Apache Zookeeper
Serviço de Coordenação Centralizada
Aplicações distribuídas consistem em múltiplos componentes de software que operam simultaneamente em diversos servidores físicos escaláveis, podendo abranger centenas ou milhares de máquinas.
Obviamente, este sistema está sujeito a falhas de hardware, travamentos, falhas de sistema, de comunicação e assim por diante, São falhas que não seguem um padrão e, portanto, tornam dificil aplicar um código de tolerância na lógica do aplicativo ou no projeto do Sistema.
Além disso, fazer uma coordenação de Cluster correta, rápida e escalável é dificil e muitas vezes sujeita a erros, podendo gerar inconsistências no Cluster.
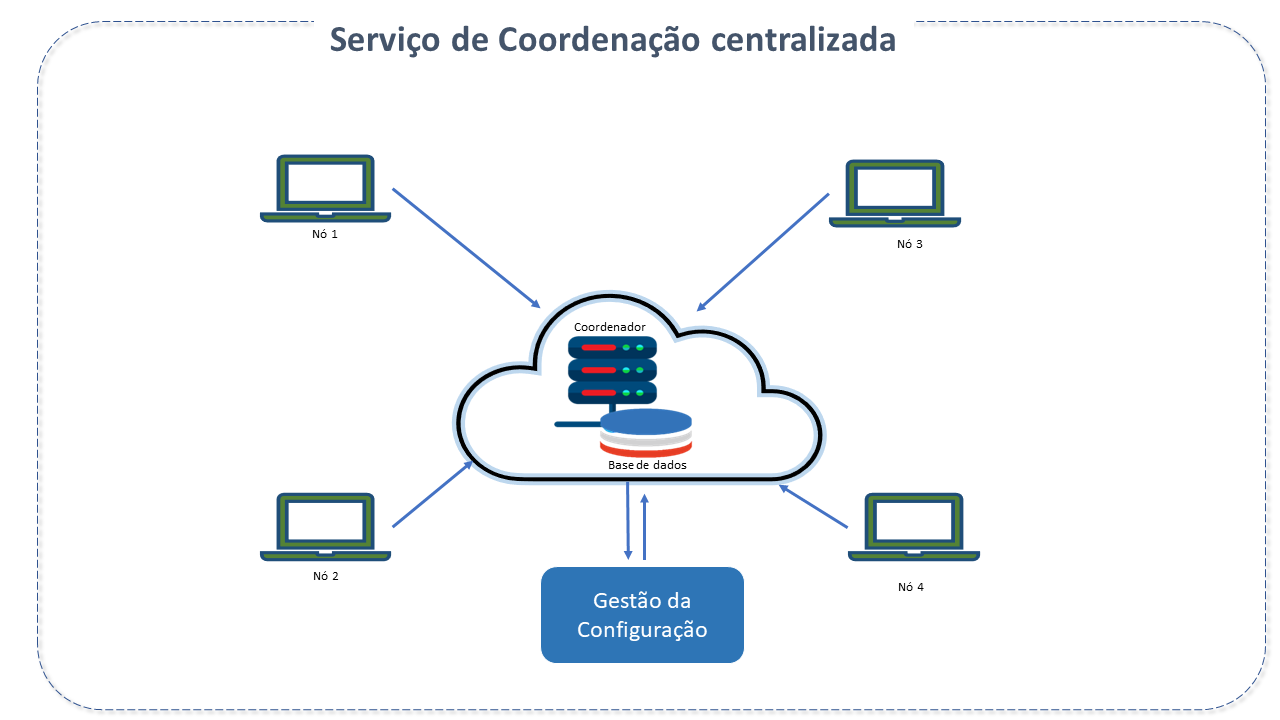
A coordenação centralizada garante a manutenção do "estado" consistente e da performance destes sistemas (como computadores e softwares), evitando alterações não documentadas no ambiente e auxiliando a evitar problemas de desempenho, inconsistências ou conformidade.
Executar essas tarefas manualmente é um trabalho complexo em sistemas grandes, como o Big Data. Pode envolver milhares de componentes para cada aplicativo.
Para isso, existem ferramenta que fornecem um plano e uma versão única e o estado desejado dos sistemas da organização, além de dar visibilidade de quaisquer modificações na configuração, por meio de trilhas de auditoria e rasteamento de alterações.
Características do Apache Zookeeper
Apache Zookeeper é um projeto voluntário de software livre da Apache, originalmente desenvolvido pela YAHOO e, hoje, amplamente utilizado por grandes organizações como a própria Yahoo, Netflix e Facebook(uma lista completa de organizações e projetos que usam o Zookeeper pode ser vista aqui).
