Apache Hive
Analytics
Um banco de dados é um conjunto de dados pertencentes ao mesmo contexto, armazenados sistematicamente dentro de uma estrutura construída para suportá-los. Nesta estrutura convivem as regras de negócio necessárias para atingir objetivos específicos.
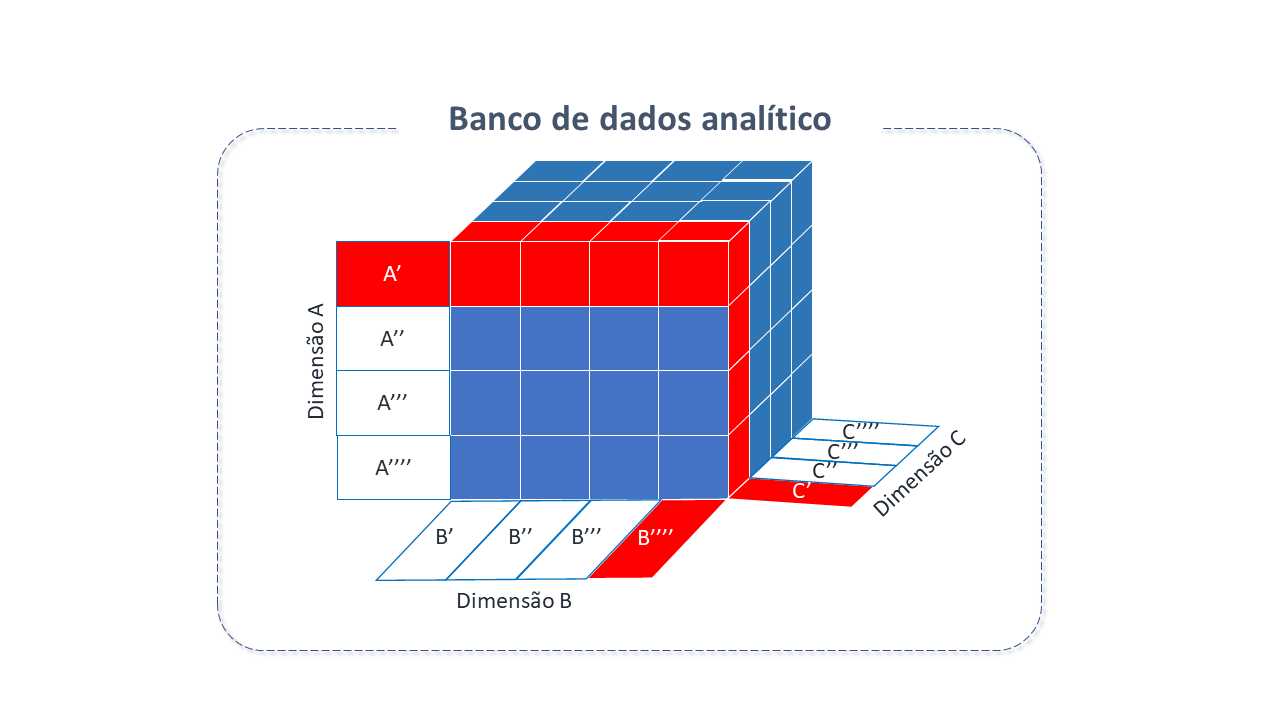
Um banco de dados analítico é um tipo de banco de dados criado para armazenar, gerenciar e consumir dados, projetado para soluções específicas de Análise de Negócio, Big Data e BI.
Ao contrário de um banco de dados típico, que armazena dados por transações ou processo, um banco de dados analítico armazena dados históricos, em métricas de negócio. É baseado em modelos multidimensionais que usam as relações com os dados para gerar matrizes multidimensionais chamadas "cubo" . Estes modelos podem ser consultados diretamente combinando suas dimensões, evitando consultas complexas que seriam realizadas em bancos de dados convencionais.
Características do Apache Hive
O Apache Hive é um banco de dados analítico (Datawarehouse) baseado no APACHE Hadoop, criado para facilitar o trabalho dos usuários data-warehouse com grande conhecimento em queries SQL, mas que encontram dificuldade para adotar Java ou outras linguagens.
