Apache HBase
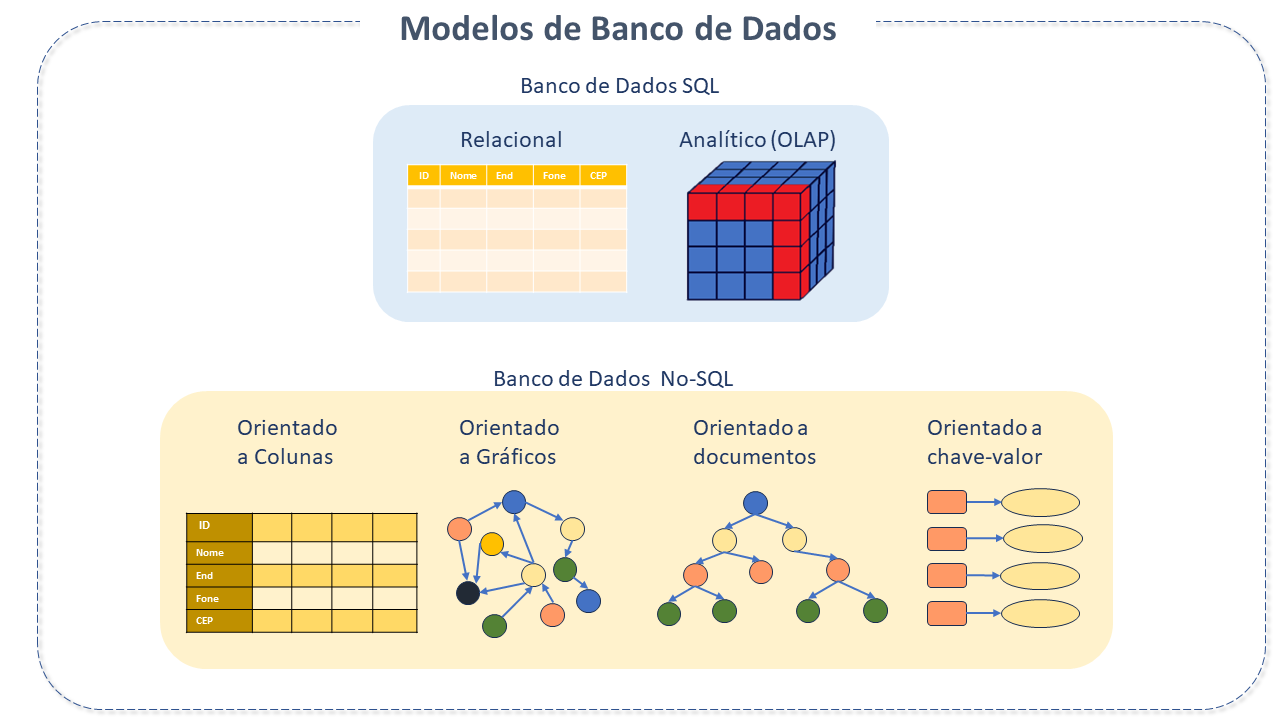
Banco de Dados NoSQL
O Modelo NoSQL("no SQL" ou "not only SQL") representa bancos de dados não relacionais (ou não somente relacionais, conforme definições mais recentes). Trata-se de uma classe de banco de dados que fornece mecanismos de armazenamento e recuperação de dados modelados de formas diferentes das relações tabulares usadas pelos bancos de dados relacionais.
Estes bancos de dados existem desde a década de 1960, mas alcançaram popularidade na década de 2000, desencadeada pelas necessidades de empresas como Facebook, Google e Amazon.com. São cada vez mais usados em Big Data e aplicações Web de tempo real.
Os Bancos de dados NoSQL podem suportar linguagens de consulta similares à SQL.
Características do Apache HBase
HBase é um banco de dados distribuído, de código aberto, não-relacional ("NoSQL"), Colunar (orientado a colunas), que "executa sobre" o HDFS, criado para fornecer acesso aleatório eficiente e leitura/gravação em tempo real em grandes conjuntos de dados distribuídos.
