Apache Spark
Computação Distribuída
Com a evolução das redes de computadores, um novo paradigma computacional surgiu e se tornou extremamente poderoso: a possibilidade de distribuição do processamento entre computadores diferentes.
A computação distribuída permite a repartição e especialização das tarefas computacionais, segundo natureza e função de cada computador.
Este paradigma surgiu para solucionar um grande problema da computação, que é a necessidade de computadores com poder de processamento suficiente para realizar análise do grande volume de dados disponíveis atualmente.
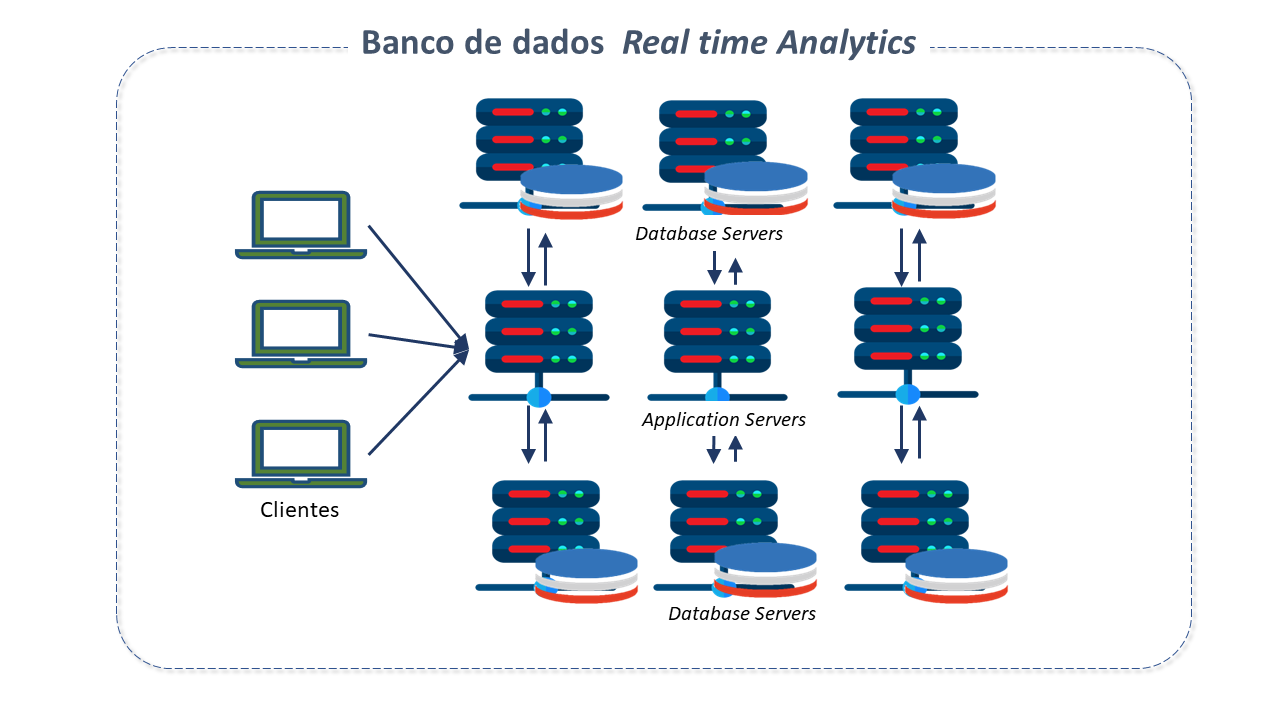
Características do Apache Spark
O Apache Spark é um mecanismo de análise unificada para processamento de dados em larga escala em computação distribuída.
Criado em 2009 na Universidade da Califórnia pelo AMPLab de Berkeley, o Spark rapidamente ganhou uma grande comunidade, levando à sua adoção pela Apache Software Foundation em 2013.
Desenvolvedores de mais de 300 empresas auxiliaram na sua implementação, e uma vasta comunidade com mais de 1.200 desenvolvedores de centenas de organizações continuam a contribuir para seu contínuo refinamento.
É usado por organizações em uma gama de setores e sua comunidade de desenvolvedores é uma das maiores existentes.
O poder do Spark vem de seu processamento in-memory.
Ele usa um conjunto distribuído de nós com muita memória e codificação de dados compacta(data-encoding), juntamente com um query planner(planejador de consultas) otimizado para minimizar o tempo de execução e a demanda por memória.
Como realiza cálculos in-memory, pode processar até 100 vezes mais rápido do que as estruturas que processam no disco.
É ideal para processar grandes volumes de dados em Analytics, training models para machine learning e AI.
Adicionalmente, o Spark executa uma pilha de bibliotecas nativas de aprendizagem de máquina e processamento de gráficos e estruturas de dados SQL-like, permitindo um desempenho excepcional.