Fornece interface semelhante a SQL entre o usuário e o sistema de arquivos distribuídos do HADOOP-HDFS.
Foi projetado para facilitar a sumarização, análise, consulta, leitura, gravação e tratamento de grandes conjuntos de dados.
Com ele, tornou-se possível definir tabelas com os dados armazenados no HDFS e então executar queries para transformação ou geração de relatórios.
-
O Apache Hive oferece funcionalidades padrão SQL, incluindo muitos recursos SQL 2003, SQL 2011, SQL 2016 e posteriores, para análise.
-
O Apache Hive também pode ser estendido por meio de funções definidas pelo usuário (UDFs), agregações definidas pelo usuário (HDAFs) e funções de tabela definidas pelo usuário (UDTFs).
-
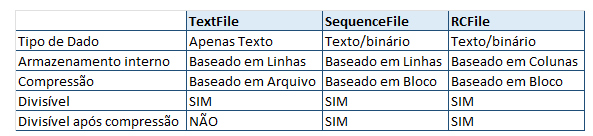
Não existe um "formato Hive" único. O Hive traz conectores integrados para:
-
Arquivos de texto com valores separados por vírgulas e tabulações(CSV/TSV)
-
"Apache Parquet(formato de armazenamento colunar disponível para qualquer projeto no ecossistema Hadoop)
-
Apache ORC(formato de arquivo colunar autodescritivo com reconhecimento de tipo projetado para cargas de trabalho do Hadoop)
-
outros formatos.
-
-
O usuário pode estender o Hive com conectores para outros formatos a partir dos seguintes perfis :
-
As operações de consulta e armazenamento são semelhantes aos SGBD tradicionais. Entretanto, existem muitas diferenças na estrutura e funcionamento do Hive.
-
Apache Hive não foi projetado para processamento de transações online (OLTP). É melhor usado para tarefas tradicionais de Data Warehousing.
-
Foi projetado para maximizar a escalabilidade, desempenho, extensibilidade, tolerância a falhas e acoplamento flexível, com seus formatos de entrada.
-
A simplicidade do Hive query language (HQL) tem ajudado o Hive a ganhar popularidade na comunidade HADOOP, sendo usado em muitos projetos por todo o mundo. HQL provê comandos de explain e analyze que podem ser usados para checar e identificar a performance de queries. Adicionalmente, os logs do Hive contém informação detalhada para investigação de performance e solução de problemas.
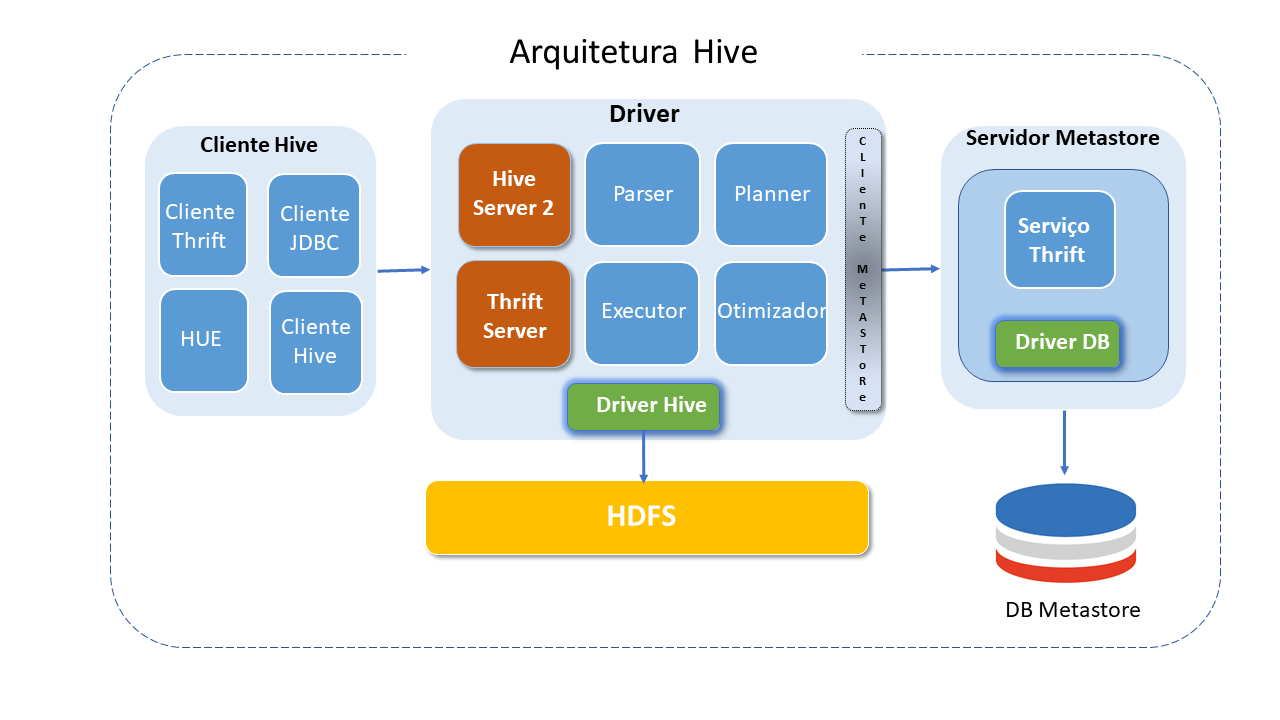
Arquitetura do Apache Hive
Hive consiste em múltiplos componentes, sendo os principais:
-
Cliente Hive: O Hive provê diferentes drives para comunicação com distintos tipos de aplicações.
Para aplicações Thrift based, disponibiliza o Thrift client. Para aplicativos Java, provê _Drivers JDBC. Para outros tipos de aplicações, provê drives ODBC.
