Apache YARN
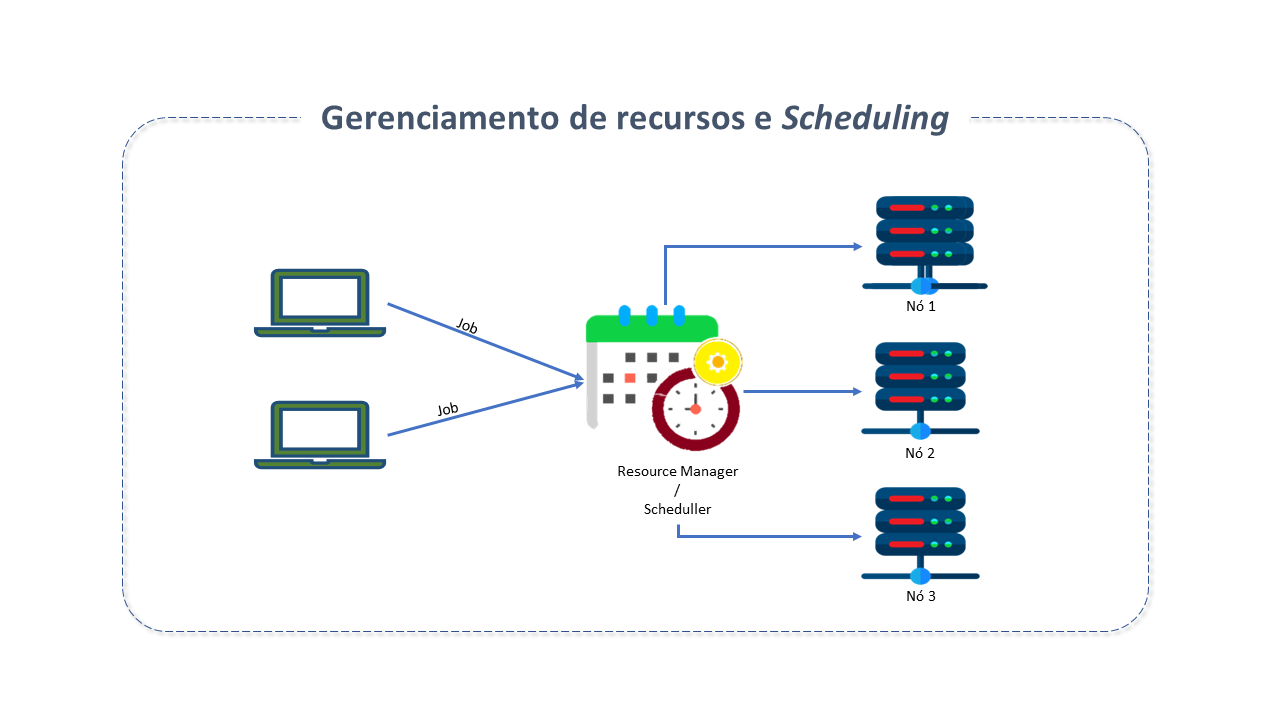
Gerenciamento de Recursos
O Processamento de Big Data é uma tarefa difícil e não é viável em um sistema centralizado. Soluções de computação distribuídas precisam ser adotadas para viabilizar o processamento paralelo exigido pela tecnologia.
Nesse ambiente, vários locatários, com diferentes demandas, podem compartilhar recursos de computação como dados, armazenamento, rede,memória e CPU, o que torna o Gerenciamento de recursos uma tarefa crítica nesta tecnologia.
Usuários de Big Data podem solicitar vários processamentos, cada qual com distintos requisitos.
O Gerenciador de recursos age como um "scheduler", que "agenda" e prioriza solicitações, segundo os requisitos. Age, essencialmente, como um árbitro, que gerencia e aloca recursos disponíveis.
Nas primeiras versões do HADOOP, não havia um Gerenciador de Recursos. O HADOOP consistia em duas partes principais:
Com a evolução das soluções, onde processamento real time e near real time passaram a predominar, tornou-se essencial contar com um executor de aplicativos e um gerenciador de recursos para agendar e executar todos os tipos de aplicativos, incluindo MapReduce, em tempo real.