Conta com mais de 80 operadores de alto nível, facilitando a criação de aplicativos paralelos.
O Spark guarda algumas semelhanças com o HADOOP. Ambos são estruturas de código aberto para processamento de dados analíticos, vivem na Apache Software Foundation, contém bibliotecas de aprendizado de máquina, podendo ser programados em várias linguagens diferentes.
No entanto, Spark estende o número de cálculos possíveis com o HADOOP, aprimorando o componente de processamento de dados nativo do HADOOP, o MapReduce.
O Spark usa a infraestrutura do Hadoop Distributed File System (HDFS), mas melhora suas funcionalidades e fornece ferramentas adicionais, como, por exemplo, a implementação de aplicativos em Cluster Hadoop (com SIMR - Spark Inside MapReduce) ou YARN.
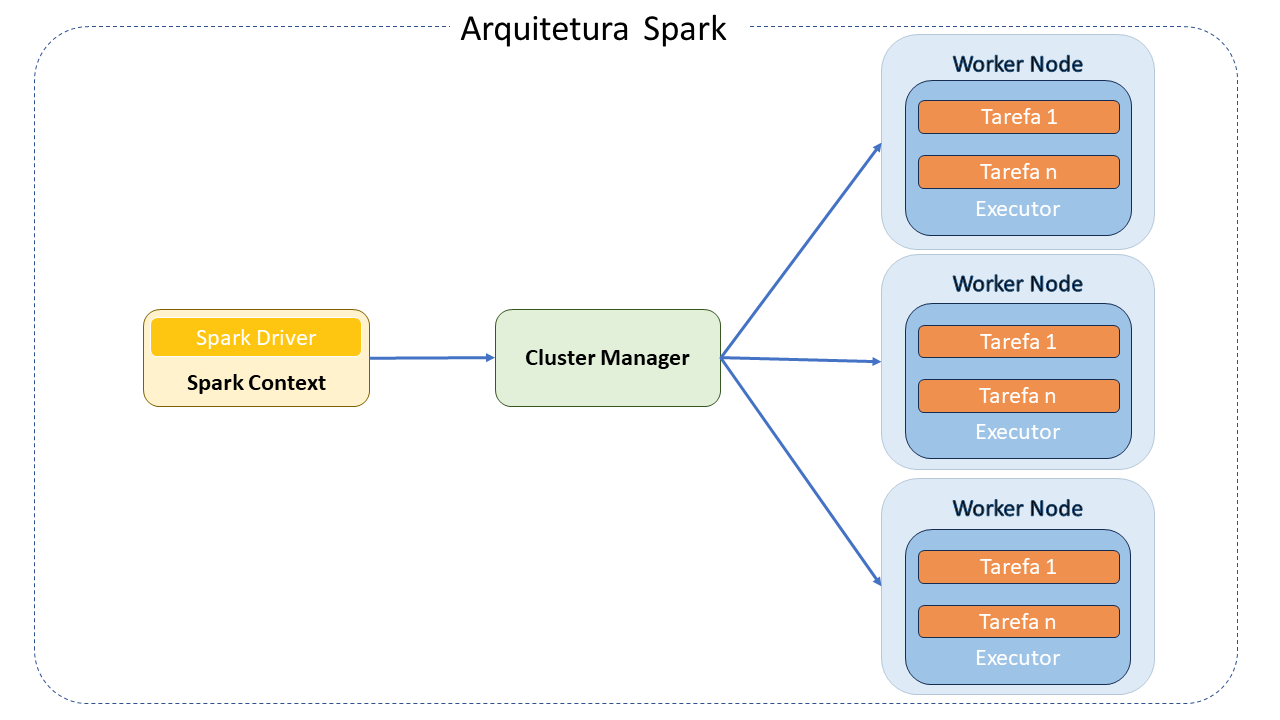
Arquitetura do Apache Spark
Apache Spark é um "engine" de processamento distribuído que trabalha com o principio coordenador/trabalhador.
Sua arquitetura consiste nos seguintes componentes principais:
-
Spark Driver: É o mestre da arquitetura Spark. É a aplicação principal que gerencia a criação e que executará o processamento definido pelo programador.
-
Cluster Manager: É um componente opcional somente necessário se a execução do Spark for de forma distribuída. É responsável por administrar as máquinas que serão utilizadas como workers.
-
Spark Workers: São as máquinas que efetivamente executam as tarefas enviadas pelo Programa Driver. Se o Spark for executado de forma local, a máquina pode desempenhar tanto o papel de Driver como de Worker.
Componentes fundamentais do modelo de programação Spark:
-
Resilient Distributed Datasets (RDD): É o objeto principal do modelo de programação Spark. É nestes objetos que os dados são processados. Armazenam os dados na memória para realizar várias operações como a carga, transformação e ações(cálculos, gravações, filtros, uniões e map-reduce) nos dados. Abstraem um conjunto de objetos distribuídos no Cluster, geralmente executados na memória principal. Podem estar armazenados em sistemas de arquivo tradicional, no HDFS e em alguns Bancos de Dados NoSQL, como o HBase.