Trata-se de um serviço centralizado de código aberto, para coordenação de aplicações distribuídas.
Disponibiliza um conjunto de "primitivas" acessíveis por meio de APIs simples sobre as quais aplicações podem ser construídas a fim de implementar serviços de alto nível, tornando menos complicado(a)s:
-
Operações de associação de Cluster (detecção de saída ou junção de nós).
-
Sincronização distribuída (bloqueios(locks) e barreiras).
-
Nomeação (identificação de nós em um _Cluster pelo nome, semelhante ao DNS).
-
Gerenciamento de configuração (informações de configuração mais recentes e atualizadas do sistema para um nó de junção).
A principal intenção do Apache Zookeeper é permitir que desenvolvedores de aplicativos se concentrem na lógica negocial e confiem inteiramente no Zookeeper para a correta coordenação:
-
Ao contrário dos sistemas de arquivos convencionais, o Zookeeper fornece alto rendimento e baixa latência.
-
Executa em uma coleção de máquinas e foi desenhado para alta disponibilidade, evitando a introdução de pontos de falha em sistemas.
-
A ordem é muito importante. Sua ordenação permite que primitivas de sincronização sofisticadas sejam implementadas no cliente.
Todas as atualizações são ordenadas. Cada atualização é marcada com um número que reflete esta ordem, chamado zxid(Zookeeper Transaction Id_), que é exclusivo para cada atualização.
As leituras (e relógios) são ordenadas em relação às atualizações. As respostas lidas sao carimbadas com o último zxid processado pelo servidor que atende à leitura.
-
Os aspectos de desempenho do Zookeeper permitem que seja usado em grandes sistemas distribuídos.
-
O desempenho e a escalabilidade são alcançados por meio do mecanismo de watches, que permite que clientes se registrem para receber notificações sempre que um znode sofre alguma alteração (criação ou exclusão, mudanças nos dados mantidos pelo znode, criação ou exclusão de um dos filhos na sub-árvore de um _znode).
-
-
Facilita interações com fraco acoplamento.
Arquitetura do Apache Zookeeper
Zookeeper é uma aplicação distribuída e altamente confiável de coordenação centralizada, seguindo o modelo cliente-servidor e operando em um conjunto de servidores replicados, conhecidos como ensemble, similarmente à gestão de serviços como o DNS.
O Zookeeper possui arquitetura simples, com namespace hierárquico padrão (que se assemelha ao filesystem Unix) de registradores de dados, denominados znodes(cada nó da árvore), o que o torna uma solução eficiente para gerenciamento de informações de configuração.
Os clientes são nós que consomem os serviços e os servidores são nós que fornecem os serviços.
Os caminhos para os nós são expressos como caminhos canônicos(de acesso mais curto a um arquivo a partir do diretório raiz), absolutos e separados por barra.
Não há referência relativa.
A principal diferença entre Zookeeper e um sistema de arquivos padrão é que todo znode pode ter dados associados como filhos (todo arquivo pode ser também um diretório e vice-versa), e os znodes são limitados ao volume de dados que possuem.
Zookeeper foi desenhado para armazenar dados de coordenação: informações de status, configuração, informações de localização, etc.
Este tipo de meta-informação é normalmente medido em kilobytes, se não bytes.
Por isso, possui uma checagem de "sanidade" integrada de 1M, para evitar que seja usado como um grande "armazenador" de dados, mas, em geral, é usado para armazenar partes de dados bem menores.
Os principais componentes da arquitetura do Zookeeper são:
-
Clientes, que se conectam ao serviço, a partir de APIs da biblioteca cliente Zookeeper (responsável pela interação de um aplicativo com o serviço Zookeeper), por meio de qualquer membro do Ensemble.
Pode enviar e receber solicitações e respostas, bem como notificações e pulsações(heartbeats), por meio de uma conexão TCP.
Se a conexão for interrompida, o cliente se conectará a um servidor diferente.
Quando se conecta pela primeira vez, o primeiro servidor configurará uma sessão para o cliente.
As solicitações de leitura são processadas localmente no servidor ao qual está conectado e atendidas a partir da réplicas locais de cada banco de dados do servidor.
Se a solicitação registrar uma observação em um znode, esta também será rastreada localmente no servidor.
As solicitações de gravação, que alteram o estado do serviço, são processadas por um protocolo de "agreement" e encaminhadas para outros servidores ZooKeeper. Passam por consenso antes que uma resposta seja gerada.
As solicitações de sincronização também são encaminhadas para outro servidor, mas não passam por consenso.
-
Lider, é o servidor que recupera automaticamente os nós com falhas. Todas as solicitações de gravação dos clientes são encaminhadas ao Lider.