-
Metastore server : Armazena metadados para cada tabela, como esquema e localização, incluindo os metadados da partição , o que ajuda o driver a rastrear o progresso de vários conjuntos de dados distribuídos pelo Cluster.
Mantém detalhes sobre tabelas, partições, esquemas, colunas, etc. Os dados são armazenados em formato RDBMS tradicional.
Os metadados ajudam o "driver" a acompanhar os dados.
Um servidor de backup replica regularmente os dados que podem ser recuperados em caso de perda de dados.
Provê interface Thrift Service para acesso às informações e metadados.
-
Driver: É responsável por receber as consultas Hive submetidas pelos clientes.
Inicia a execução da instrução criando sessões e monitora o ciclo de vida e o progresso da execução.
Armazena os metadados necessários gerados durante a execução de uma instrução HIVEql.
O driver também atua como ponto de coleta de dados ou resultados de consulta obtidos após a operação reduce.
Possui quatro componentes:
-
Parser: Responsável por "checar" erros de sintaxe em queries. É o primeiro passo da execução da query e, caso encontre irregularidades, retorna um erro para o cliente via Driver.
-
Planner: Queries parsed com sucesso são encaminhadas ao planner que gera os planos de execução, usando tabelas e outras informações de metadados do metastore.
-
Otimizador: Responsável pela análise do plano e geração de um novo plano DAG otimizado. A otimização pode ser feita em joins, reducing suffling data,, etc. , visando otimização da performance.
-
Executor: Uma vez parser, planner e otimizador tenham finalizado suas tarefas, o executor iniciará a execução do job na ordem das dependências. O Plano otimizado é comunicado a cada tarefa usando um arquivo. O executor cuida do ciclo de vida das tarefas e monitora sua execução.
-
Interação Hive com HADOOP
Em linhas gerais, a interação entre Hive e Apache HADOOP se dá da seguinte forma:
1) O UI chama a interface de execução do Driver.
2) O Driver cria um identificador de sessão para a consulta e a envia ao compilador para que seja gerado um plano de execução.
3 e 4) O compilador obtém os metadados necessários no metastore, que serão usados para verificação do tipo de expressões na árvore de consulta e para remover partições com base nos predicados da consulta (quando um resultado booleano é esperado).
-
O Plano gerado pelo compilador é um DAG de estágios sendo cada estágio um job map ou reduce, uma operação de metadados ou no HDFS.
-
Para os estágios Map/reduce, o plano contém árvores de operador map (árvores de operador que são executados nos mappers) e uma árvore de operador reduce (para operações que usam reducers).
6) O Engine de execução submete estes estágios aos componentes apropriados (6, 6.1, 6.2, 6.3).
-
Em cada map ou reduce, o desserializador associado com a tabela ou saídas intermediárias é usado (para ler as linhas dos arquivos HDFS que são passadas pela árvore do operador associado).
A saída é gravada em um arquivo HDFS temporário por meio do serializador (o que acontece no Mapper caso a operação não necessite de reduce).
Os arquivos temporários são usados para fornecer dados para mapear/reduzir etapas subsequentes do plano.
Para operações DML, o arquivo temporário final é movido para o local da tabela.
A figura abaixo mostra como uma consulta comum "flui" pelo sistema:
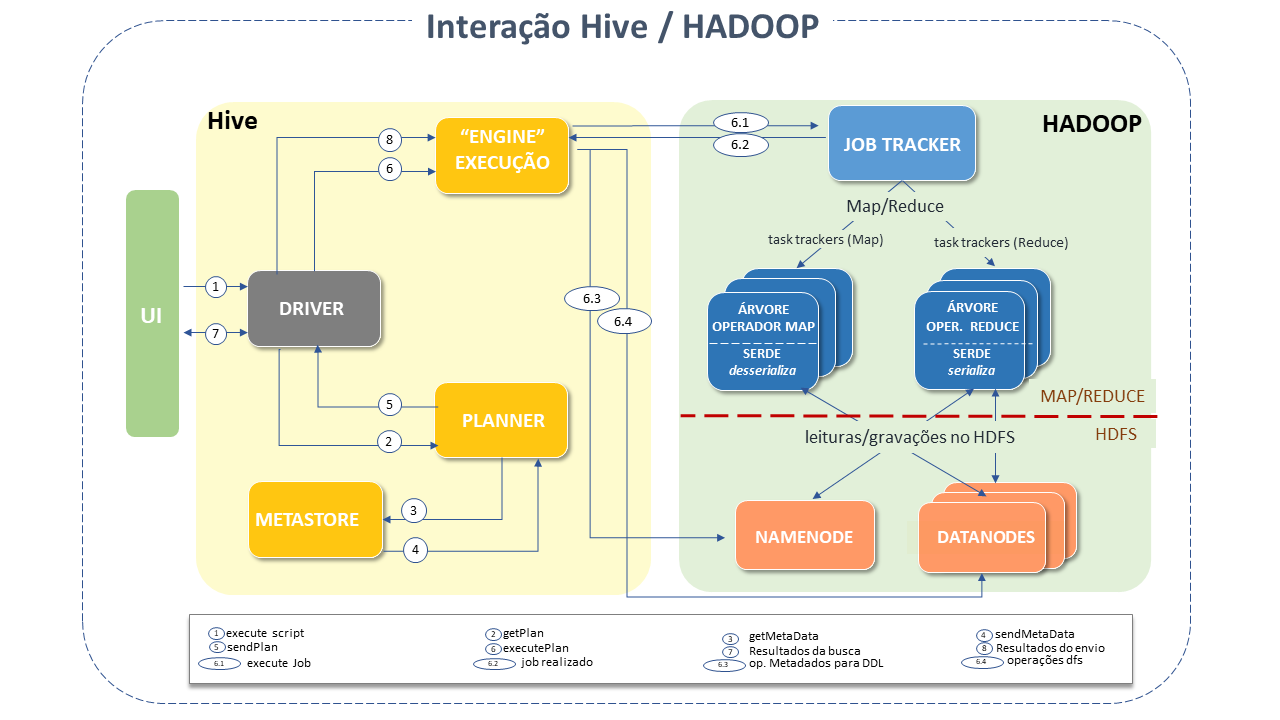
Como o Apache Hive funciona
HCatalog:
Camada de gerenciamento de tabela e armazenamento para HADOOP que habilita ferramentas como o Hive e MapReduce a ler dados de tabelas.
