Criação do Cluster e Instalação dos Componentes
Após a instalação do serviço do Apache Ambari, o próximo passo é a criação do Cluster de Big Data, incluindo a instalação dos demais serviços/componentes desejados.
Vamos Começar!
-
Utilize um browser para acessar a interface web do Ambari disponível no IP/hostname da máquina do Ambari Server, porta 8080. Por exemplo:
http://192.168.56.100:8080
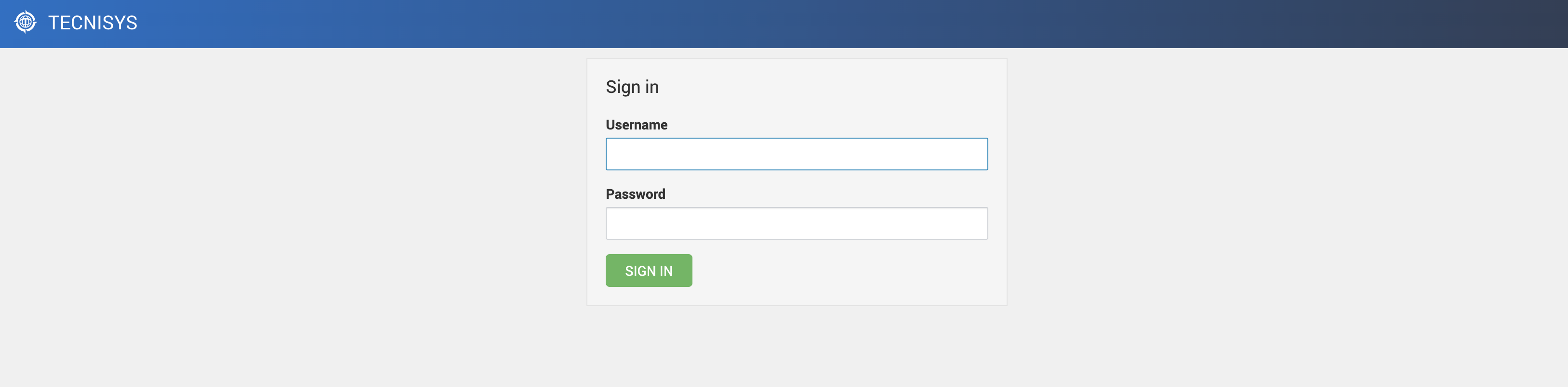
| Por padrão, o usuário / senha de acesso são, respectivamente, admin / admin. |
-
No primeiro acesso será exibida uma página inicial de boas vindas. Para iniciar o processo de implantação do Cluster clique no botão LAUNCH INSTALL WIZARD:
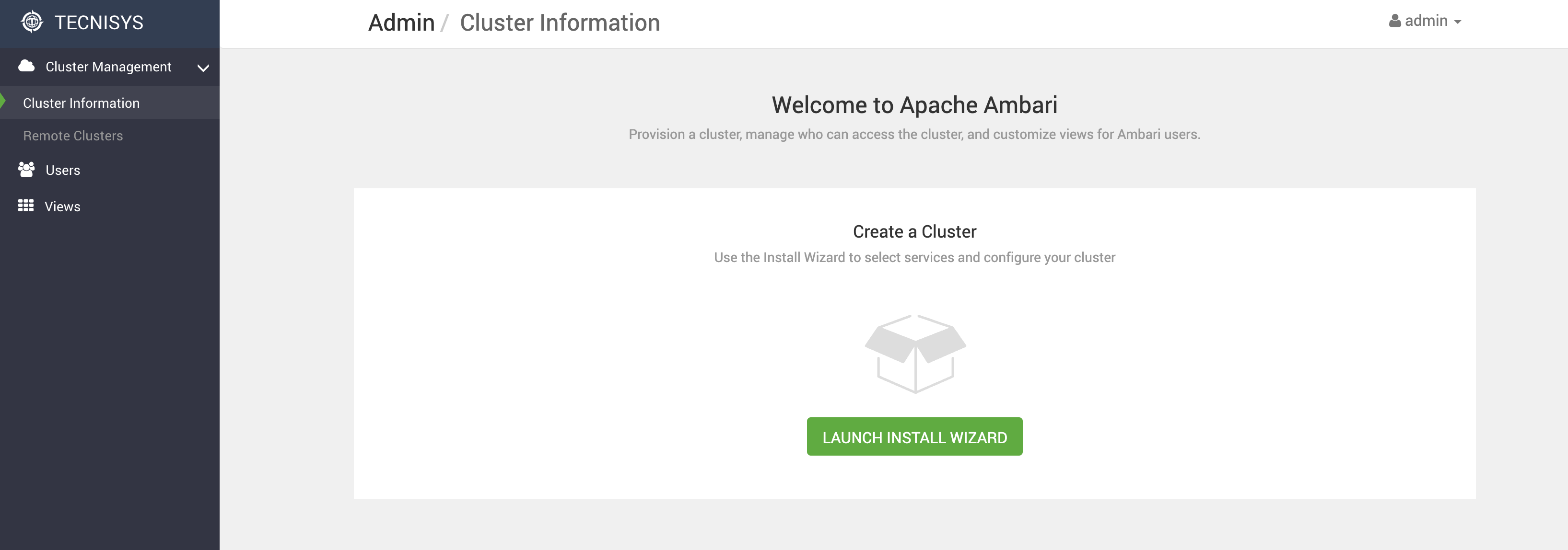
-
Informe um nome para o Cluster e clique em NEXT:
Seleção da Versão
-
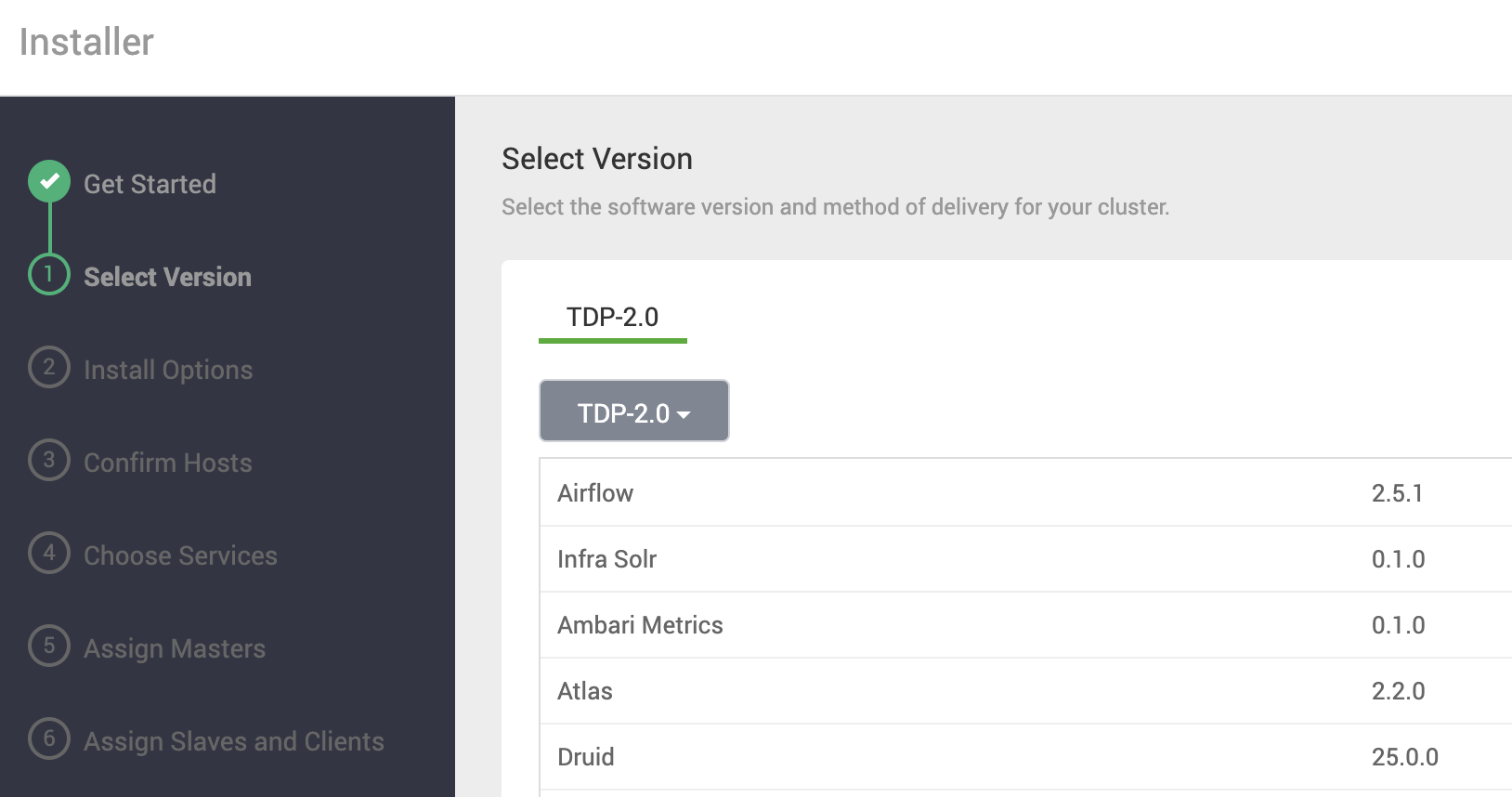
Selecione a versão do TDP desejada:
-
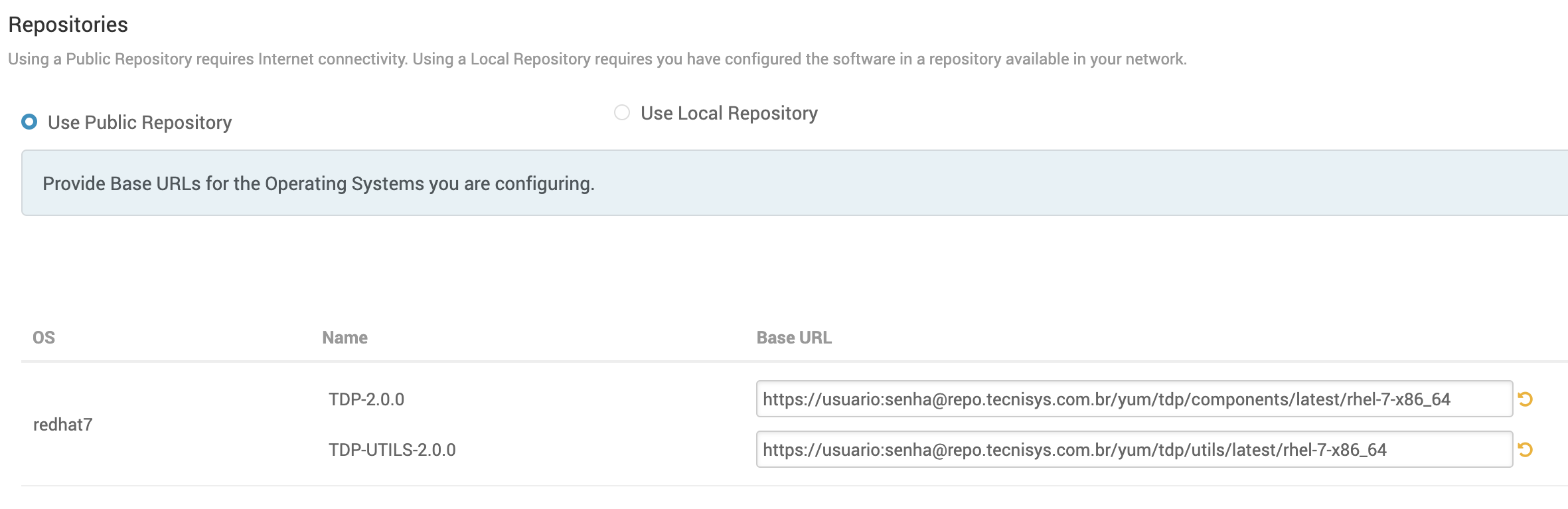
Selecione o tipo do repositório de pacotes (Public ou Local) e informe a URL para Components (TDP-2.2.0) e Utils (TDP-UTILS-2.2.0):
-
Na sequência, clique em NEXT.
| Caso opte pela utilização do Repositório Público de Pacotes da Tecnisys, as credenciais de acesso (usuário e senha) devem ser informados diretamente na URL, conforme demonstrado na imagem acima. |
Opções de Instalação
-
Em Target Hosts, infome o Fully Qualified Domain Name (FQDN) dos hosts (máquinas) que irão compor o Cluster.
O Ambari Server precisa ter acesso às máquinas informadas. Certifique-se que a resolução do FQDN das máquians ocorra corretamente, seja através de um Servidor de DNS (recomendado) ou localmente (arquivo /etc/hosts).
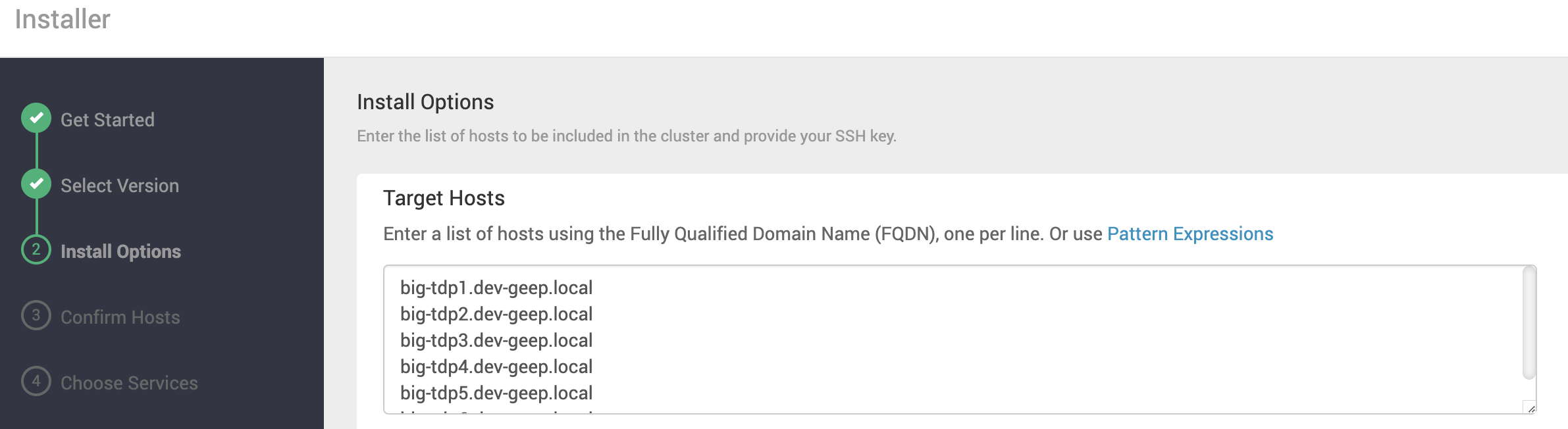
| Em Target Hosts, é possível informar as máquinas usando Expressões (Pattern Expressions). O exemplo apresentado na figura acima ficaria assim: big-tdp[1-7].dev-geep.local |
-
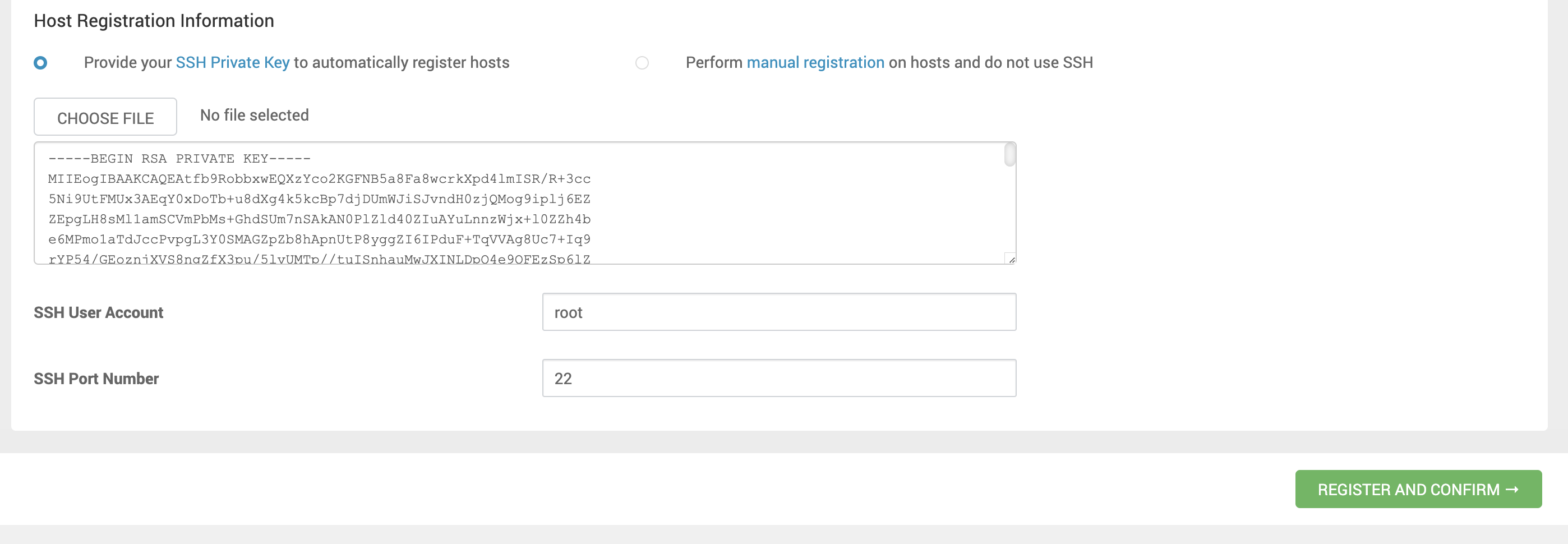
Em Hosts Registration Information, selecione como as máquinas do Cluster serão registradas.
-
Caso opte por fornecer a chave SSH privada da máquina do Ambari Server para o registro automático das máquinas do Cluster, cole o seu conteúdo no campo de texto abaixo ou faça o upload de seu arquivo. Na sequência, confirme o usuário e a porta SSH a serem utilizados.
Além disso, certifique-se que a Relação de Confiança (a troca das chaves SSH) tenha sido realizada corretamente, sendo possível, a partir da máqina do Ambari Server, acessar todas as máquinas via SSH sem a informação da senha do usuário do daemon do Ambari Server (por padrão, root). -
Caso opte por realizar o registro manual das máquinas, faça você mesmo a instalação do Ambari Agent em todas as máquinas antes de prosseguir.
-
-
Na sequência, clique em REGISTER AND CONFIRM.
|
A chave SSH privada do tipo RSA pode ser obtida executando o seguinte comando: |
|
Para instalar manualmente o Ambari Agent: |
Configuração da Relação de Confiança
-
Na máquina do Ambari Server, gere uma chave SSH privada:
ssh-keygen -
Copie a chave SSH para TODAS as máquinas do Cluster. Por exemplo:
ssh-copy-id tdp-mn01.tecnisys.com.br -
Teste o acesso via SSH à TODAS as máquinas do Cluster sem a informação da senha do usuário. Por exemplo:
Confirmação dos Hosts
Após a instalação do Ambari Agent em todas as máquinas informadas na etapa anterior, o Ambari realiza uma série de verificações para garantir que os pré-requisitos foram atendidos (JDK, Firewall, THP, entre outros).
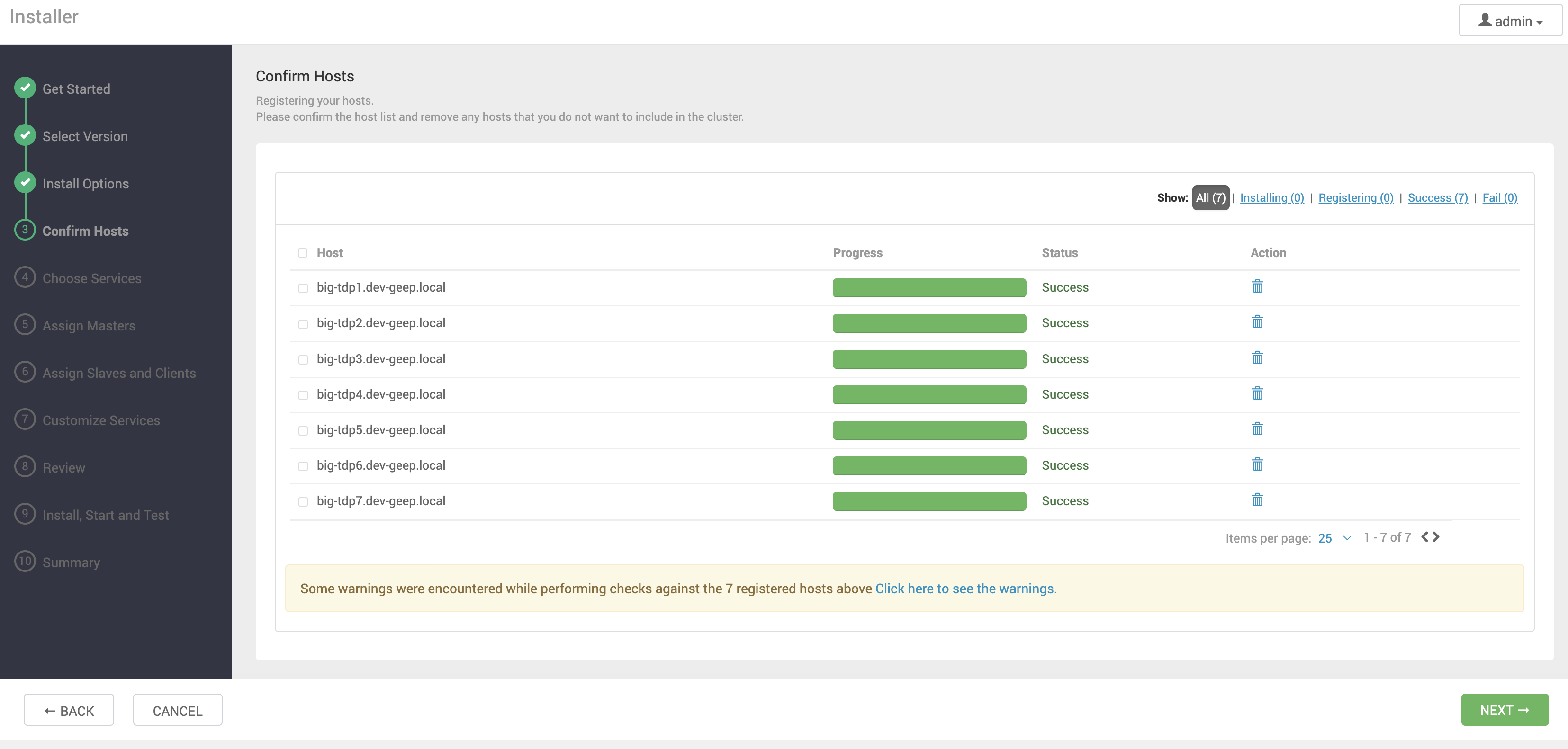
Eventuais erros precisam ser corrigidos e a verificação reexecutada para prosseguir.
Clique em NEXT para avançar.
| Alertas do tipo Package Issues, referentes aos pacotes do PostgreSQL já instalados, podem ser desconsiderados. |
Seleção dos Serviços
-
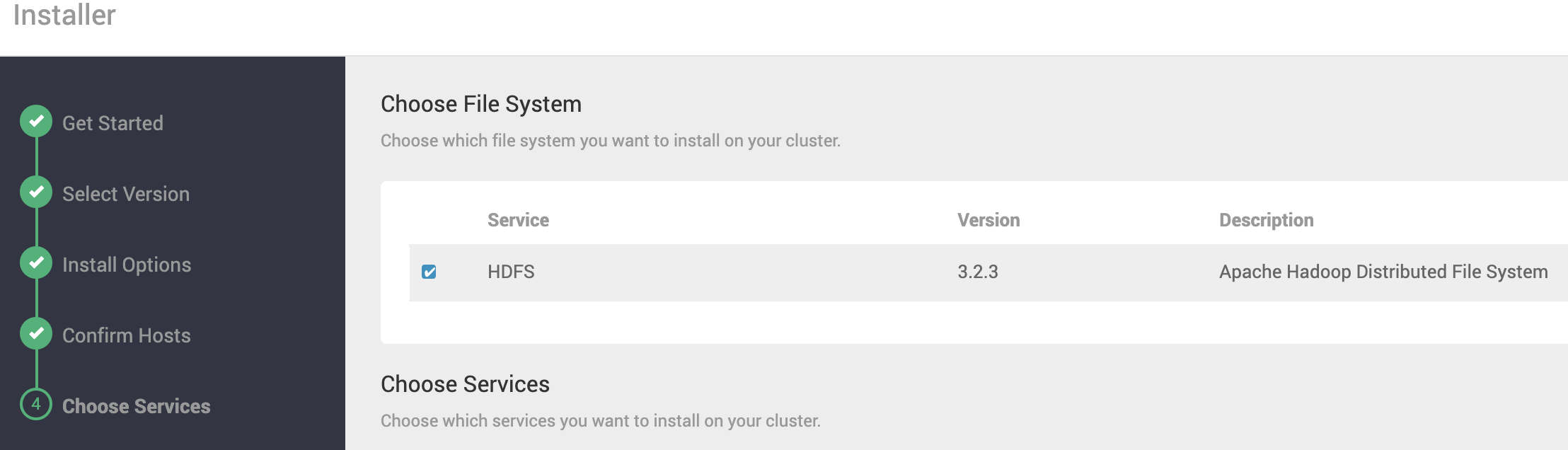
Selecione o serviço responsável pala camada de armazenamento do Cluster.
-
Selecione os demais serviços do Cluster.

| Recomendamos, inicialmente, a seleção dos serviços básicos, como YARN + MapReduce2, Tez, Zookeeper, Infra Solr e Ambari Metrics. Os demais serviços, caso necessário, podem ser adicionados após a criação do Cluster. Assim é mais fácil lidar com possíveis problemas nas instalação dos componentes. |
| O Cluster requer determinados serviços para operar plenamente, como por exemplo, o Apache Ranger para a camada de segurança e o Apache Atlas para a camada de governança de dados. Logo, o Ambari apresentará alertas caso alguma funcionalidade venha a ser limitada pela não instalação de um serviço específico. Ignore o alerta (clique no botão PROCEED ANYWAY) caso o serviço em questão venha a ser instalado futuramente, ou caso esteja ciente de tal limitação. |
-
Na sequência, clique em NEXT.
Atribuição dos Componentes Masters
-
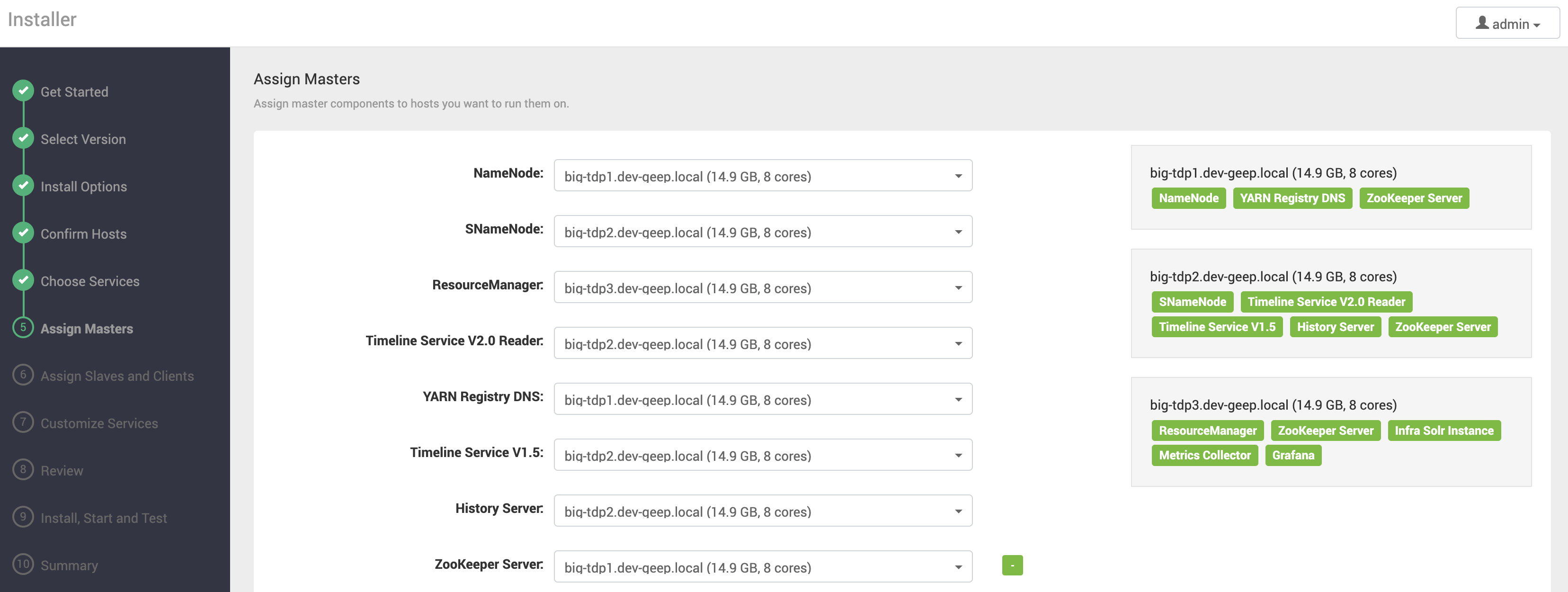
Indique a máquina de cada um dos componentes Masters (em geral, componentes de gerenciamento e coordenação) dos serviços selecionados. Observe que à direita da página é apresentado a organização dos componentes por máquina.
|
A organização deve ser feita considerando as necessidades de cada componente e os recursos disponíveis em cada máquina. Algumas recomendações podem ser observadas:
|
-
Na sequência, clique em NEXT.
Atribuição dos Componentes Slaves e Clients
-
Indique em quais máquinas serão instalados os componentes Slaves (em geral, componentes de armazenamento e processamento) e Clients.
