Apache Druid
Database Analítico Real-Time
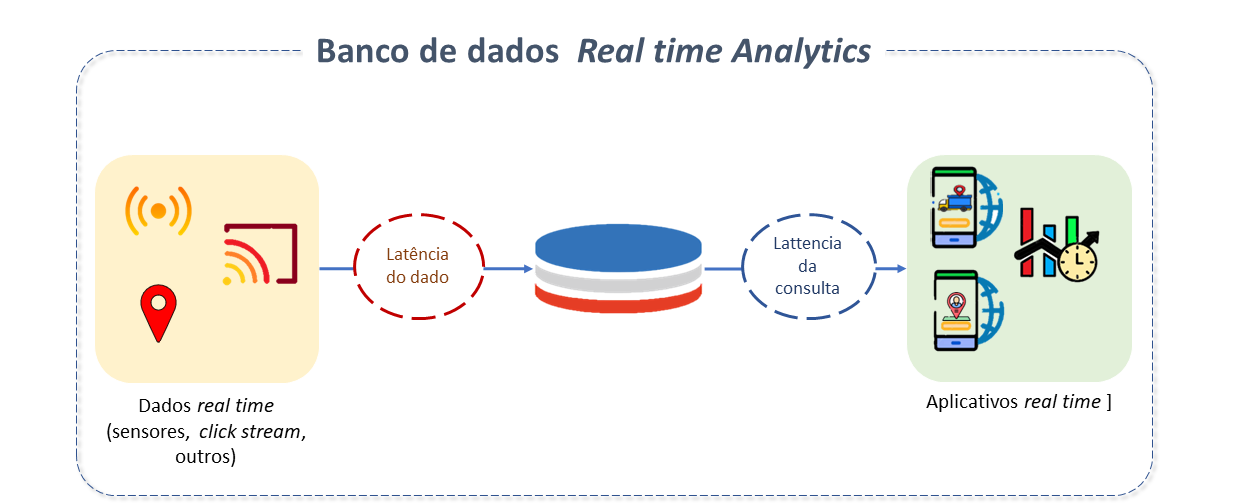
A habilidade de armazenar, processar e recuperar dados em velocidades muito rápidas é um dos principais requisitos atendidos por um Database analítico Real-Time.
Nos SGBDs tradicionais, derivar valor dos dados é uma tarefa difícil porque os dados precisam ser movidos, transformados, carregados num Datawarehouse ou Data Lake antes de seu consumo. Isto demanda tempo, algumas horas, muitas vezes dias.
Mecanismos de streaming, como o Kafka, auxiliam, mas somente até certo ponto, pois a necessidade fundamental é uma Base de Dados com poder de processar grandes quantidades de dados em tempo real.
As bases de dados analíticas em tempo real otimizam recursos para permitir pesadas cargas de trabalho. Contam com protocolos de ingestão leves e estruturas de armazenamento eficientes em disco, para permitir ingestões muito rápidas. Sua arquitetura utiliza processamento massivamente paralelo com alto grau de simultaneidade, de forma a não resultar em altos custos com infraestrutura.
Características do Apache Druid
O Apache Druid é um Sistema Gerenciador de Base de Dados analítico real-time, projetado para análises rápidas e fragmentadas (consultas OLAP) em grandes conjuntos de dados. Potencializa Use Cases onde a ingestão real-time, o desempenho rápido de consultas e a alta produtividade são importantes.
Sua origem remonta a 2011, quando o time de dados de uma empresa de TI resolveu criar seu própria base de dados, após tentar a utilização de várias alternativas de mercado para solucionar um problema de agregação e consulta rápida de dados em tempo real provenientes da Internet para analisar leilões de publicidade digital. A primeira versão do Druid escaneou, filtrou e agregou um bilhão de linhas em 950 milissegundos.
Druid tornou-se código aberto após alguns anos, e um projeto de alto nível da Apache Software Foundation em 2016.
Em 2023, mais de 1400 organizações usam o Druid e a ferramenta conta com mais de 10.000 desenvolvedores ativos em sua comunidade.
