Trino
Motor de Consulta Distribuído
Um mecanismo de consulta distribuído é concebido para executar consultas SQL complexas em grandes volumes de dados dispersos por várias fontes. Elimina a necessidade de mover ou duplicar dados, permitindo análises diretamente no local onde os dados estão armazenados, aumentando a eficiência e a escalabilidade.
Principais Características dum Mecanismo de Consulta Distribuído:
- Execução Paralela: Divide consultas em tarefas mais pequenas, que são processadas simultaneamente em diferentes nós dum cluster, otimizando o tempo de execução.
- Liga�ção a Múltiplas Fontes de Dados: Oferece integração com data lakes, data warehouses e bases de dados relacionais, permitindo a execução de consultas federadas.
- SQL como Linguagem Universal: Os analistas podem realizar consultas utilizando SQL, sem necessidade de aprender linguagens específicas.
- Desempenho Otimizado: Utiliza técnicas como pushdown de predicados e armazenamento em memória para reduzir a latência e maximizar a performance.
Entre os casos de uso mais comuns dos mecanismos de consulta distribuídos, destacam-se:
- Consultas federadas em várias fontes de dados.
- Análises em tempo real de grandes volumes de dados.
- Unificação de data lakes e data warehouses para facilitar a governança e auditoria.
O seu funcionamento básico envolve:
- O cliente envia uma consulta ao mecanismo.
- O mecanismo interpreta a consulta, cria um plano de execução e distribui tarefas aos workers.
- Cada worker processa a sua parte, acedendo diretamente às fontes de dados.
- Os resultados são consolidados e enviados de volta ao cliente.

Principais Características do Trino
O Trino é um mecanismo de consulta distribuído open-source, projetado para executar consultas SQL em grandes volumes de dados armazenados em fontes diversas, como data lakes, data warehouses e bases de dados relacionais.
Inicialmente desenvolvido como Presto por engenheiros do Facebook para responder às suas necessidades internas de análise de dados, o Trino surgiu em 2020 após uma divisão com a Presto Foundation. Desde então, tornou-se uma referência em soluções de alta performance para análise de dados distribuídos.
Principais Características:
- Velocidade: Desenvolvido para análises de baixa latência, o Trino utiliza execução altamente paralela e distribuída para processar consultas de forma eficiente.
- Escalabilidade Horizontal: Permite a adição de workers para ampliar a capacidade de processamento, sendo capaz de lidar com workloads em escala de exabytes, como em grandes data lakes e data warehouses.
- Simplicidade: Compatível com ANSI SQL, facilita a integração com ferramentas de BI como R, Tableau, Power BI, Superset, entre outras.
- Versatilidade: Suporta análises "ad hoc" interativas, consultas em lote de longa duração e aplicações de alto volume, garantindo tempos de resposta inferiores a um segundo em cenários críticos.
- Análise Local: Consulta dados diretamente em fontes como Hadoop, S3, Cassandra e MySQL, eliminando a necessidade de copiar ou mover dados, simplificando processos e reduzindo erros.
- Consultas Federadas: Possibilita a execução de consultas em múltiplas fontes de dados, como HDFS, S3, bases de dados relacionais e data warehouses.
- Alta Performance: A sua arquitetura é otimizada para workloads interativos, garantindo latência mínima.
- Extensibilidade: Oferece suporte para conectores personalizados, possibilitando integração com novas fontes de dados.
- Confiabilidade: Amplamente utilizado em operações críticas, como relatórios financeiros para mercados públicos, por algumas das maiores organizações globais.
- Suporte a Diversos Formatos: Compatível com formatos como Parquet, ORC, Avro, JSON e CSV.
- Comunidade Aberta: Desenvolvido sob a liderança da Trino Software Foundation, uma organização sem fins lucrativos.