Foi criado pela empresa Powerset, para hospedar tabelas muito grandes e , posteriormente, absorvido pela Fundação Apache como parte do Projeto HADOOP, tornando-se uma ótima opção para combinar e armazenar dados multi-estruturados e esparsos.
O HBase está integrado nativamente com o HADOOP e funciona perfeitamente ao lado de outros "motores" de acesso a dados, através do YARN. Possui muitos recursos que suportam escalabilidade linear e modular.
Seus Clusters se expandem pela adição de RegionServers que são hospedados em servidores "commodity class" (hardware comum). Se um Cluster se expande de 10 para 20 RegionServers, por exemplo, ele dobra sua capacidade de armazenamento e processamento.
Suas principais características são:
-
Leitura e gravação consistentes: O HBase é um DataStore consistente, o que o torna muito adequado para tarefas como high speed counter aggregation.
-
"Fragmentação" automática: As tabelas HBase são distribuídas no Cluster via Regions(regiões), e estas regiões são automaticamente divididas e redistribuidas à medida que os dados "crescem".
-
Tolerância à falhas (failover) automática do RegionServer: Os dados de entrada "residem" em regiões disponibilizadas pelos RegionServers . Se um RegionServer falhar, o servidor mestre designará outro para assumir as regiões que foram tratadas pelo RegionServer com falha.
-
Integração HADOOP/HDFS: HBase suporta HDFS "out of the box"(pronta para uso) como seu sistema de arquivos distribuídos.
-
Suporte ao MapReduce: O HBase oferece suporte a processamento fortemente paralelizado via MapReduce, atuando tanto como fonte quanto como coletor.
-
API Java Client: HBase suporta API Java "easy to use" para acesso programático.
-
API Thrift/REST: HBase suporta Thrift e REST para "front-ends" não-Java.
-
Block-cache e Bloom Filters: HBase oferece suporte para high volume query otimization .
-
Gerenciamento Operacional: HBase provê Web pages integradas para percepção operacional e métricas JMX.
-
Alta disponibilidade: HBase provê alta disponibilidade com:
-
Informações de topologia de Cluster altamente disponíveis através de implantações de produção com múltiplas instâncias HMaster e Zookeeper.
-
Distribuição de dados em vários nós garantindo que a perda de um único nó afete somente os dados armazenados nesse nó.
-
HBase HA permite o armazenamento de dados, garantindo que a perda de um único nó não resulte na perda de disponibilidade de dados.
-
O formato HFile armazena dados diretamente no HDFS e pode ser lido ou escrito por Apache Hive, Apache PIg, MapReduce e Apache Tez, favorecendo análises profundas no HBase sem movimentação de dados.
-
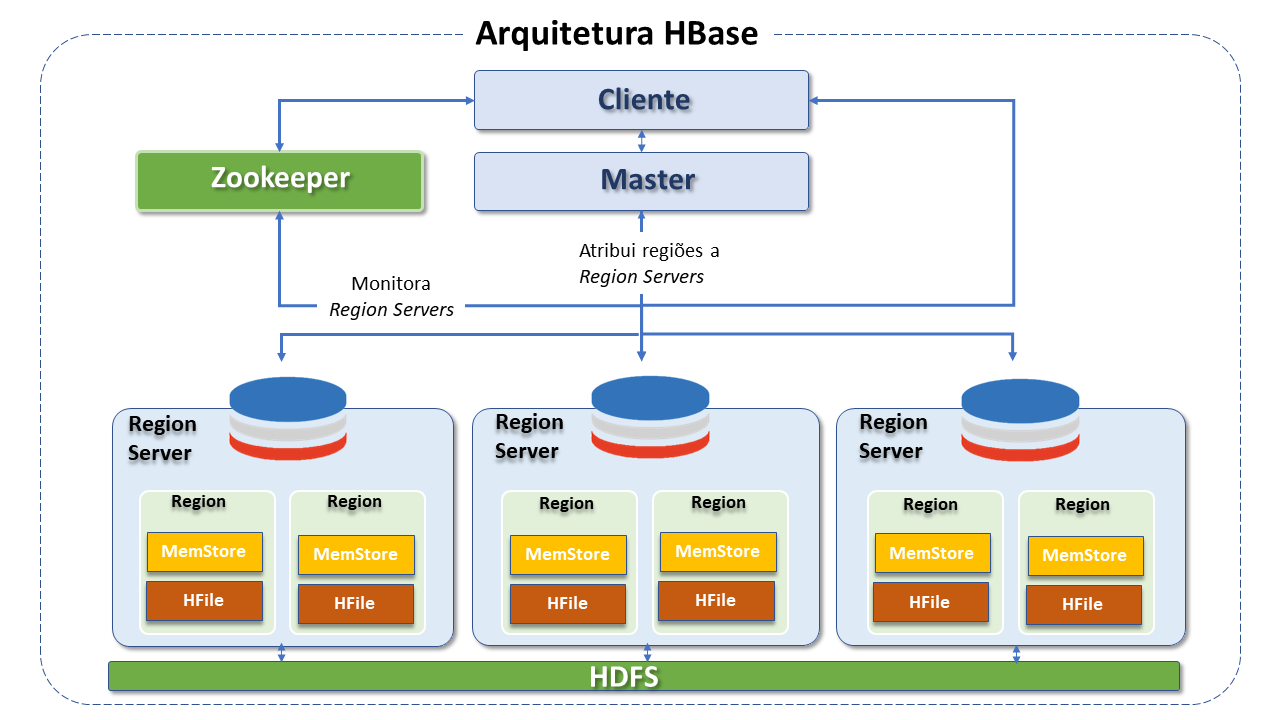
Arquitetura do Apache HBase
A arquitetura do HBase também segue o modelo mestre/escravo e é formada por três componentes principais:
-
HMaster(Servidor mestre): É um processo responsável por designar regiões para Region Servers no Cluster HADOOP para balanceamento de carga. É responsável pela monitoração de todas as instâncias de Region Server no Cluster HBase, e age como uma interface para todas as mudanças de metadados.
O master tipicamente é executado em um servidor dedicado, dentro do cluster HADOOP.
Existem outros masters em standby disponíveis para substituição em caso de indisponibilidade e o Zookeeper cuida disso.
É possível que o master fique inativo por algum tempo e é possível o Cluster HADOOP trabalhar sem ele durante este período, mas é sempre bom reativar o master o mais breve possível, porque ele conduz algumas funcionalidades criticas como: Gerenciamento e monitoramento do Cluster HADOOP; Controle do failover Atribuição de regiões aos Region Servers , com apoio do Zookeeper. Balanceamento de carga das regiões entre os Region Servers. Alterações de esquema e outras operações de Metadados. Operações DDL, como criação e exclusão de tabelas. -
Regionservers(Servidores de região): Os Region Servers mantém as múltiplas regiões designadas pelo HMaster. Várias regiões são combinadas em um único RegionServer.
São responsáveis pela comunicação cliente e por executar todas as operações relacionadas a dados. Qualquer requisição de leitura ou gravação para as regiões são conduzidas pelo Region Server.
O Region Server é implementado pelo HRegionServer e executa em todo nó de dados no Cluster HBase. É composto pelos seguintes componentes:
-
Write-Ahead Log (WAL): O WAL(registro de gravação antecipada) registra todas as alterações de dados do HBase. Em uma situação normal, ele não é necessário, pois as mudanças de dados são movidas do MemStore para os StoreFiles Entretanto, se um RegionServer travar ou ficar indisponível antes que o MemStore seja liberado, o WAL garante que as mudanças possam ser repetidas. Se a gravação no WAL falhar, toda a operação falha.
