Apache Sqoop
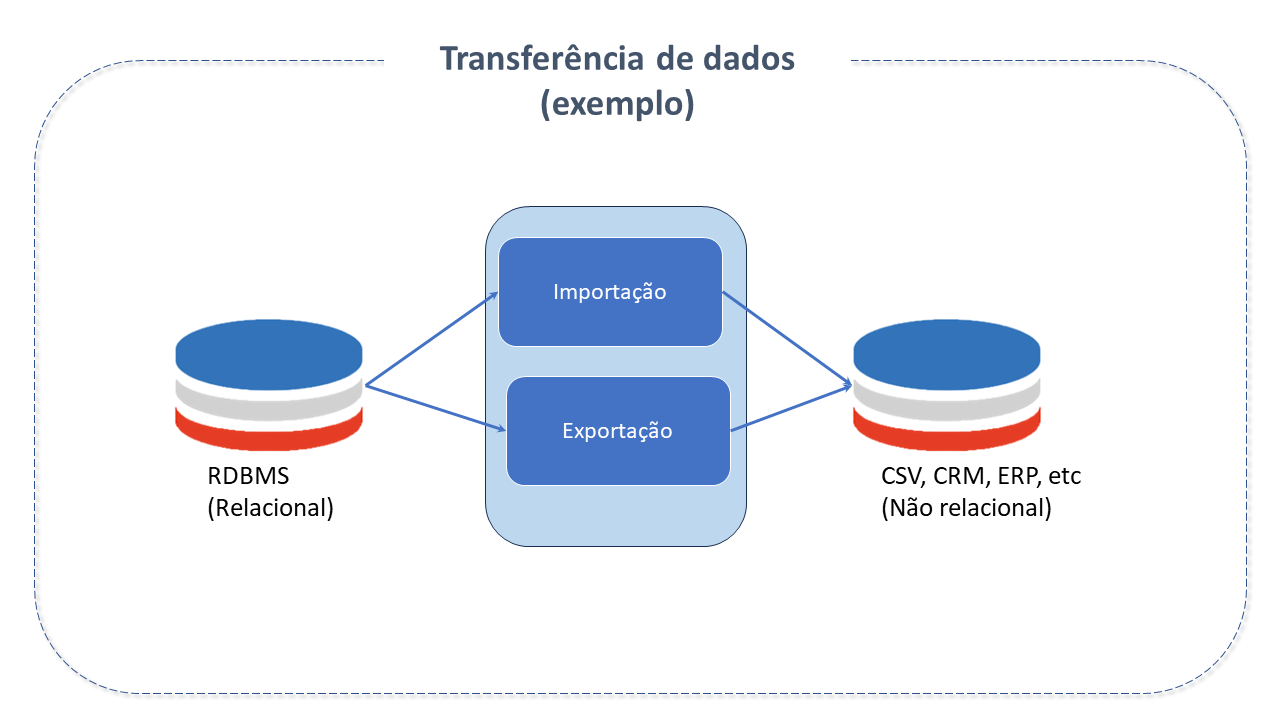
Transferência de dados
Antes de serem processados por um sistema de aprendizado de máquina, os dados precisam ser importados. Da mesma forma, precisam ser exportados para outras aplicações antes de usados externamente.
Um "engine" de transferência de dados habilita a movimentação "para" ou "de" dispositivos de armazenamento diferentes. O trabalho real de importação é feito pelos mecanismos de processamento, que executam os trabalhos de importação e, em seguida, persistem os dados importados no dispositivo de armazenamento.
Diferentemente de outros sistemas de processamento de dados, onde os dados de entrada estão em conformidade com um esquema e são quase sempre estruturados, os dados de origem de um sistema de "machine learning" pode incluir uma mistura de fontes e formatos.
Características do Apache Sqoop
O Apache Sqoop é uma ferramenta de linha de comando criada para viabilizar a transferência de dados "em massa" entre Apache HADOOP e datastores estruturados, como SGBD Relacionais.
A integração destes ambientes é o papel do Sqoop e sua principal finalidade é realizar a importação/exportação de dados entre o ambiente relacional e o HADOOP.