-
Operações: Representam transformações (agrupamentos, filtros, mapeamento de dados) ou ações (contagens e persistências), realizadas em um RDD. Um programa Spark normalmente é definido como uma sequência de transformações ou ações realizadas em um conjunto de dados.
-
Spark Context: O contexto é o objeto que conecta o Spark ao programa que está sendo desenvolvido. Pode ser acessado como uma variável em um programa.
Bibliotecas do Apache Spark
Além das APIs, existem bibliotecas que compõem seu ecossistema e fornecem capacidades adicionais:
-
Spark Streaming: Pode ser usado para processar dados de streaming em tempo real baseado na computação de microbatch. Para isso utiliza o DStream, que é basicamente uma série de RDD para processar os dados em tempo real. É escalável, possui alto throughput, tolerante a falhas e suporta Workloads batch ou streaming.
O Spark Streaming permite a leitura/gravação a partir/para o topic Kafka no formato texto, csv, avro e json.
-
Spark SQL: Fornece a capacidade de "expor" os conjuntos de dados Spark por meio de uma API JDBC. Isto permite a execução de consultas no estilo SQL sobre esses dados, fazendo uso de ferramentas tradicionais de BI e visualização. Além disso, permite a utilização de ETL para extração de dados em diferentes formatos (Json, Parquet ou Banco de dados), e transformá-los e expô-los para consultas ad-hoc.
-
Spark MLlib: É a biblioteca de aprendizado de máquina do Spark, que consistem em algoritmos de aprendizagem, incluindo a classificação, regressão, clustering, filtragem colaborativa e redução de dimensionalidade.
-
Spark GraphX: É uma nova API do Spark para grafos e computação paralela. Simplificando, estende o Spark RDD para grafos. Para apoiar a computação de grafos, expõe um conjunto de operadores fundamentais (subgrafos e vértices adjacentes), bem como uma variante otimizada do Pregel. Além disso, inclui uma crescente coleção de algoritmos para simplificar tarefas de análise de grafos.
-
Variáveis compartilhadas: O Spark oferece dois tipos de variáveis compartilhadas para torná-lo mais eficiente na execução em Clusters:
-
Broadcast: são variáveis read only que são armazenadas em cache em todos os nós do Cluster para acesso ou uso por tarefas. Em vez de mandar o dado junto com cada tarefa, o Spark distribui as variáveis broadcast(de transmissão) na máquina usando algoritmos eficientes broadcast para reduzir custos de comunicação.
-
Accumulator(acumuladoras): São variáveis compartilhadas apenas adicionadas por meio de uma operação associativa e comutativa que são usadas para executar contadores (similar aos contadors Map Reduce) ou operações de soma.
-
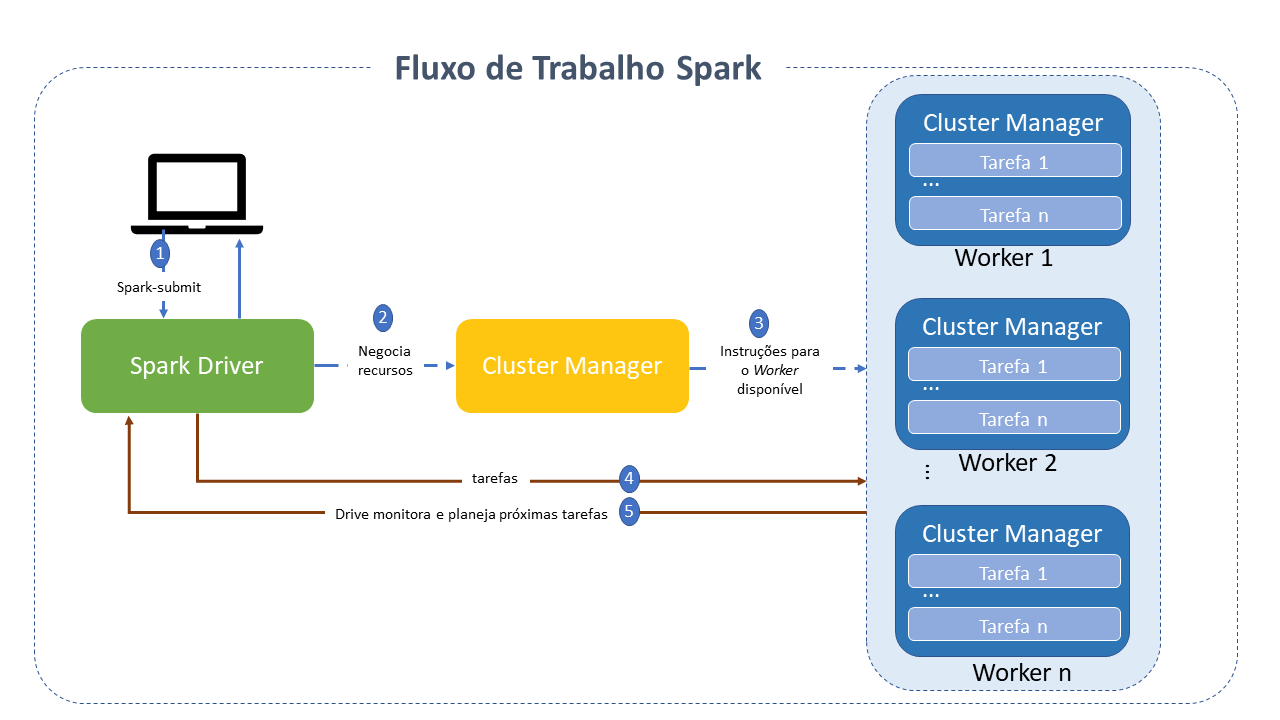
Fluxo de trabalho do Apache Spark
Seu ciclo de vida envolve vários passos intermediarios e cada um é responsavel por conduzir responsabilidades específicas.