O WAL é anexado a cada Region Server. Usualmente, existe apenas uma única instância de WAL por Region Server. A exceção é o RegionServer que carrega a tabela HBase:meta. A tabela tem seu próprio WAL dedicado.
-
Block Cache: O Block Cache reside no Region Server e é responsável pelo armazenamento de dados acessados com frequência, na memória, auxiliando no incremento da performance. O Block Cache segue o conceito least recently used(LRU), em que registros menos utilizados recentemente serão removidos.
-
MemStore: É um cache de gravação. Uma memória temporária para todos os dados de entrada. Responsável por armazenar dados ainda não gravados no disco. Existem múltiplos MemStores no Cluster HBase.
-
HFile: São os arquivos ou células nos quais são armazenados os dados. Quando o MemStore está cheio, grava dados no HFile, no disco.
-
-
Regions: São o elemento basico de disponibilidade e distribuição de tabelas. São compostos por uma Column Family. Tabelas HBase são divididas por intervalos row key nas regiões.
Todas as linhas entre region start key e region end key estarão disponíveis na região. Cada região é designada para um region server , que gerencia as solicitações leitura/gravação para esta região.
Como regiões são blocos básicos de escalabilidade no HBase, é recomendado um baixo número de regiões por Region Server para garantir alta performance.
A arquitetura HBase usa um processo de fragmentação automática para manter os dados. Neste processo, sempre que uma tabela HBase fica muito longa, é distribuída pelo sistema com o auxílio do HMaster.
-
Zookeeper: O Zookeeper realiza a coordenação distribuída, provendo regiões para os Region Servers e também recuperando regiões, no caso de falha do Region Server , carregando-as em outros Region Servers. Se um cliente deseja compartilhar ou permutar com regiões, precisa abordar o Zookeeper antes.
O serviço HMaster e todos os Region Servers são registrados com o serviço ZooKeeper.
O Cliente acessa o ZooKeeper para conectar-se com Region Servers e HMaster. Em caso de falha em um nó do Cluster HBase, o ZKquoram do Zookeeper ativará mensagem de erro e iniciará o repaire failed nodes.
O serviço ZooKeeper mantém e acompanha todos os Region Servers no Cluster HBase e coleta informações como número de Region Servers , datanodes designados, etc. É também responsável por estabelecer a comunicação cliente com Region Servers , mantendo o controle de falhas de servidor e partições de rede, informações de configuração, etc.
Como o Apache HBase funciona
HBase escala linerarmente, exigindo que todas as tabelas tenham uma chave primária. O espaço da chave está dividido em blocos sequenciais que são, então, atribuídos a uma região.
Os RegionServers possuem uma ou mais regiões, de modo que a carga seja distribuída uniformemente em todo o Cluster. Se as chaves dentro de uma região são frequentemente acessadas, o HBase pode subdividir a região de modo que o corte manual de dados não seja necessário.
Os servidores do Zookeeper e HMaster disponibilizam informações sobre a topologia de Cluster aos clientes. Os clientes se conectam a estes e baixam:
-
a lista de RegionServers,
-
as regiões contidas nesses RegionServers e
-
os intervalos de chaves hospedados pelas regiões.
Como os clientes sabem exatamente onde está cada informação no HBase, podem entrar em contato diretamente com o RegionServer sem necessidade de um "coordenador central".
Regionserver inclui uma memstore para armazenar em cache as linhas frequentemente acessadas na memória.
Modelo de Dados HBase
No HBase os dados são armazenados em tabelas (tables), que possuem linhas e colunas, podendo, sua estrutura, ser entendida como um mapa multidimensional.
Seus principais componentes são:
-
Tabelas: Como a arquitetura HBase é orientada a colunas, os dados são armazenados em tabelas que estão no formato tabular. Estas tabelas são declaradas antecipadamente no momento da definição do "esquema". Uma tabela consiste em várias linhas.