O dado armazenado em databases externos não pode ser acessado diretamente pelas aplicações MapReduce. Esta abordagem colocaria o sistema em nós dos Clusters em grande risco de estresse.
O Sqoop simplifica o carregamento de grandes quantidades de dados de RDBMS para o Hadoop, solucionando essa questão.
A maior parte do procedimento é automatizada pelo Sqoop, que depende do banco de dados para especificar a estrutura de importação de dados. Ele importa e exporta dados usando a arquitetura MapReduce, que oferece uma abordagem paralela e tolerante a falhas.
O Sqoop graduou-se da incubadora em março de 2012, tornando-se um projeto de nível superior na Apache.
Algumas de suas características merecem destaque:
-
Faz a leitura linha por linha da tabela ao escrever o arquivo no HDFS.
-
Realiza importação de dados e metadados de bancos relacionais direto para o Hive.
-
Fornece um processamento paralelo e tolerante a falhas ao usar o Map Reduce em atividades import/export.
-
A ferramenta Sqoop usa a estrutura YARN para importar e exportar dados, tornando-se tolerante a falhas com paralelismo.
-
Possibilidade de selecionar o intervalo de colunas a serem importadas.
-
Possibilidade de especificar os delimitadores e formatos de arquivos.
-
Paraleliza conexões em Banco de Dados executando comando SQL como SELECT(import) e Insert/Update(export)
-
O Padrão do arquivo importado do HDFS é o CSV .
-
Conversão de tipos de dados:
-
O Sqoop importa tabelas individuais ou Databases inteiros para arquivos em HDFS.
-
Um conector JDBC genérico é fornecido para conexão com qualquer banco de dados que suporte o padrão JDBC. Possui diversos plugins para conexão com PostgreSQL, Oracle, Teradata, Netezza, Vertica, DB2, SQL Server e MySQL.
-
Cria classes java que permitem a interação de usuários com o dado importado.
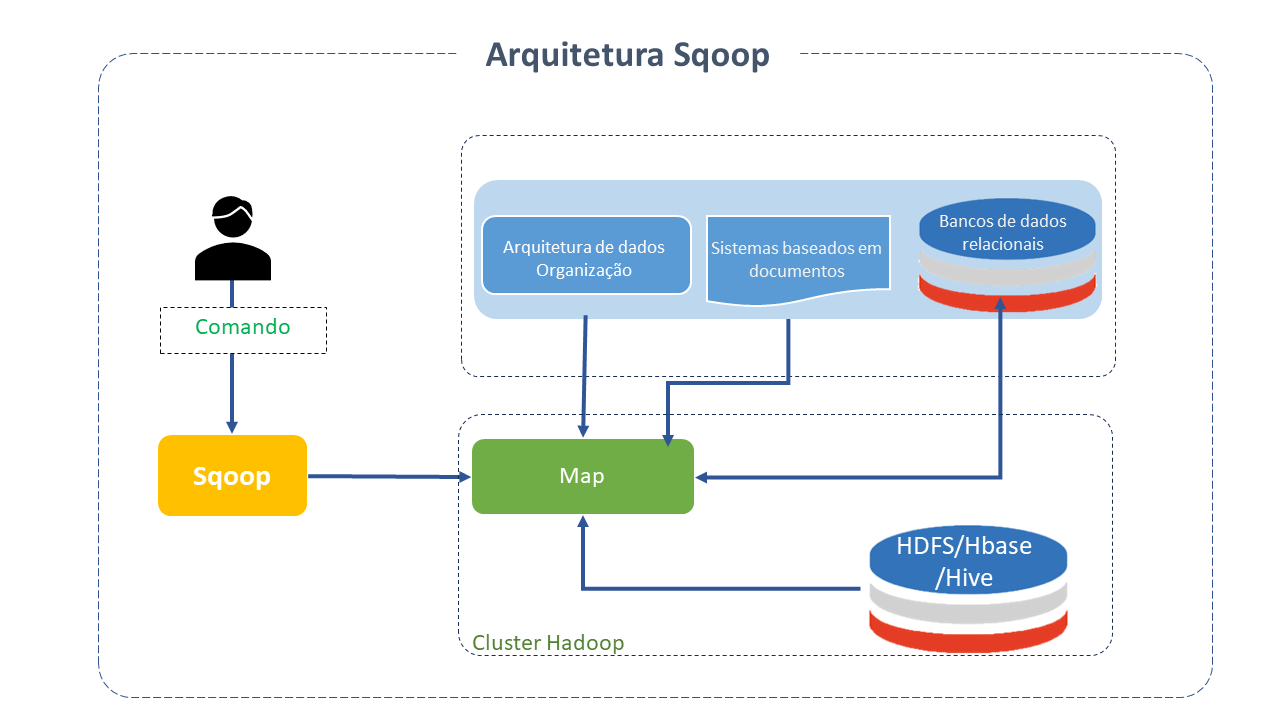
Arquitetura do Apache Sqoop
Sqoop fornece uma interface de linha de comando para usuários finais e também pode ser acessado pela API Java.
