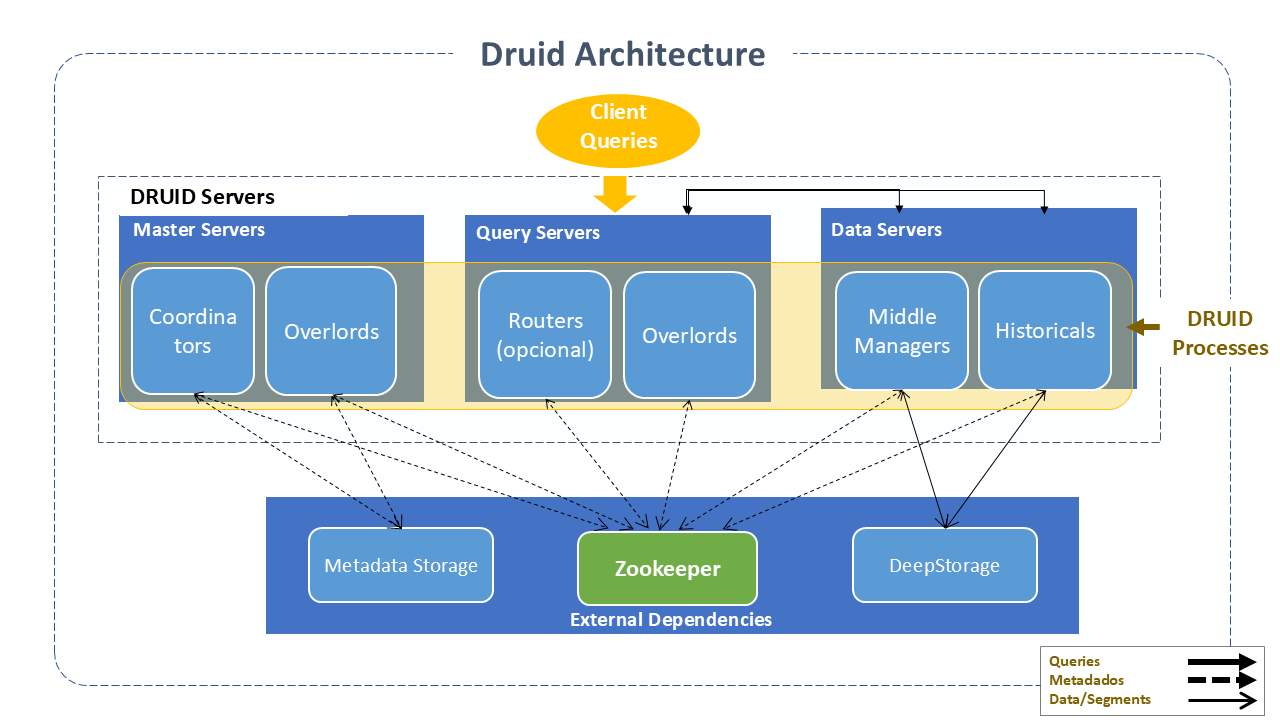
Apache Druid has a distributed architecture designed to be cloud-friendly and easy to operate. Services can be configured and scaled independently, ensuring maximum flexibility in Cluster operations.
Druid combines ideas from data warehouses, time-series databases, and log search systems.
Some of its main components include:
Druid Services (Process Types)
-
Coordinator: Manages data availability in the Cluster.
-
Overlord: Controls the assignment of workloads for data ingestion.
-
Broker: Handles queries from external clients.
-
Router Services (optional): Route requests to Brokers, Coordinators, and Overlords.
-
Historical Services: Store queryable data.
-
The MiddleManager Services: Ingest data for most ingestion methods.
-
Indexer (optional and experimental): Acts as an alternative to "MiddleManager + Peon". Instead of forking a separate JVM process per task, the indexer runs tasks as separate threads within a single JVM process.
noteServices can be viewed in the Services Tab in the web console.