É construído "sobre" o serviço Hive Metastore e , portanto, suporta formatos de arquivos para os quais o Hive SerDe (serialização e desserialização) pode ser feito.
O HCatalog habilita a visualização de dados como tabelas relacionais, sem a necessidade de preocupar-se com a localização do dado ou seu formato.
Suporta formatos text file, ORC file , sequence file, e RCFile e SerDe pode ser escrito para formatos como AVRO(formato de dados de código aberto que possibilita o agrupamento de dados serializados com o esquema de dados no mesmo arquivo).
As tabelas do HCatalog são "imutáveis", o que significa que, por natureza, os dados na tabela e na partição não podem ser anexados. No caso de tabelas particionadas, os dados podem somente ser anexados a uma nova partição, sem afetar a partição antiga.
As interfaces do HCatalog para aplicações MapReduce são HCatInputFormat e HCatOutputFormat. Ambos são InputFormat e OutPutFormat do HADOOP. O HCatalog está evoluindo novas interfaces para interagir com outros componentes do ecossistema HADOOP.
-
WebHCat: fornece serviço para execução de tarefas HADOOP Map Reduce (ou YARN), Pig e Hive. Também permite a execução de operações de metadados do Hive usando uma interface HTTP (estilo _REST).
Organização dos Dados
Por padrão, o Hive armazena metadados em um Banco de Dados Apache Derby embutido. Outros bancos de dados cliente-servidor podem ser usados opcionalmente, como o Postgree.
Os primeiros quatro formatos de arquivo suportados pelo Hive eram apenas texto simples, arquivos sequenciais, formatos ORC e RCFile. O Apache Parquet pode ser lido via plug-in em versões posteriores a 0.1 e originalmente iniciando em 0.13. A representação compactada de dados do Parquet(colunar) reduz a quantidade de dados que o Hive tem que percorrer e, em consequência, o tempo de execução das consultas.
Plugins adicionais suportam a consulta do Blockchain Bitcoin.
Unidades de Dados
Hive é organizado em:
-
Banco de Dados: Os Namespaces existem para evitar conflitos de nomes em tabelas, views, partições, colunas e tudo o mais. Databases também podem ser usados para reforçar a segurança para um usuário ou grupo de Usuários.
-
Tabelas: Unidades homogêneas de dados que possuem o mesmo esquema.
-
Partições: Cada tabela pode ter uma ou mais chaves de partição que determinam como os dados são armazenados. Partitions além de ser unidades de armazenamento, também habilitam o usuário a identificar, de forma eficiente, as linhas que satisfazem um critério específico. Cada valor único de uma chave de partição define uma partição da tabela.
-
Buckets ou Clusters: Dado em cada partição pode ser dividido em "porções" baseado no valor da função hash de alguma coluna da tabela. Por exemplo, uma tabela pode ser "quebrada" pelo userid, a qual é uma das colunas da tabela.
Recursos do Apache Hive
-
Construído sobre o Apache Hadoop, o Hive fornece os seguintes recursos:
-
Acesso via SQL , facilitando tarefas de armazenamento de dados, como extração/transformação/carga (ETL), geração de relatórios e análise de dados.
-
Suporte à simultaneidade e autenticação de vários clientes com o Hive-Server 2(HS2), projetado para fornecer melhor suporte a cliente de API aberta, como o JDBC e ODBC.
-
Suporte completo à ACID para tabelas ORC e de inserção a todos os outros formatos.
-
Suporte à inicialização e a replicação incremental para backup e recuperação de dados.
-
Repositório central de metadados para tabelas e partições Hive em um SGBD relacional com acesso a estas informações por meio de API do serviço MetaStore.
-
Mecanismo para estabelecer estrutura em uma variedade de formato de dados.
-
Acesso a arquivos armazenados diretamente no Apache HDFS ou outros, como o Apache Hbase.
-
Execução de consulta via Apache Tez, Apache Spark ou Mapreduce.
-
Linguagem procedural com HPL-SQL.
-
Recuperação de consultas em subsegundos via Hive LLAP e Apache YARN.