-
Rowkey: Uma linha no HBase corresponde a uma Rowkey e uma ou mais colunas com valores associadas a ela. As linhas são classificadas alfabeticamente pela RowKey à medida em que são armazenadas. O Objetivo da Rowkey é armazenar dados de forma que as linhas relacionadas fiquem próximas umas das outras.
-
Colunas: Uma coluna no HBase consiste em uma família de colunas (column_family) e um qualificador de coluna delimitados por um caractere ":"(dois pontos). São os diferentes atributos do dataset. Cada Rowkey pode ter um número ilimitado de colunas.
-
As colunas não são definidas previamente na estrutura, como no Banco de Dados Relacional.
-
Não é obrigatório que todas as colunas estejam presentes em todas as linhas.
-
As colunas não armazenam valores nulos.
-
Todas as colunas de uma Column Family são armazenadas juntas num arquivo (HFile) juntamente com a Rowkey.
-
-
Column Family: São o agrupamento de várias colunas. Uma simples requisição de leitura a uma column family dá acesso a todas as colunas daquela familia, tornando rápida e fácil a leitura do dado. Uma tabela deve ter pelo menos uma Column Family, que é criada com a tabela.
-
Qualificadores de coluna (Column Qualifiers): São como títulos das colunas ou nomes de atributos em uma tabela normal. Um qualificador de colunas é adicionado a uma column family para fornecer o índice para um determinado dado.
-
Célula: É uma combinação entre linha, column family e qualificador de coluna e contém um valor e um _timestamp, que representa a versão do valor.
-
Timestamp: O dado é armazenado no modelo de dados HBase com um Timestamp. O Timestamp é escrito ao lado de cada valor e é o identificador para uma determinada versão do valor. Por padrão, o registro de data e hora representa a hora no RegionServer quando os dados foram gravados, mas isto pode ser configurado ao colocar os dados na célula.
Namespace:
Consiste de um agrupamento lógico de tabelas análogas a um Banco de Dados em sistemas de SGBD relacionais. Essa abstração estabelece as bases para recursos de multilocação:
-
Gerenciamento de cotas : restringindo a quantidade de recursos (regiões, tabelas) que um namespace pode consumir.
-
Administração de segurança: fornecendo outro nível de gestão de segurança para "locatários".
-
Grupos de Region Servers: uma tabela/namespace pode ser fixado(a) em um subset de RegionServers, garantindo um certo nivel de isolamento.
-
Administração da Segurança do Namespace Um Namespace/table pode ser fixado em um subconjunto de RegionServers, garantindo isolamento.
Operações do Modelo de Dados:
Como todo database, o HBase suporta um conjunto de operações básicas referenciadas como CRUD (Criação, Exclusão, leitura e atualização).
Versões
Uma tupla {linha,coluna,versão} especifica uma célula. É possível haver um número de células ilimitado, onde a linha e colunas são as mesmas mas o endereço da célula difere em sua dimensão versão.
Joins
HBase nao suporta joins(junções) na forma como os RDBMS. As leituras do HBase são Get e Scan. Para viabilizar o join, existem duas estratégias:
-
Desnormalizar os dados ao gravar no Hbase.
-
Ter tabelas de pesquisa e fazer a junção entre as tabelas HBase e um aplicativo ou código MapReduce.
A melhor estratégia depende do que se deseja fazer.
HBase e Design do Schema
Projetar um Schema para Bigtable é diferente de projetar um schema para o banco de dados relacional.
No Bigtable, um esquema é um blueprint ou modelo de uma tabela, incluindo a estrutura dos componentes da tabela a seguir:
-
Rowkeys
-
Grupos de Colunas (incluindo as políticas de coleta de lixo)
-
Colunas
Os principais conceitos que se aplicam ao design do Schema em Bigtable são:
-
Bigtable é uma armazenamento de chave/valor, não um armazenametno relacional. Ele não é compativel com "mesclagens" e as transações são compatíveis apenas com uma única linha.
-
Cada tabela possui apenas um índice: a rowkey. Não há indices secundários. Cada rowkey precisa ser única.
-
As linhas são classificadas lexicograficamente por rowkey, da string que tem menos bytes para a que tem mais.
-
Os grupos de colunas não são armazenados em alguma ordem específica.
-
As colunas são reunidas por grupo e classificadas em ordem lexicográfica dentro desse grupo.
-
A intersecção de uma linha e coluna pode contér várias células com timestamp de data/hora. Cada célula contém uma versão exclusiva e com timestamp dos dados para essa linha e coluna.
-
Todas as operações são atômicas no nível da linha. Uma operação afeta uma linha inteira ou nenhuma linha.
-
O ideal é leituras e gravações distribuídas por igual pelo espaço da linha de uma tabela.
-
As tabelas do Bigtable são esparsas. Uma coluna não ocupa espaço em uma linha que não usa a coluna.
A comunidade Hbase indica, para tratar este assunto, o site práticas e recomendações de criação de esquema para maiores detalhes.
Recursos do Apache HBase
-
Segurança no Apache HBase
-
Segurança da Interface para o Usuário Web: HBase provê mecanismos para assegurar vários componentes e aspectos e no seu relacionamento com a infraestrutura Hadoop, bem como clientes e recursos externos ao Hadoop.
-
Segurança do acesso pelo cliente ao Apache HBase: As versões mais recentes do Apache HBase suportam autenticação opcional SASL de clientes. A comunidade recomenda a leitura do artigo Understanding User Authentication and Authorization in Apache HBase: para maiores detalhes.
-
Segurança no nível de transporte A partir da versão 2.6.0 o HBase suporta criptografia TLS na comunicação entre o cliente-servidor e _Master-RegionServer_. TLS é um protocolo criptografico padrão desenhado para prover segurança de comunicações entre redes de computadores.
-
Segurança no acesso ao HDFS e Zookeeper: O HBase requer Zookeeper e HDFS seguros impedir o acesso ou modificação de metadados e dados. HBase use o HDFS para manter seus arquivos de dados, _write ahead logs_(WALs) e outros dados. E usa Zookeeper para armazenar algums metadados para operações (endereço master, lock de tabelas, recuperações, etc.)
-
Segurança no acesso aos dados do cliente: A segurança dos dados do cliente também deve ser considerada. Algumas estratégias são oferecidas para isto:
-
Role-based Access Control (RBAC - controle de Acesso baseado em papéis): Onde usuários e grupos podem ler e gravar em um recurso específico ou executar um endpoint coprocessor, usando o paradigma de papéis.
-
Labels de visibilidade que viabilizam a rotulação de células e controle de acesso às células rotuladas, visando restringir quem pode ler e gravar em determinado subconjunto de dados.
-
Criptografia transparente de dados em repouso no sistema de arquivos subjacente, tanto HFiles quanto Wal, protegendo dados em repouso de uma invasão.
-
-
-
Inmemory compaction(Compactação na memória): A compactação na memória (Aka Acordion) é um novo recurso do HBase - 2.0.0. Foi introduzido pela primeira vez no Blog Accordion:HBase respira com compactação na memória.
-
RegionServer Offheap Read-Write Path (Caminho de leitura e gravação "fora da pilha" RegionServer) Para ajudar a reduzir as latências de RPC P99/P999, o Hbase 2.x fez com que o caminho de leitura e gravação usasse um pool de buffers offheap. As células são alocadas na memória offheap, fora do alcance do garbage collector(coletor de lixo) JVM com redução na pressão do Gc.
-
Backup e Restore: O Backup e Restore do HBase provê a habilidade de criar backups full e incremental em tabelas do Cluster HBase.
-
Replicação síncrona: A replicação no HBase é assincrona. Portanto, se o _Cluster_ Master falhar, o Cluster escravo pode não ter os dados mais atuais. Para garantir consistência o usuário não poderá alternar para o Cluster escravo.
-
APIs: Além das APIs nativas, o HBase suporta APIs externas.