Servers
Druid servers can be deployed in any desired way. To facilitate deployment, it is suggested to organize them into three types:
- Master: Runs Coordinator and Overlord processes, manages data availability and ingestion.
- Query: Runs Broker and optional Router processes and handles queries from external clients.
- Data: Runs Historical and MiddleManager processes, performs ingestion workloads, and stores all queryable data.
External Dependencies:
In addition to its built-in process types, Druid also has three external dependencies that leverage existing infrastructure when present:
- Deep Storage: As part of ingestion, Druid securely stores a copy of the data segment in Deep Storage, creating a continuous and automated additional copy of the data in the cloud or HDFS. It makes the segment immediately available for queries and creates a replica of each data segment. It is always possible to recover data from Deep Storage, even in the unlikely event that all servers fail.
- Metadata Storage: Contains various shared system metadata, such as segment usage information and task information. In a Cluster deployment, it is usually a traditional RDBMS like PostgreSQL. In a single-server deployment, it can be a local Apache Derby database.
- Zookeeper: Used for active Cluster management, coordination, and leader election.
How Apache Druid Works
Storage Design
-
Datasources and Segments:: Druid data is stored in datasources, which are similar to tables in a traditional RDBMS. Each datasource is partitioned by time and, optionally, by other attributes. Each time interval is called a chunk – for example, a single day, if partitioned by day. Within a chunk, data is partitioned into one or more segments. Each segment is a single file. Once segments are organized into time chunks, it is sometimes appropriate to think of segments as living on a timeline.
A datasource can have from a few segments to hundreds of thousands or millions of segments. Each segment is created by a MiddleManager as mutable and uncommitted. Data can be queried as soon as it is added to an uncommitted segment. The segment building process speeds up later queries, producing a compact and indexed data file:
- Converted to columnar format.
- Indexed with bitmap indexes.
- Compressed with type-aware compression for all columns.
Periodically, segments are committed and published in deep storage, becoming immutable, and passed from MiddleManagers to Historical processes. An entry about the segment is also written in Metadata Storage. This entry is a self-descriptive bit of metadata about the segment, including things like the segment schema, its size, and location in deep storage, informing Coordinators of what data is available in the Cluster.
-
Indexing and Handoff:: Indexing is the process by which new segments are created. Handoff is the process by which they are published and begin to be served by Historical processes.
-
Every segment has a 4-part identifier with the following components:
- Datasource name
- Time interval (for the time chunk containing the segment), which corresponds to the segmentGranularity specified at ingestion time.
- Version number (usually an ISO8601_timestamp_corresponding to when the set of segments was started). This serves multiversion concurrency control.
- Partition number (an integer unique within the datasource+interval+version, not necessarily contiguous).
-
Every segment has a lifecycle involving:
- Metadata storage: Segment metadata is stored in Metadata Storage as soon as the segment finishes being built (publication).
- Deep storage: Segment data files are uploaded to deep storage as soon as the segment finishes being built, before publication.
- Available for querying on a Druid data server, such as a real-time task or a Historical process.
Ingestion:
Loading data into Druid is referred to as ingestion or indexing. When data is ingested into Druid, it reads the data from the source system and stores it in data files called segments. Generally, segments contain a few million rows each.
For most ingestion methods, a MiddleManager or Indexer process will load the data. The only exception is Hadoop-based ingestion, which uses a MapReduce job on Yarn.
During ingestion, Druid creates segments and stores them in deep storage. Historical nodes load the segments into memory to answer queries. For streaming ingestion, MiddleManagers and Indexers can respond to queries in real time as data is being loaded.
Common ingestion methods include:
-
Streaming: Two options are Kafka and Kinesis.
-
Kafka:: When the Kafka indexing service is enabled, supervisors can be configured on the Overlord to manage the creation and lifecycle of Kafka indexing tasks. Kafka indexing tasks read events using Kafka's partition and offset mechanism to ensure exactly-once ingestion. The supervisor monitors the state of indexing tasks to:
- Coordinate handoffs
- Manage failures
- Ensure scalability and replication requirements are met.
-
Kinesis:: When the Kinesis indexing service is enabled, supervisors can be configured on the Overlord to manage the creation and lifecycle of Kinesis indexing tasks. These tasks read events using Kinesis's shard and sequence number mechanism to ensure exactly-once ingestion. The supervisor monitors the state of indexing tasks to:
- Coordinate handoffs
- Manage failures
- Ensure scalability and replication requirements are met.
-
-
Batch: Three options are Native batch, SQL, or Hadoop-based.
-
Apache Druid supports two types of native batch indexing:
- Parallel indexing: Allows multiple indexing tasks to run concurrently.
- Simple indexing: Runs a single task at a time.
-
Hadoop-based Batch Ingestion::
Hadoop-based Batch Ingestion is supported via a task that can be submitted to a running Overlord instance. For comparisons of ingestion types (Hadoop-based, native, and native batch), refer to the community site here.
-
Druid supports SQL-based batch ingestion using the druid-multi-stage-query extension, which adds a multi-stage query engine for SQL, enabling SQL Insert and Replace operations as batch tasks. As an experimental feature, the Select operation can also be used.
-
Query Processing:
Queries are distributed across the Druid cluster and managed by a Broker. Queries first enter the Broker, which identifies the segments with data that may belong to the query. The segment list is always broken down by time and other attributes, depending on how the datasource is partitioned. The Broker identifies which Historicals and MiddleManagers are serving the segments and distributes a rewritten subquery to each of these processes. These processes execute each subquery and return the results to the Broker, which merges them to obtain the final response, returning it to the original caller.
Data Management:
Data management operations involving replacing or deleting segments include:
- Updates
- Deletions
- Schema Changes: For new and existing data.
- Compaction and Automatic Compaction.
SQL Queries:
Queries can be made via Druid SQL (Druid translates SQL queries into its native query language) or native Druid SQL.
The SQL plan happens at the Broker. To configure the SQL plan and JDBC query, the Broker's runtime properties must be configured.
Key Resources of Apache Druid:
-
Columnar Storage Format: Druid uses column-oriented storage, meaning it loads only the columns needed for a particular query. This improves query speed. Additionally, to support fast scans and aggregations, Druid optimizes the storage of each column according to its data type.
-
Optimized Data Format: Ingested data is automatically columnarized, time-indexed, dictionary-encoded, bitmap-indexed, and type-aware compressed.
-
Real-Time or Batch Ingestion: Druid can ingest data in real-time or batches. Ingested data is immediately available for querying.
-
Indexes for Fast Filtering: Druid uses compressed bitmap indexes, such as roaring or CONCISE, for fast filtering and searching across multiple columns.
-
Time-Based Partitioning: Druid partitions data by time first and can optionally implement additional partitioning based on other fields. Time-based queries access only the partitions corresponding to the query's time range, significantly improving performance.
-
Approximation Algorithms: Druid includes algorithms for approximate count-distinct, approximate ranking, and approximate histogram and quantile calculations. These algorithms offer limited memory usage and are generally much faster than exact calculations. For situations where precision is more important than speed, Druid also offers exact count and ranking.
-
Automatic Roll-Up at Ingestion Time: Druid optionally supports summarizing data at ingestion time. This pre-aggregation can significantly reduce storage costs and improve performance.
-
Interactive Query Engine: Uses scatter/gather for high-speed queries with pre-loaded data in memory or local storage to avoid data movement and network latency.
-
Tiers and QoS: Configurable tiers with quality of service allow optimal cost-performance for mixed workloads, ensuring priority and avoiding resource contention.
-
Stream Ingestion: Connector-free integration with streaming platforms allows "query on arrival," high scalability, low latency, and guaranteed consistency.
-
Uninterrupted Reliability: Automatic data services, including continuous backup, automated recovery, and multi-node replication, ensure high availability and durability.
When to Use Apache Druid
Druid is used by many organizations of various sizes for different use cases. It is a good choice for the following situations:
- High insertion rates and few updates.
- Predominance of aggregation queries and reports, such as group by.
- Query latencies ranging from 100ms to a few seconds.
- Data with time components (Druid includes optimizations and design options specifically related to time).
- Even when there are multiple tables, each query hits only one large distributed table. Queries may potentially hit more than one smaller lookup table.
- Data columns with high cardinality (e.g., URLs, user IDs) and the need for fast counting and ranking.
When Not to Use Apache Druid
- Low-latency updates to existing records using a primary key. Druid supports streaming inserts but not streaming updates. Updates can be performed using background batch jobs.
- Creating an offline reporting system where query latency is not very important.
- Needing large joins, meaning joining one large fact table to another large fact table.
Apache Druid Integration with Spark
Druid and Spark are complementary solutions since Druid can be used to accelerate OLAP queries in Spark.
Spark is a general cluster computing framework initially designed around the concept of Resilient Distributed Datasets (RDDs). RDDs allow data reuse by keeping intermediate results in memory and enable Spark to provide fast calculations for iterative algorithms. This is especially good for certain workflows, like machine learning (where the same operation may be applied repeatedly until a result converges).
Spark's generality makes it well-suited as an engine for processing (cleaning or transforming) data. While it provides the capability to query data via Spark SQL, like Hadoop, its query latencies are not specifically targeted for subsecond iterative responses.
Druid focuses on extremely low-latency queries and is ideal for powering applications used by thousands of users, where each query needs to return quickly enough for users to interactively explore the data.
Druid fully indexes all data and can act as an intermediary layer between Spark and an application.
A typical setup is to process data in Spark and load the processed data into Druid for faster access. For more details on Druid and Spark interaction, refer to the documentation here.
Major Differences Between Apache Druid and Traditional RDBMS
-
Schemas: Druid stores data in datasources, similar to tables in traditional RDBMS. Its data models share similarities with relational and time-series data models.
- Its schemas must always include a primary timestamp. This field is used for partitioning and sorting data. It is also used to quickly identify and retrieve data within the query time range and for data management, such as dropping time chunks, overwriting time chunks, and time-based retention rules.
-
Dimensions: Dimensions are columns that Druid stores as-is. They can be used for any purpose, such as grouping, filtering, or aggregating dimensions at query time. With rollup disabled, Druid treats the set of dimensions as a set of columns to be ingested. Dimensions behave exactly like in any database without a rollup feature.
-
Metrics: Metrics are columns that Druid stores in an aggregated form. They are most useful with rollup enabled. With a specified metric, an aggregation function can be applied to each row during ingestion.
Best Practices for Apache Druid
-
Rollup:: Druid can roll up data as it ingests to minimize the volume of raw data that needs to be stored. This is a form of summarization or pre-aggregation.
-
Partitioning and Sorting:: Proper partitioning and sorting can have a substantial impact on performance.
-
Sketches for High Cardinality Columns: for high cardinality columns: When dealing with high cardinality columns, like user IDs or other unique identifiers, consider using sketches for approximate analysis before operating with actual values.
- When using a sketch, Druid does not store the raw original data but a sketch of it that can be used for later calculations at query time.
- Popular use cases include distinct count and quantile calculations.
- Sketches serve two purposes: improving rollup and reducing memory consumption during queries.
-
Strings vs Numeric Dimensions:: To ingest a column as a numeric dimension, specify the column type in the dimensions section. If the type is omitted, Druid will ingest the column as a default string type.
-
Segments:: For optimal performance under heavy query loads, segment file size should be within the recommended range of 300 to 700 MB. If larger, consider adjusting the segment time granularity or partitioning your data, and/or adjusting the targetRowsPerSegment in partitionsSpec. A good starting point for this parameter is 5 million rows.
Apache Druid Project Details
Apache Druid was developed in Java.
Sources: