Apache Kafka
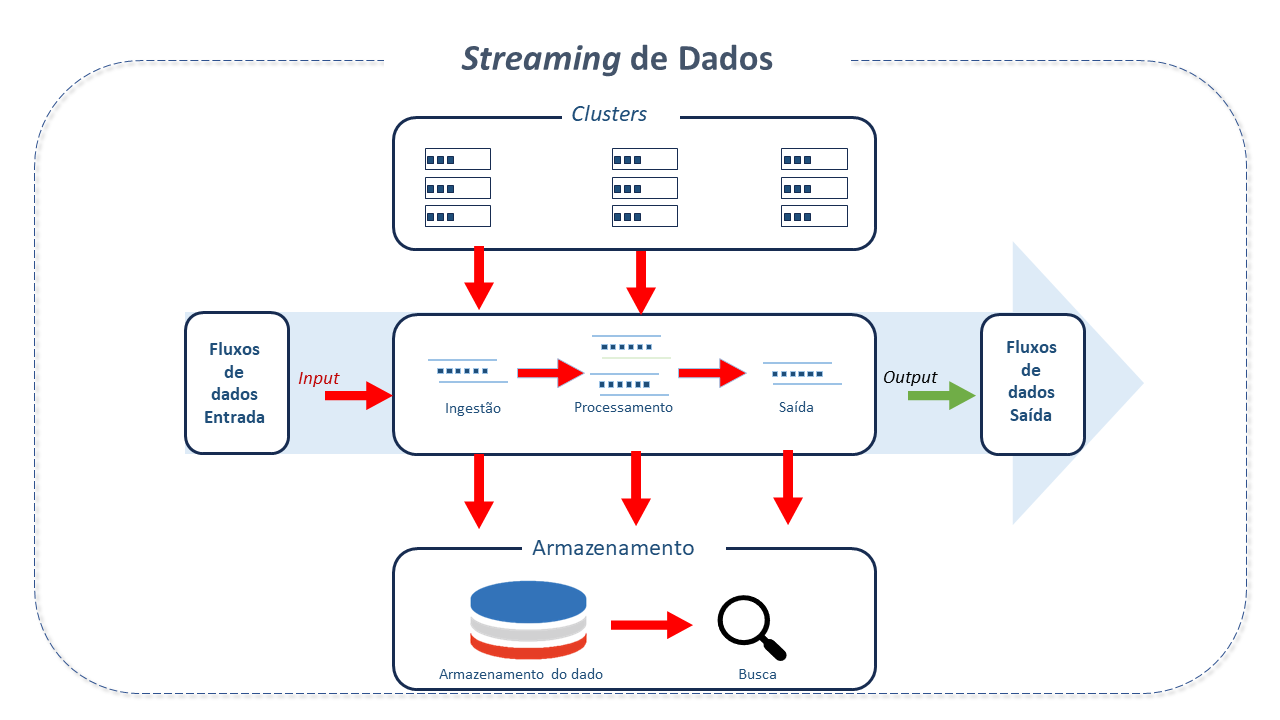
Streaming de Dados
Métodos legados de processamento em lote exigem que os dados sejam coletados em forma de lote antes de serem processados, armazenados ou analisados.
Por outro lado, dados de "streaming" fluem continuamente, e podem ser tratados imediatamente, permitindo decisões dinâmicas, contextuais e em tempo real, capacitando, assim, as empresas a explorar todo o valor e potencial de seus dados e aplicativos.
Streaming de Dados é a captura de fluxos de dados(elementos de dados ordenados no tempo) em tempo real a partir das mais diversas fontes de eventos como databases, sensores, mobiles, nuvem e aplicativos de software.
Os fluxos(streams) capturados podem ser tratados em tempo real ou retrospectivamente e roteados para diferentes tecnologias, conforme necessário. Podem ser armazenados para posterior recuperação, manipulação ou processamento.
O Streaming de dados envolve tecnologias que surgiram nos últimos anos. Um sistema de análise de dados em tempo real, por exemplo, está preparado para alta geração de dados, com base em eventos que rapidamente se espalham pela rede.
Características do Apache Kafka
O Kafka é a plataforma de streaming de eventos mais comumente utilizada. Kafka é usado para coletar, processar, armazenar e integrar dados em escala. Possui numerosos casos de uso, incluindo registro distribuído, processamento de fluxos, integração de dados e publicação/subscrição de mensagens.
Originalmente criada como solução para um software do Linkedin, que coletava dados de atividades do usuáríos no portal de dados e os usava para mostrar num portal web, a plataforma foi construída como um sistema distribuido, tolerante a falhas, combinando três funcionalidades:
-
Publicação (write) e Subscrição (read) de streams de eventos, incluindo importações e exportações contínuas do dado a partir de outro sistema.
-
Armazenamento de streams de eventos de forma duradoura e confiável pelo tempo necessário.
-
Processamento de streams de eventos a medida que ocorrem ou de forma retrospectiva.
Kafka foi construido com as seguintes premissas:
-
Persistência de dados para suportar uma variedade de cenarios de consumo e tratamento de falhas.
-
Máxima taxa de transferência "end-to-end" com componentes de baixa latência.
-
Gerenciamento de diversos formatos e tipos de dados usando formatos de dados binários.
Kafka é comumente usado em sua arquitetura de processamento stream. Com sua semântica reliable message delivery(entrega confiável de mensagens), auxilia no consumo de altas taxas de eventos. Provê, ainda, recursos de replay de mensagens para diferentes tipos de consumers.
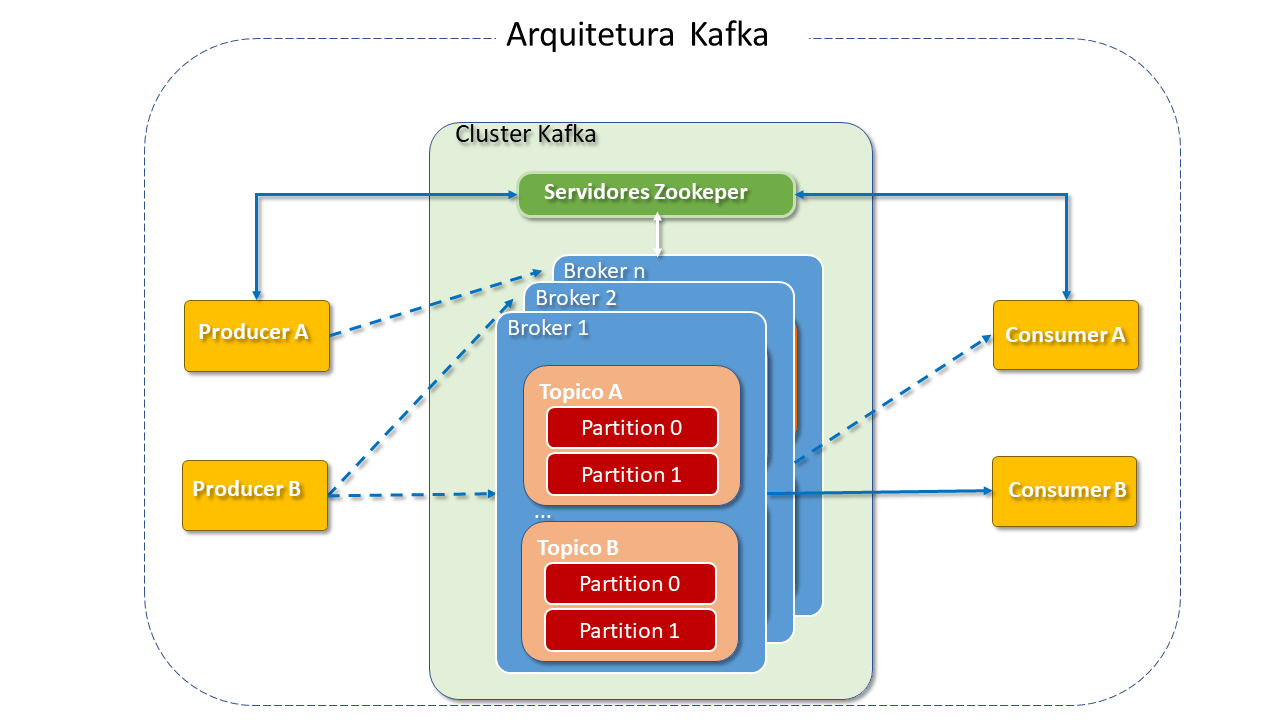
Arquitetura do Apache Kafka
-
Sistema de comunicação: Kafka é um sistema distribuído que consiste em servidores e clientes se comunicando por meio de protocolo de rede TCP de alta performance.
