Apache Iceberg
"Table Formats"
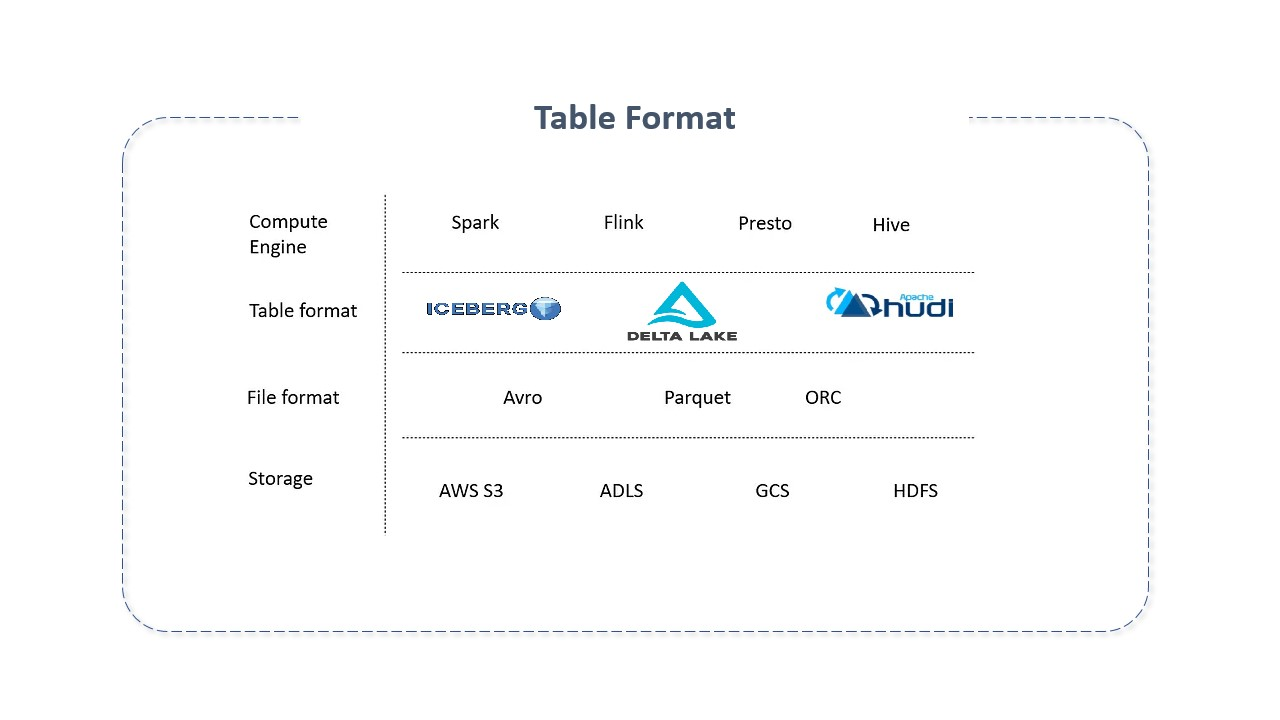
Table Formats são estruturas de tabelas utilizadas para organizar e gerenciar dados complexos, permitindo que sejam visualizados e interagidos como uma única "tabela" compreensível e acessível para vários usuários e ferramentas simultaneamente.
Os Table Formats adicionam uma camada de abstração semelhante a uma tabela sobre formatos de arquivo nativos, servindo como uma camada de metadados e fornecendo as primitivas necessárias para que os mecanismos de computação interajam com os dados armazenados de forma mais eficiente, garantindo a conformidade aprimorada com ACID, a capacidade de registrar dados transacionais com eficiência, a escalabilidade e a capacidade de atualizar ou excluir registros.
Os table formats evoluíram como resposta a uma necessidade crítica: combinar as vantagens de gerenciamento de dados de "armazéns" (bancos de dados OLAP) com maior escalabilidade e economia características dos data lakes. Em suma, combinam a versatilidade dos data lakes para lidar com dados brutos e semiestruturados com a capacidade de processar cargas de trabalho transacionais.