A migração de dados entre Sqoop Hadoop e um sistema externo de armazenamento é possível por meio dos conectores Sqoop, os quais o habilitam a usar vários de bancos de dados relacionais conhecidos como, por exemplo, o MySQL, PostgreSQL, Oracle, etc. Cada uma destas conexões pode se comunicar com o DBMS ao qual está vinculada.
O que ocorre durante a execução do Sqoop é bem simples: O dataset transferido é dividido em várias porções e um job somente de Map é criado com mappers distintos encarregados de carregar cada partição. O Sqoop usa as informações do banco de dados para deduzir os tipos de dados, manipulando cada registro de maneira segura.
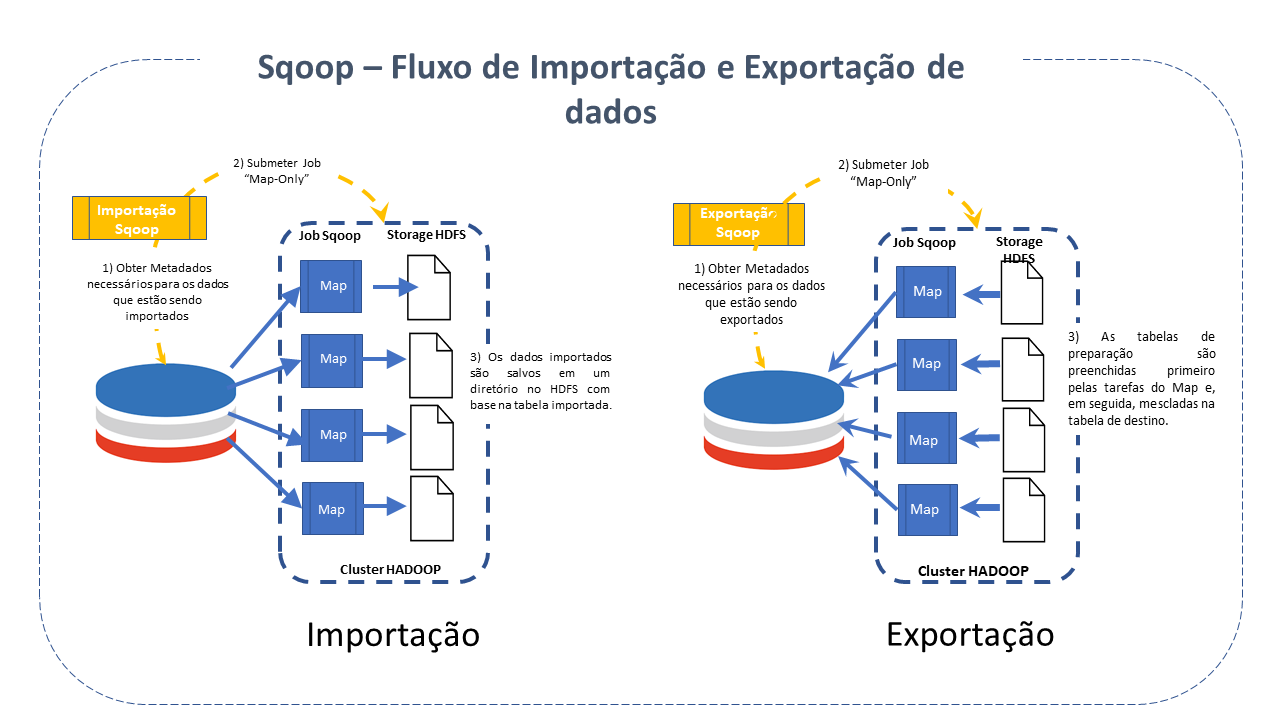
O Sqoop é composto, assim, de duas operações principais:
Procedimento realizado com o comando Sqoop import. Cada registro carregado no SGBD HADOOP como um único registro é mantido em arquivos texto como parte da estrutura HADOOP. Ao importar dados, também é possível carregar e dividir o Hive. O Sqoop também permite a importação incremental de dados.