-
Beeline-Command Line Shell HiveServer2 suporta Beeline Shell. Trata-se de um cliente JDBC baseado em SQLLine CLI que trabalha tanto em modo "embutido"(com um Hive integrado - semelhante do Hive CLI) quando remoto (conectando-se a um processo HS2 separado por meio do Thrift).
Principais diferenças entre Hive e os SGBD tradicionais
Nos SGBD tradicionais, um esquema é aplicado a uma tabela quando os dados são carregados nela. Isso permite que o SGBD verifique se os dados inseridos seguem a representação da tabela, conforme especificado em sua definição. Este "design" é chamado "esquema na gravação".
O Hive não verifica os dados em relação ao esquema da tabela na gravação. Ele faz verificações de tempo quando os dados são lidos. Este modelo é denominado "esquema em leitura". As duas abordagens têm suas vantagens e desvantagens. A verificação durante a carga adiciona sobrecarga, onerando o tempo de carga de dados, mas garantindo que os dados não estejam corrompidos. A detecção antecipada garante o tratamento antecipado de exceções. Como as tabelas são forçadas a corresponder ao esquema durante/após a carga dos dados, tem melhor desempenho em tempo de consulta.
O Hive , por outro lado, pode carregar dados dinamicamente sem verificação de esquema, garantindo uma carga inicial rápida, mas com desempenho mais lento no momento da consulta.
As transações são operações fundamentais em SGBD tradicionais.
Como qualquer RDBMS típico, o Hive suporta as quatro propriedades das transações (ACID): Atomicidade, Consistência, Isolamento, Durabilidade. As transações foram incluídas no Hive 0.13, mas limitadas apenas ao nível de partição.
A versão 0.14 do Hive foi totalmente adicionada para suportar propriedades ACID completas. A partir desta versão, é possível realizar diferentes transações em nível de linha, como insert, delete, update. A ativação destes comandos requer a fixação de valores apropriados para as propriedades de configuração, como hive.support.concurrency, hive.enforce.bucketinge, hive.exec.dynamic.partition.mode
Segurança do Apache Hive
A versão 0.7.0 do Hive adicionou integração com a segurança do Hadoop, que, por sua vez, passou a usar o suporte de autorização do Kerberos para fornecer segurança. O Kerberos permite a autenticação mútua entre cliente e servidor. Nesse sistema, a solicitação do cliente para um ticket é passada junto com a solicitação.
Permissões para arquivos recém-criados no Hive são ditadas pelo HDFS. O modelo de autorização do sistema de arquivos distribuídos do HADOOP usa três entidades: usuário, grupo e outras com três permissões: ler, gravar, executar. As permissões padrão para arquivos recém-criados podem ser configuradas alterando o valor unmask para a variável de configuração Hive hive.files.umask.value.
Boas Práticas para Apache Hive
-
Particionamento de tabelas: O Apache Hive resolve a ineficiência da execução de jobs MapReduce com grandes tabelas oferecendo um esquema de partições automatico no momento da criação da tabela.
Neste método, todos os dados da tabela são divididos em múltiplas partições, cada qual correspondendo a(os) valor(es) especifico(s) da(s) coluna(s) da partição, que é(são) mantido(s) em registro(s) da tabela HDFS(como sub-registro(s)) .
Uma consulta com filtragem de partição carregará apenas dados das partições específicas (subdiretórios), trazendo mais velocidade ao processo. A seleção da chave de partição é um fator importante, deve sempre ser um atributo de baixo "cardinal" para evitar sobrecargas.
Alguns atributos comumente usados como chaves de partição são: * partições por data e hora: data-hora, ano-mês-dia(mesmo horas) * partições por local: país, território, cidade, estado. * partições por lógica de negócio: departamento, clientes, região de vendas, aplicativos.
-
Desnormalização: A normalização é um processo padrão usado para modelar tabelas de dados lidando com redundâncias e outras anomalias. Junções são operações caras e complicadas e geram problemas de desempenho. É uma boa idéia evitar estruturas de tabelas altamente normalizadas, pois exigem a junção de consultas.
-
Compactação da saída Map/Reduce: Compactação reduz significativamente o volume de dados intermediários e minimiza a quantidade de transferência de dados entre Mapper e Reducer.
A compactação pode ser aplicada à saída do Mapper e do Reducer individualmente. Importante lembrar que arquivos compactados com gzip não podem ser divididos. Significa que deve ser aplicado com cautela.
O tamanho do arquivo não deve ser maior do que algumas centenas de Mb, sob risco de produzir um trabalho desequilibrado.
Opções de codec de compressão podem ser snappy, izo, bzip, etc.
-
Map Joins (junções de mapa) Map Joins são eficientes se a tabela "no outro lado do join" for pequena o suficiente para residir em memória.
Com o parâmetro hive.auto.convert.join=true o Hive tenta o map join automaticamente. Ao usar este parâmetro, é adequado certificar-se de que o auto-convert esteja habilitado no ambiente Hive.
É essencial, ainda, o parâmetro hive.enforce.bucketing = true. Esta configuração fará com que o Hive reduza os ciclos de scan para encontrar uma chave específica porque o bucketing garantirá que a chave esteja em um bucket específico.
-
Seleção do formato de entrada : Formatos de entrada tem um papel critico no desempenho do Hive. O tipo texto, por exemplo, não é adequado para um sistema com alto volume de dados, pois estes tipos legíveis de formatos ocupam muito espaço e trazem sobrecarga à análise.
Para resolver isto, o Hive traz formatos de entrada colunares como RCFile, ORC, etc. Estes formatos permitem reduzir operações de leitura em consultas analíticas, viabilizando o acesso a cada coluna individualmente.
Outros formatos binários como Avro, arquivos de sequência, Thrift e ProtoBuf podem ajudar.
-
Execução paralela : HADOOP pode executar jobs MapReduce em paralelo e várias consultas executadas no Hive usam este paralelismo automaticamente .
Entretanto, Consultas únicas e complexas do Hive geralmente são convertidas em vários jobs MapReduce, que, por sua vez, são executados sequencialmente por padrão.
Alguns dos estágios MapReduce de uma consulta não são interdependentes e podem ser executados em paralelo, aproveitando a capacidade "disponível" do Cluster, melhorando sua utilização e reduzindo o tempo geral de execução.
A configuração Hive para mudar este comportamente é alternar o sinalizador
Set _hive.exe.parallel=true_
-
Vetorização: A execução de consultas vetorizadas melhora o desempenho do Hive.
É uma técnica que trabalha com o processamento de dados em lotes, em vez de uma linha por vez, o que resulta em uma eficiente utilização da CPU.
Para ativar a vetorização, o parâmetro adequado é Set hive.vectorized.execution.enabled=true.
-
Teste de unidade: O teste de unidade determina se a menor parte testável do código funciona. Detectar problemas antecipadamente é muito importante. O Hive permite testar unidades UDFs, SerDes, Scripts de streaming, Consultas do Hive, etc., por meio de testes rápidos em modo local.
Existem várias ferramentas disponíveis que auxiliam o teste de consultas Hive, como HiveRunner, Hive_test e Beetest.
-
Sampling (amostragem): A amostragem permite que um subconjunto de dados seja analisado sem a necessidade de análise de todo o conjunto.
Com uma amostra representativa, uma consulta pode retornar resultados significativos muito mais rapidamente, consumindo menos recursos.
O Hive oferece o TABLESAMPLE, que permite que tabelas sejam experimentadas, em vários níveis de granularidade - retornando subconjuntos ou blocos HDFS ou apenas os primeiros n registros de cada input split.
Uma UDF pode ser implementada para filtrar os registros segundo um algoritmo de amostragem.
Linguagem do Apache Hive
Apache Hive foi desenvolvido predominantemente em Java. O HiveQL é a linguagem baseada em SQL do HIVE. Ela "aplica" a sintaxe SQL na criação de tabelas, carga de dados e consulta. Também permite a incorporação de scripts personalizados de MapReduce. Esses scripts podem ser escritos em qualquer idioma usando uma interface streaming simples (leitura das linhas na entrada padrão e gravação na saída padrão).
Fontes: