Apache Airflow
Orquestração de Pipelines
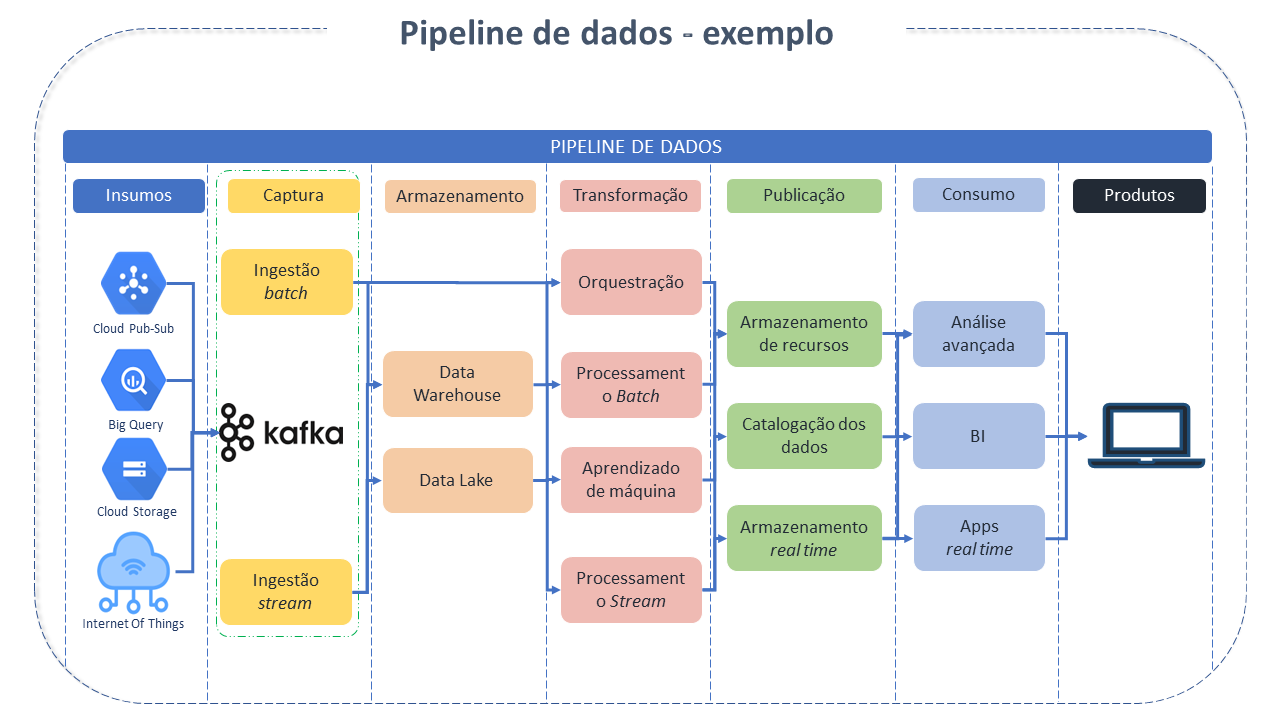
Pipeline de dados consiste num conjunto de tarefas ou ações que precisam ser executadas numa determinada ordem ou sequência lógica (Workflow) para alcançar um resultado desejado.
Os pipelines de dados podem ser representados como DAGs - _Directed Acyclic Graph - que consistem em blocos que seguem uma sequência, à medida em que o anterior é executado, permitindo bifurcações em diversos pontos, não sendo possível retornar ao ponto inicial. Nos DAGs é possível definir operadores (que se transformam em tarefas) e relações entre operadores de forma programática.
Embora muitos Orquestradores de Pipelines tenham sido desenvolvidos ao longo dos anos para executar tarefas (DAGs), o Airflow possui vários recursos importantes que o tornam especialmente adequado para implementação de pipelines de dados eficientes e orientados a lotes.
Características do Apache Airflow:
O Apache Airflow foi criado no Airbnb em 2014 como uma solução para gerenciar os seus complexos Workflows. Desde o início, o projeto é de código aberto, tendo se tornado, em 2017, um projeto Apache incubator e, em 2019, um Projeto de nível superior da Apache.
É uma ferramenta rica em recursos e funcionalidades e possui um conjunto de características fundamentais para uma solução de Big Data:
- Versatilidade: A capacidade de implementar pipelines usando código Python permite criar pipelines complexos com qualquer coisa compatível com Python.
- Fácil Integração: A base Python do Airflow facilita a extensibilidade e adição de integrações com muitos sistemas diferentes. A comunidade Airflow já desenvolveu uma rica coleção de extensões para diferentes bases de dados, serviços em nuvens, etc.
- Rica semântica de programação: Permite a execução de pipelines em intervalos regulares e criação de pipelines eficientes usando processamento incremental para evitar recálculos dispendiosos de resultados existentes.
- Backfilling: Permite o reprocessamento de dados históricos de forma fácil, e o recálculo de qualquer conjunto de dados derivados após mudanças no código.
- Interface Web Rica: A rica interface web do Airflow disponibiliza visualização fácil para monitorização de resultados de execuções de pipeline bem como a depuração de quaisquer falhas.
- Código aberto: Garante a criação de trabalhos sem qualquer dependência de disponibilizador.
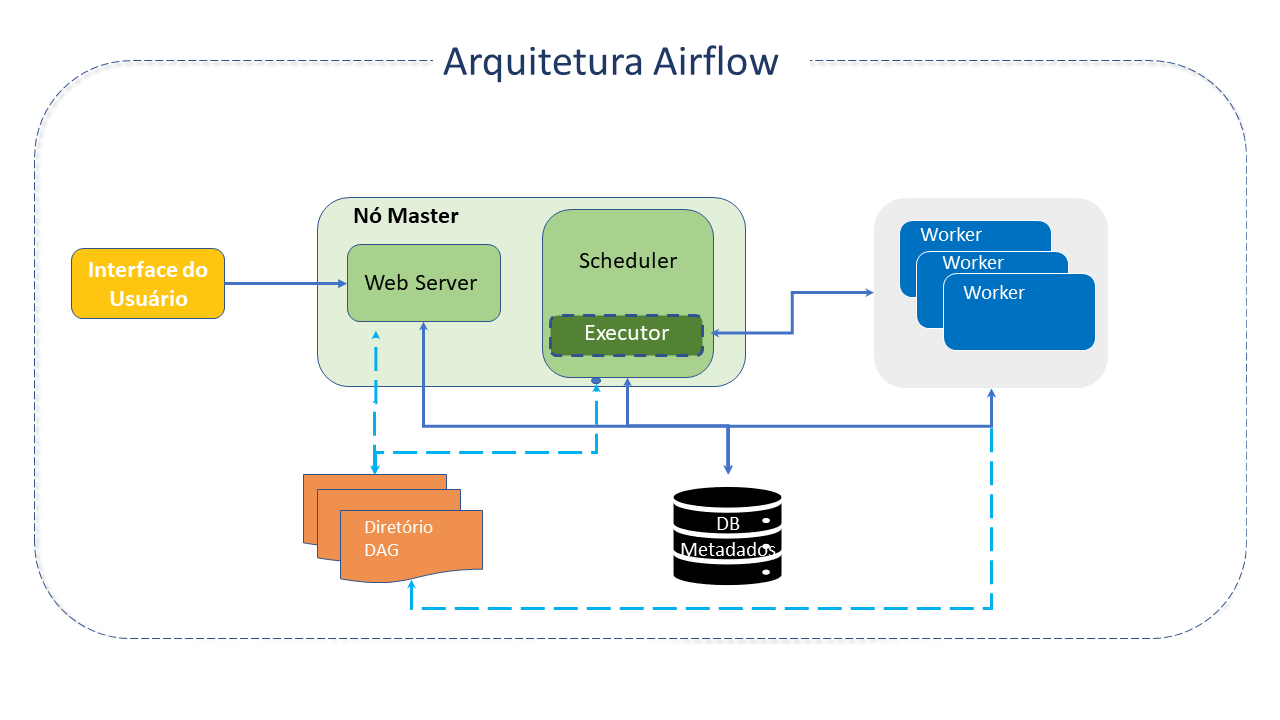
Arquitetura do Apache Airflow
O Airflow é organizado a partir dos seguintes componentes principais:
-
DAGs - _Directed Acyclic Graph: O DAG é o conceito principal do Airflow. Representa um Workflow (uma coleção de tarefas individuais, organizadas com suas respectivas dependências e fluxos de dados - as próprias tarefas descrevem o que será feito, como busca de dados, análise, acionamento de outro app, etc).
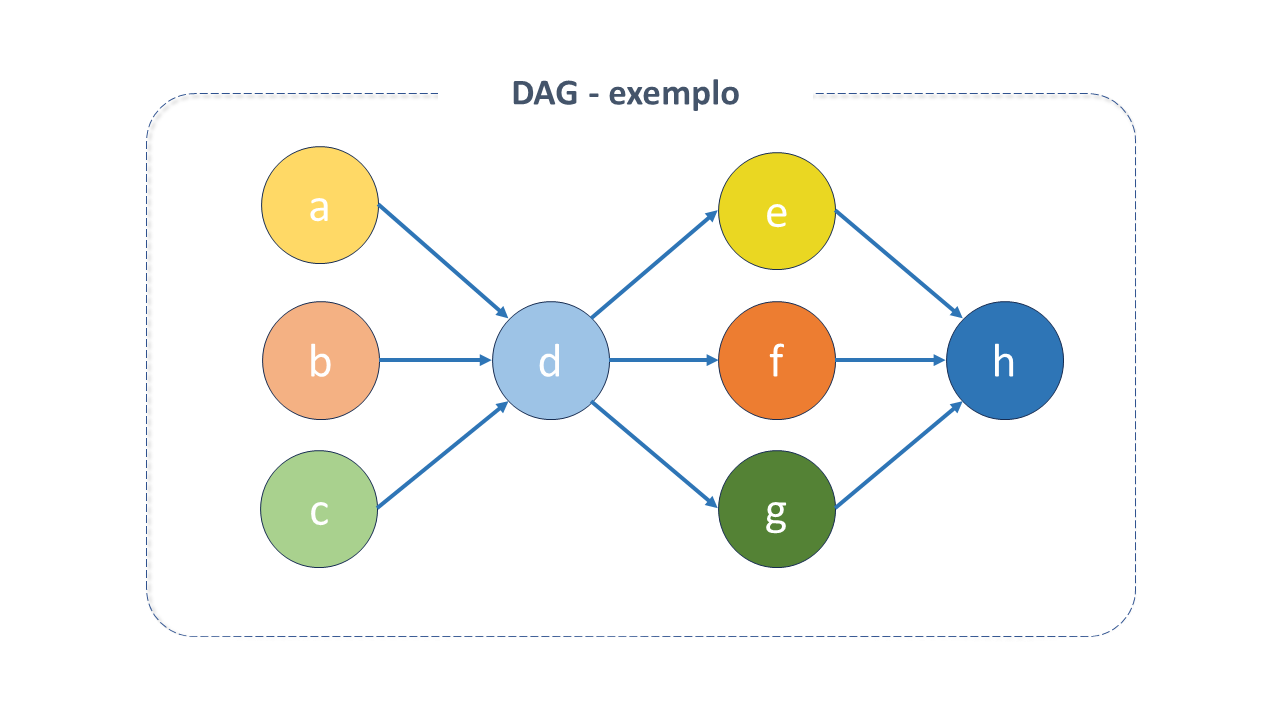 Figura 3 - Exemplo da estrutura dum DAG
Figura 3 - Exemplo da estrutura dum DAGO DAG não se preocupa com o que acontece dentro de uma tarefa, mas em como executá-la (a ordem de execução, quantas vezes repeti-las, se há um tempo limite, etc). A estrutura DAG é composta da declaração das dependências entre tarefas.
Fora isso, os ficheiros DAG contêm alguns metadados adicionais sobre o DAG informando ao Airflow como e quando deve ser executado. Esta abordagem programática oferece muita flexibilidade para criar DAGs e permite personalização na forma de criação dos pipelines.
Os DAGs não requerem agendamento, mas é muito comum que sejam definidos, o que é feito pelo Scheduler .
Um DAG é executado de duas maneiras: acionado manualmente ou por meio de API ou num cronograma definido, como parte do DAG.
Seus parâmetros mais importantes são:
-
Scheduler: O Scheduler lida com o acionamento de workflows agendados e com o envio de tarefas, para o Executor.
-
Webserver: Apresenta uma interface de usuário que permite a visualização dos DAGs e tarefas, sua inspeção, acionamento, depuração e análise dos seus resultados.
-
Executor: Processo que lida com as tarefas em execução. Numa instalação padrão é executado dentro do Scheduler. Entretanto, a maioria dos Executores adequados para a produção envia a execução da tarefa para os Workers.
A maior parte dos Executores irá introduzir outros componentes para que possam "conversar" com seus Workers (como a fila de tarefas). Entretanto, podemos entender o Executor e seus Workers como um componente lógico único lidando com a execução da tarefa.
O Executor é configurável e, dependendo dos requisitos, é possível escolhê-lo dentre algumas opções:
-
Locais:
-
Sequential Executor: É o executor default. Irá executar uma instância de tarefa por vez.
-
Local Executor: Executa tarefas gerando processos de maneira controlada em diferentes modos. Dado que o BaseExecutor tem a opção de receber um parâmetro de paralelismo para limitar o número de processos gerados, quando este parâmetro é 0, o número de processos que o Local Executor pode gerar fica ilimitado.
-
-
Remotos:
-
Dask Executor: Permite a execução de tarefas Airflow num Cluster Dask Distributed. Clusters Dask podem executar numa máquina única ou redes remotas.
-
Celery Executor: É um dos caminhos para escalar o número de workers.
-
Kubernetes Executor: Introduzido no Apache Airflow 1.10.0, permite que o Airflow seja dimensionado com muita facilidade à medida que as tarefas são executadas no Kubernetes.
-
Celery Kubernetes Executor: Permite a execução simultânea de Celery Executor e Kubernetes Executor. Herda a escalabilidade do Celery Executor para lidar com altas cargas em horário de pico e isolamento do tempo de execução do KubernetesExecutor.
-
-
-
Workers: São processos separados que executam as tarefas agendadas.
-
Ficheiros DAG: Armazenam os ficheiros que são lidos pelo Scheduler e Executor (e pelos Workers que o Executor tenha).
-
Base de Dados de metadados: Bases de dados SQL usado pelo Scheduler, Executor e Webserver para armazenar metadados sobre os pipelines de dados que estão a ser executados.
Recursos do Apache Airflow
-
Pooling: Os pools são uma funcionalidade adicional que disponibiliza mecanismos de gerenciamento de recursos. Os pools limitam a execução paralela no recurso quando muitos processos o demandam ao mesmo tempo, evitando sobrecarga.
-
Queuing: Todas as tarefas vão para a fila padrão. É possível definir filas e workers para consumir tarefas de uma ou mais filas. As filas são especialmente úteis quando algumas tarefas precisam ser executadas num ambiente ou recurso específico.
-
Plugins: O Airflow tem um gerenciador de plugins simples que pode integrar recursos externos ao seu núcleo simplesmente "soltando" ficheiros na pasta $Airflow_home/plugins. Os módulos Python na pasta plugins são importados e as macros e exibições da web são integradas às principais coleções do Airflow e ficam disponíveis para uso.
Conceitos importantes:
-
Dag Runs: Toda vez que se executa um DAG, uma nova instância dele é criada, chamada pelo Airflow de Dag-Run. As Dag-Runs podem ser executadas em paralelo para o mesmo DAG e cada uma tem um intervalo de dados definido que identifica o período de dados e quais tarefas deve operar.
-
Tasks: Embora do ponto de vista do usuário tarefas e operadores sejam equivalentes, no Airflow existem componentes tarefas que gerem o estado de operação dos operators (definem uma unidade de trabalho dentro dum DAG por meio dos operadores). São representadas como um nó da DAG.