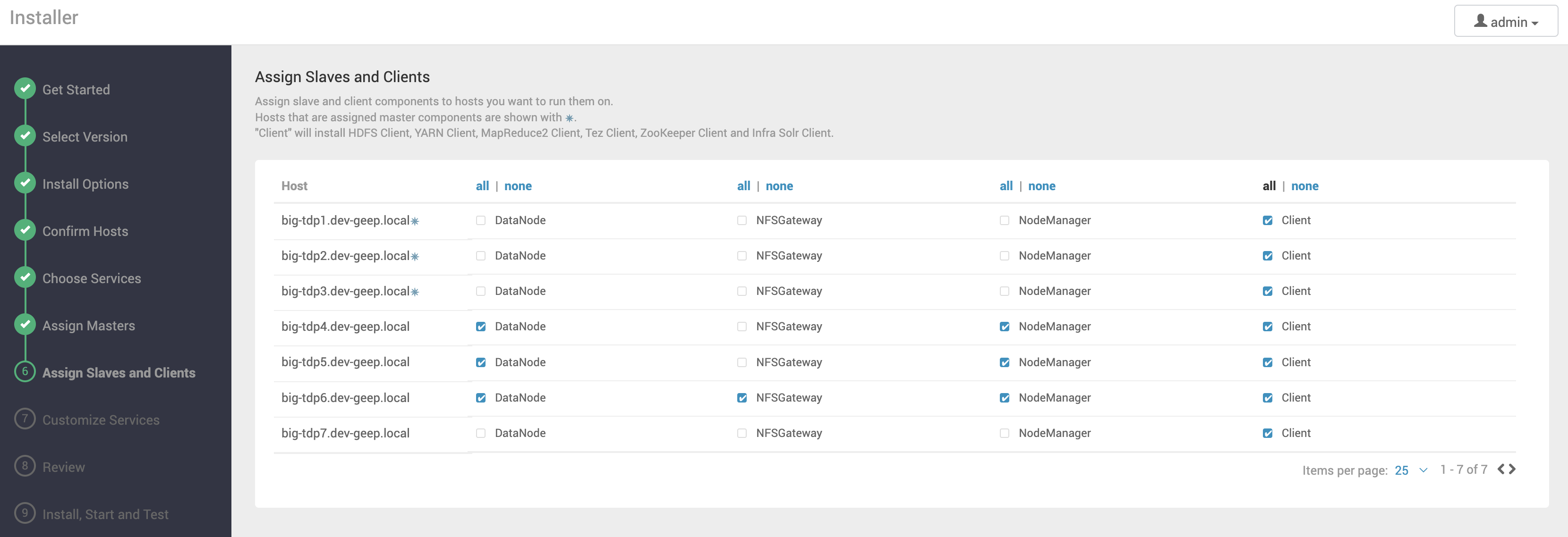
| Sempre que possível, evite instalar componentes Slaves em máquinas de componentes Masters. |
-
Na sequência, clique em NEXT.
Customização dos Serviços
Nessa etapa devem ser definidas as credenciais de acesso, dados de conexão à bancos de dados, diretórios, usuários, entre outras informações próprias de cada serviço e necessárias para a instalação.
Resolva as pendências de todas as seções dessa etapa e clique em NEXT para avançar.
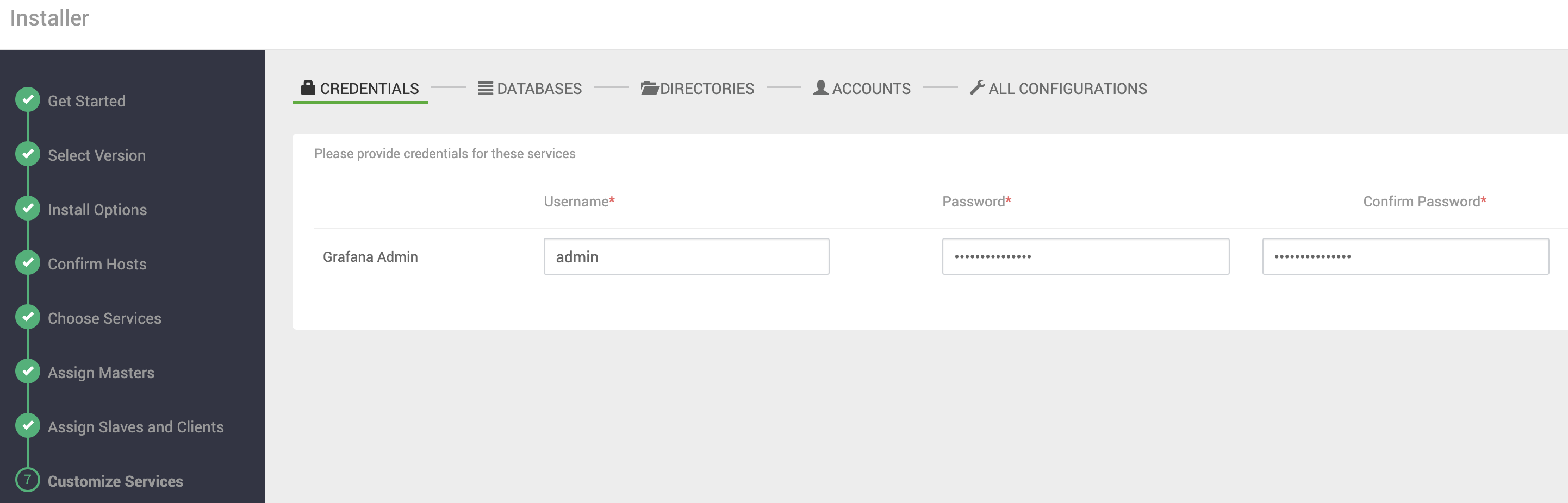
Credenciais
Ilustrando essa seção temos o Grafana, componente do Ambari Metrics, que requer a definição do usuário e senha de adminsitração da ferramenta:
Bancos de Dados
Ilustrando essa seção temos o Hive, o qual requer um banco de dados para persistência de metadados. Nesse exemplo, informamos os dados de conexão para uma instância PostgreSQL existente:
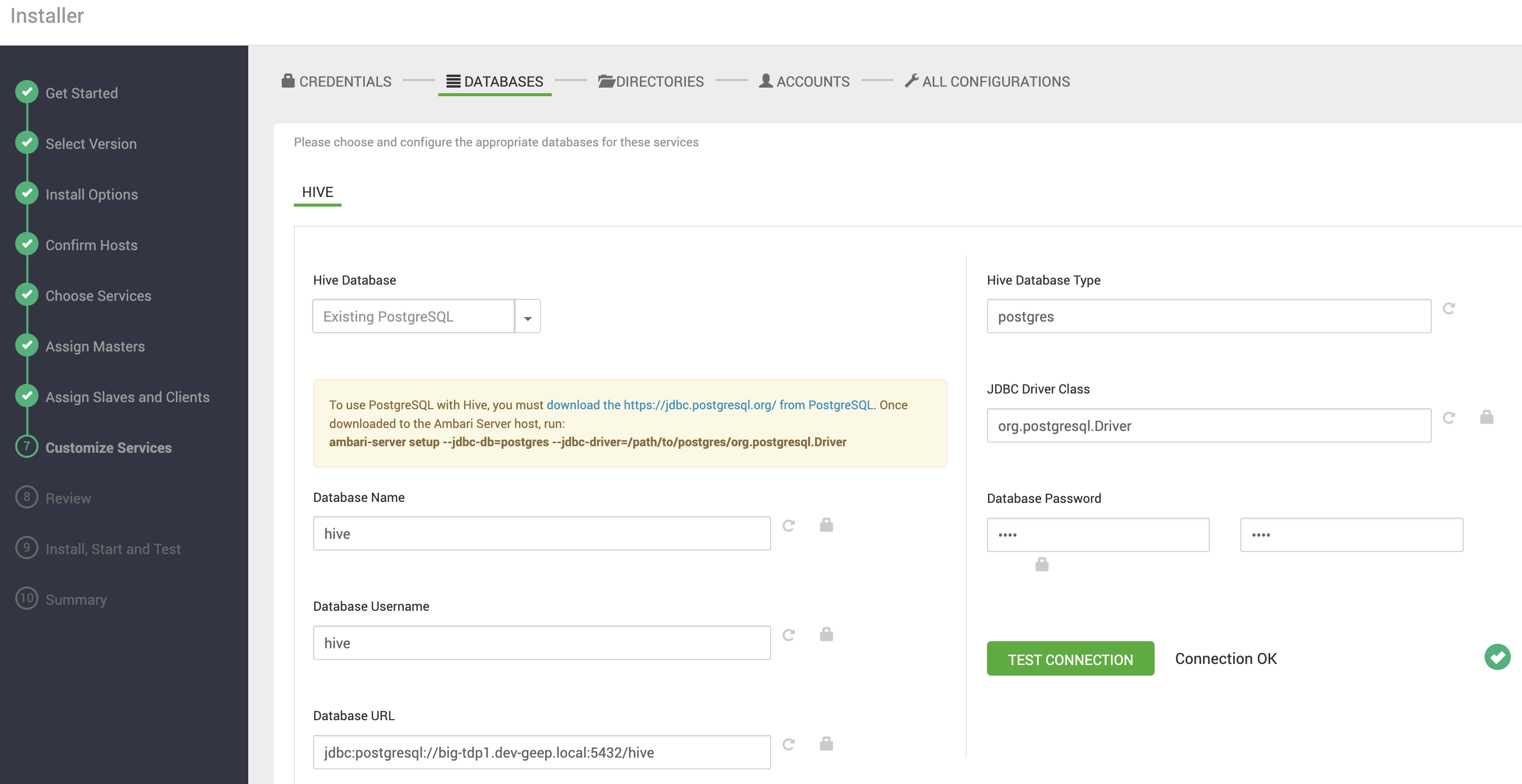
| Clique no botão TEST CONNECTION para testar a conexão com o banco de dados informado. |
Diretórios
Nesta seção é possível customizar os diretórios dos serviços, como por exemplo, os diretórios de dados dos DataNodes, os diretórios da namespace do NameNode, diretórios de log, etc.
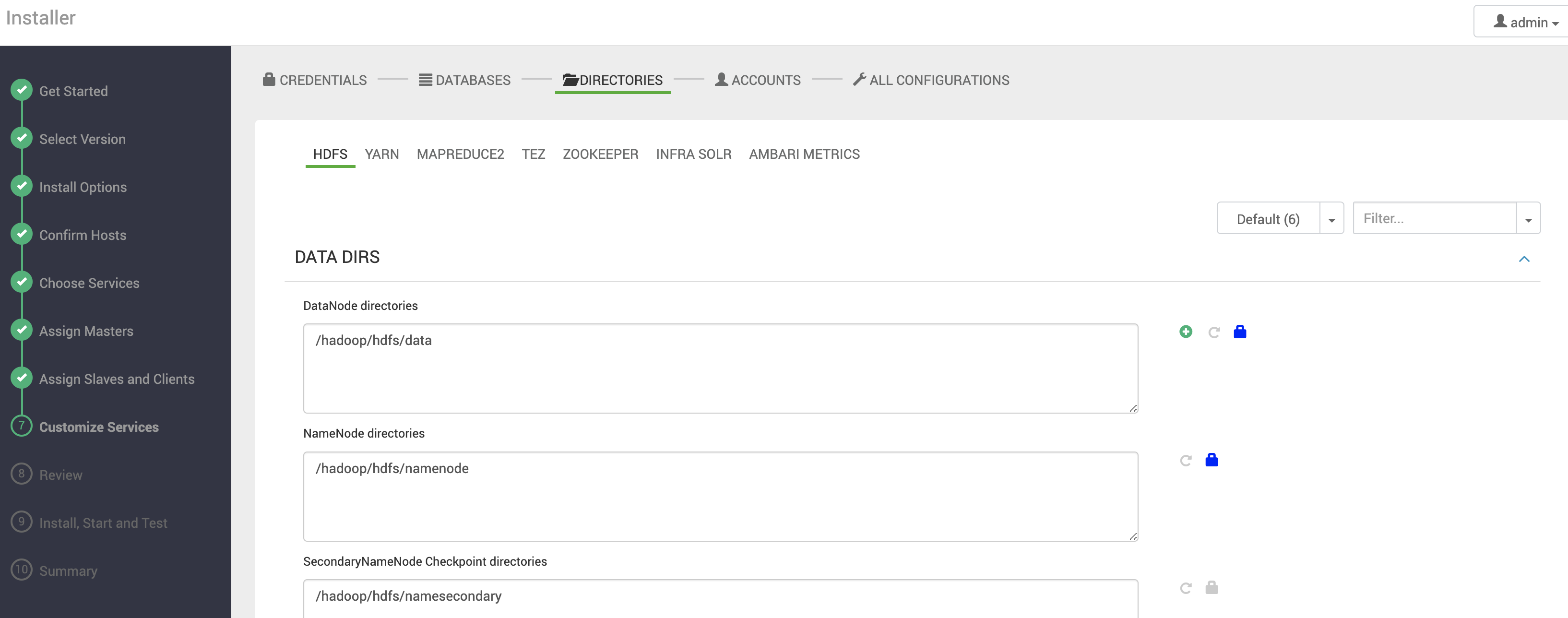
| Se possível, use dispositivos de armazenamento (discos, SSD, entre outrs), volumes e diretórios exclusivos para os arquivos dos DataNodes, NameNodes, JournalNodes, NodeManagers, Timeline Services e Zookeeper. |
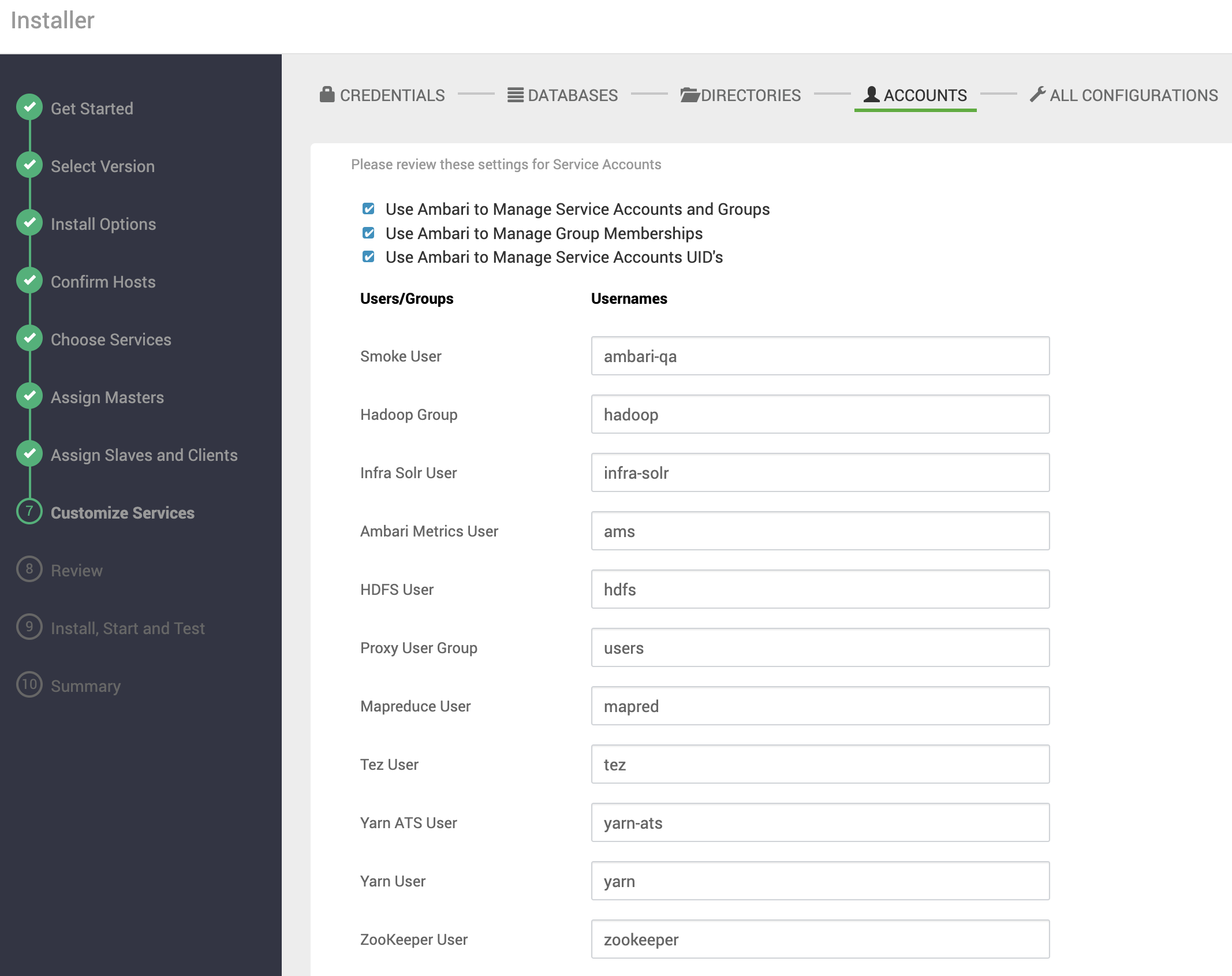
Usuários dos Serviços
Nesta seção é possível customizar os usuários de sistema operacional que serão criados para cada serviço.
