Apache Solr
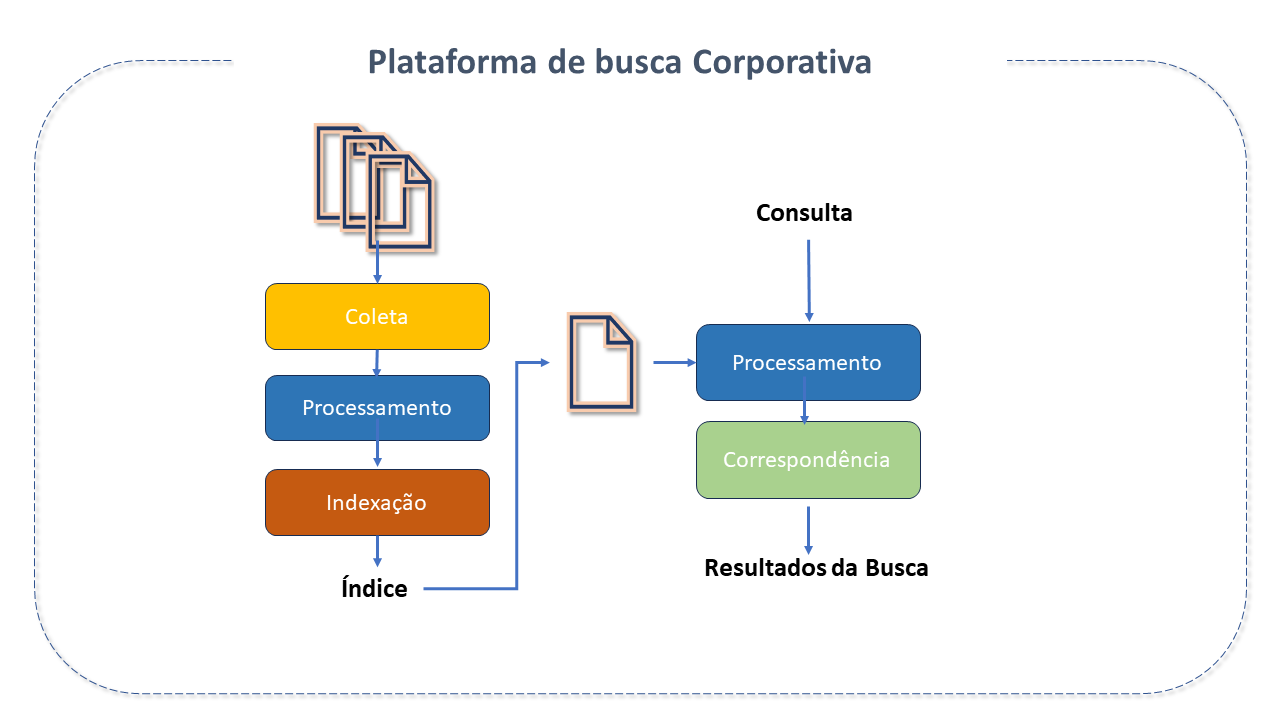
Plataforma de Pesquisa Corporativa
As Plataformas de Pesquisa Corporativa têm a função de criar uma funcionalidade de pesquisa segura, poderosa e fácil de usar.
Quando aplicadas em contextos empresariais, geralmente integram-se com soluções de inteligência de negócios e gestão de dados, sendo usadas para "limpar" e estruturar dados, facilitando a localização de informações. Podem extrair dados de diferentes fontes, como CRM, ERP, entre outros.
Para se qualificar como uma plataforma de pesquisa corporativa, o produto deve:
- Manipular informações de diferentes fontes, tipos de dados e formatos.
- Indexar ou arquivar dados.
- Oferecer opções de pesquisa inteligente.
- Disponibilizar uma interface para busca e recuperação de dados.
- Permitir que os utilizadores refinem as suas pesquisas com filtros avançados.
- Configurar permissões de acesso às informações.
Funcionalidades do Apache Solr
O Apache Solr é uma plataforma de pesquisa corporativa de código aberto, construída sobre o Apache Lucene, projetada para recuperação de documentos.
O Apache Solr foi criado em 2004 por Yonik Seeley, na CNET Networks, como um projeto interno para adicionar capacidades de pesquisa ao site da empresa.
- Em janeiro de 2006, o seu código fonte foi doado para a Apache Software Foundation e, em 2007, já era considerado um projeto autónomo de nível superior (TLP), crescendo continuamente com recursos acumulados, atraindo utilizadores, colaboradores e commiters.
- Foi lançado pela Apache em 2008, na versão 1.3, e em 2010 foi fundido com o Lucene (o seu esquema de versionamento foi alterado em 2011 para coincidir com o do Lucene).
- Em 2020, a Bloomberg doou o operador Solr para o projeto Lucene/Solr, possibilitando a implementação e execução do Solr no Kubernetes.
- Em 2021, o Solr foi estabelecido como um projeto Apache independente (TLP), autónomo do Lucene. A sua primeira versão independente foi a 9.0.
O Solr é amplamente utilizado para casos de uso de pesquisa e análise corporativa. É desenvolvido de forma aberta e colaborativa pelo projeto Apache Solr na Apache Software Foundation. Tem uma comunidade de desenvolvimento muito ativa, com lançamentos regulares.
As suas principais funcionalidades incluem:
-
Funcionalidades Avançadas de Pesquisa em Texto:
Permite funcionalidades avançadas, como correspondência de frases, uso de wildcards para tornar as pesquisas mais flexíveis, além de suportar joins e agrupamentos em qualquer tipo de dado. -
Otimizado para tráfego em grande escala.
Provado em escalas extremamente grandes ao redor do mundo. -
Interfaces abertas: Baseadas nos padrões XML, JSON e HTTP.
-
Interfaces administrativas abrangentes: Inclui uma interface de administração responsiva integrada, facilitando o controlo das instâncias.
-
Monitorização fácil: Publica cargas de dados de métricas via JMX.
-
Altamente escalável e tolerante a falhas:
- Construído sobre o Apache Zookeeper, facilita a escalabilidade.
- Oferece replicação, distribuição, balanceamento e tolerância a falhas.
-
Flexível e adaptável com configuração simples: Configurações de esquema flexíveis, permitindo armazenar quase qualquer tipo de dado no Solr.
-
Indexação em tempo quase real: Permite que alterações sejam visíveis a qualquer momento.
-
Arquitetura extensível de plugins. Publica vários pontos de extensão que facilitam a incorporação de plugins de indexação e consulta, permitindo a personalização do código à vontade (licença de código aberto).

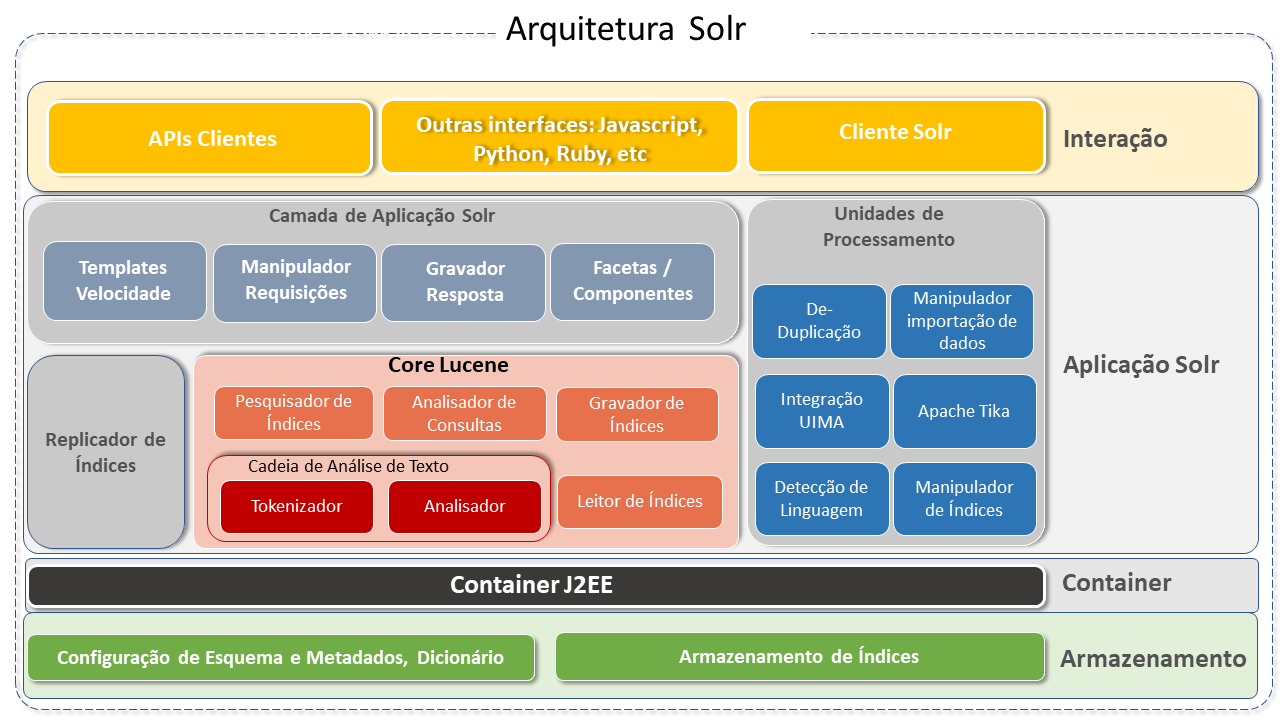
Arquitetura do Apache Solr
O Apache Solr foi projetado para escalabilidade e tolerância a falhas. Ele funciona como um servidor de pesquisa de texto independente.