Existem três tipos comuns de tarefas:
-
Operators: São, conceitualmente, um template para tarefas pré-definidas que podem ser declaradas dentro do DAG. São os componentes especializados na execução de uma única e específica tarefa dentro do Workflow. É um passo no Workflow e geralmente (não sempre) é atómico, não carregando informações de operadores anteriores. Desta forma, detém autonomia. Como são eles que efetivamente executam as tarefas, muitas vezes ambos os termos são utilizados. O Airflow tem um conjunto extenso de operadores disponíveis, alguns integrados ao núcleo ou pré-instalados. Os mais populares são:
-
PythonOperator chama uma função Python.
-
EmailOperator: manda um email.
-
BashOperator: executa um script Bash, comando ou conjunto de comandos.
-
Sensors: Uma subclasse especial de Operators que fica à "espera" dum evento externo.
-
Operators: Uma função customizada Python empacotada como uma tarefa. Torna a criação de DAGs muito mais fácil para quem usa código Python simples em vez de Operators para escrever DAGs.
note- Se dois operadores precisarem partilhar informações, podem ser combinados num único operador. Se isto não for possível há um recurso de comunicação cruzada chamado xcom.
- Operadores não precisam ser atribuídos às DAGs imediatamente (mas, uma vez atribuído, não pode ser transferido ou não-atribuído).
-
-
**Task instances****: Representam o estado de uma tarefa -> em qual etapa do ciclo de vida a tarefa se encontra. Instancia uma tarefa - que foi designada a um DAG e tem um estado associado a uma execução específica. Os estados possíveis são:
- None: A task não foi adicionada à fila de execução (escalonada) pois suas dependências ainda não foram supridas.
- Scheduled: As dependências foram supridas e a tarefa pode ser executada.
- Queued: a tarefa foi vinculada a um worker pelo executor e está aguardando disponibilidade para execução.
- Running: a tarefa está em execução.
- Success: a tarefa foi executada sem erros.
- Failed: a tarefa encontrou erros durante a execução e falhou.
- Skipped: a tarefa foi bypassada devido a algum mecanismo.
- Upstream failed: as dependências falharam e, portanto, a tarefa não foi executada.
- Up for retry: a tarefa falhou mas existem mecanismos definidos para novas tentativas e, portanto, pode ser re-escalonada.
- Sensing: A tarefa é um smart sensor.
- Removed: a tarefa foi removida da DAG desde a sua última execução.
-
Boas Práticas para o Apache Airflow
A comunidade Apache disponibiliza uma série de Boas práticas, dentre as quais resumimos algumas a seguir:
- Escrever um DAG: Embora a criação dum novo DAG no Airflow seja uma tarefa bem simples, a comunidade alerta para uma série de cuidados necessários para garantir que sua execução não produza resultados inesperados.
- Gerar DAG dinâmico: Algumas vezes escrever um_DAG_manualmente não é prático. O recurso de geração dinâmica de DAGs pode ser útil nestas ocasiões.
- Acionamento de DAGs após alterações: O sistema necessita de tempo suficiente para processar ficheiros alterados. É recomendável que se evite acionar DAGs logo após a sua alteração ou a alteração de ficheiros que o acompanhem.
- Reduzir a Complexidade do DAG: Embora o Airflow seja bom para lidar com grandes volumes de DAGs com muitas tarefas e dependências, DAGs muito complexos e em grande quantidade podem afetar o desempenho do Scheduler. É recomendável simplificá-los e otimizá-los sempre que possível.
- Testar um DAG: Os DAGs devem ser tratados como código de nível de produção e possuir inúmeros testes associados, para garantir que produzam os resultados desejados. É possível escrever uma grande variedade de testes para um DAG.
- Manutenção do DB Metadados: Com o passar do tempo, a base de Metadados aumenta sua área de cobertura de armazenamento. O CLI do Airflow permite limpar dados antigos com o command airflow db clean.
- Manipular dependências conflitantes/complexas do Python: O Airflow possui muitas dependências do Python que, às vezes, entram em conflito com o que o código deseja. A comunidade oferece algumas estratégias que podem ser empregadas para mitigar os riscos.
Detalhes do Projeto Apache Airflow
O Airflow foi escrito em Python. Os seus fluxos de trabalho são criados por meio de scripts Python. Foi projetado sob o princípio de "configuration as code". Embora existam outras ferramentas que adotem este princípio, o uso do Python é o que permite aos desenvolvedores a importação de bibliotecas e classes.
Fonte(s):