Todas as Configurações
Esta última seção dá acesso a todas as configurações dos serviços a serem instalados. Aproveite para conferir e ajustar o que for necessário.
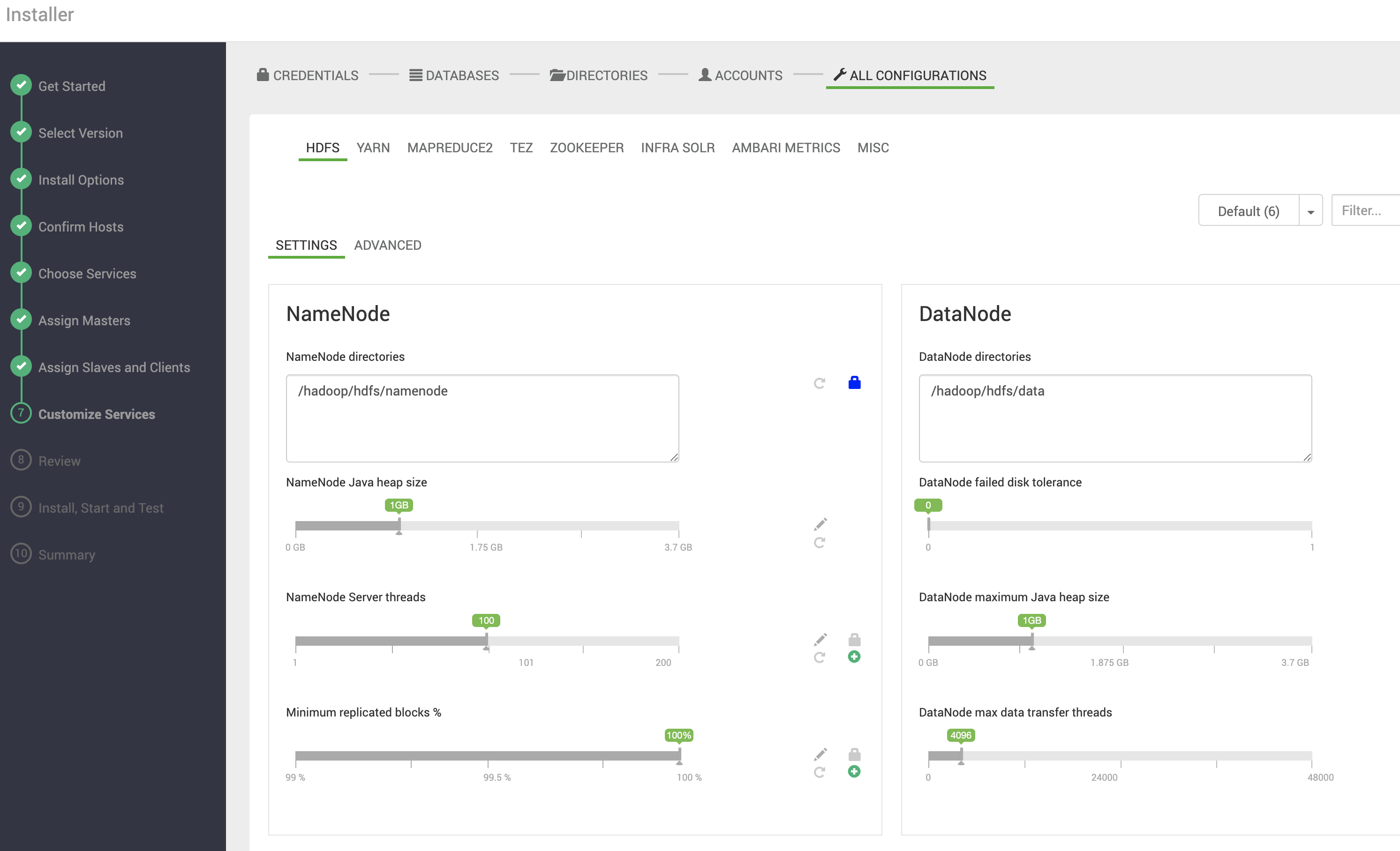
Caso tenha esquecido alguma configuração, não se preocupe. Após a instalação todas essas configurações também estarão disponíveis para alteração via Ambari.
Revisão das Configurações
Nessa etapa, a última antes da criação do Cluster, é apresentada uma revisão das configurações definidas. Verifique cuidadosamente todas as informações e, sendo necessário alterar alguma configuração, utilize a área de navegação lateral esquerda para retornar na etapa desejada.
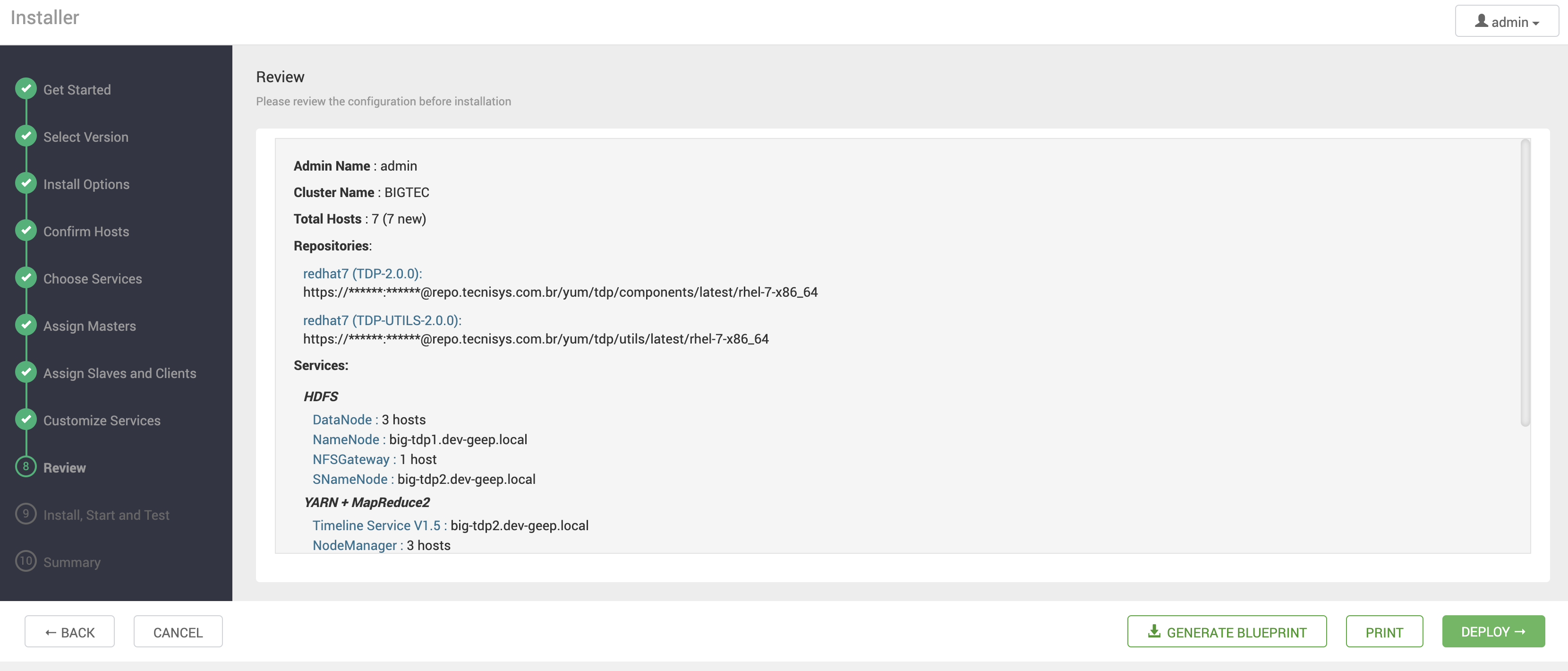
| Utilize o botão PRINT para gerar um relatório da instalação e o botão GENERATE BLUEPRINT para gerar um arquivo XML com todas as configurações definidas e que, futuramente, pode ser utilizado para recriar o Cluster via Ambari REST API. |
Para iniciar a implantação do Cluster, clique no botão DEPLOY.