O Apache Solr é executado sobre a biblioteca de software Lucene, que é, de fato, o motor que o alimenta. O núcleo do Solr é uma instância do índice Lucene, onde todos os ficheiros de configuração necessários para utilizá-lo estão localizados. A biblioteca de pesquisa Java Lucene é usada para indexação e pesquisa de texto completo e possui APIs REST-like HTTP/XML e JSON, que tornam o Solr utilizável nas linguagens de programação mais populares.
A sua configuração externa permite adaptá-lo a muitos tipos de aplicações sem necessidade de codificação em Java, e a sua arquitetura de plugins suporta personalizações mais avançadas.
As consultas no SOLR são URLs de solicitações HTTP simples e as respostas são documentos estruturados em JSON, XML, CSV ou outro formato. Os documentos (indexação) são enviados para ele via JSON, XML, CSV ou binário através de HTTP. As consultas são realizadas via HTTP GET e recebem resultados em JSON, XML, CSV ou binário.
O Solr opera com uma arquitetura não escrava, pois cada nó é o seu próprio mestre. Os nós utilizam o Zookeeper para aprender sobre o estado do Cluster e cada nó (JVM) pode hospedar vários núcleos (onde o Lucene é executado).
As consultas são configuradas e geridas nos ficheiros schema.xml e solrconfig.xml.
Os principais componentes da arquitetura do Apache Solr são:
-
RequestHandler:
As solicitações recebidas no Apache Solr são processadas pelo Request Handler. A solicitação pode ser uma consulta ou uma atualização de índice. Com base na solicitação, o request handler é selecionado. O handler geralmente é mapeado para um URI end-point através do qual a solicitação será atendida. -
Search Resource:
Fornece a funcionalidade de pesquisa ao Apache Solr. Isso pode incluir spell checking, consultas, faceting, realce de ocorrências (hit highlighting), entre outros. -
Query Parsers:
Analisam as consultas e verificam erros de sintaxe. Após a análise, traduzem as consultas para um formato compreensível pelo Lucene. O Solr suporta vários analisadores de consultas (query parsers). -
Response Writer:
É o componente que gera a saída formatada para a consulta do utilizador. Os formatos suportados incluem XML, JSON, CSV, entre outros. Existem diferentes response writers para cada tipo de resposta. -
Parser / tokenizer:
O Lucene reconhece dados na forma de tokens. O Apache Solr analisa o conteúdo, divide-o em tokens e passa esses tokens para o Lucene. Um Analyzer no Apache Solr examina o texto dos campos e gera um fluxo de tokens. Um tokenizer divide o fluxo de tokens preparado para o parser em tokens. -
Update Request Processors:
Cada solicitação de update é executada através dum conjunto de plugins (assinatura, registo, indexação), conhecidos coletivamente como "processador de solicitação de atualização" (update request processor). Este processador é responsável por modificações, como "remoção de campos, adição de campos, etc."
Termos do Apache Solr
-
Cluster
Nós Solr que operam em coordenação uns com os outros via Zookeeper e são geridos como uma unidade. Um Cluster pode conter várias coleções. -
Coleções:
Um ou mais documentos agrupados num único índice lógico utilizando uma única configuração e esquema. Na nuvem, a coleção pode ser dividida em múltiplos fragmentos lógicos, que podem ser distribuídos por vários nós ou num único nó. -
Nó
Na nuvem Solr, cada instância única do Solr é considerada um nó. -
Commit:
Permite que as alterações ao índice sejam permanentes. -
Núcleo:
Uma instância individual do Solr (representando um índice lógico). Vários núcleos podem ser executados num único nó. -
Shard (fragmento):
É uma partição lógica da coleção que contém um subconjunto dos seus documentos, de forma que cada documento numa coleção esteja contido em exatamente um Shard.