-
O processo se inicia com a submissão do job pelo cliente, por meio da opção spark-submit .
-
A classe main, especificada durante a submissão do job é chamada e o programa Spark driver é iniciado no nó master, responsável por gerenciar o ciclo de vida do aplicativo.
-
O programa driver solicita recursos do Cluster manager para iniciar os Executores baseado na configuração do aplicativo.
-
O Cluster manager ativa o executor no worker node em nome do driver Spark, que agora assume a propriedade do ciclo de vida do aplicativo.
-
O driver Spark cria uma DAG baseado no RDD. A tarefa é então dividida em etapas. O driver Spark envia as tarefas para o executor que as executa.
-
O executor envia uma solicitação de conclusão da tarefa ao driver por meio do Cluster manager. Depois que todas as tarefas forem concluídas em todos os executores, o driver envia um status de conclusão do Cluster manager.
Outras características do Apache Spark
-
O Spark pode acessar fontes de dados variáveis e executar em várias plataformas, incluindo o HADOOP.
-
Fornece APIs funcionais de alto nível em Java, Scala, Python e R para:
-
manipulação de dados em escala
-
armazenamento em cache de dados in memory
-
reutilização de datasets
-
-
Suporta vários formatos e conjuntos de APIs para lidar com qualquer tipo de dado no modo distribuído.
-
Oferece, ainda, um mecanismo otimizado com suporte a gráficos de execução geral.
-
Utiliza o conceito de direct acyclic graph (DAG), por meio do qual é possível desenvolver pipelines compostos por várias etapas complexas.
-
A capacidade de armazenamento de dados in-memory e processamento near real-time torna o Spark mais rápido que o framework MapReduce e provê uma vantagem para casos de uso iterativos onde o mesmo dataset é usado múltiplas vezes em diferentes execuções.
Boas práticas para Apache Spark
-
Uso do Dataframe/Dataset_sobre RDD(resilient distributed dataset): O RDD serializa e desserializa sempre que distribui os dados entre _Clusters. Estas operações são muito caras.
Por outro lado, o Dataframe armazena os dados como binários, usando armazenamento off-heap(fora da pilha), sem a necessidade de serialização e desserialização de dados na distribuição para Clusters, tornando-se uma grande vantagem em relação ao RDD.
-
Uso do Coalesce: Sempre que for necessário reduzir o número de partições, use o coalesce, pois ele faz o movimento mínimo de dados sobre a partição. Por outro lado, o repartition recria toda a partição tornando a movimentação de dados muito alta.
Para aumentar o número de partições, temos que usar o repartition.
-
Uso de formatos de dados serializados: Geralmente, seja um job de streaming ou em lote, o Spark grava os resultados calculados em algum arquivo de saída e outro job do Spark o consome, faz alguns cálculos e grava novamente em algum arquivo de saída.
Nesse cenário, usar um formato de arquivo serializado, como Parquet, nos dá uma vantagem significativa sobre os formatos CSV e JSON.
-
Evitando funções definidas pelo usuário: Use as funções pré-construídas do Spark sempre que possível. As funções UDF(User Defined function) são uma caixa preta para o Spark e isto o impede de aplicar otimizações. Perdemos, desta forma, todos os recursos de otimização oferecidos pelo Dataframe/Dataset Spark.
-
Dados da memória em Cache: Sempre que fazemos uma sequência de transformações do Dataframe e precisamos usar um Dataframe intermediário repetidamente para cálculos adicionais o Spark fornece um recurso para armazenar DF especifico na memória na forma de um cache.