Facilita a execução da tarefa com auxilio do comando export, que realiza a operação no sentido contrário. Os dados são transferidos do sistema de arquivos HADOOP para o SGBD Relacional. Antes de finalizar a operação, os dados exportados são transformados em registros.
Recursos do Apache Sqoop:
-
É possível importar os resultados de uma query SQL em HDFS com Sqoop.
-
Oferece conectores para a maior parte dos RDBMS, como MySQL, Microsoft SQL Server, PostgreSQL, etc.
-
Suporta protocolo de autenticação de rede Kerberos, permitindo que os nós autentiquem usuários enquanto se comunicam com segurança numa rede insegura.
-
Com um único comando, o Sqoop pode recarregar a tabela inteira ou seções específicas da tabela.
Quando usar o Apache Sqoop
-
Processamento de bases OLTP usando alguma ferramenta de Big Data.
-
Integração de OLTP com HADOOP
-
Ingestão de dados no HADOOP
Como funciona
O Comando inserido pelo usuário é analisado pelo Sqoop e executa o Hadoop Map apenas para importar ou exportar dados, pois a fase Reduce só é necessária quando as agregações são necessárias.
Sqoop analisa os argumentos inseridos na linha de comando e prepara a tarefa Map. Um trabalho de mapeamento que executa vários mapeadores depende do número definido pelo usuário na linha de comando.
Durante uma importação, cada tarefa do map recebe uma parte dos dados a serem importados com base na linha de comando.
Sqoop distribui os dados uniformemente entre os mapeadores para garantir alto desempenho.
Em seguida cada mapeador cria uma conexão com o banco de dados JDBC.
Boas Práticas para Apache Sqoop
-
Embora as importações para o formato de arquivos CSV sejam fáceis de testar, alguns problemas podem surgir quando o texto armazenado no Banco de dados usa caracteres especiais. A importação para o formato binário, como o Avro evitará este problema e poderá tornar mais rápido o processamento no HADOOP.
-
Sqoop trabalha no modelo de programação MapReduce. Importa e exporta dados a partir da maior parte de databases relacionais em paralelo. O número de tarefas Map por job determina este paralelismo. Controlar o paralelismo permite lidar com a carga dos databases e também com sua performance. Existem duas formas de explorar o paralelismo no Sqoop:
-
Alterando o número de mappers: Os trabalhos tipicos do Sqoop iniciam quatro mappers por padrão. Para otimizar o desempenho recomenda-se aumentar as tarefas do Map (processos paralelos) para um valor inteiro de 8 ou 16. Isto pode mostrar um aumento no desempenho em alguns bancos de dados. Usando -m ou --num—mappers pode-se definir o grau de paralelismo no Sqoop.
Sqoop import \-- connect jdbc: postgresql://postgresql.example.com/Sqoop \-- username Sqoop \-- password Sqoop \-- table _nome-da-tabela_ \-- num-mappers 10 -
Dividindo por consulta: Ao realizar importações paralelas, o Sqoop precisa de um critério para dividir a carga de trabalho. Ele usa uma coluna de divisão para dividir a carga de trabalho.
Por padrão, identificará a coluna de chave primária (se estiver presente) em uma tabela e a usará como coluna de divisão.