Quando um documento é enviado para um nó para indexação, o sistema determina a qual "shard" o documento pertence, em seguida, qual nó hospeda o seu Líder, encaminhando o documento para este líder para indexação, que por sua vez o encaminha para todas as outras réplicas. -
Replicação:
Quando o índice é demasiado grande para uma única máquina e há um volume de consultas que shards individuais não conseguem suportar, é necessário replicar cada shard.
No núcleo do Solr, a réplica é uma cópia do shard executada num nó. -
Líder:
É a réplica do shard que distribui as solicitações do Solr Cloud para as outras réplicas.
Funcionalidades adicionais do Apache Solr
O Solr oferece capacidades ricas e flexíveis de pesquisa. As suas principais funcionalidades incluem:
Pesquisa em texto: Alimentado pelo Lucene, o Solr permite funcionalidades como correspondência de frases, wildcards, joins, agrupamentos e mais, para qualquer tipo de dados.
-
Destaque (Highlighting):
Permite que fragmentos de documentos correspondentes à consulta sejam incluídos na resposta. -
Faceting:
Organização dos resultados da pesquisa em categorias com base nos termos indexados. -
Indexação em tempo real:
O Solr permite criar um índice com vários campos ou tipos de entrada diferentes. Um índice Solr pode aceitar dados de várias fontes, como XML, CSV ou dados extraídos de tabelas em bases de dados e ficheiros em formatos comuns como Word ou PDF. -
Agrupamento e expansão de resultados:
Agrupa documentos (colapsando o conjunto de resultados) de acordo com parâmetros e disponibiliza acesso ao documento no agrupamento "colapsado" para uso em exibição ou aplicação. -
Correção ortográfica (SpellChecking):
Projetado para oferecer sugestões de consultas online com base em termos semelhantes. -
Integração com bases de dados.
-
Funcionalidades NoSQL:**
A funcionalidade realtime get unique-key permite a recuperação da versão mais recente de qualquer documento sem o custo de reabrir um pesquisador. Isso é especialmente útil ao usar o Solr como um armazenamento de dados NoSQL, não apenas como um índice de pesquisa.A funcionalidade Real Time Get depende do recurso de registo de atualizações (update log), que está ativado por padrão e pode ser configurado em
solrconfig.xml.
Alguns dos sites mais famosos da Internet utilizam o Solr, como Macy, eBay e Zappos.
Melhores práticas para o Apache Solr
-
Campos indexados:
O uso de armazenamento em nuvem pode ser bastante otimizado ao controlar o número de campos indexados.
Os índices representam um fator crítico entre qualidade, desempenho e custo. Muitos campos indexados podem degradar o desempenho e aumentar os custos.
Ao definir campos, evite marcar campos como indexed=true se eles não forem utilizados numa consulta.
O número de campos indexados aumenta:- O uso de memória durante a indexação.
- O tempo de fusão de segmentos.
- O tempo de otimização.
- O tamanho do índice.
-
Armazenamento de campos:
Recuperar campos armazenados a partir do resultado de uma consulta pode ser custoso. Este custo é afetado pela quantidade de bytes armazenados por documento. Quanto maior a quantidade de bytes, mais esparsa será a distribuição dos documentos no disco - o que exige maior largura de banda de I/O para recuperar os campos desejados.Estes custos aumentam em implementações na nuvem. Obviamente, a sua utilização deve equilibrar qualidade, desempenho e custo.
-
Uso da Cache do Solr:
O Solr armazena em cache vários tipos de informações para evitar a repetição de consultas semelhantes.
A Cache de Documentos ajuda a melhorar o tempo de resposta às solicitações.
Existem três tipos principais de cache:- Query cache: Armazena os IDs dos documentos retornados por consultas.
- Filter cache: Armazena filtros criados pelo Solr em resposta a filtros adicionados às consultas.
- Document cache: Armazena os campos do documento solicitados ao exibir os resultados da consulta.
-
Aquecimento automático (Autowarming):
Ativar o autowarming pode aumentar significativamente o desempenho de uma pesquisa para qualquer um dos três tipos de cache.
Ao aumentar autowarmCount, o Solr pré-preencherá ou aquecera automaticamente o cache com os objetos criados pelo resultado da pesquisa.
Esta configuração indica o número de itens no cache que serão copiados para o novo "pesquisador". -
Expressões de Streaming (Streaming Expressions):
O Solr oferece uma linguagem de processamento de streaming simples, mas poderosa, para o Solr Cloud.
As expressões de streaming são um conjunto de funções que podem ser combinadas para realizar várias tarefas de computação paralela. -
Heap de memória da JVM (JVM Memory Heap):
O heap é uma área de memória onde os objetos da aplicação, criados a partir de classes (com semântica de referência), são armazenados. Objetos que são referenciados em algum lugar são alocados lá.
Esta área é gerida pelo garbage collector e ocupa espaço conforme necessário. No futuro, o GC liberará os espaços quando os dados numa porção não forem mais necessários.No caso da memória da JVM (Java Virtual Machine), grande parte da alocação já é reservada antecipadamente pelo GC, que tenta gerenciar a memória da melhor maneira possível.
As configurações de heap da memória da JVM afetam diretamente o uso de recursos do sistema.
Em um ambiente de nuvem, o uso de recursos e os custos podem aumentar rapidamente, afetando diretamente o desempenho e o sucesso ou fracasso de uma implementação de pesquisa.O tamanho ideal do heap de memória da JVM:
Um intervalo entre 8 e 16 GB é adequado. Recomenda-se começar com o menor valor e realizar testes, monitorizando o uso de memória e ajustando gradualmente o tamanho até alcançar o ideal. -
Garbage Collector (GC):
Este é o processo no qual a memória liberada num programa Java é devolvida ao pool de memória para reutilização.
O coletor usado antes da versão 9 do Java era o ParallelGCf. O coletor G1GC opera de forma simultânea e multithreaded, resolvendo problemas de latência existentes no ParallelGC.
O seu uso é, portanto, recomendado.
Além disso, o script de controlo do Solr vem com um conjunto de configurações pré-configuradas de GC Java, que funcionam bem para muitos tipos de cargas de trabalho. No entanto, essas configurações podem não ser adequadas para casos específicos.
Nesse caso, as configurações do GC podem ser alteradas usando a variável GC_TUNE no ficheiro/etc/default/solr.in.sh.
Recomendações de configuração para produção
-
Configurações de memória e GC:
Por padrão, o scriptbin/solrdefine o heap máximo como 512M. Para produção, ajuste esta configuração conforme necessário:solr_java_mem="-Xms10g -Xmx10g" -
Encerramento devido à falta de memória:
O scriptbin/solrregista o scriptbin/oom_solr.sh, que é acionado em caso de erro OutOfMemory. Este script executa um comandokill -9no processo do Solr.Analise o conteúdo do ficheiro
/opt/solr/bin/oom_solr.shpara entender as ações realizadas. -
Modo SolrCloud:
Para executar o Solr no modo SolrCloud, configure a variávelZK_HOSTpara apontar para o conjunto Zookeeper. Por exemplo:zk_host=zk1,zk2,zk3Quando configurada, o Solr iniciará no modo de nuvem (cloud mode).
-
Zookeeper:
Para isolar os znodes do SolrCloud, use o suporte chroot do Zookeeper. Por exemplo:zk_host=zk1,zk2,zk3/solrAntes de usar o chroot pela primeira vez, crie o caminho raiz no Zookeeper com o comando:
bin/solr zk mkroot /solr -z <ZK_NODE>:<ZK_PORT> -
Definir o nome do host do Solr:
Configure o nome do host do servidor Solr utilizando a variávelSOLR_HOST. Por exemplo:solr_host=solr1.example.comIsso é especialmente útil no modo SolrCloud, pois define o endereço do nó ao ser registado no Zookeeper.
-
Substituição de configurações no solrconfig.xml:
Propriedades de configuração no ficheirosolrconfig.xmlpodem ser substituídas utilizando propriedades de sistema Java com a sintaxe-Dproperty=value. -
Execução de múltiplos nós Solr por host:
O scriptbin/solrsuporta a execução de várias instâncias numa única máquina. Contudo, essa configuração não é recomendada para instalações padrão, pois aumenta o consumo de recursos de CPU e memória.warningEm cenários de escalabilidade extrema, a execução de vários nós Solr em um único host pode reduzir a necessidade de heaps muito grandes. Para mais detalhes, consulte a documentação.
Detalhes do Projeto Apache Solr
O Solr é escrito em Java.