Características do Apache YARN
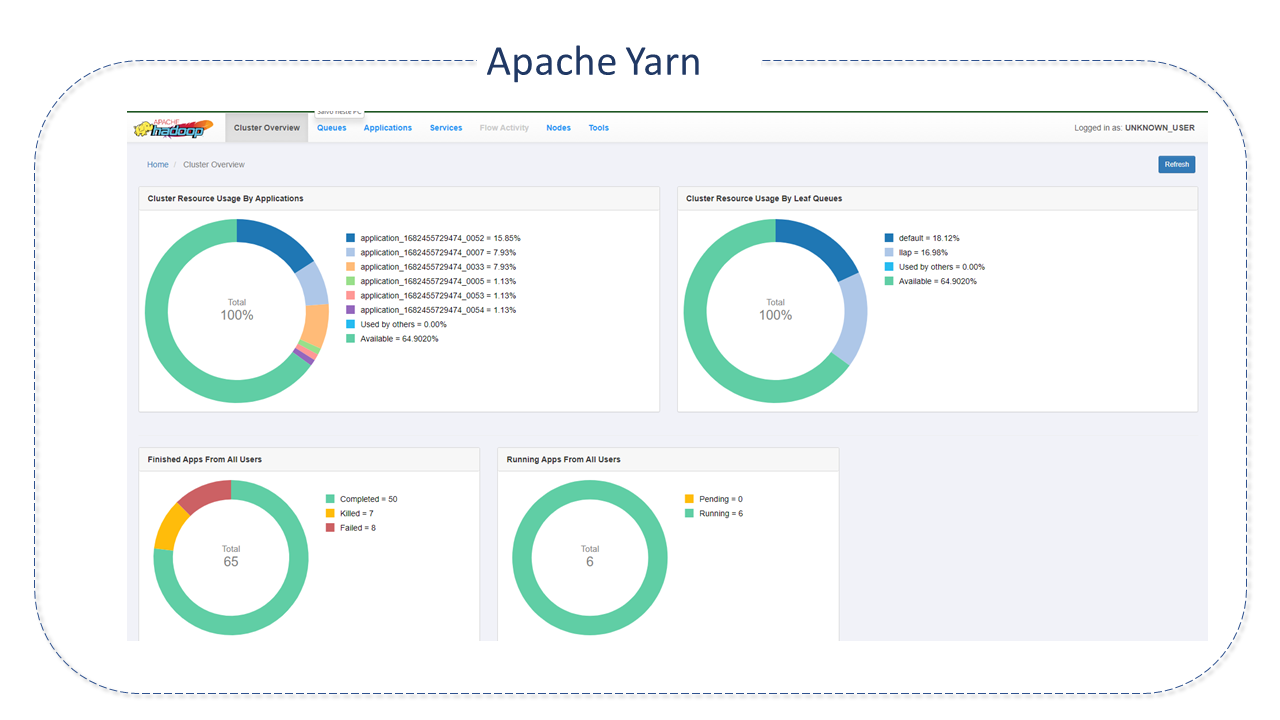
O Yet Another Resource Negotiator (YARN) foi introduzido no Apache HADOOP 2.0 para atender estas necessidades e, ainda, solucionar problemas de escalabilidade e capacidade de gerenciamento que existiam na versão anterior do Hadoop. Tem a responsabilidade de auxiliar no gerenciamento de recursos entre os Clusters, assumindo, ainda, a responsabilidade pelo scheduling e alocação de recursos para o Sistema HADOOP, tarefas realizadas até então pelo JobTracker do MapReduce.
Hoje, o Apache YARN ganhou popularidade devido às vantagens que oferece em escalabilidade e flexibilidade e, ainda, pela sua versatilidade e baixo custo, pois pode ser utilizado em hardwares comuns. É implementado com sucesso no eBay, Facebook, Spotify, Xing, Yahoo, etc.
Dentre suas principais características, destacamos:
-
Múltilocação: Um conjunto abrangente de limites é fornecido para evitar que um único aplicativo, usuário ou fila monopolize os recursos da fila ou do Cluster, evitando, assim, sobrecarga do Cluster.
-
Docker for YARN: O Linux Container Executor (LCE) permite que o YARN NodeManager inicie containers YARN para execução diretamente na máquina host ou dentro de containers Docker.
Os containers Docker fornecem um ambiente de execução personalizado no qual o código do aplicativo é executado, isolado do ambiente de execução do NodeManager e de outros aplicativos.
O Docker for YARN fornece consistência (todo container YARN terá o mesmo ambiente de software) e isolamento (não há interferência com o que está instalado na máquina física).