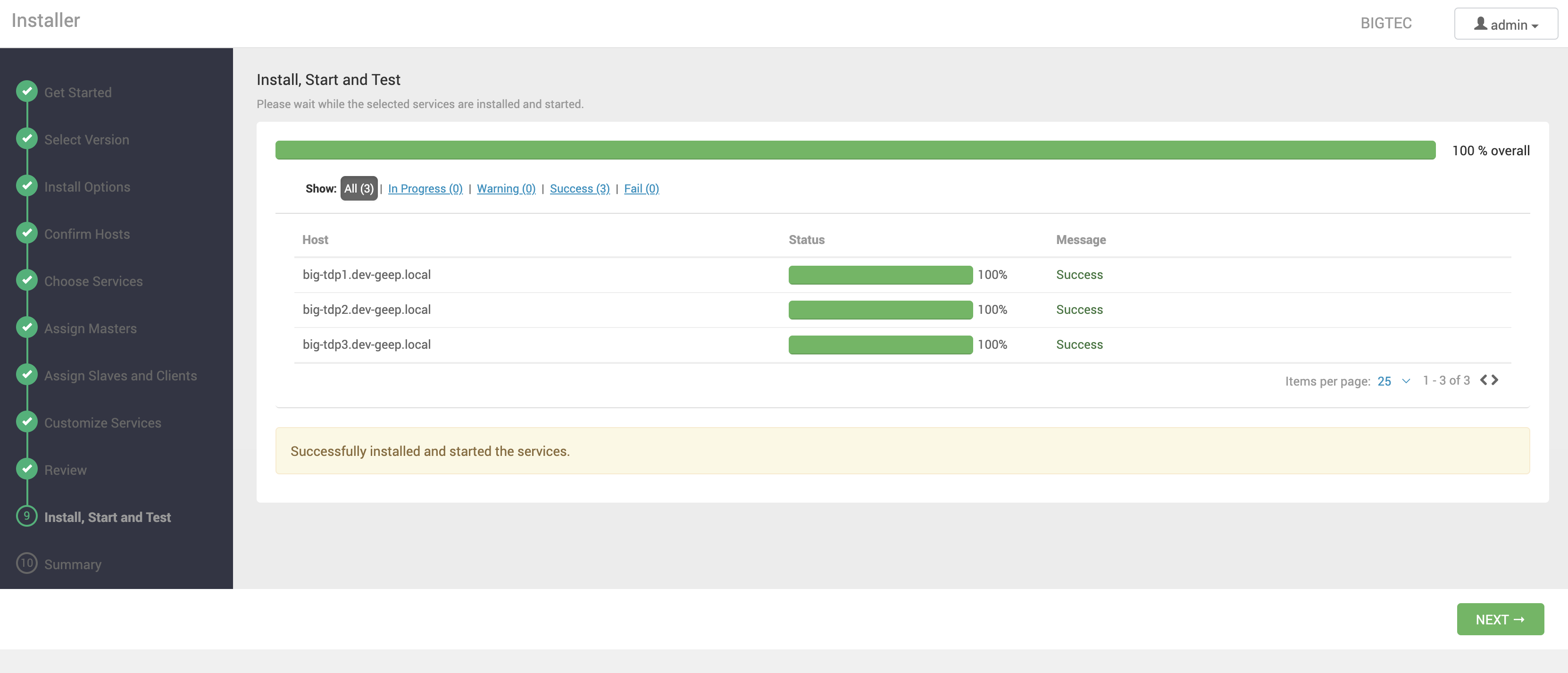
Instalação, Iniciação e Teste dos Serviços
Nessa etapa os serviços serão instalados, iniciados e testados, respeitando as dependências e integrações de cada um.
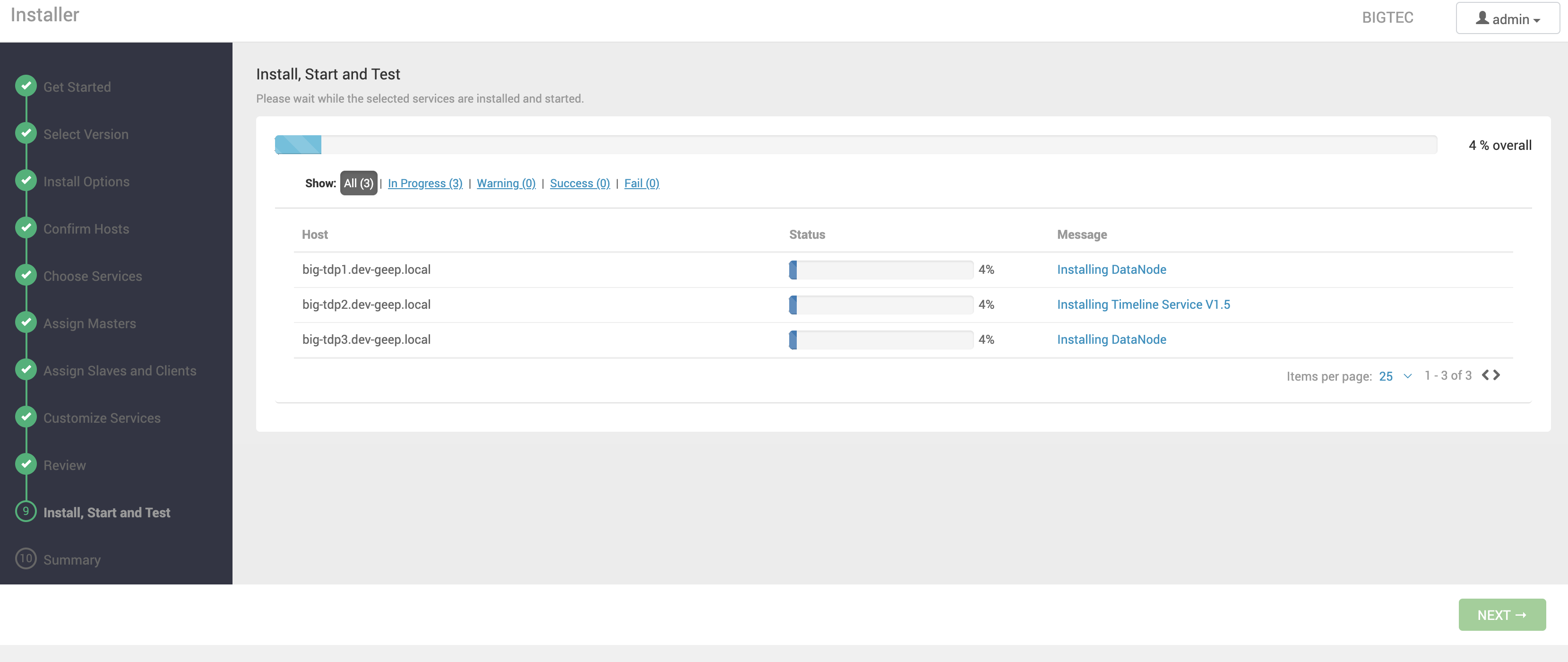
| Clique no link do texto da coluna Message para visualizar as tarefas programadas para cada máquina. |
Na ocorrência de falhas, o Ambari pode interromper a implantação, sendo possível retomá-la após a correção do problema clicando no botão RETRY.
No entanto, de acordo com o progresso já realizado, o Ambari pode concluir a implantação e disponibilizar o Cluster como ele está, mesmo que nem todos os componentes de um determinado serviço tenham sido instalados, iniciados ou testados com sucesso. Nesse caso, após criado o Cluster é possível, pelo próprio Ambari, alterar as configurações ou remover e instalar novamente apenas o serviço problemático.
Finalizada a implantação, clique em NEXT.