Apache Hadoop
Distributed processing of large volumes of data
Apache Hadoop is an open-source implementation of the MapReduce paradigm, which defines an architecture for distributed and parallel processing of large volumes of data, so that they can be "executed" on multiple servers, using simple programming models.
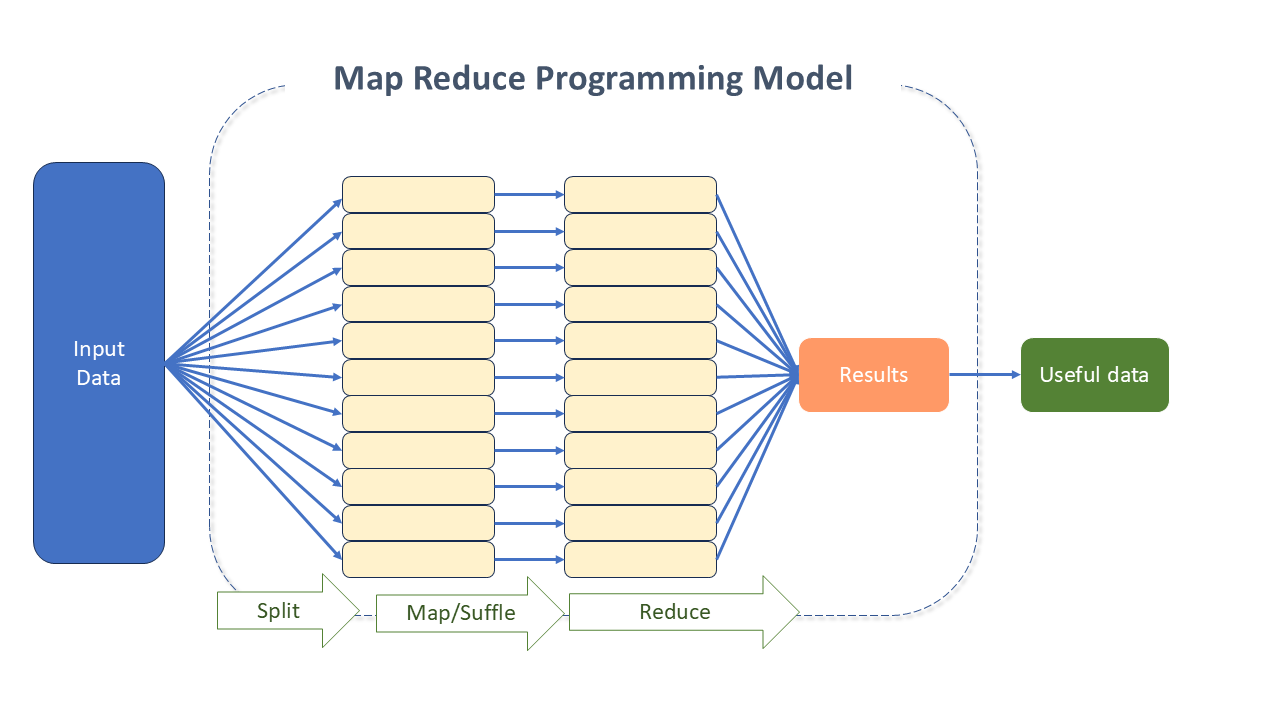
The MapReduce paradigm expands single servers to many machines, offering local computing and storage. The reason for its scalability is the distributed nature of its solution - a complex initial task is divided into several smaller ones, and then executed on different machines. Subsequently, the result is combined to generate the solution of the initial task.
Apache Hadoop emerged in 2006, from a web search solution called Nutch Distributed File System (NDFS) which, according to its creators, Doug Cutting and Mike Cafarella, had its genesis in the document Google File System, published in October 2003. NDFS evolved into what we now know as Hadoop Distributed File System (HDFS).
Apache Hadoop, as well as its set of linked solutions, is one of the most popular and high-performance implementations currently used to solve challenges related to the collection, storage, and analysis of data, whether structured or not, static or real-time.
Apache Hadoop Benefits
- Scalability: Hadoop achieves scalability relatively simply through minor modifications to configuration files. The effort to prepare an environment with a thousand machines is not much greater than with 10. The limitations are due to the resources, disk space, and processing capacity available.
- Simplicity: Hadoop manages issues related to parallel computing, such as fault tolerance, scheduling, and load balancing. Its operations boil down to mapping (Map) and joining (Reduce), which keeps it focused on abstraction and task processing in the MapReduce programming model.
- Low Cost/Economy:
- As free software, it does not require the purchase of licenses or the hiring of specialized personnel.
- It can process data on conventional machines and networks.
- Allows applications to run "in the cloud", without the need to deploy your own cluster of machines.
- Open Source: It has an active community that involves many companies and independent programmers sharing knowledge, promoting improvements, and collaborating with its quality. This collaborative work promotes timely updates and fixes with higher quality, as individual production is evaluated by everyone.
- High Availability: Hadoop does not depend on hardware to deliver high availability. Its libraries were built to detect and handle failures at the application layer, thus providing high availability in a computer cluster.
Apache Hadoop Architecture
The key components of Hadoop are the MapReduce and the HDFS. With its evolution, new subprojects were incorporated, aiming to solve specific problems.