-
Escalabilidade: A escalabilidade do Apache YARN é conhecida por escalar para milhares de nós. É determinada pelo Resource Manager e é proporcional ao número de nós, aplicações ativas, containers ativos e frequência de heartbeat (de nós e aplicativos).
-
Alta disponibilidade para componentes: A tolerância a falhas é um principio básico do Apache YARN. Essa responsabilidade é delegada ao Resource Manager(falhas de NodeManager e Application Master) e ApplicationMaster (falhas de container).
-
Modelo de Recursos flexíveis: No Apache YARN, uma solicitação de recursos é definida em termos de memória, CPU, localidade, etc, resultando em uma definição genérica. A capacidade dos nós NodeManager e Workers é calculada baseado na memória instalada e nos núcleos da CPU.
-
Múltiplos algoritmos de processamento de dados: o Apache YARN foi desenvolvido para executar em ampla varidade de processamento de dados. É uma estrutura para gerenciamento de recursos genéricos e permite execução de vários algoritmos sobre os dados.
-
Agregação de log e localização de recursos: Para gerenciar log de usuários o Apache YARN utiliza a agregação de logs. Assim que o aplicativo é concluído, o serviço NodeManager agrega os logs de usuários relacionados a um aplicativo e grava os logs agregados em um único arquivo de log no HDFS.
-
Recursos eficientes e confiáveis: o Apache YARN fornece uma estrutura genérica de gerenciamento de recursos com suporte à análise de dados por meio de vários algoritmos de processamento de dados.
Arquitetura do Apache YARN
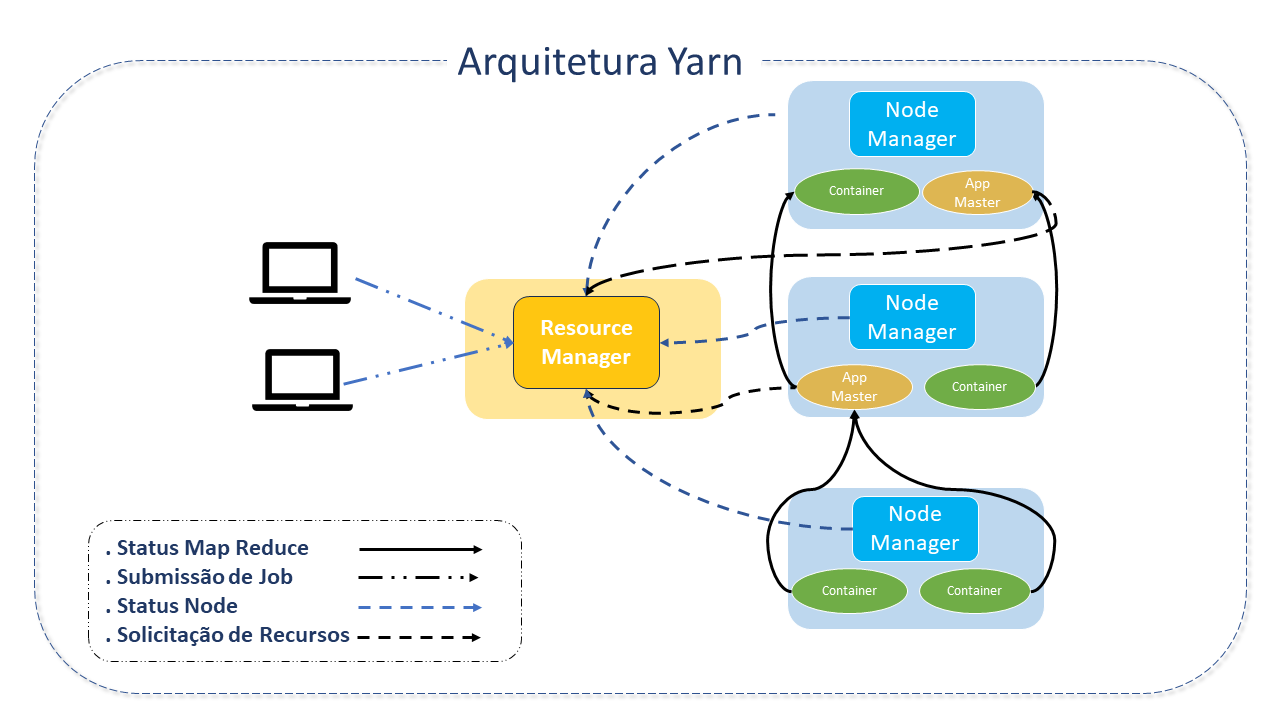
o Apache YARN consiste em três componentes:
-
Resource Manager: É o nó master, responsável pelo gerenciamento de recursos no Cluster. É a "autoridade maior" que arbitra recursos entre todos os aplicativos no sistema.