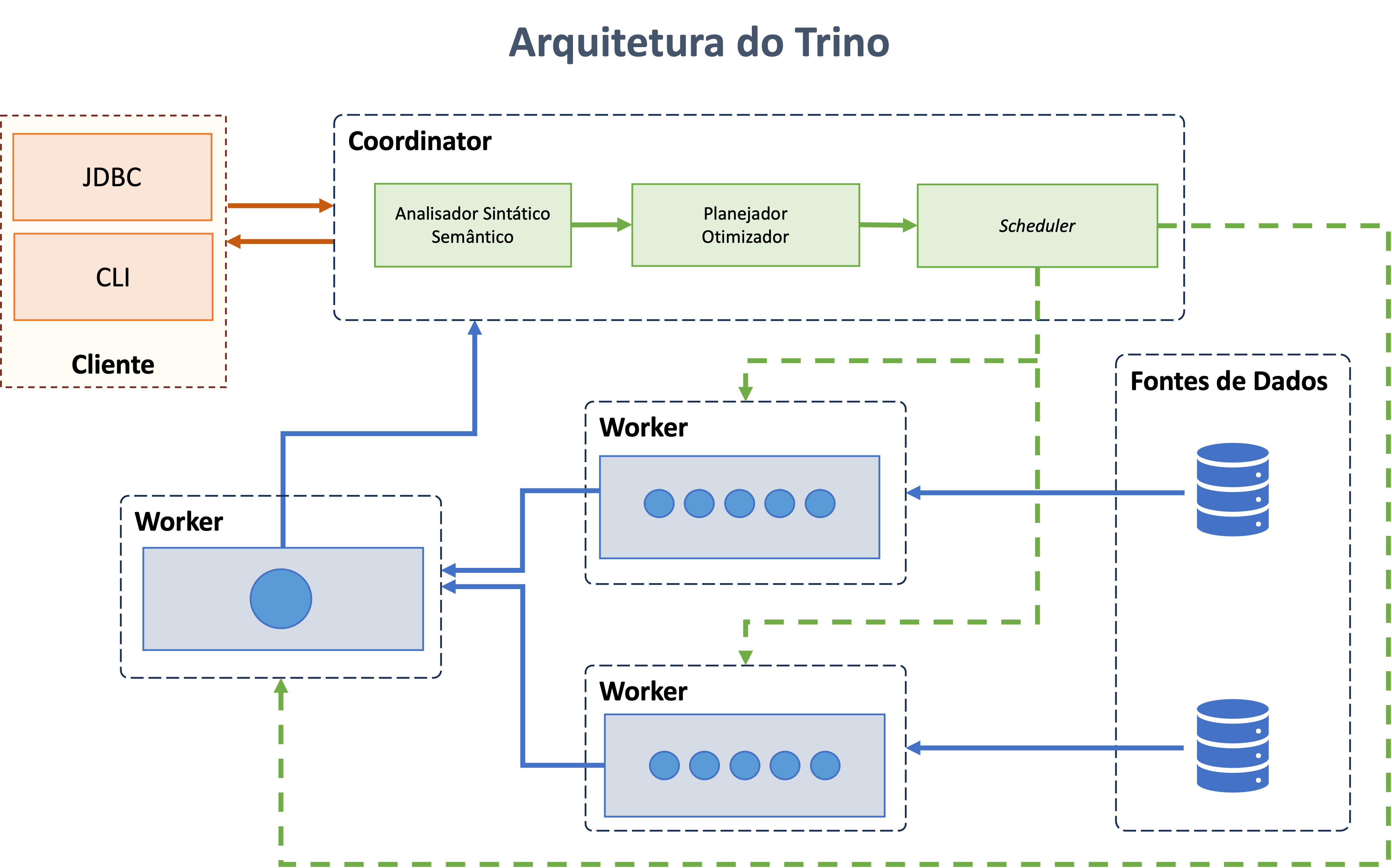
Arquitetura do Trino
O Trino é um mecanismo de consulta distribuído que processa dados em paralelo em vários servidores. Os servidores dum Cluster Trino são classificados como Coordinators e Workers.
As secções seguintes descrevem os principais componentes da arquitetura do Trino.
Cluster
Um cluster Trino é composto por vários nós, incluindo um Coordinator e zero ou mais Workers. Os utilizadores ligam-se ao Coordinator através de ferramentas de consulta SQL. O Coordinator orquestra tarefas entre os Workers e acede às fontes de dados conectadas por meio de catálogos configurados.
Cada consulta é processada como uma operação com estado. O Coordinator distribui a carga de trabalho entre os Workers em paralelo. Cada nó executa uma única instância JVM, com paralelização adicional usando threads.
Nó (Node)
Um Node no Trino refere-se a qualquer servidor dentro dum cluster que executa um processo Trino. Normalmente corresponde a um único computador, uma vez que apenas um processo Trino é recomendado por máquina.
Coordinator
O Coordinator é o servidor central responsável por analisar instruções, planear consultas e gerenciar nós Workers. Atuando como o "cérebro" do cluster, rastreia as atividades dos Workers, coordena a execução de consultas e comunica-se com clientes e Workers por meio da API REST.
Para desenvolvimento ou testes, uma única instância do Trino pode ser configurada para funcionar como Coordinator e Worker.
Worker
Um Worker é um servidor responsável por executar tarefas e processar dados. Os Workers obtêm dados de conectores, trocam dados intermediários e comunicam-se com o Coordinator via API REST. Quando iniciado, um Worker regista-se no servidor de descoberta do Coordinator para alocação de tarefas.
Cliente
Os clientes ligam-se ao Trino para enviar consultas SQL e recuperar resultados. Podem aceder às fontes de dados configuradas por meio de catálogos e incluem ferramentas como interfaces de linha de comandos, aplicações de ambiente de trabalho e sistemas baseados na web. Alguns clientes também suportam autoria interativa de consultas, visualizações e relatórios.
Fonte de Dados
O Trino suporta consultas em diversas fontes de dados, incluindo data lakes, bases de dados relacionais e armazenamentos de chave-valor. O acesso a estas fontes de dados é configurado através de catálogos, que definem os conectores necessários, credenciais e outros parâmetros.
A seguir apresentamos os conceitos fundamentais associados às Fontes de Dados no Trino:
-
Conector: Os conectores permitem que o Trino interaja com fontes de dados específicas, funcionando como drivers de bases de dados. Exemplos incluem conectores para Hive, Iceberg, PostgreSQL, MySQL e Snowflake. Cada catálogo no Trino está associado a um conector.
-
Catálogo: Um catálogo é uma coleção de propriedades de configuração para aceder a uma fonte de dados. Os catálogos são definidos em ficheiros de propriedades armazenados no diretório de configuração do Trino. Um catálogo pode conter esquemas e tabelas, permitindo o acesso a múltiplas fontes de dados num único cluster.
-
Esquema: Os esquemas organizam tabelas e outros objetos dentro dum catálogo. Correspondem a conceitos semelhantes em bases de dados como Hive e MySQL.
-
Tabela: Uma tabela consiste em linhas desordenadas organizadas em colunas nomeadas com tipos específicos. As tabelas são acedidas por nomes totalmente qualificados enraizados em catálogos.
Modelo de Execução de Consultas do Trino
O Trino executa instruções SQL transformando-as em consultas distribuídas executadas no cluster.
Seguem mais detalhes sobre os termos utilizados no modelo de execução de consultas do Trino:
- Instrução (Statement): O texto SQL enviado ao Trino, convertido num plano de consulta durante a execução.
- Consulta (Query): Engloba os componentes e a configuração necessários para executar uma instrução, incluindo estágios, tarefas, divisões e operadores.
- Estágio (Stage): Secções dum plano de consulta distribuído, organizadas hierarquicamente.
- Tarefa (Task): Executa estágios em paralelo nos Workers.
- Split (Divisão): Um segmento dum conjunto de dados maior, processado por uma tarefa.
- Driver: A menor unidade de paralelismo, combinando operadores para processar dados dentro de uma tarefa.
- Operador: Realiza transformações nos dados, como buscas em tabelas ou filtros.
Detalhes do Projeto Trino
O Trino foi desenvolvido em Java, aproveitando a robustez da JVM para processamento distribuído.

Fontes:
Trino - Overview