Main Components of Apache Hadoop
- Hadoop Common: It is the "pillar" of Hadoop: where a predefined set of utilities and libraries that can be used by other modules within the Hadoop Ecosystem (Java Archive (JAR) files and scripts) is stored.
- HDFS: It is a scalable, distributed file system designed to store very large files and provide high-throughput access. It provides high-throughput access to application data.
- The idea behind its solution is to ensure scalability and reliability for parallel processing, using the concept of replicas and blocks (with a fixed size of 64MB, in general, stored on more than one server).
- Hadoop YARN: Responsible for managing and scheduling the computational resources of the Cluster.
- Hadoop MapReduce: It is a software framework created to process large amounts of data. An excellent solution for parallel data processing.
- Each task is specified in terms of mapping and reducing functions. Both tasks run in parallel, on the Cluster, while the necessary storage system is provided by HDFS.
Subprojects of Apache Hadoop
The need for new alternatives to promote faster and more efficient processing than traditional DBMSs brought large companies closer to the Platform, which, because it is an open-source project, received great encouragement.
With the emergence of new needs, new tools were created to run on top of Hadoop. As they consolidated, they became part of it. It was these contributions that collaborated with the rapid evolution of Apache Hadoop.
Below are the main tools of the Hadoop Ecosystem, which make up the Tecnisys Data Platform (TDP):

Evolution of Apache Hadoop
See the Timeline - with the evolution of Apache Hadoop
| Year | Event |
|---|---|
| 2003 | Research paper released for Google's file system |
| 2004 | Research paper released for MapReduce |
| 2006 | JIRA, mailing list, and other documents created for Hadoop Hadoop created from NDFS and MapReduce of Nutch Hadoop created by moving NDFS and MapReduce from Nutch Doug Cutting named the project Hadoop, after his son's yellow elephant toy Hadoop Release 0.1.0 37.9 hours to sort 1.8 TB of data on 188 nodes 300 machines deployed at Yahoo for the Hadoop Cluster 600 machines deployed at Yahoo for the Hadoop Cluster |
| 2007 | Two 1000-machine Clusters at Yahoo Hadoop released with HBase Apache Pig created |
| 2008 | JIRA opened for YARN 20 companies listed on the Hadoop "powered by" page (Hadoop users) Yahoo's web index moved to Hadoop Hadoop Cluster with 10,000 cores used to generate Yahoo's search index First Hadoop Summit World record set for fastest sort (one terabyte of data in 209 seconds) using a Hadoop Cluster with 910 nodes Hadoop breaks the Terabyte sort record Hadoop breaks the Terabyte sort Benchmark record Yahoo's Hadoop Cluster loading 10TB into Hadoop daily Google claims to sort 1 terabyte in 68 seconds with its MapReduce implementation |
| 2009 | 24,000 machines with 7 clusters running at Yahoo Hadoop breaks the petabyte sort record Yahoo claims to sort 1 terabyte in 62 seconds Second Hadoop Summit Core Hadoop renamed to Hadoop Common MapR distribution founded HDFS becomes a separate subproject MapReduce becomes a separate subproject |
| 2010 | Kerberos authentication added to Hadoop Stable release of Apache HBase Yahoo processes 70 PB on 4,000 nodes Facebook runs 40 Petabytes on 2,300 Clusters Apache Hive is released Apache Pig is released |
| 2011 | Apache Zookeeper released Contribution of 200,000 lines of code from Facebook, LinkedIn, eBay, and IBM Media Guardian Innovation awards Hadoop top prize Hortonworks started by Rob Barbadon and Eric Badleschieler, who were key members of Hadoop at Yahoo 42,000-node Hadoop Cluster at Yahoo, processing Petabytes of data |
| 2012 | Hadoop community begins integrating with YARN Hadoop Summit in San Jose Hadoop 1.0 release |
| 2013 | YARN in production Hadoop 2.2 release |
| 2014 | Apache Spark becomes a top-level project Hadoop 2.6 release |
| 2015 | Hadoop 2.7 release |
| 2016 | Hadoop 2.8 release |
| 2017 | Hadoop 3.0 release |
| 2018 | Hadoop 3.1.0 release |
| 2019 | Hadoop 3.2.0 release |
| 2022 | Hadoop 3.2.4 release |
| 2023 | Hadoop 3.3.6 release |
| 2024 | Hadoop 3.4.0 release |
Configuration and Use
- Configuring a Single Node Cluster
- Configuring a Cluster
- Starting and Stopping a Cluster
- Using the File System shell
- Knowing the commands and subprojects of Hadoop
Compatibility Guidelines
- Hadoop.apache.org -> Specifications for the Hadoop developer community
- Hadoop.apache.org -> Specifications for System Administrators
The Future of Apache Hadoop
In April 2021, the Apache Software Foundation announced the retirement of 13 projects related to BigData, ten of which were part of the Hadoop Ecosystem (Eagle, Sentry, Tajo, etc.).
This action raised questions about the future of Apache Hadoop. However, the Platform has a significant number of large users who continue to use it.
According to Google Trends, Apache Hadoop reached its peak in popularity between 2014 and 2017 and, as in any technological cycle, its popularity may indeed gradually decline in favor of other emerging tools. However, the technology continues to progress, with a focus on the continuous evolution of HDFS, YARN, and MapReduce. Its latest version was released in March 2023.
Apache Hadoop Project Details
Apache Hadoop was developed predominantly in Java.
Source(s):