Em poucas palavras, table formats são uma forma de organizar arquivos de dados. Tentam trazer características de bancos de dados para o data lake. Sua principal meta é prover a abstração das tabelas para pessoas e ferramentas permitindo que interajam de forma eficiente com seus dados subjacentes.
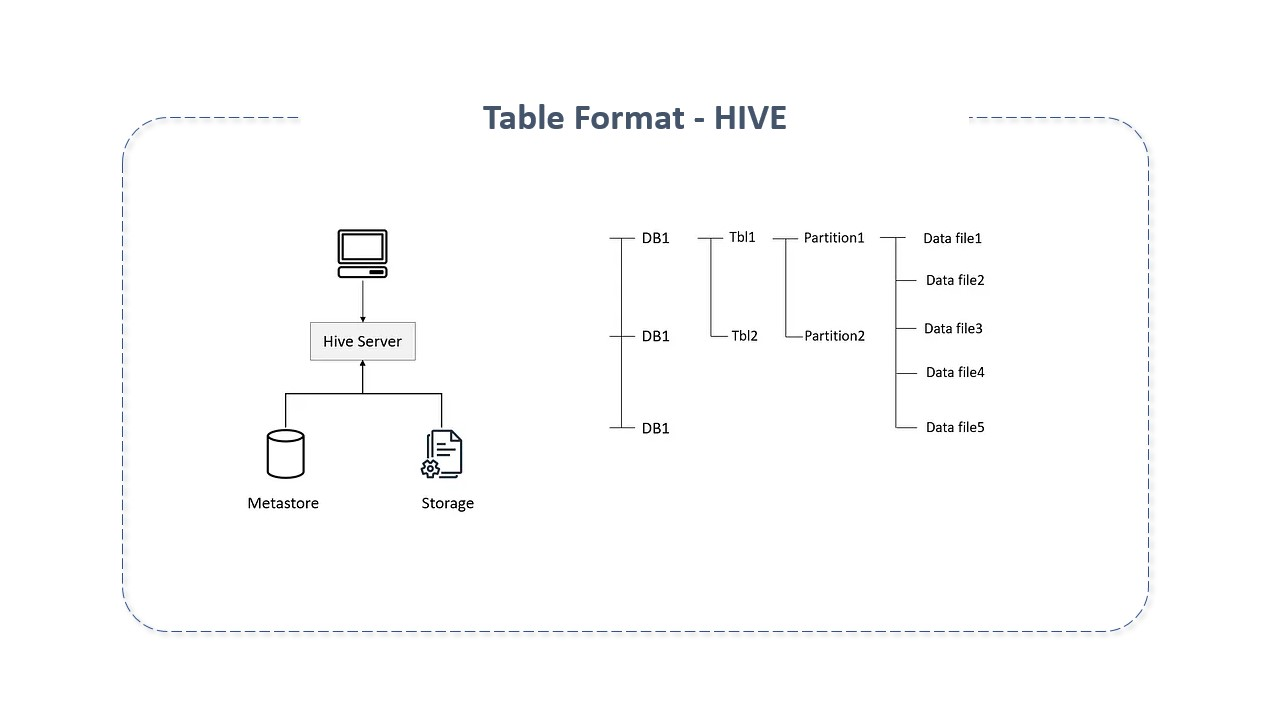
Embora não fosse o nome usado à época, os table formats existem desde que System R, Multics e Oracle implementaram pela primeira vez o modelo relacional de Edgar Codd. Quando falamos que grupo de arquivos é uma coleção, estamos falando em table formats. Quando um arquivo é visto em formato de tabela, o diretório é visto como uma tabela, o que facilita seu rastreamento e o de seus arquivos. Isto é feito com a ajuda de sistemas de catálogo. Sob ele, arquivos são escritos em versões e aqueles mais recentes, correspondentes a uma tabela, são rastreados com a ajuda do metastore. O metastore é acessado para saber o estado atual da tabela e quais os arquivos relacionados.
O Apache Hive é um dos mais antigos table formatos usados. Entretanto, como Hive foi escrito na era pré-cloud, não previu o armazenamento orientado a objetos, o que resultou em impactos no seu desempenho, uma vez que as tabelas de metadados do Hive crescem rapidamente. Para solucionar estas questões, novos formatos de tabelas foram criados.
Apache Iceberg
O Apache Iceberg é um table format de código aberto para grandes conjuntos de dados analíticos, com uma especificação que garante compatibilidade entre linguagens e implementações. Adiciona tabelas a mecanismos de computação como o Spark, Trino, Flink, Hive, etc., usando um formato de tabela de alto desempenho que funciona exatamente como uma tabela SQL.
O Apache Iceberg permite o acesso a dados históricos em tempo real de forma coesa, garantindo integridade e consistência de dados. Sua principal inovação reside na capacidade de suportar operações de leitura, escrita, atualização e exclusão de dados sem reescrita de conjuntos inteiros de dados.
O Apache Iceberg teve uma adoção muito rápida entre grandes empresas como Apple, Netflix, Amazon, etc. A sua natureza completamente aberta, comprometendo várias empresas e a comunidade, torna-o ideal para a arquitetura de data lake.
Características do Apache Iceberg:
O Apache Iceberg foi desenvolvido em 2017 pela Netflix,doado à Apache Software Foundation em Novembro de 2018. Tornou-se um projeto de alto nível em 2020. É usado por inúmeras companhias incluindo o Airbnb, Apple, Linkedin, Adobe, etc. Foi criado especificamente para resolver problemas e desafios relacionados com tabelas formatadas de arquivos tradicionais em data lakes, como a evolução de dados e schemas e gravações concorrentes, de forma consistente, em paralelo. Introduz novos recursos que permitem que vários aplicativos (como o Dremio) trabalhem juntos nos mesmos dados de maneira transacional, de forma consistente, e definam informações adicionais sobre o estado dos conjuntos de dados à medida em que evoluem e mudam ao longo do tempo.
O Apache Iceberg adiciona tabelas para engines de computação como o Spark, Trino, Flink e Hive usando um formato de tabela de alta performance que funciona como uma tabela SQL.
Dentre suas principais características citamos:
-
Evolução de esquema: Suporta a adição, exclusão, atualização ou renomeação, sem efeitos colaterais;
-
Particionamento oculto: Impede erros de usário como causa de resultados incorretos de forma silenciosa ou consultas extremamente lentas;
-
Evolução do layout da partição: Permite a atualização do layout de uma tabela à medida em que o volume de dados ou padrões de consulta mudam.
Arquitetura do Apache Iceberg
Na prática, o Apache Iceberg é uma especificação de formato de tabelas e um conjunto de APIs e bibliotecas que viabilizam a interação de mecanismos com tabelas, seguindo esta especificação.
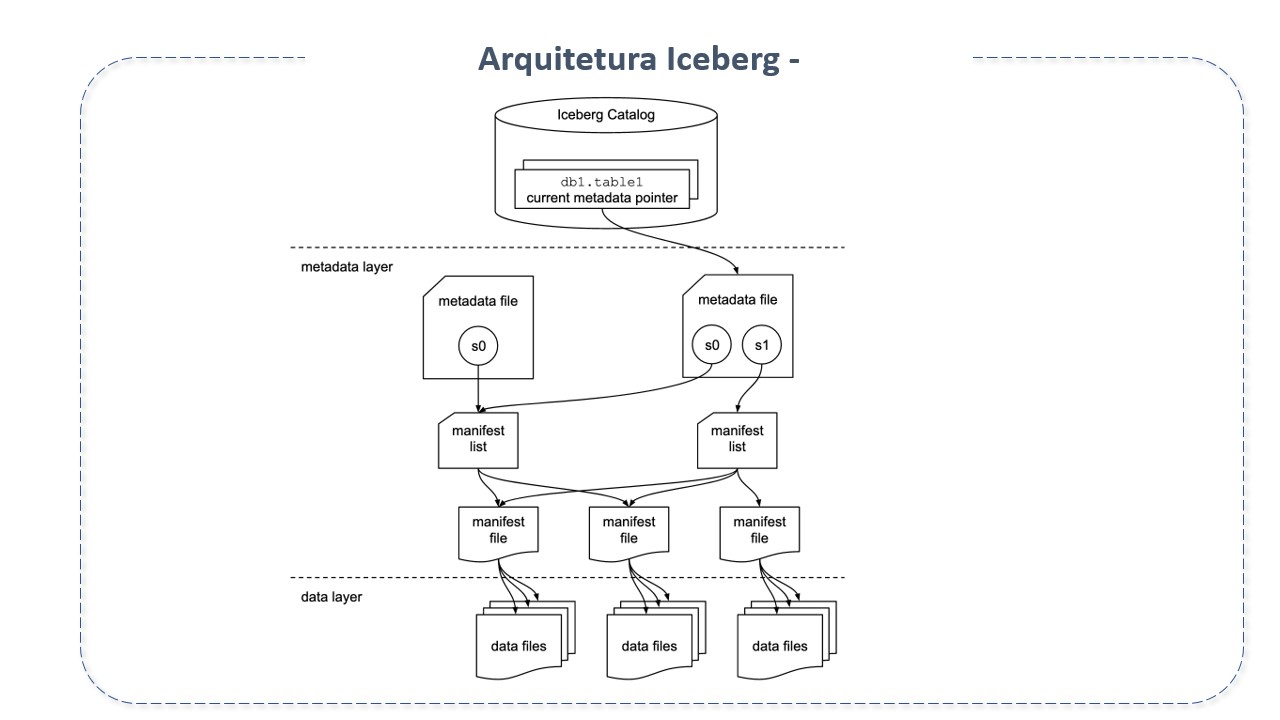
Seus principais componentes são:
-
Catalogo Iceberg
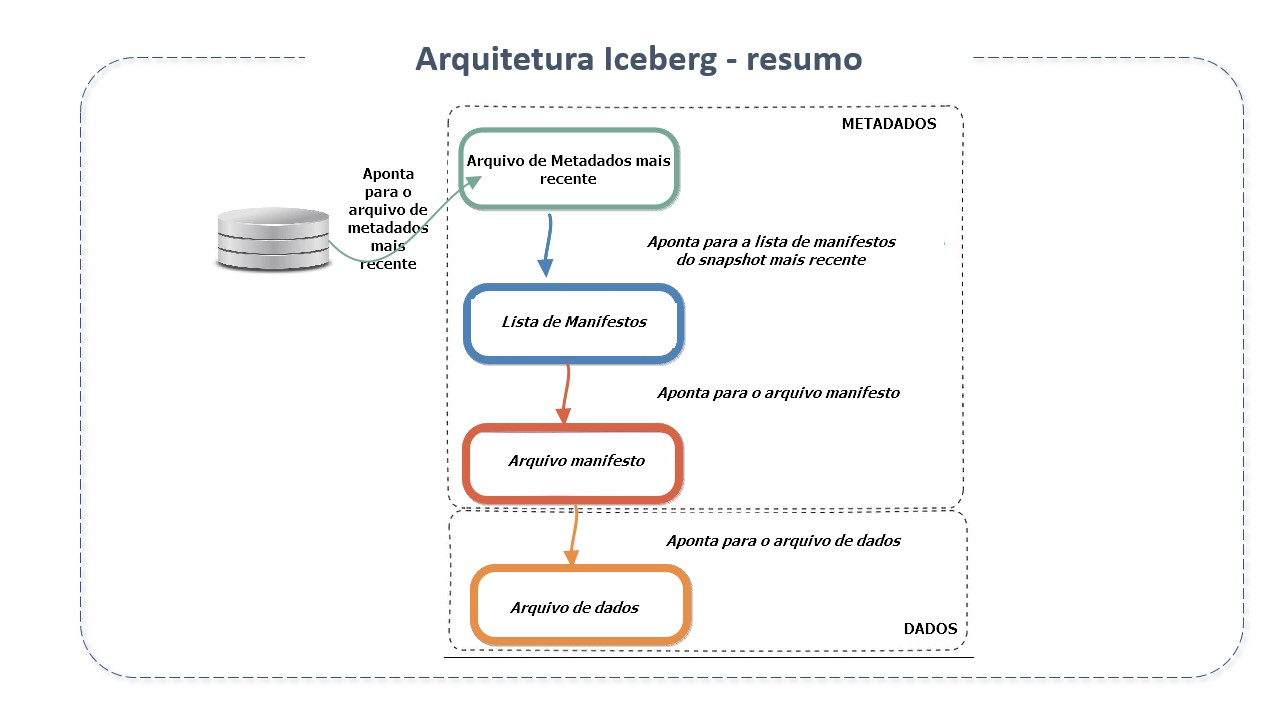
O catálogo é um repositório central onde é armazenada a referência ao arquivo de metadados de cada tabela. Seu objetivo principal é suportar operações atômicas para atualizar ponteiros. Para isto, guarda a localização atual do ponteiro de metadados (dentro do catálogo há uma referência ou ponteiro para o arquivo de metadados atual de cada tabela. O valor do ponteiro é o local do arquivo de metadados).
-
Camada de Metadados
Os metadados são rastreados em três arquivos, os arquivos de metadados, a lista de manifestos e os arquivos de manifesto.
-
Arquivos de metadados (metadata file): arquivo .json que contém informações sobre os metadados da tabela em determinado instante de tempo. Armazena o estado das tabelas. Nele encontramos detalhes sobre o schema da tabela, informações sobre partição, id do snapshot atual (current-snapshot_id), caminho para a lista de manifesto(manifest list), etc. Quando há mudança no estado das tabelas, cria um novo arquivo de metadados e substitui o antigo com um swap atômico. Possui as seguintes subseções:
-
Snapshot: É uma lista completa de todos os arquivos na tabela do snapshot. Representa o estado de uma tabela em determinado momento e é usado para acessar o conjunto completo de arquivos de dados na tabela. Contém informações sobre o schema da tabela, especificações de partição e localização da lista de manifesto;
-
Schemas: Todos os schemas de tabelas alterados são rastreados pela "matriz de schemas";
-
Especificações de partição: rastreia informações sobre a partição;
-
Ordens de classificação.
-
-
Lista de Manifestos(manifest list): Arquivo do tipo avro que contem todos os manifestos e suas métricas. Armazenam os metadados sobre os manifestos que compõem um snapshot, incluindo estatísticas de partição e contagens de arquivos de dados. Estas estatísticas são usadas para evitar a leitura de manifestos desnecessários à operação. Atua como um link entre o manifesto e o snapshot.
-
Arquivos de manifesto (manifest file): Mantém o controle sobre todos os arquivos de dados, juntamente com detalhes e estatísticas como seus formatos, localização e métricas.
-
-
Camada de Dados
-
Arquivo de dados: O arquivo físico real. Onde de fato estão os dados.
-
O Apache Iceberg foi construído para tabelas enormes que podem ser lidas sem um mecanismo SQL distribuído. Cada tabela pode conter dezenas de petabytes de dados.
Recursos do Apache Iceberg
-
Recursos relacionados à experiência do Usuário:
O Apache Iceberg melhora a experiência do usuário no sentido em que:
-
Com o suporte à evolução do schema suporta adições, eliminações, atualizações, renomeações e reordenamento de colunas em uma tabela sem a necessidade de regravação da tabela. Isto torna a evolução do schema livre de efeitos indesejados, designando um ID único a cada coluna recém criada e automaticamente adicionando-a ao metadados da coluna. Também garante a exclusividade de cada coluna;
-
Com o particionamento oculto, garante que usuários não precisem mais saber o layout estrutural de arquivos antes de executar consultas. Isto evita erros do usuário que causam resultados silenciosamente incorretos ou consultas extremamente lentas. O Iceberg evolui o esquema e a partição da tabela à medida em que os dados são dimensionados;
-
Com o "time travel", o recurso de controle de versão, o Iceberg garante o salvamento de qualquer alteração nos dados para referências futuras, seja adicionando, excluindo ou atualizando dados. Assim, qualquer problema com a versão de dados pode ser facilmente revertido para uma versão mais antiga e estável, garantindo que dados não sejam perdidos e que possam ser comparados ao longo do tempo.
-
-
Recursos de confiabilidade:
-
O isolamento do snapshot garante que qualquer leitura do conjunto de dados veja um "instantãneo" consistente. Em essência, lê o último valor confirmado presente no momento da leitura. Isto evita conflitos. Após os "commits" o registro é atualizado e um novo snapshot é criado, refletindo a atualização mais recente;
-
Com os Commits atômicos, garante que os dados permaneçam consistentes em todas as consultas. Para evitar alterações parciais, qualquer atualização deve ser concluida no conjunto de dados, ou não salvará nenhuma alteração. Isto garante o retorno apenas de dados corretos, evitando que usuários visualizem dados incompletos ou inconsistentes;
-
As leituras são confiáveis, pois cada transação (atualização, adição, eliminação) cria um novo snapshot. Assim, os leitores podem utilizar as diversas versões mais recentes de cada atualização para criar uma consulta confiável para a tabela;
-
As operações são em nível de arquivo, diferentemente dos catálogos tradicionais, que rastreiam registros por posição ou nome, o que exige leitura de diretórios e partições antes da atualização de um único registro. No Apache Iceberg é possível direcionar diretamente um único registro e qualquer atualização do registro sem nenhuma alteração na pasta. Isto porque os registros estão armazenados em seus metadados.
-
-
Recursos de desempenho:
-
Cada arquivo que pertence a uma tabela possui metadados armazenados para qualquer transação ocorrida, junto com estatísticas extras. Isto permite que usuários localizem apenas os arquivos que correspondem à consulta que desejam no momento;
-
O Iceberg utiliza dois níveis de metadados para rastrear os arquivos em um snapshot - os arquivos de manifesto e a lista de manifestos. O primeiro nível contém os arquivos de dados, junto com seus dados de partição e estatísticas em nível de coluna. O segundo armazena a lista de snapshots do manifesto com um intervalo de valores para cada partição;
-
Para obter um rápido "scan planning" , o Iceberg usa valores mínimo e máximo da partição na lista de manifestos para filtrar os manifestos. Posteriormente, ele lê todos os manifestos retornados para obter o arquivo de dados. Assim, é possível planejar sem ler todos os arquivos de manifesto, usando a lista de manifestos para restringir o número de arquivos de manifestos necessários à leitura.
Com isto, é possível alcançar consultas eficientes e econômicas em arquivos.
-
Boas Práticas no Uso do Apache Iceberg
O Apache Iceberg é uma ferramenta poderosa para gerenciamento de grandes conjuntos de dados analíticos. Para maximizar sua eficiência e eficácia, aqui estão algumas boas práticas:
-
Estrutura de Dados e Esquemas: Mantenha os esquemas de dados simples e evolutivos. Utilize a funcionalidade de evolução de esquema do Iceberg para manter a compatibilidade e minimizar as interrupções;
-
Particionamento Eficiente: Utilize particionamento lógico para organizar os dados de maneira que otimize as consultas mais comuns. O particionamento oculto do Iceberg pode ajudar a evitar problemas de desempenho;
-
Gerenciamento de Metadados: Mantenha os metadados limpos e atualizados. Isso inclui remover snapshots antigos e arquivos de manifesto não utilizados para evitar sobrecarregar o catálogo;
-
Testes e Validação: Implemente testes rigorosos ao evoluir esquemas ou modificar tabelas para garantir a integridade dos dados;
-
Monitoramento e Otimização: Monitore regularmente o desempenho das consultas e otimize as tabelas conforme necessário. Isso pode incluir ajustar o particionamento ou modificar índices;
-
Documentação: Mantenha uma documentação clara sobre as estruturas de tabelas, esquemas e qualquer lógica de negócios associada para facilitar a manutenção e a colaboração;
-
Segurança e Controle de Acesso: Implemente controles de acesso adequados e práticas de segurança para proteger os dados;
-
Uso de Recursos e Custo: Esteja ciente do uso de recursos e custos associados, especialmente em ambientes de nuvem. Otimize o uso de armazenamento e computação para manter a eficiência de custos;
-
Atualizações e Compatibilidade: Mantenha-se atualizado com as versões mais recentes do Apache Iceberg para aproveitar melhorias e correções de segurança;
Utilizar o Apache Iceberg de acordo com essas práticas pode melhorar significativamente a gestão de dados e a eficiência operacional.
Quando uasr o Apache Iceberg
-
Grandes Conjuntos de Dados: Quando estiver lidando com petabytes de dados em tabelas enormes;
-
Data Lakes Modernos: Para arquiteturas modernas de data lake que necessitam de gerenciamento robusto de dados e esquemas;
-
Escalabilidade e Confiabilidade: Quando a escalabilidade e a confiabilidade são críticas para a operação e análise de dados;
-
Transações ACID em Data Lakes: Para suportar transações ACID em data lakes, garantindo a integridade dos dados;
-
Evolução de Esquema: Quando há necessidade de evoluir o esquema de dados sem interrupção ou perda de dados;
-
Atualizações e Deleções: Se precisar fazer atualizações e deleções eficientes em grandes conjuntos de dados;
-
Trabalho com Múltiplos Formatos de Dados: Se trabalha com vários formatos de dados e precisa de uma camada de abstração uniforme;
-
Leituras e Escritas Concorrentes: Quando precisar de suporte para leituras e escritas concorrentes sem bloqueio;
-
Compliance e Governança de Dados: Para atender a requisitos rigorosos de compliance e governança de dados;
-
Integração com Plataformas de Análise: Se deseja integrar com plataformas de análise como Spark, Trino, Flink e outras;
-
Snapshot e Traveling de Dados: Quando a funcionalidade de snapshot e traveling de dados é necessária para auditoria ou rollback;
-
Melhoria de Performance de Leitura: Para melhorar a performance de leitura através de indexação e otimizações de arquivo;
Estes itens destacam cenários ideais para a implementação do Apache Iceberg, maximizando seus recursos para gerenciamento eficiente de data lakes.
Quando não usar o Apache Iceberg
O Apache Iceberg não é a ferramenta adequada para:
-
Pèquenos volumes de dados: se o universo de dados for pequeno, que não exija o uso de data lake, o Apache Iceberg não trará benefícios.
-
Ingestão em tempo real: Apache Iceberg não oferece suporte a ingestão de dados em tempo real porque usa o processamento em lote.
-
Estrutura centralizada: Se o objetivo não é usar uma estrutura de computação distribuída, o Apache Iceberg não é a escolha ideal, pois foi projetado para usar uma estrutura de computação distribuída para processar dados.
Linguagem de desenvolvimento
O Apache Iceberg é desenvolvido principalmente em Java. Portanto, uma boa compreensão de Java é essencial para contribuir efetivamente para o projeto ou para personalizá-lo. Isso também implica a necessidade de manter as práticas padrão de codificação Java, como o gerenciamento eficiente de exceções e a utilização de bibliotecas Java comuns para operações de I/O e manipulação de dados.
Fonte(s):