-
Coprocessors:(Co-processadores) O framework de Co-processadores fornecem mecanismos para executar códigos customizados diretamente nos RegionServers que gerenciam o dado.
Quanto usar o Apache HBase
O Apache HBase não é adequado para todas as situações.
-
É um bom candidato apenas para situações com um grande volume de dados. Para pequenos e médios volumes de dados, os RDBMS tradicionais podem ser melhores, pois seus dados podem se concentrar em um ou dois nós.
-
Não possui tantos recursos extras quantos os RDBMS (colunas digitadas, índices secundários, transações, linguagens avançadas de consulta, etc.).
-
Necessita de estrutura de Hardware adequada. Mesmo o HDFS não funciona bem com menos que 5 DataNodes e 1 NameNode.
Diferença entre Apache HBase e HDFS
HDFS é um sistema de arquivos distribuídos adequado para armazenamento de grandes arquivos. Entretanto, não é um sistema de arquivos de uso geral e não fornece pesquisas rápidas de registros individuais em arquivos.
O HBase, por sua vez, é construído sobre o HDFS e fornece pesquisas rápidas de registros (e atualizações) para grandes tabelas. O HBase, internamente, dispõe seus dados em StoreFiles indexados do HDFS para pesquisas de alta velocidade.
Boas Práticas para o Apache HBase
-
Como as linhas do HBase são classificada lexigraficamente por chave de linha (processo que otimiza as varreduras, permitindo que sejam armazenadas linhas relacionadas próximas umas das outras), quando mal projetadas, as chaves de linha podem ser uma fonte de hotspotting (quando uma grande quantidade de tráfego do cliente é direcionada para um nó ou apenas alguns nós, sobrecarregando uma única (ou poucas) máquinas).
É recomendável projetar padrões de acesso a dados, de forma que o Cluster seja utilizado total e uniformemente.
Para evitar pontos de acesso nas gravações, é importante projetar chaves de linha de forma que estas estejam na mesma região quando realmente precisam, mas, no quadro geral, os dados sejam gravados em várias regiões do Cluster.
A Comunidade sugere algumas técnicas para evitar o hotspotting, que podem ser vistas aqui.
-
Seleção de número de Regiões: Na criação de tabelas, no HBase, é possível definir explicitamente o número de regiões para a tabela ou o HBase calculará baseado em um algoritmo. É uma boa prática definir o número de regiões para a tabela e isto auxilia, inclusive, na melhoria de performance .
-
Escolher o número de column family: Quase sempre, temos uma row key e uma column family mas algumas vezes podemos ter mais de uma column family. É boa prática manter o menor número possível de column family e nunca ultrapassar o número de 10 .
-
Balanced Cluster: Um Cluster HBase é considerado "balanceado" quando a maioria dos Region Server tem um número igual de regiões. Você pode desejar ativar o balancer, que balanceará os Clusters a cada 5 minutos.
-
Evitar execução de outro job no Cluster HBase: Os frameworks de integração utilizados para configurar o HBase vêm com outras ferramentas como Hive, Spark, etc. Entratanto, o HBase consome, de forma intensiva, CPU e memória, e, esporadicamente realiza grande acesso sequencial I/O. Portanto, executar outros jobs irá resultar em um significativo decremento na performance.
-
Evitar compactação "maior" e split: HBase possui duas formas de compactação: a "menor", que combina um número configurável de Hfiles pequenos em um maior e a compactação "maior", quando todos os arquivos do store são lidos para uma região e gravados em um único arquivo. Isto consome tempo e impede que haja gravações na região até que finalize. É uma boa prática evitar a compactação "maior".
-
Regras práticas para o esquema de tabelas e dimensionamento de Region Servers: Existem diferentes data sets com diferentes padrões de acesso e expectativas de níveis de serviço. Entretanto, a Comunidade apresenta algumas regras gerais que podem ser vistas aqui.
Além dos itens acima, a Comunidade HBase disponibiliza uma série de recomendações para ajustes do desempenho do HBase, que podem ser lidas aqui.