-
Seguidores, são os servidores não-líder, que recebem propostas de mensagens do líder e concordam com a entrega das mensagens.
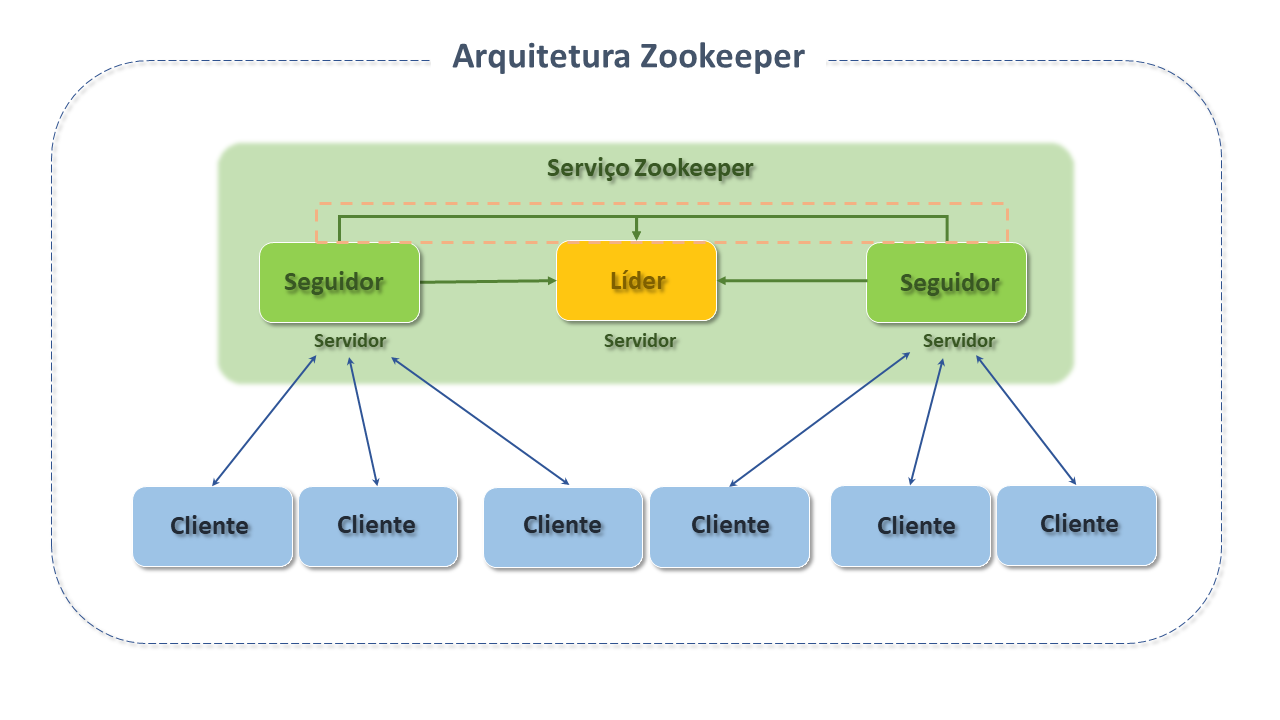
A camada de mensagens cuida da substituição de líderes em caso de falha e da sincronização entre seguidores e líderes.
O Zookeeper usa o protocolo padrão de mensagens atômicas para garantir a consistência dos dados entre os nós em todo o sistema. Isto permite garantir que as réplicas locais nunca divirjam.
Após receber a solicitação de alteração de dados, o líder grava o dado no disco e depois na memória .
Zookeeper segue um modelo de armazenamento compartilhado e hierárquico similar a um sistema de arquivos tradicional. As abstrações providas pelo serviço permitem que os znodes sejam manipulados de forma simples e eficiente.
O serviço Zookeeper é replicado no conjunto de máquinas que o compõem.
Essas máquinas mantém uma imagem in memory da árvore de dados junto com logs de transação e "snapshots"(instantâneos) em um armazenamento persistente. Uma vez que o dado é mantido in memory, alcança alto throughput(taxa de transferência) e baixa latência.
A desvantagem é que o tamanho do banco de dados que o Zookeeper pode gerenciar é limitado pela memória.
Essa limitação é mais um motivo para manter pequena a quantidade de dados armazenados em znodes.
Os servidores que compõem o serviço Zookeeper devem conhecer uns aos outros.
Enquanto a maioria estiver disponível, Zookeeper estará disponível. Os clientes também devem conhecer a lista de servidores, pois criam um identificador para o serviço usando esta lista.
Znodes
O namespace do Zookeeper é composto por registros de dados conhecidos como znodes, similares a arquivos e diretórios.O Znode mantém a estrutura de estatística que inclui numero de versão para mudanças no dado, mudanças ACL, timestamps, para permitir validações de cache e atualizações coordenadas. Cada vez que os dados de um znode muda, o número da versão aumenta.
Existem dois tipos de Znodes :
-
Persistentes: Os Znodes persistentes só deixam de compor o namespace quando são excluídos. Existem para armazenar dados que precisam estar altamente disponíveis e acessíveis por todos os componentes de um aplicativo distribuído.
-
Efêmeros: Os Znode efêmeros são excluidos pelo Zookeeper quando a sessão do cliente termina, o que pode ocorrer por uma desconexão por falha ou um término de conexão. Embora estejam vinculados à sessão do cliente, são visiveis para todos os clientes, dependendo da política de Lista de controle de acesso (ACL) vinculada. Também pode ser excluido pelo cliente criador ou qualquer outro autorizado.
Os znodes efêmeros podem ser usados para construir aplicativos distribuidos nos quais é necessário que os componentes conheçam o estado um dos outros ou de recursos constituintes.
-
Sequenciais: Existe um terceiro nó, apontado por alguns como outro tipo de znode - o sequencial. Entretanto, este znode deve ser entendido como um qualificador dos dois principais.
É atribuído um número de sequencia pelo Zookeeper como parte de seu nome durante sua criação. O valor de um contador, mantido pelo znode pai é anexado ao nome. Estes znodes são usados para implementação de uma fila global distribuída, pois os números de sequência podem impor uma ordenação. Também para projetar um serviço de bloqueio para um aplicativo distribuído.
Boas Práticas com Apache Zookeeper
Coisas a Evitar:
Existem alguns problemas que devem ser evitados por meio de uma correta configuração do Zookeeper:
-
Lista de servidores inconsistente: A lista de servidores Zookeeper usada pelos clientes deve corresponder à lista de servidores Zookeeper que cada servidor Zookeeper possui. A lista cliente tem que ser um subconjunto da lista real. Além disso, as listas de servidores em cada arquivo de configuração dos servidores Zookeeper devem ser consistentes entre si.
-
Posicionamento incorreto do log de transação: A parte mais crítica para o desempenho do Zookeeper é o log de transações. O Zookeeper sincroniza as transações com a mídia antes de retornar uma resposta. Um dispositivo de log de transações dedicado é a chave para um bom e consistente desempenho.
Nunca devemos colocar o log em um dispositivo ocupado, pois isto prejudicará o desempenho. No caso de existir apenas um dispositivo de armazenamento, sugerimos colocar os arquivos de rastreamento no NFS e aumentar o snapshotCount. Isto não elimina o problema, mas pode mitigá-lo.
-
Swap para o disco:
-
É necessário um cuidado especial na configuração do tamanho do heap java. Deve ser evitada a situação em que Zookeeper realize swap para disco. Tudo é ordenado e, portanto, se o processamento de uma solicitação "trocar" de disco, todas as outras solicitações na fila provavelmente farão o mesmo.
-
É recomendável ser conservador em estimativas: Com 4G de RAM, um tamanho máximo de heap do Java não deve ultrapassar 3G, por exemplo, pois o sistema operacional e o cache também precisam de memória.
-
A melhor prática é a execução de testes de carga, mantendo a garantia de estar bem abaixo do limite que poderia causar o swap.
-
O monitoramento de sistema como vmstat pode ser usado para monitorar estatisticas de memoria virtual e decidir sobre o tamamho ideal de memória dependendo das necessidades do aplicativo. Em qualquer caso, sempre evitar o swap.
-
Coisas a fazer:
-
É recomendável limpar o diretório de dados do Zookeeper periodicamente, caso a opção de autopurge não esteja habilitada. Este diretório contém o snapshot e os arquivos de log transacionais.
+ Além disso, é importante avaliar a necessidade de backup, que, sendo o Zookeeper um serviço replicado, só é necessário em um dos servidores do conjunto.
-
Zookeeper usa o Apache log4j como infraestrutura de registro. É recomendável definir o rollover automático usando o recurso Log4j embutido para logs do Zookeeper, à medida que os arquivos de log crescem.
Linguagem do Zookeeper
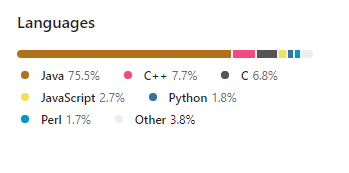
O Zookeeper é implementado em Java, e oferece interfaces (bindings) para várias outras linguagens de programação como C, Java, Perl e Python.
A lista completa de ligações-cliente disponíveis na comunidade pode ser acessada aqui.
Fontes: