Apache HDFS
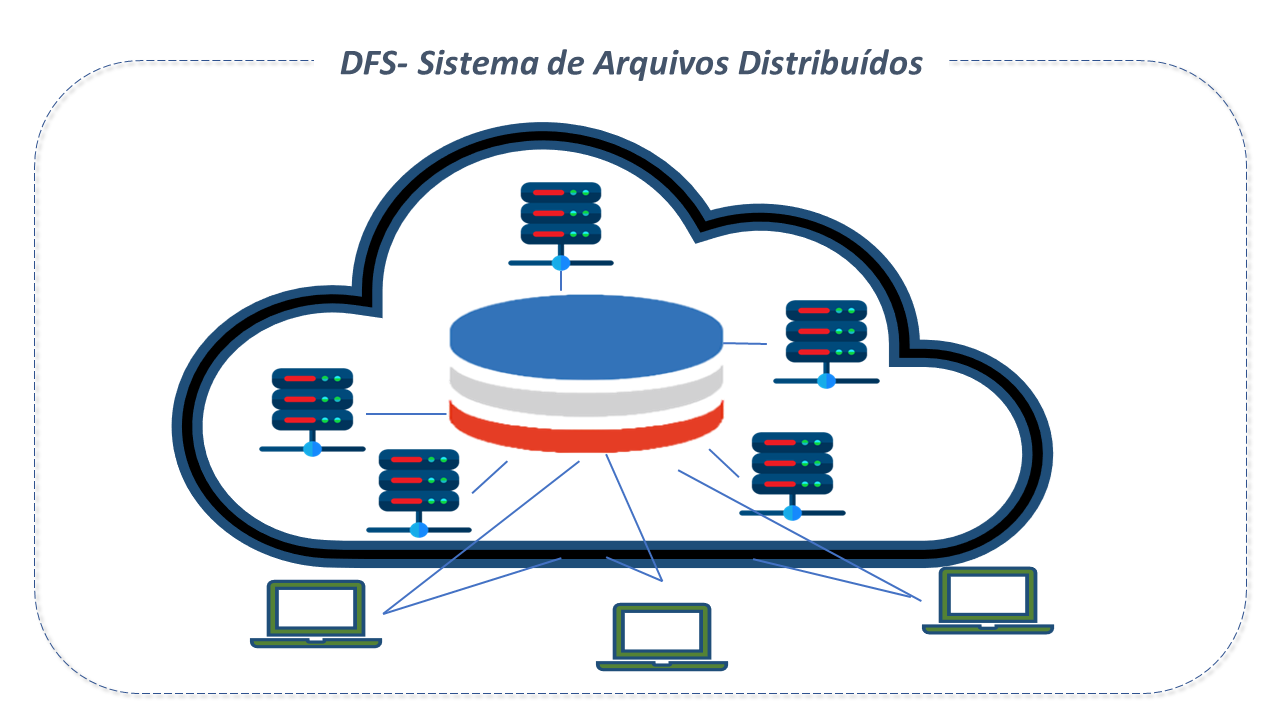
Sistema de Arquivos Distribuídos
Um sistema de arquivos distriuídos(DFS) é um sistema de arquivos que habilita o acesso, pelo cliente, a dados armazenados em múltiplos servidores, por meio de uma rede de computadores, como se estivesse acessando um armazenamento local.
Os arquivos são distribuídos em múltiplos servidores de armazenamento e em múltiplas localidades, o que permite o compartilhamento de dados e de recursos.
O DFS agrupa vários nós de armazenamento e neles distribui logicamente conjuntos de dados, cada um com sua própria configuração. Os dados podem residir em vários tipos de dispositivos, como unidades de estado sólido e discos rigidos.
Os dados são replicados, o que viabiliza a redundância para alcançar disponibilidade.
Para expandir a infraestrutura, a organização precisa apenas adicionar mais nós ao sistema.
Características do Apache HDFS
O HDFS (Hadoop Distributed File System) é o principal sistema de armazenamento utilizado pelo HADOOP.
Trata-se de um sistema de arquivos distribuídos extremamente confiável, desenhado para execução em hardware comum que trabalha com rápida transferência de dados entre nós.
O HDFS foi originalmente construído como infraestrutura para um projeto de mecanismo de pesquisa da Web Apache Nutch e hoje faz parte do Core do projeto Apache Hadoop. Possui muitas semelhanças com os sistemas de arquivo distribuídos existentes. Entretanto, suas diferenças são significativas:
-
é altamente tolerante a falhas
-
foi projetado para hardware de baixo custo
-
oferece alta taxa de transferência no acesso aos dados
-
é adequado para tratamento de grandes conjuntos de dados.
Destacamos abaixo algumas de suas principais características:
-
Tolerância a falhas: Uma instância do HDFS pode consistir em milhares de servidores armazenando parte dos dados de um sistema de arquivos, o que envolve um grande número de componentes. Isto aumenta a probabilidade de falhas pois, em algum momento, um ou mais componentes poderá estar não funcional. Por esta razão a tolerância a falhas é a premissa principal do HDFS. A detecção de falhas e a recuperação rápida e automática é a sua meta arquitetônica central.
-
Acesso Streaming de dados: O padrão de acesso aos dados é o streaming de dados, ou seja, dados gerados em tempo real e com fluxo contínuo.
-
Suporte a grandes conjuntos de dados: Um arquivo comum no HDFS pode alcançar, tranquilamente, terabytes em tamanho, pois aplicativos que executam no HDFS tratam grandes conjuntos de dados. O HDFS foi ajustado para fornecer elevada largura de banda agregada , escalar para centenas de nós em um único Cluster e suportar dezenas de milhões de arquivos em uma única instância.
-
Modelo de Coerência Simples: O HDFS foi projetado com base no princípio write once read many(gravação única, múltiplas leituras). Depois que os dados são gravados, não há suporte para atualizações em um ponto arbitrário ou alterações exceto em appends e truncates( anexar o conteúdo ao final dos arquivos ou excluir todas as linhas). É essa premissa que simplifica os problemas de coerência de dados e garante alto throughput no acesso a dados. Um aplicativo MapReduce ou um web crawler(rastreador de sites) se encaixam perfeitamente neste modelo.
-
Interfaces que aproximam os aplicativos dos dados: Uma computação solicitada por um aplicativo é sempre mais eficiente se executada próxima aos dados com os quais opera. Principalmente quando o tamanho do conjunto de dados é grande, pois minimiza o congestionamento da rede e aumenta a taxa de transferência geral do sistema. O HDFS oferece interfaces para que os aplicativos se aproximem dos dados.
-
Portabilidade entre plataformas heterogêneas de hardware e software: O HDFS foi projetado para ser facilmente "portável" de uma plataforma para outra. Isto facilita a sua adoção generalizada como plataforma para grande conjunto de aplicativos.
Arquitetura do Apache HDFS
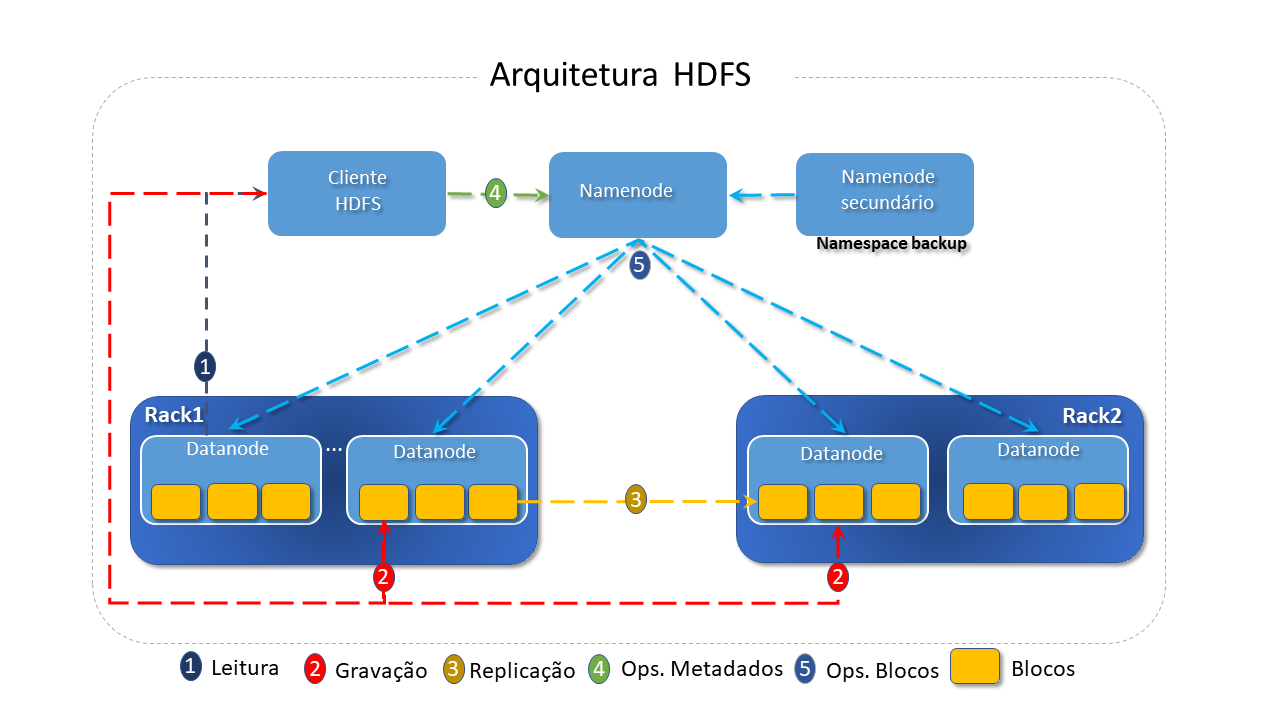
A arquitetura do HDFS é do tipo mestre/escravo, no qual um único mestre (o Namenode) controla a operação dos demais, os escravos ( DataNodes).
HDFS divide um arquivo em blocos, que são armazenados como unidades independentes, o que facilita os processos de distribuição, replicação, recuperação e processamento.
-
Namenode: O Namenode é a peça central do sistema de arquivos HDFS. É ele quem realiza o mapeamento dos blocos para os DataNodes, determinando onde eles e suas réplicas devem ser armazenados e registrando a que arquivo pertence cada um.
-
O NameNode atua através dos arquivos:
-
fsimage: que armazena quais blocos pertencem a cada arquivo
-
edit log: que armazena operações de escrita no sistema.
Quando o sistema é inicializado, o NameNode carrega toda informação do fsimage para sua memória, registrando o estado atual do sistema. Depois, registra as modificações por meio do arquivo edit log para atualizar o sistema.
-
-
Os aplicativos cliente conversam com o "Namenode" sempre que desejam localizar ou trabalhar com um arquivo(copiar/mover/excluir) e o Namenode responde às solicitações retornando uma lista de servidores onde os dados residem.
-
Quando o cliente executa uma operação de escrita, esta é registrada no arquivo de edit log e, depois, o filesystem namespace é modificado(onde ficam as informações sobre os arquivos). O filesystem namespace é armazenado localmente.
-
O NameNode executa operações de namespace do sistema de arquivos, como abrir, fechar, renomear arquivos e diretórios. Além disso, qualquer alteração no namespace é registrada pelo NameNode.
-
Um Cluster HDFS consiste em um único Namenode, o que simplifica muito a arquitetura do sistema.
-
A Comunidade elaborou algumas orientações que merecem destaque em relação ao NameNode:
Na nova arquitetura, o Cluster HA (alta disponibilidade) consiste de NameNodes em 03 distintos estados: active, standby e observer.
-
-
Datanodes: Os DataNodes são responsáveis por atender às solicitações de leitura e gravação dos clientes do sistema de arquivo e armazenar os blocos.
-
Os Datanodes ficam espalhados pelo Cluster, geralmente um por nó:
-
São eles que realizam a criação, exclusão e replicação de blocos, sob instruções do Namenode.
-
Os blocos geralmente são lidos através do disco, porém blocos frequentemente acessados podem estar em Cache dentro do DataNode. Desse modo, gerenciadores de escalonamento podem rodar tarefas nos nós onde o bloco está em cache, melhorando a performance.
-
Como são considerados pontos de falha, periodicamente enviam relatórios de funcionamento para o Namenode.
Um hearbeat indica que o DataNode está em funcionamento. Um block report indica quais os blocos estão armazenados no DataNode. Esses dados permitem que o NameNode saiba, de antemão, quais DataNodes estão disponíveis para armazenamento e para leitura, evitando, assim, o direcionamento do cliente para DataNodes que não estão em funcionamento.
-
-
Os Namenodes e Datanodes são peças de software projetadas para executar em máquinas comuns. Estas máquinas geralmente executam um sistema operacional (S.O.) GNU_Linux.
-
Uma implantação tipica possui uma maquina dedicada que executa apenas o software NameNode.
Cada uma das outras máquinas no Cluster executam uma instância do software DataNode. -
A arquitetura não impede a execução de vários DataNodes na mesma máquina, mas em uma implantação real este caso é muito raro.
Recursos do Apache HDFS
-
NameSpace do Sistema de Arquivos: O HDFS suporta a organização hierárquica tradicional de arquivos. Um usuário ou um aplicativo pode criar diretórios e armazenar arquivos dentro destes diretórios.
A hierarquia de namespace do sistema de arquivos é semelhante à maioria dos outros sistemas de arquivos existentes: pode-se criar e remover arquivos, mover um arquivo entre diretórios ou renomeá-lo.
-
Userquotas(Suporte a Quotas do Usuário) Permite que o administrador defina cotas para o número de nomes e o volume de espaço usado para diretórios individuais. Quotas de nome e quotas de espaço operam de forma independente, mas a administração e implementação dos dois tipos é paralela.
-
Access Permissions(Suporte a Permissões de Acesso). Implementa um modelo de permissões para arquivos e diretórios que compartilha muito do modelo POSIX.
-
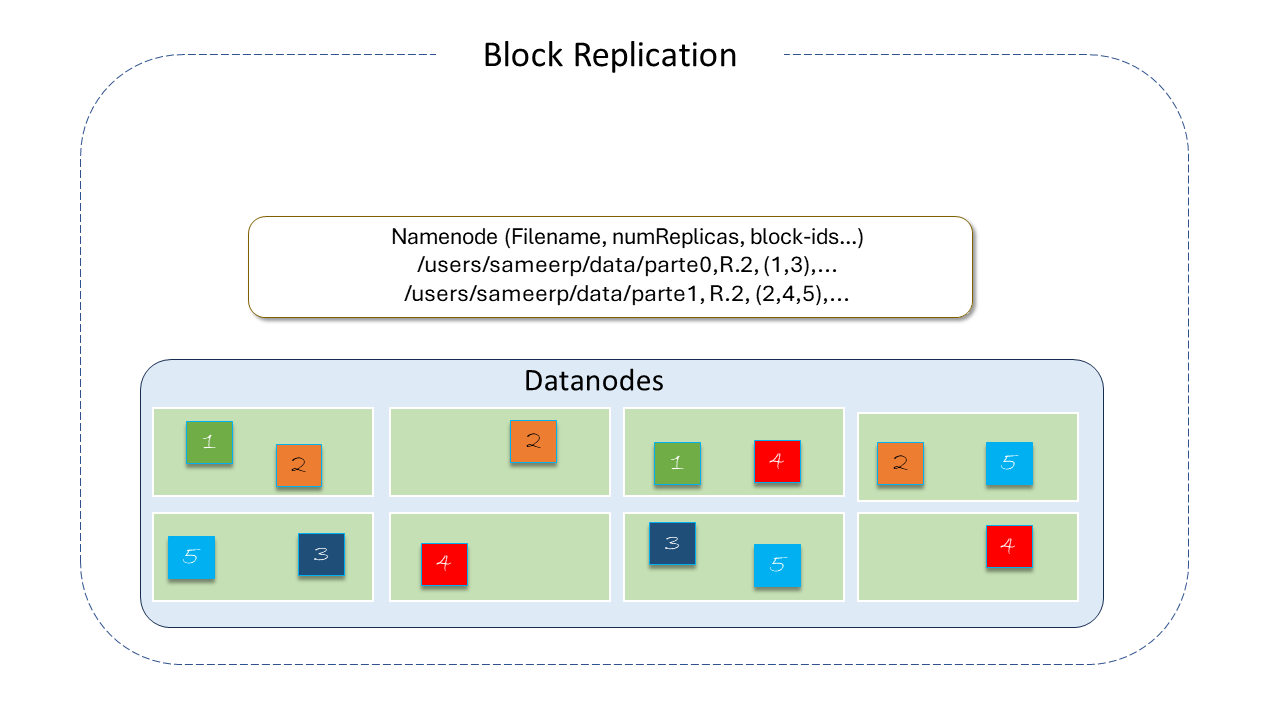
Data Replication(Replicação de Dados)*: O HDFS foi projetado para armazenar grandes arquivos em máquinas de um grande Cluster. Cada arquivo é armazenado como uma sequência de blocos que são replicados para garantir a tolerância a falhas. O tamanho do bloco e o fator de replicação são configuráveis por arquivo.
Todos os blocos de um arquivo, exceto o último, são do mesmo tamanho e os usuários podem iniciar um novo bloco sem preencher o último com o tamanho configurado, após o suporte para bloco de comprimento variado ter sido adicionado para append e hsync.
Um aplicativo pode especificar o número de réplicas de um arquivo. Este número é chamado repplication factor e pode ser definido na criação e modificado posteriormente.
O fator de replicação é armazenado pelo NameNode, que é, de fato, o responsável por tomar todas as decisões sobre replicação de dados.
Por padrão, o número de replicas é 3(tres), e os blocos são separados de forma que o primeiro esteja em um rack distinto dos demais e o segundo no mesmo rack do terceiro, mas em nós separados.
Desse modo o sistema consegue lidar com dois tipos de falhas: as falhas dos DataNodes e as falhas de rack.
Além disso, essa política melhora as operações de escrita, pois reduz a largura de banda, considerando que entre racks distintos, ela é menor que dentro do mesmo rack, uma vez que os dados estão em dois racks distintos, não em três, que seria a política mais simples.
O HDFS tenta satisfazer as requisições com uma réplica mais próxima do cliente.
-
Replica Placement(Posicionamento da réplica): A colocação das réplicas é critica para garantir confiabilidade e desempenho do HDFS. A Otimização de seu posicionamento distingue o HDFS da maioria dos outros sistemas de arquivos distribuídos. É um recurso que exige muito ajuste e experiência. A implementação da política de colocação de réplicas é um primeiro esforço nesta direção. Depois que o suporte para Storage Types and Storage Policies(tipos de armazenamento e políticas de armazenamento) foi adicionado ao HDFS, o NameNode leva em consideração a política para o posicionamento da réplica, além do conhecimento do rack. Detalhes sobre o assunto podem ser obtidos no item Replicas Placement: The First Baby Steps, no site da comunidade.
-
Replica Selection: Para minimizar o consumo global da largura de banda e latência, HDFS tenta satisfazer uma solicitação de leitura a partir de uma replica que esteja proxima do leitor. Se existir, no mesmo rack que o nó leitor, esta replica terá prefer~encia para satisfazer a solicitação. Se o Cluster HDFS espalha-se por multiplos Datacenters, então a replica que está no data center local terá preferência sobre as remotas.
-
Políticas Block Placement: Quando o fator de replicação é 3(três), a política de posicionamento do HDFS é colocar uma replica na máquina local, se o gravador estiver em um DataNode, caso contrário, em um datanode aleatório no mesmo rack que o gravador, outra replica em um nó em um rack remoto diferente, e a última em um nó diferente no mesmo rack remoto. Quando o fator de replicação é maior que 3, a colocação das demais replicas são determinadas aleatoriamente mantendo o número de replicas por rack menor que o limite superior (calculado como: replicas-1/racks+2). Adicionalmente, o HDFS oferece suporte a quatro distintas políticas de colocação de blocos conectáveis. Os usuários podem escolher a política com base em sua infraestrutura e caso de uso. Por padrão, o HDFS oferece suporte a BlockPlacementPolicyDefault.
-
Safemode Na inicialização, o NameNode entra em estado inicial denominado Safemode. A replicação de blocos não ocorre, nesta situação. O NameNode recebe mensagens Heartbeat e Blockreport(com a lista de blocos de dados que um DataNode está hospedado) dos DataNodes. Cdada bloco tem um número especificado mínimo de replicas. Um bloco é considerado replicado com segurança quando o número mínimo de replicas do bloco de dados é verificado com o NameNode. Depois que um percentual configurável de blocos de dados replicados com segurança faz check-in com o NameNode (mais 30 segundos adicionais), o NameNode sai do estado Safemode e, em seguida, determina a lista de blocos de dados (se existir) que ainda possui menos do que o número especificado de réplicas. O NameNode então replica estes blocos para outros DataNodes.
-
-
HDFS Federation O HDFS Federation adiciona suporte a múltiplos NameNodes/NameSpaces ao HDFS.
-
Viewfs O ViewFs( View File System) provê uma forma de gerenciamento de múltiplos Namespaces (ou volumes de Namespaces). É particularmente útil para Clusters com multiplos NameNodes e ambém múltiplos NameSpaces, no HDFS Federation. É análogo ao client side mount tables em sistemas Unix-Linux. Pode ser usado para criar views personalizadsa de NameSpaces e também views comuns por Cluster.
-
Snapshots São cópias "pontuais" somente leitura do sistema de arquivos. Alguns casos de uso comuns de snapshots são o backup de dados, proteção contra erros do usuário e recuperação de desastres.
-
Edits Viewer Permite a análise do arquivo de log de edições. Opera apenas em arquivos e não exige que o Cluster HADOOP esteja em execução.
-
ImageViewer ferramenta que "despeja" o conteúdo dos arquivos fsimage do HDFS em um formato "legível" e provê uma API WebHDFS somente leitura para analise e exame offline do NameSpace de um Cluster HADOOP.
-
Gerenciamento de Cache centralizado Permite a especificação de caminhos a serem armazenados em cache pelo HDFS.
-
Gateway NFS Permite que o HDFS seja "montado" como parte do sistema de arquivos local do cliente. Suporta NFSv3.
-
Criptografia transparente O HDFS implementa criptografia transparente de ponta a ponta. Depois de configurados, os dados lidos e gravados em diretórios HDFS especiais são criptografaos e descriptografados de forma "transparente", sem exigir alterações no código do aplicativo do usuário.
-
Multihomed Networks O HDFS suporta o Multihomed Newworks, onde os nós do Cluster são conectados com mais de uma interface de rede. Existem várias razões para usá-lo, como segurança, performance, e tolerância a falhas.
-
Suporte à armazenamento de memória O HDFS suporta a gravação na memória off heap(controlada pelo desenvolvedor) gerenciada pelos DataNodes.
-
Synthetic load generator Ferramenta de testes que permite verificar o comportamento do NameNode sob diferentes cargas de clientes.
-
Disk Balancer Ferramenta de linha de comando que distribui dados uniformemente em todos os discos do DataNode. É uma ferramenta diferente de Balancer,que cuida do balanceamento de dados no Cluster. O Disk Balancer opera criando um plano e executando este plano no DataNode. É ativado por padrão em um Cluster.
-
Guia de Administração do DataNode Ferramenta que permite operações como:
-
Estado de manutenção do DataNode, criado para permitir reparos/manutenções.
-
Desativação de DataNodes.
-
Recomissionamento.
-
-
Router Federation Adiciona uma camada de software para "federar" os Namespaces, permitindo que usuários acessem qualquer subcluster de forma transparente.
-
Provided Storage Permite que os dados armazenados fora do HDFS sejam mapeados e endereçados a partir do HDFS.
-
Observer NameNode: Em um Cluster HDFS habilitado à Alta Disponibilidade (HA), existe um único NameNode Ativo (Active Namenode) e um ou mais NameNode(s) "standby". O NameNode ativo é responsável por servir todas as requisições dos clientes, enquanto o NameNode em "standby" apenas mantém as informações atualizadas sobre o NameSpace, assim como inofrmações sobre a localização dos blocos, recebendo relatórios de todos os DataNodes. O recurso Observer NameNode endereça as funções acima por meio de um novo NameNode chamado "Observer NameNode". Da mesma forma que o NameNode "standby", o Observer NameNode se mantém atualizado em relação ao NameSpace e informções de localização do bloco. Mas além disso, tem a capacidade de produzir leituras consistentes, como o Active NameNode. Com as solicitações de leitura são uma grande parte em um ambiente típico, isto ajuda a balancear a carga do tráfego NameNode e melhorar a taxa de transferência geral (throughput).
Observações importantes
-
Embora o HDFS siga a convenção de nomes do Filesystem , alguns caminhos e nomes (p.ex: /.reserved e .snapshot) são reservados. Recursos como criptografia transparente (transparent encryption) e snapshot usam caminhos reservados.
-
Atualmente, o HDFS não suporta hard links (o link atuando como ponteiro para o inode de um arquivo ou diretório) ou soft links(ou link simbólico - atuando como ponteiro ou referencia para o nome do arquivo). No entanto sua arquitetura não impede a implementação destes recursos.
Linguagem do Apache HDFS
O HDFS foi construído na linguagem Java, altamente portável, o que o torna implementável em uma ampla variedade de máquinas. Qualquer máquina que suporta Java pode executar o software NameNode ou DataNode.
fonte(s): hadoop.apache.org