Existe um Resource Manager por Cluster e ele "conhece" a localização e recursos de todos os escravos, o que inclui informações como GPU, CPU e memória necessária para execução de aplicativos. O Resource Manager age como um proxy entre o cliente e todos os outros nós.
Possui dois componentes principais:
-
Scheduler: Responsável pela alocação de recursos para os diversos aplicativos em execução.
O Scheduler não realiza monitoramento ou acompanhamento do status do aplicativo e não oferece garantias sobre reinicialização de tarefas comprometidas por falha de aplicativo ou hardware. Sua função é executada com base nos requisitos de recursos dos aplicativos, e na noção abstrata de container de recursos_, que incorpora elementos como memória, cpu, disco, rede, etc.
Containers são parcelas de recursos (CPU, memória, etc) de uma máquina do Cluster que pode ser reservada para a execução de uma aplicação, sendo esta aplicação HADOOP Map Reduce ou não. A partir da versão 2.0 do HADOOP, a coordenação de um Job não ocorre no nó Master, mas em um container instanciado em uma máquina worker, a qual possui geralmente dois componentes (podendo possuir três, no caso da instância de gerenciamento da aplicação):o Node Manager, Application Master e DataNode.
O Scheduler possui uma política "plugável" responsável pelo particionamento dos recursos do Cluster entre as várias filas, aplicativos, etc.
O Scheduler recebe solicitações do Application Masters com requisições de recursos e executa sua função de agendamento. A estratégia de agendamento é configurável e pode ser escolhida com base na necessidade de cada aplicativo.
Existem , por padrão, três agendadores no Apache YARN:
-
Scheduler FIFO: Usa a estratégia simples primeiro a entrar, primeiro a "servir". A memória será alocada baseado na sequência de tempo de solicitação, sendo que o primeiro aplicativo da fila recebe a memória necessária, depois o segundo e assim por diante. Caso a memória não esteja disponível, os aplicativos aguardarão a disponibilidade. Nesta opção, o Apache YARN cria uma fila de solicitações, adicionando aplicativos a ela e os iniciando, um a um.
-
Scheduler de Capacidade: Garante que o usuário obtenha a quantidade mínima de recursos. Ajuda a compartihar os recursos do Cluster de maneira econômica entre diferentes usuários. Em outras palavras, os recursos do Cluster são compartilhados entre os vários grupos de usuários. Trabalha com o conceito de filas. Um Cluster é dividido em partições (filas) e cada fila recebe uma porcentagem de recursos.
-
Scheduler Fair Todos os aplicativos obtém uma quantidade quase idêntica dos recursos disponíveis. Quando o primeiro aplicativo é enviado ao Apache YARN, este atribuirá todos os recursos disponiveis a ele. Se um novo aplicativo é enviado, o Apache YARN começa a alocar recursos para ele até que ambos tenham quase a mesma quantidade. Ao contrário dos anteriores, o Scheduler Fair evita que aplicativos fiquem sem recursos e garante que todos os aplicativos da fila obtenham a memória necessária para execução.
-
-
Application Manager: A tarefa principal do Application Manager é aceitar submissões de jobs, negociar o primeiro container para execução do Application Master específico do aplicativo e prover o serviço para reestartar o container ApplicationMaster quando houver falha. .
-
-
NodeManager: Responsável por iniciar e monitorar containers de jobs. É o framework da máquina responsável pelos containers, monitorando seu uso de recursos e reportando-se ao ResourceManager/Scheduler.
-
Containers: O Hadoop 2.0 melhorou o seu processamento paralelo com a adição de containers, que são uma noção abstrata, que suporta a multilocação em um nó de dados.
Esta foi a forma que Hadoop encontrou para definir requisitos de memória, CPU, rede: dividindo os recursos no servidor de dados em containers. Assim, o servidor de dados pode hospedar múltiplos jobs, hospedando múltiplos containers.
O Resource Manager é responsável por "schedular" recursos alocando containers.
Isto é feito com base em um algoritmo, a partir da "entrada" fornecida pelo cliente, a capacidade do Cluster e as filas e priorizações de recursos no Cluster.
Uma regra geral é iniciar o container no mesmo nó que os dados requeridos pelo job para facilitar a sua localização.
-
-
Application Master: É uma biblioteca específica do framework, encarregada de negociar recursos do ResourceManager e trabalhar com o(s) NodeManager(s) para executar e monitorar jobs. Ao receber um aplicativo, o ResourceManager iniciará o ApplicationMaster em um container alocado, que se comunicará com o Cluster YARN para lidar com a execução do aplicativo. As principais tarefas do ApplicationMaster são:
-
Comunicar-se com o ResourceManager para negociar e alocar recursos para futuros containers.
-
Após a alocação do container, comunicar-se com os NodeManagers para que iniciem os containers do aplicativo.
O Resource Manager e o Node Manager formam o framework da computação de dados.
-
A idéia principal do Apache YARN é a de dividir as funcionalidades de gerenciamento de recursos e scheduling/monitoramento de jobs em daemons separados, existindo, assim, um ResourceManager(RM) global e um ApplicationMaster(AM) por aplicativo. Um aplicativo é um job único ou um DAG(Directed acyclic graph) de jobs.
|
Com a implementação do Apache YARN na versão 2.0 do HADOOP, o MapReduce mantém a compatibilidade com a versão estável anterior (HADOOP versão 1.x). Todas as tarefas do MapReduce continuam sendo executadas no Apache YARN. |
Recursos suportados pelo Apache YARN
-
Modelo de Recursos Extensível Apache YARN oferece suporte a um modelo de recursos extensível. Por padrão, rastreia CPU e memória para todos os nós, aplicativos e filas, mas a definição de recursos pode ser estendida para incluir recursos "contabilizáveis" (recursos consumidos enquanto o container está em execução, mas liberados posteriormente, como memória e CPU), o que significa dizer que a definição de recursos pode ser estendida em seus valores default (como CPU e memória) para qualquer tipo de recurso que possa ser consumido quando a tarefa "executa" no container. Além disso, YARN oferece suporte ao uso de "perfis de recursos", permitindo que um usuário especifique várias solicitações de recursos por meio de um único perfil, semelhante aos tipos de instância Amazon Web Services Elastic Compute Cluster. É uma forma fácil de requisitar recursos a partir de um único perfil e um meio de administradores regularem o consumo.
-
Reserva de Recursos O Apache YARN oferece suporte à reserva de recursos por meio do ReservationSystem, um componente que permite ao usuário especificar um perfil de recursos ao longo do tempo e restrições temporais (por exemplo prazos) e reservar recursos para garantir a execução previsivel de jobs importantes. O ReservationSystem rastreia recursos extras, executa o controle de admissão para reservas e instrui dinamicamente o Scheduler subjacente para garantir que a reserva seja atendida.
-
Federation O Apache YARN oferece suporte à Federation por meio do recurso YARN Federation, que permite conectar de forma transparente vários (sub)Clusters de YARN e fazê_los aparecer como um único Cluster massivo. Pode ser usado para alcançar uma escala maior e/ou permitir que vários Clusters independentes sejam usados juntos para trabalhos muito grandes ou para inquilinos que tenham capacidade entre todos eles. A abordagem é dividir um grande Cluster em unidades menores, chamadas sub-clusters. Cada unidade possui seu próprio YARN Resource Manager e compute-node(Node_manager).
-
REST APIs O Apache YARN oferece APIs RESTful para permitir que aplicativos cliente acessem diferentes dados de métricas como Cluster metrics, schedulers, nós, estado dos aplicativos, prioridades, gerenciadores de recursos, etc. Provê, ainda, informações e estatísticas sobre a instância NameNode e estatísticas sobre aplicativos e containers. Estes serviços podem ser usados por aplicativos de monitoramento remoto. Atualmente, os seguintes componentes suportam informações RESTful:
-
Resource Manager
-
Application Master
-
History Server
-
Node Manager.
-
-
Alta Disponibilidade Uma falha no gerenciador de recursos provocará uma falha no Apache YARN e, portanto, é importante implementar a alta disponibilidade do Resource Manager. O Recurso de Alta disponibilidade (HA) adiciona redundância para remover pontos de falha.
-
Arquitetura do Resource Manager HA: A alta disponibilidade do Resource Manager funciona na arquitetura Active/Standby. O _Resource Manager Standby assume o controle ao receber o sinal do ZooKeeper.
-
Recursos do Resource Manager HA:
-
Armazenamento do Resource Manager state: Em caso de falha, o Resource Manager Standby recarregará o estado de armazenamento e iniciará a partir do último ponto de execução. As informações do Cluster serão reconstruídas quando o Nodemanager enviar um heartbeat para o novo Resource Manager.
-
Resource Manager restart and failover: O Resource Manager carrega o estado do aplicativo interno a partir do armazenamento de estado do Resource Manager. O Scheduler do Resource Manager reconstrói seu estado de cluster information quando o NodeManager envia o heartbeat. O processo de checkpoint evita reinicialização de tarefas já concluidas.
-
Failover and fencing: Em Clusters YARN de alta disponibilidade pode haver dois ou mais Resource Manager em modo ativo/Standby. É possível acontecer o split brain, quando dois Resource Manager se assumem como ativos. Se isto acontecer, ambos controlarão recursos do Clusters e manipularão solicitações dos clientes. O failover fencing permite que o Resource Manager ativo restrinja a operação dos outros. O armazenamento de estado discutido anteriormente fornece o ZKResourceManager StateStore baseado no Zookeeper, que permite apenas um único Resource Manager gravando por vez.
-
Leader Elector: Baseado no Zookeeper ActiveStandbyElector , é usado para eleger um novo Resource Manager ativo e implementar fencing internamente. Quando um Resource Manager fica inativo, um novo Resource Manager é eleito pelo ActiveStandbyElector e assumirá o controle. Se o Failover automático não estiver ativado, o administrador deverá realizar a transição do RM ativo para o modo de espera e vice versa manualmente.
-
-
-
Nodelabels Trata-se de um marcador para cada máquina, para que máquinas com o mesmo nome de etiqueta possam ser usadas em jobs específicos.
Os nós com recursos de processamento mais poderosos podem ser rotulados com o mesmo nome e, em seguida , os jobs que requerem mais máquina podem usar o mesmo rótulo durante o envio. Cada nó pode ter apenas um rótulo atribuído a ele, o que significa que o Cluster terá um conjunto desarticulado de nós. Podemos dizer que um cluster é particionado com base nos rótulos dos nós.
O Apache YARN também fornece recursos para definir a configuração de nivel de fila, que define quanto de uma partição ou fila pode ser usado. Existem dois tipos de rótulos de nó disponiveis até o momento:
-
Exclusivo: garante que seja a única fila permitida para acesar o rótulo de nó. o aplicativo enviado pela fila com um rótulo exclusivo terá acesso exclusivo à partção para que nenhuma outra fila poss obter recursos.
-
Nâo exclusivo: permite o compartilhamento de recursos ociosos com outros aplicativos. As filas recebem rótulos de nó e os aplicativos enviados a essas filas terão prioridade sobre os respectivos rótulos de nó. Se não houver aplicativo ou job numa fila para esses rótulos, os recursos serão compartilhados entre outros rótulos de nó não exclusivos. Se a fila com o rótulo de nó enviar um aplicativo ou job entre o processamento, os recursos serão retirados da tarefas em execução e atribuidos às filas associadas com base na prioridade.
-
-
Node Attributes São uma forma de descrever atributos de um nó sem garantia de recursos. Pode ser usado por aplicações para selecionar os nós corretos para que seu container seja colocado com base na expressão de vários desses atributos.
-
Proxy Web Application Sua principal finalidade é reduzir a possibilidade de ataques baseados na Web por meio do Apache YARN.
-
Timeline Server e Timeline Server 2 O Timeline Server é o responsável pelo armazenamento e recuperação de informações atuais e históricas da aplicação. Possui, basicamente, duas responsabilidades:
-
Persistência de Informações específicas do aplicativo:
-
Informações genéricas persistentes sobre aplicativos concluídos.
O Timeline Server 2 é a próxima grande iteração do Timeline Server, criada para corrigir questões de escalabilidade e melhorar a usabilidade do Timeline Server 1.
-
Linguagem do Apache YARN
O Apache YARN foi desenvolvido em Javascript, Shell, PHP, TypeScript e HTML.
Fonte(s): Hadoop.apache.org