Dentre suas principais características, destacamos:
-
Escalabilidade e Flexibilidade: Sua arquitetura elástica e distribuída permite a criação de qualquer aplicativo em qualquer escala.
-
Eficiência e Integração: O princípio orientador do Druid é efetuar operações apenas quando estritamente necessário:
- Não carrega dados do disco para a memória (ou vice-versa) quando não são necessários.
- Não decodifica dados se puder operar diretamente em dados codificados.
- Não lê o conjunto de dados completo se puder ler um índice menor.
- Não inicia novos processos para cada consulta se puder usar um processo de execução longa.
- Não envia dados desnecessários entre processos ou servidores.
- O mecanismo de consulta e formato de armazenamento do Druid são totalmente integrados e foram projetados em conjunto para minimizar a quantidade de trabalho a ser realizado pelos servidores de dados.
- É geralmente usado como um backend de Base de Dados para GUIs ("Graphical User Interface") de aplicações analíticas, ou para APIs altamente concorrentes que demandam rápidas agregações.
-
Resiliência e Durabilidade: Druid é "auto-reparável", "autobalanceado" e tolerante a falhas. Foi projetado para funcionar continuamente sem inatividade, mesmo durante alterações de configuração e atualizações de software, impedindo a perda de dados, mesmo em caso de grandes falhas de sistemas. Seu Cluster se reequilibra automaticamente em segundo plano sem inatividade. Quando um servidor falha, o sistema "absorve" a falha e continua a operar.
-
Alto Desempenho: Os recursos do Druid se combinam para permitir alto desempenho em alta simultaneidade, evitando trabalho desnecessário.
-
Alta Simultaneidade: Este foi um dos objetivos originais do projeto Druid. Muitos Clusters suportam centenas de milhares de consultas por segundo. A chave disso é a relação exclusiva entre armazenamento e recursos de computação. Os dados são armazenados em segmentos, que são verificados em paralelo por consultas de dispersão/reunião.
-
Ingestão de dados em alta velocidade: Para ingestão streaming os gerentes intermédios e indexadores estão habilitados a responder a consultas em tempo real. Todas as tabelas estão sempre totalmente indexadas, tornando desnecessária a criação de índices.
-
**O Druid funciona melhor com dados orientados a eventos. As áreas de aplicação comuns para Druid incluem:
- Análise de Clickstream (fluxos de cliques), incluindo análises web e mobiles.
- Análise de telemetria de rede, incluindo monitorização de desempenho de rede.
- Armazenamento de métricas do servidor.
- Análise da cadeia de suprimentos, incluindo métricas de "fabricação".
- Métricas de desempenho de aplicativos.
- Análise de marketing/publicidade digital.
- Inteligência de negócios (OLAP).

Arquitetura do Apache Druid
Apache Druid tem uma arquitetura distribuída desenhada para ser cloud friendly e fácil de operar. Serviços podem ser configurados e escalados de forma independente, garantindo um máximo de flexibilidade nas operações de Cluster.
Druid combina ideias de data warehouses, Bases de dados de séries temporais e sistemas logsearch (busca de log).
Alguns dos seus principais componentes incluem:
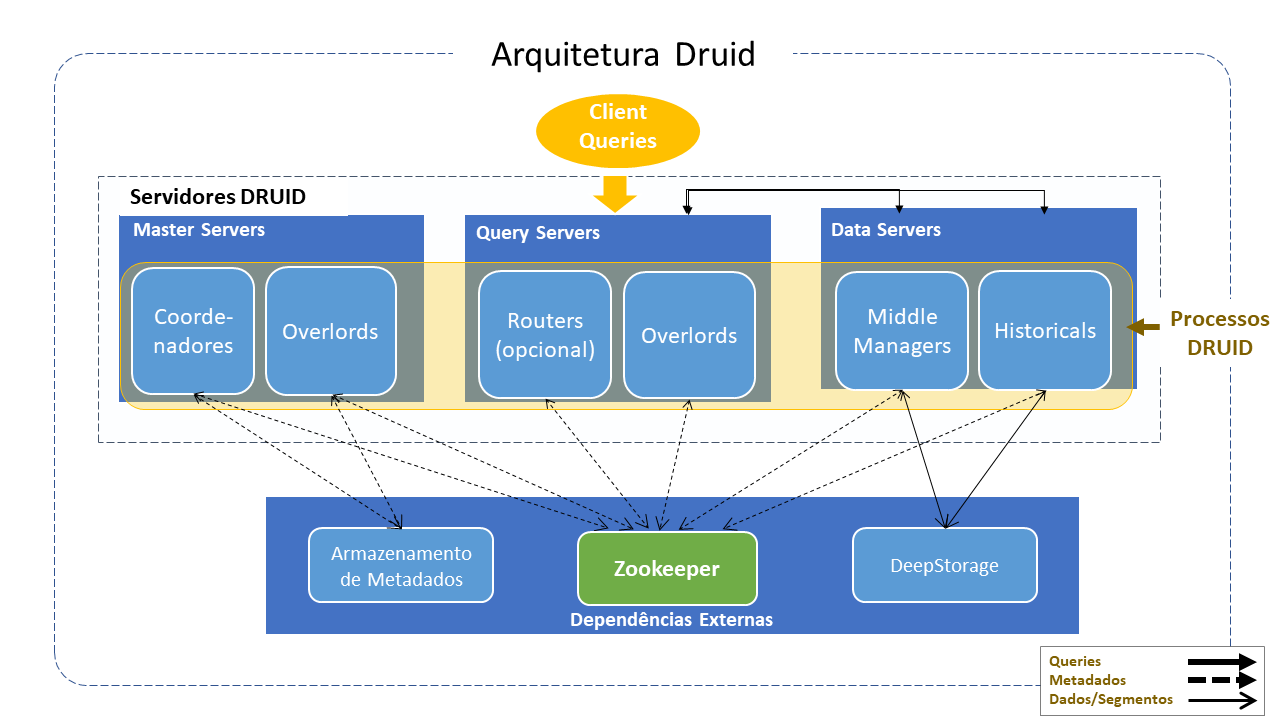
Serviços Druid (Tipos de Processo)
- Coordenador: gerencia a disponibilidade dos dados no Cluster.
- Overlord: controla a designação de workloads (cargas de trabalho) para ingestão de dados.
- Broker: lida com consultas de clientes externos.
- Serviços do roteador: são opcionais. Encaminham solicitações para Brokers, Coordenadores e Overlords.
- Serviços Históricos: armazenam dados que podem ser consultados.
- Serviços de MiddleManager: ingerem os dados para a maior parte dos métodos de ingestão.
- Indexador: é um recurso opcional e experimental. Seu sistema de gerenciamento de memória ainda estava em desenvolvimento quando da confecção desta documentação. Será aprimorado em versões posteriores. Deverá atuar como uma alternativa ao MiddleManager + Peon. Em vez de "bifurcar" um processo JVM separado por tarefa, o indexer executa tarefas como encadeamentos separados dentro dum processo JVM único.
Os serviços podem ser visualizados na Guia Serviços, no console da Web.
Servidores
Os servidores Druid podem ser implantados da maneira desejada. Para facilitar a implantação, sugere-se organizá-los em três tipos:
- Mestre: Executa os processos do Coordenador e do Overlord, gerencia a disponibilidade e ingestão de dados.
- Query: Executa processos de Broker e Router opcional e lida com consultas de clientes externos.
- Dados: executa processos históricos e do MiddleManager, executa cargas de trabalho de ingestão e armazena todos os dados que podem ser consultados.
Dependências Externas:
Além de seus tipos de processos integrados, o Druid também possui três dependências externas que alavancam a infraestrutura existente, quando presente:
- Deep Storage: Como parte da ingestão, o Druid armazena com segurança uma cópia do segmento de dados em Deep Storage, criando uma cópia adicional contínua e automatizada dos dados na nuvem ou HDFS. Disponibiliza o segmento para consultas imediatamente e cria uma réplica de cada segmento de dados. Sempre será possível recuperar dados do Deep Storage, mesmo no caso improvável de todos os servidores falharem.
- Armazenamento de Metadados: O armazenamento de metadados contém vários metadados de sistemas partilhados, como informações de uso de segmentos e informações de tarefas. Numa implantação em Cluster, geralmente é um RDBMS tradicional, como PostgreSQL. Numa implantação de servidor único, pode ser uma Base de Dados Apache Derby local.
- Zookeeper: Usado para gerenciamento do Cluster ativo, coordenação e eleição de líder.
Como o Apache Druid funciona
Design de Armazenamento
-
Os dados Druid são armazenados em datasources, que são similares a tabelas dum RDBMS tradicional. Cada datasource é particionado por tempo e, opcionalmente, por outros atributos. Cada intervalo de tempo é chamado chunk (bloco) - por exemplo, um único dia, no caso de particionado por dia. Dentro dum chunk, dado é particionado num ou mais segmentos. Cada segmento é um ficheiro único. Uma vez que os segmentos são organizados em blocos de tempo, algumas vezes é adequado pensar segmentos vivendo numa linha do tempo.
Uma fonte de dados pode ter de apenas alguns segmentos até centenas de milhares ou milhões de segmentos. Cada segmento é criado por um MiddleManager como mutable (mutável) e uncommitted (não confirmado). Os dados podem ser consultados assim que adicionados a um segmento uncommitted. O processo de construção do segmento acelera consultas posteriores, produzindo um ficheiro de dados compacto e indexado:
- Convertido para o formato colunar.
- Indexado com índices de bitmap.
- Compactados com reconhecimento de tipo para todas as colunas.
Periodicamente, os segmentos são committed (confirmados) e publicados no deep storage, tornando-se imutáveis, e passados dos MiddleManagers para os processos históricos. Uma entrada sobre o segmento também é gravada no Metadata Storage. Esta entrada é um bit autodescritivo de metadados sobre o segmento, incluindo coisas como o esquema do segmento, seu tamanho e localização no deep storage, informando aos Coordenadores quais dados estão disponíveis no Cluster.
-
Indexação e Transferência: Indexing é o processo pelo qual novos segmentos são criados. Handoff é o processo com o qual são publicados e começam a ser servidos por processos históricos.
-
Todo segmento tem um identificador de 4 partes com os seguintes componentes:
- Nome do datasource
- Intervalo de tempo (para o bloco de tempo que contém o segmento), que corresponde ao segmentGranularity especificado no tempo de ingestão.
- Número de versão (geralmente um timestamp ISO8601 correspondente a quando o conjunto de segmentos foi iniciado). Serve para o controlo da simultaneidade de várias versões.
- Número da partição (um inteiro, único dentro do datasource+intervalo+versão, não necessariamente contíguo).
-
Cada segmento tem um ciclo de vida que envolve:
- Armazenamento de Metadados: os metadados do segmento são armazenados no Metadata Storage assim que o segmento termina de ser construído (publicação).
- Armazenamento profundo: os ficheiros de dados do segmento são enviados para o deep storage assim que o segmento termina de ser construído, antes da publicação.
- Disponibilidade para consulta: os segmentos estão disponíveis para consulta num servidor de dados Druid, como uma tarefa em tempo real ou um processo histórico.
Ingestão:
A carga de dados no Druid é denominada ingestion (ingestão) ou indexing (indexação). Quando o dado é ingerido no Druid, o Druid lê o dado do sistema de origem e armazena-o em ficheiros de dados denominados segments (segmentos). Em geral, os segmentos contêm alguns milhões de linhas cada.
Para a maior parte dos métodos de ingestão, o processo MiddleManager ou o processo Indexer irá carregar os dados. A única exceção é para a ingestão baseada no Hadoop, que usa o job MapReduce no Yarn.
Durante a ingestão, o Druid cria segmentos e os armazena no Deep storage. Nós históricos carregam os segmentos na memória para responder às consultas. Para ingestões streaming, os MiddleManagers e os Indexers podem responder a consultas em tempo real quando o dado está a ser carregado.
Os métodos de ingestão mais comuns são:
-
Streaming: para o qual há duas opções: Kafka e Kinesis.
-
Quando habilitado o serviço Kafka indexing, supervisores podem ser configurados no Overlord para gerenciar a criação e o ciclo de vida das tarefas de indexação Kafka. As tarefas de indexação Kafka lêem eventos usando a partição própria do Kafka e o mecanismo offset para garantir a ingestão de uma única vez. O Supervisor acompanha o estado das tarefas de indexação para:
- Coordenar Handoffs (transferências).
- Gerenciar falhas.
- Garantir que a escalabilidade e requisitos de replicação estão mantidos.
-
Quando habilitado, o serviço indexador Kinesis, é possível configurar supervisores no Overlord para gerenciar a criação e o ciclo de vida das tarefas de indexação Kinesis. Estas tarefas lêem os eventos usando seu próprio mecanismo de shard e número de sequência para garantir a ingestão de uma só vez. O supervisor supervisionará o estado das tarefas de indexação para:
- Coordenar Handoffs (transferências).
- Gerenciar falhas.
- Garantir que a escalabilidade e requisitos de replicação estão mantidos.
-
-
Batch (em Lote): para o qual há três opções: Native batch, SQL ou Hadoop-based.
-
Ingestão em lote Native Batch:
Apache Druid suporta dois tipos de indexação native batch:
- Indexação paralela: que permite a execução de múltiplas tarefas de indexação concorrentemente.
- Indexação simples: que executa uma única tarefa a cada vez.
-
Ingestão em lote baseada em Hadoop:
A ingestão em lote baseada no Hadoop é suportada via uma tarefa. Estas tarefas podem ser enviadas para uma instância em execução dum Overlord. Para comparar os tipos de ingestão (baseado em Hadoop, nativo e nativo em lote), consulte o site da comunidade aqui.
-
Ingestão em lote baseada em SQL:
Druid suporta a ingestão em lote baseada em SQL usando a extensibilidade druid-multi-stage-query, que adiciona um engine de consulta multi-stage para SQL, que viabiliza a execução de operações SQL Insert e Replace como tarefas
em lote. Como recurso experimental, a operação Select também pode ser usada.
-
Processamento de consultas
As consultas são distribuídas pelo Cluster Druid e gerenciadas por um Broker. Primeiro entram no Broker, que identifica os segmentos com dados que podem pertencer àquela consulta. A lista de segmentos é sempre "quebrada" por tempo e também por outros atributos, dependendo de como a fonte de dados é particionada. O Broker identifica quais Históricos e MiddleManagers estão atendendo os segmentos e distribui uma subconsulta reescrita para cada um desses processos. Estes processos executam cada subconsulta e retornam os resultados aos Brokers, que os mescla para obter a resposta final, retornando ao chamador original.
Gestão do dado
As operações de gerenciamento de dados envolvendo replacing (substituição) ou deletion (exclusão) de segmentos incluem:
-
Schema Changes (Mudanças de Esquema) para dados novos e existentes
-
Compactação e Automatic Compaction (Compactação e Compactação Automática)
Consultas SQL:
As consultas podem ser feitas por meio do Druid SQL (Druid traduz consultas SQL em sua linguagem de consulta nativa) ou pelo SQL nativo do Druid.
O Plano SQL acontece no Broker. Para configurar o Plano e consulta JDBC as propriedades de execução do Broker devem ser configuradas.
Recursos do Apache Druid:
- Formato de armazenamento colunar: Druid usa armazenamento orientado a colunas. Significa que carrega apenas as colunas que precisa para uma consulta particular. Isto melhora a velocidade das consultas. Além disso, para suportar scans e agregações rápidas, Druid otimiza o armazenamento de cada coluna segundo seu tipo de dado.
- Formato de dados otimizado: Os dados ingeridos são automaticamente colunarizados, indexados por hora, codificados por dicionário, indexados por bitmap e compactados com reconhecimento de tipo.
- Ingestão em tempo real ou lote: O Druid pode ingerir dados em tempo real ou em lotes. Os dados ingeridos ficam imediatamente disponíveis para consulta.
- Índices para filtragem rápida: O Druid usa índices de bitmap compactados roaring ou CONCISE para criar índices para filtragem e pesquisas rápidas em várias colunas.
- Particionamento baseado em tempo: O Druid primeiro particiona os dados por tempo. Opcionalmente, pode implementar particionamento adicional com base em outros campos. As consultas baseadas em tempo acessam apenas as partições que correspondem ao intervalo de tempo da consulta, o que melhora significativamente o desempenho.
- Algoritmos aproximados: O Druid inclui algoritmos para count-distinct aproximado, classificação aproximada e cálculo de histogramas e percentis aproximados. Estes algoritmos oferecem uso de memória limitado e geralmente são substancialmente mais rápidos do que cálculos exatos. Para situações em que a precisão é mais importante que a velocidade, o Druid também oferece contagem exata e classificação exata.
- Resumo automático no momento da ingestão: O Druid opcionalmente oferece suporte ao resumo de dados em tempo de ingestão. Esse pré-resumo agrega particularmente seus dados, levando potencialmente a economias de custo significativos e aumentos de desempenho.
- Engine interativa de Consultas: Utiliza dispersão/reunião para consultas de alta velocidade com dados pré-carregados na memória ou armazenamento local, para evitar movimentação de dados e latência na rede.
- Camadas e QoS: Camadas configuráveis com qualidade de serviço que permitem a relação custo x desempenho ideal para cargas de trabalho mistas. Garantem prioridade e evitam a contenção de recursos.
- Ingestão de streams: Uma integração "connector free" com plataformas de streaming permite "query on arrival", alta escalabilidade, baixa latência e consistência garantida.
- Confiabilidade ininterrupta: Serviços de dados automáticos incluindo Backup contínuo, recuperação automatizada e replicação de vários nós garantem alta disponibilidade e "durabilidade".
Quando usar o Apache Druid
Druid é usado por muitas organizações de distintos tamanhos e para diferentes use-cases. Será uma boa escolha para as seguintes situações:
- Altas taxas de inserção e poucas atualizações.
- Predomínio de consultas e relatórios de agregação, como, por exemplo, group by (agrupamentos).
- Latências de consultas segmentadas de 100ms a alguns segundos.
- Dados com componentes de tempo (o Druid inclui otimizações e opções de design especificamente relacionadas ao tempo).
- Mesmo na existência de mais de uma tabela, cada consulta atinge apenas uma grande tabela distribuída. As consultas podem potencialmente atingir mais de uma tabela de "pesquisa" menor.
- Existem colunas de dados com alta cardinalidade (URLs, IDs de usuário) e há necessidade de contagem e classificação rápidas sobre elas.
- Carregar dados Kafka, HDFS, ficheiros simples ou armazenamento de objetos como o Amazon S3.
Quando o Apache Druid não se aplica
- Atualizações de baixa latência dos registos existentes usando uma chave primária. O Druid suporta inserções de streaming, mas não atualizações de streaming. É possível executar atualizações usando trabalhos em lote em segundo plano.
- Criação dum sistema de relatórios off-line em que a latência da consulta não é muito importante.
- Necessidade de grandes junções, o que significa a união de uma grande tabela de fatos a outra grande tabela de fatos.
Interação Apache Druid com Spark
Druid e Spark são soluções complementares, uma vez que Druid pode ser usado para acelerar consultas OLAP no Spark.
Spark é um framework geral de computação em Cluster inicialmente projetado em torno do conceito de Conjuntos de dados distribuídos resilientes (RDDs). Os RDDs permitem a reutilização de dados, mantendo resultados intermédios na memória e permitem que o Spark forneça cálculos rápidos para algoritmos iterativos. Isso é especialmente bom para certos fluxos de trabalho, como aprendizado de máquina (onde a mesma operação pode ser aplicada repetidamente até que um resultado convirja).
A generalidade do Spark o torna muito adequado como mecanismo para processar (limpar ou transformar) dados. Embora forneça capacidade de consultar dados por meio do Spark SQL, como o Hadoop, as latências de consulta não são especificamente direcionadas para serem iterativas (subsegundos).
O foco do Druid é em consultas de latência extremamente baixa e é ideal para alimentar aplicativos usados por milhares de usuários, e onde cada consulta deve retornar rápido o suficiente para que os usuários possam explorar interativamente os dados.
O Druid indexa totalmente todos os dados e pode atuar como uma camada intermediária entre o Spark e um aplicativo.
Uma configuração típica é processar dados no Spark e carregar os dados processados no Druid para acesso mais rápido. Veja detalhes da interação Druid e Spark.
Principais diferenças entre Apache Druid e os SGBDs tradicionais
- Esquemas: Druid armazena dados em datasources, similarmente a tabelas em tradicionais RDBMS. Os seus modelos de dados guardam similaridades com modelos de dados relacionais e timeseries (de série temporal).
- Seus esquemas devem sempre incluir um timestamp primário. Ele usa este campo para particionar e classificar os dados. Também usa para identificar e recuperar dados rapidamente dentro do intervalo de tempo das consultas. E para gerenciamento de dados, como dropar time chunks, sobrescrever time chunks e regras de retenção baseadas em tempo.
- Dimensões: Dimensões são colunas que o Druid armazena "como estão". Podem ser usadas para qualquer finalidade. Por exemplo, agrupamento, filtro ou agregações de dimensões no momento da consulta.
- Com o rollup desativado, Druid trata o conjunto de dimensões como um conjunto de colunas a serem ingeridas. As dimensões se comportam exatamente como qualquer Base de Dados sem suporte a um recurso "Rollup".
- Métricas: São colunas que o Druid armazena de forma agregada. São mais úteis com o Rollup ativado. Com uma métrica especificada, uma função de agregação pode ser aplicada a cada linha durante a ingestão.
Boas Práticas para Apache Druid
-
Rollup: pode acumular dados à medida em que ingere para minimizar o volume de dados brutos que necessitam ser armazenados. Isto é uma forma de sumarização ou pre-agregação.
-
Particionamento e sorting: adequados podem ter um impacto substancial no seu desempenho.
-
Sketches para colunas de alta cardinalidade:. Quando lidando com colunas de alta cardinalidade, como user ID ou outros identificadores únicos, considere o uso de sketches para uma análise aproximada antes de operar com os valores reais.
- Quando o sketch é utilizado, o Druid não armazena o dado original bruto, mas um sketch (esboço) dele que pode alimentar um cálculo posterior no momento da consulta.
- Casos de uso populares incluem cálculo de contagem distinta e quantil.
- Em geral, o sketch atende a dois propósitos: melhorar o rollup e reduzir o consumo de memória durante a consulta.
-
Strings x dimensões numéricas:. Para ingerir uma coluna com uma dimensão de tipo numérico é necessário especificar o tipo da coluna na seção dimensions. Se o tipo é omitido, Druid vai ingerir a coluna como o tipo string default.
-
Segmentos:: Para operar adequadamente sob pesadas cargas de consulta, é importante que o tamanho de ficheiro do segmento esteja dentro do intervalo recomendado de 300 a 700 MB. Se for maior que isto, considere mudar a granularidade do intervalo de tempo do segmento ou particionar seu dado e/ou ajustar o targetRowsPerSegment no partitionsSpec. Um bom ponto de partida para este parâmetro é 5 milhões de linhas.
Detalhes do Projeto Apache Druid
Apache Druid foi desenvolvido em Java.