Pode ser implementado em hardware bare-metal(servidor físico), máquinas virtuais(computadores de software com a mesma funcionalidade que os computadores físicos) e containers assim como no ambiente em nuvem.
O Cluster Kafka é altamente escalável e tolerante a falhas. Seu modelo de comunicação utiliza o sistema WAL(Write-ahead log) no qual toda mensagem é publicada em arquivos log antes de disponibilizada para aplicações Consumer para que Subscribers e Consumers possam ler no momento apropriado.
O Kafka simplifica a comunicação entre sistemas agindo como um hub centralizado de comunicação. O padrão de comunicação implementado é o publish-subscribe, cuja principal diferença em relação ao modelo cliente-servidor é a comunicação não bidirecional, ou seja, os streams fluem em uma única direção.
Projetado como uma biblioteca de cliente simples e leve, pode ser facilmente incorporado a qualquer aplicativo Java e integrado a qualquer pacote.
Não possui dependências externas na camada de mensagens. A camada de mensagens particiona os dados para armazená-los e transportá-los. Este particionamento é que permite a localidade, escalabilidade, alto desempenho e tolerância a falhas.
-
Os principais componentes do Kafka são:
-
Clientes Os clientes viabilizam a escrita de microsserviços e aplicações distribuidas que lêem, gravam e processam streams de eventos em paralelo, em escala e de uma forma tolerante a falhas, mesmo diante de problemas de máquina ou rede. Kafka traz alguns clientes incluídos, os quais são aumentados por vários outros entregues pela comunidade: Clientes estão disponíveis para Java e Scala, incluindo a biblioteca de alto nível Kafka Streams, para Go, Python, C/C++ e muitas outras linguagens e APIs REST.
-
Servidores: Kafka é executado como um Cluster de um ou mais servidores que pode estender-se a múltiplos Datacenters ou Cloud-Regions. Alguns destes servidores, denominados brokers, formam a camada de armazenamento.
-
Brokers: Um Cluster Kafka tipico consiste de multiplos brokers. Isto ajuda no balanceamento de carga nas leituras e gravações no cluster. Cada broker é steteless(não permanece dedicado à conexão) e conta com o Zookeeper para manter seu estado.
-
-
Topics: (tópicos) são a forma de organização dos eventos. Sua função é similar às tabelas de um Database (agrupam dados relacionados) sem, entretanto, impor um esquema particular. Armazenam as mensagens em dados raw bytes (bytes não codificados), o que os torna muito flexíveis para tratamento, suportando dados homôgeneos e heterogêneos. São categorizados em partitions. Fisicamente, cada tópico é distribuído por diferentes brokers , os quais hospedam uma ou duas partitions para cada tópico.
-
Partitions (partições): As partições armazenam mensagens na sequência em que chegam. Eventos com a mesma chave(id) são gravados na mesma partição.
O número de partições de um tópico é configurável, assim como o seu tamanho. Contar com mais partições em um tópico geralmente traduz-se em mais paralelismo e throughput .
Os pipelines Kafka devem ter um número uniforme de partições por broker e todos os topicos em cada máquina.
Em cada partição, um dos brokers é o lider e zero ou mais são seguidores. Os lideres gerenciam as requisições de leitura ou gravação para suas respectivas partições. Os seguidores replicam o lider mas não interferem no seu trabalho, atuando, como um "backup". Um deles será escolhido para substituí-lo em caso da falha. Cada Cluster Kafka pode ser simultaneamente um lider de alguma partição de topico, ou seguidor em outras. Assim, a carga em qualquer servidor é balanceada igualmente.
A eleição do lider é feita com ajuda do Zookeeper, que gerencia e coordena os brokers e consumers . O Zookeeper acompanha qualquer adição ou falha de broker no Cluster, notificando seu estado aos producers ou consumers das filas Kafka. Também auxilia producers e consumers na coordenação dos brokers ativos, registrando quais são os lideres para qual partição de tópico e passando esta informação para producers e consumers.
-
Producers são as aplicações responsáveis por enviar dados para a partição do tópico para o qual está produzindo dados. O Producer não grava dados na partição. Apenas cria solicitações de gravação para mensagens e as envia para o broker líder. Dependendo da configuração, o producer aguarda por uma confirmação de mensagens.
-
Consumers são aplicações ou processos que subscrevem (lêem e processam) os eventos. Buscam mensagens a partir dos arquivos de log pertencentes a uma partição do tópico. São eles que distribuem o trabalho em múltiplos processos.
Kafka-UI
O Kafka-UI é uma interface web versátil, rápida e leve para gerenciamento e monitoramento de clusters Kafka.
Trata-se de uma ferramenta open source que auxilia na observação dos fluxos de dados, detecção e solução de problemas, gestão e análise de desempenho. Seu dashboard permite o rastreamento das principais métricas de Brokers, Tópicos, Partições, e Produção e Cosumo de Eventos.
Principais Recursos do Kafka-UI
-
Exploração de mensagens - navegue pelas mensagens de tópicos usando com Avro, Protobuf, JSON ou codificação de texto simples;
-
Visualização de grupos de consumidores — visualização, por partição, de offset estacionados (parked offsets) e atrasos
-
Assistente de configuração — configuração de clusters Kafka através de uma interface web (UI)
-
Gerenciamento de vários clusters — monitoramento e gerenciamento de todos os clusters em um só lugar
-
Monitoramento de desempenho com painel de métricas - rastreamento e exibição das principais métricas do Kafka
-
Visualização de Kafka Brokers - visualização de atribuições de tópicos e partições, e status do controlador
-
Visualização de tópicos do Kafka - visualização de contadores, status da replicação e configurações personalizadas
-
Configuração dinâmica de tópicos — criação e configuração de novos tópicos com configuração dinâmica
-
Controle de acesso baseado em função - gerenciamento de permissões para acessar a UI com precisão granular
-
Mascaramento de dados - ofuscamento de dados confidenciais de mensagens de tópicos
Recursos do Apache Kafka
-
Ferramentas de código aberto para grandes ecossistemas: Vasta gama de ferramentas orientadas pela comunidade.
-
APIs Kafka: Adicionalmente às ferramentas de linha de comando, Apache Kafka disponibiliza cinco APIS para Java e Scala nas tarefas de gerenciamento e administração:
-
API admin: para gerenciar e inspecionar topicos, brokers etc.
-
Producer-API: para publicação(gravação) de fluxos de eventos em um ou mais topicos.
-
Consumer-API: para subscrição(leitura) de um ou mais topicos e processamento do fluxo de eventos produzido.
-
API Kafka Streams :: Uma vez o dado armazenado como evento no Kafka, pode ser processado com a biblioteca cliente Kafka Streams para Java/Scala, que permite a implementação de aplicações e microsserviços real- time de missão critica, onde a(s) entrada(s) e/ou saída(s) são armazenadas nos tópicos Kafka. O Kafka Streams combina a simplicidade de escrever e implantar aplicativos Java e Scala no lado cliente com os benefícios da tecnologia do Cluster no lado do servidor, tornando esses aplicativos altamente escaláveis, elásticos, tolerantes a falhas e distribuídos.
-
Kafka Connect API: para construção e execução de conectores de importação/exportação de dados que consomem ou produzem fluxos de eventos.
-
-
Kafka é frequentemente usado para Monitoramento Operacional, que envolve estatísticas de aplicativos distribuídos para produção de fontes centralizadas de dados operacionais.
-
Kafka pode ser usado como Solução de Agregação de Logs, coletando arquivos de log físicos de servidores e colocando-os em um local centralizado (como o HDFS) para processamento.
Em comparação aos sistemas "centrados" em log como Flume e Scribe, oferece desempenho similar, com garantias mais fortes de durabilidade, devido à replicação e menor latência de ponta a ponta .
-
Kafka pode ser utilizada em Event Sourcing, armazenando alterações no estado do aplicativo como uma sequência de eventos que podem não apenas ser consultados mas também ter seu log usado para reconstruçao de estados passados e mudanças retroativas).
-
Kafka pode servir como um commit-log externo para sistemas distribuídos. O log ajuda a replicar dados entre os nós e atua como mecanismo de ressincronização para que os nós com falha restaurem seus dados. O recurso de Compactação de Log do Kafka suporta este uso. Neste sentido, o Kafka é similar ao projeto Apache Bookeeper.
-
Replicação. O Apache Kafka replica o log para cada partição de tópico por um número configurável de servidores (este fator de replicação pode ser definido em bases topyc-por-topico). Isto auxilia no failover automático para estas replicas quando o servidor do Cluster falha de modo que as mensagens permanecem disponiveis na presença de falhas.
Quotas. O Cluster Kafka tem a capacidade de "impor" cotas em solicitações para controlar os recursos do agente usados pelo cliente. Dois tipos de cota de cliente podem ser aplicados para cada grupo de clientes que compartilha uma cota:
-
As cotas de largura de banda da rede : que definem os limites da taxa de bytes (a partir de 0,9).
-
As cotas de taxa de solicitação: que definem os limites de utilização da CPU como um percentual da rede e dos threads de E/S (a partir de 0,11).
Boas Práticas para Apache Kafka
-
Validação de dados: Durante a gravação de um sistema producer, é essencial a realização de testes de validação dos dados que serão gravados no Cluster (valores não nulos para campos chave por exemplo).
-
Exceções: Durante a gravação de um Producer ou Consumer é importante que sejam definidas classes de exceção e as ações a serem tomadas em conformidade com os requisitos dos negócios. Isto ajuda não somente no debug, mas mitiga riscos. (alertas para situações definidas, por exemplo).
-
Numero de retries(novas tentativas): Em geral existem dois tipos de erro na aplicação producer: erros "solucionáveis" com nova tentativa (como network timeouts e "lider não disponivel") e erros que precisam ser tratados pelo producer.
Configurar o número de retries ajuda a mitigar riscos relacionados à perda de mensagens devido a erros do Cluster kafka ou rede.
-
Número de bootstrap URLS: É importante ter mais que um broker listado no bootstrap broker configuration, no programa producer. Isto auxilia producers a ajustar-se quando houver falhas por causa de indisponibilidade de um broker.
Os producers tentam usar todos os brokers listados até encontrar um com o qual possa se conectar.
O ideal é listar todos os brokers no Cluster kafka para acomodar todas as falhas de conexão. Entretanto, em caso de Clusters muito grandes, pode-se escolher um menor número que possa representar significativamente os brokers do Cluster.
Atente que o número de retries pode afetar a latência "end-to-end" e causar duplicação de mensagens na fila Kafka.
-
Novas partições em topicos existentes: Novas partições em topicos existentes devem ser evitadas quando usando particionamento baseado em chaves para distribuição das mensagens.
Adicionar novas partições pode mudar o hash calculado para cada chave pois considera o número de partições como uma de suas entradas.
Acabariam existindo partições diferentes para uma mesma chave.
-
Rebalanceamentos: Sempre que um novo consumidor ingressa em grupos de consumers ou um antigo fica inativo, um reequilíbrio de partições no Cluster é acionado.
Sempre que um consumer estiver perdendo a propriedade de sua partição, é importante o Commit dos offsets do último evento que recebeu do Kafka.
-
Commit offsets na hora certa: No caso de commit offset for messages é necessário fazê-lo no momento correto. Um aplicativo em processamento batch toma mais tempo para completar o processamento.
Não é uma regra, mas se o processamento durar mais que um minuto, é razoável realizar o commit the offset em intervalos regulares para evitar processamento duplicado de dados no caso de falha da aplicação.
Para aplicações mais criticas onde esta duplicação possa causar problemas financeiros, o tempo de commit offset deve ser o menor possível se throughput não for um fator importante.
Outras recomendações
O blog.kafka.br disponibiliza uma série de discussões e recomendações que valem a pena ser conhecidas.