Os valores baixo e alto para a coluna de divisão são recuperados do Banco de Dados e as tarefas de map operam em componentes de tamanho uniforme do intervalo total.
O parâmetro split-by divide os dados da coluna uniformemente com base no numero de mappers especificados. A sintaxe split by é:
Sqoop import -- connect jdbc: postgresql://postgresql.example.com/_nome-do-database_ \-- username _nome-do-usuário_ \-- password _senha_ \-- table _nome-da-tabela_ \-- split-by _campo__id_
O número de tarefas map deve ser menor que o número máximo de conexões de databases paralelos possiveis. O incremento no grau de paralelismo deve ser menor que aquele disponivel dentro de seu Cluster Map Reduce.
-
-
Controle do Processo de transferência de dados: Um método popular de melhorar a performance é gerenciando o caminho onde importamos e exportamos dados. Resumimos abaixo alguns caminhos. Para ver os argumentos existentes, Pesquise as Tabelas "Table 3" e "Table 29" → argumentos de controle de importação/exportação, no Sqoop User Guide:
-
Batch: (lote) Que significa que as instruções SQL podem ser agrupadas em um lote quando os dados são exportados.
A interface JDBC disponibiliza uma API para fazer lotes em uma instrução preparada com vários conjuntos de valores. Essa API está presente em todos os drivers JDBC porque é exigida pela interface JDBC.
O lote é desabilitado por padrão no Sqoop. Habilite o lote JDBC usando o parâmetro batch.
sqoop export -- connect jdbc: postgresql://postgresql.example.com/_nome-do-database_ \-- username _nome-do-usuário_ \-- password _senha_ \-- table _nome_tabela_ \-- export-dir /data/_nome-do-database_ \-- *batch* -
Tamanho de busca: O número padrão de registros que podem ser importados de uma única vez é 1.000. Isso pode ser alterado pelo parâmetro Fetch-size, usado para especificar o número de registros que o Sqoop pode importar por vez.
-- connect jdbc: postgresql://postgresql.example.com/_nome-do-database_ \-- username _nome-do-usuário_ \-- password _senha_ \-- table _nome_tabela_ \-- fetch-size=n --> onde n representa o número de entradas que o Sqoop deve buscar por vez.Com base na memória e largura de banda disponíveis, o valor do parâmetro fetch-size pode ser aumentado em relação ao volume de dados que precisa ser lido.
-
Modo Direto: Por padrão, o processo de importação Sqoop usa JDBC, que fornece um suporte razoável. No entanto, alguns bancos de dados podem obter maior desempenho usando utilitários específicos de bancos de dados pois são otimizados para fornecer a melhor velocidade de transferência possível, colocando menos pressão sobre o servidor de banco de dados .
Ao fornecer o argumento --direct, o Sqoop é forçado a tentar usar o canal de importação direta. Este canal pode ter um desempenho maior que usar o JDBC.
Sqoop import -- connect jdbc: postgresql://postgresql.example.com/_nome-do-database_ \-- username _nome-do-usuário_ \-- password _senha_ \-- table _nome_tabela_ \-- directExistem várias limitações que companham essa importação mais rápida. Nem todos os bancos de dados possuem utilitários nativos disponiveis e esse modo não está disponível para todos os bancos de dados.
Sqoop tem suporte direto para MySQL e PostgreSQL.
-
Consultas de limite personalizados: Como já visto, o split by distribui uniformemente os dados para importação. Se a coluna tiver valores não uniformes, a consulta de limite pode ser usada se não obtivermos os resultados desejados ao usar apenas o arqumento split-by. Idealmente, configuramos o parâmetro de consulta de limite como min(id) e max(id) juntamente com o nome da tabela.
Sqoop import -- connect jdbc: postgresql://postgresql.example.com/_nome-do-database_ \-- username _nome-do-usuário_ \-- password _senha_ \-- query 'SELECT... FROM... JOIN ... USING ... WHERE $CONDITIONS' \-- split-by id \-- target-dir _nome-da-tabela_ \-- boundary-query "selecionar min(id), max(id) de _nome-da-tabela-normalizada_"
-