Motores de Computação Distribuída
O conceito de computação distribuída não é novo e tornou-se ainda mais conhecido com a "explosão" de dados dos últimos anos, e o crescimento da necessidade de tratar grandes fluxos de informação com capacidade preditiva.
Entre seus principais benefícios podemos citar a capacidade de adicionar mais nós de processamento (escalabilidade), na proporção do crescimento dos dados, sem comprometer performance ou disponibilidade dos sistemas e a capacidade de processamento em tempo real - a distribuição dos trabalhos em diversos nós agiliza e proporciona eficiência à tomada de decisão.
Na era do Big Data surgiram vários modelos de programação e frameworks para execução de jobs em batch de forma otimizada e distribuída, como o Map Reduce, e outros, com a capacidade de processamento de dados em larga escala, em paralelo e com tolerância a falhas, muito úteis para ETL (Exctract, Transform, Load), como o Apache Hadoop, Apache Spark, Apache Beam e Apache Flink.
Uma outra forma de processar dados decorrente da era Big Data é o streaming, um tipo de "engine" de processamento de dados projetado para tratar datasets infinitos (os dados surgem infinitamente e não há garantia da ordem de chegada). Dentre os principais frameworks/engines de processamento distribuídos codificados para streaming, citamos o Apache Flink, Apache Storm, Apache Flume e Apache Samza. Estes mecanismos recebem mensagens por meio da leitura de um sistema de mensageria (source) - como o Apache Kafka - processa-os em tempo real, filtrando os que contém os dados procurados e envia-os para uma saída.
Apache Flink
O Apache Flink é uma estrutura e mecanismo de processamento distribuído para computação com estado (funções que assumem um estado e retornam um novo estado) de streams de dados ilimitados e limitados. Foi criado pela equipe de pesquisa da Berlin Technical University, liderada por Stephan Ewen. Começou como um projeto acadêmico chamado Stratosphere, por volta de 2009. Em 2014, o projeto foi incorporado à Apache Software Foundation, tornando-se um projeto de incubação. Posteriormente foi promovido a um projeto de nível superior da Apache. Desde então, o Flink evoluiu significativamente, tornando-se uma das principais plataformas de processamento de fluxo de dados em tempo real.
Características do Apache Flink
O Apache Flink suporta múltiplas noções de tempo para processamento de fluxos baseado em estado.
Dentre suas principais características, destacamos:
-
Processamento de estados: Gerencia estados complexos, mesmo em operações de grande escala.
-
Correção e consistência: Oferece garantias de exatidão de dados (exatidão-uma-vez).
-
Processamento de tempo de evento: Permite lidar com dados em tempo real, considerando a hora em que eventos ocorrem.
-
APIs em camadas: Abordagem modular e flexível para construir aplicações. Fornece várias APIs em diferentes níveis de abstração, incluindo SQL, DataStream e DataSet:
-
API de Processamento de Fluxo de Dados (DataStream API): Usada para aplicações de processamento de fluxo de dados em tempo real.
-
API de Conjunto de Dados (DataSet API): Voltada para processamento de dados em lote.
-
API SQL e Table: Permite aos usuários escrever consultas em SQL ou em uma linguagem de tabela similar para manipulação de dados.
Essas APIs permitem aos desenvolvedores escolher o nível de abstração que melhor se adapta às suas necessidades.
-
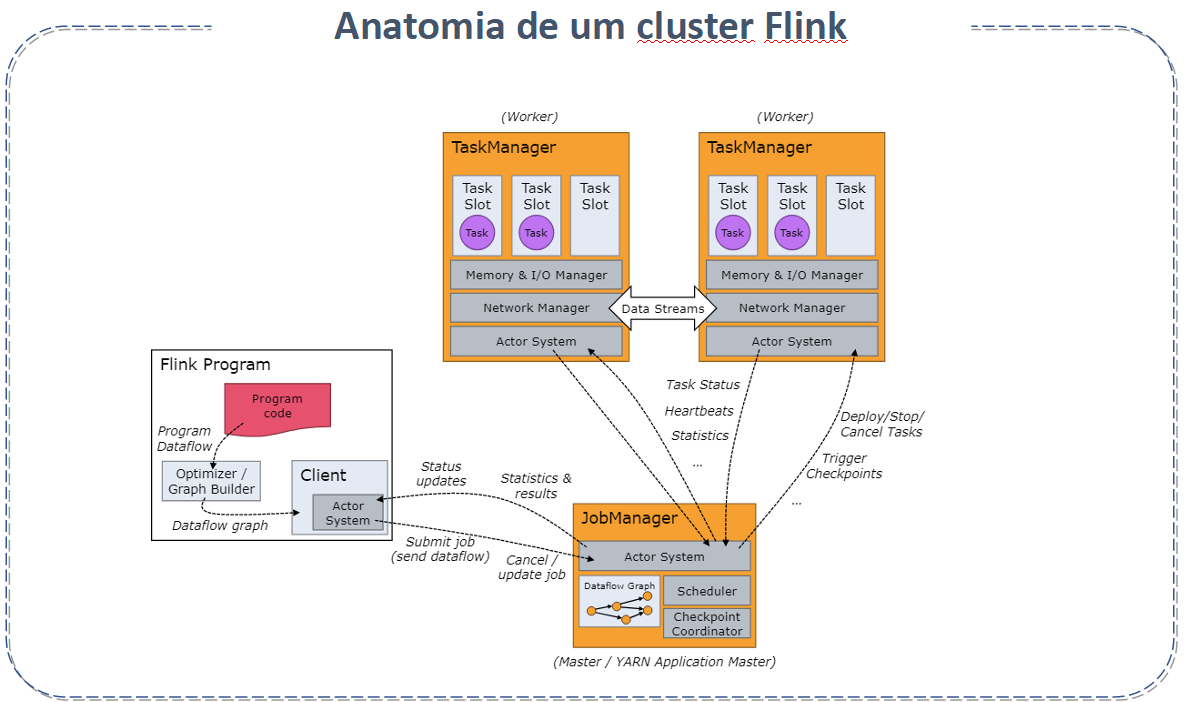
Arquitetura do Apache Flink
A arquitetura do Apache Flink é composta por vários componentes :
-
JobManager: Coordena a distribuição de tarefas e a gestão de recursos. Ele também lida com o checkpointing para garantir a tolerância a falhas.
-
TaskManager: Executa as tarefas (ou jobs) efetivamente. Cada TaskManager pode executar múltiplas tarefas simultaneamente.
-
Dispatcher: Oferece uma interface REST para submeter aplicações Flink e iniciar um novo JobMaster para cada trabalho, além de executar o WebUI do Flink.
-
Cliente Flink: Prepara e envia um fluxo de dados para o JobManager. Pode desconectar ou permanecer conectado para receber relatórios de progresso.
-
Resource Manager: Responsável pela alocação de recursos e provisão no cluster Flink, gerenciando slots de tarefas.
-
JobMaster: Gerencia a execução de um único JobGraph.
-
Fontes e Destinos de Dados (Sources and Sinks): Conectam-se com sistemas de armazenamento externos para entrada e saída de dados.
Esta arquitetura permite o processamento distribuído e escalável de grandes volumes de dados. Para mais informações detalhadas, visite a documentação oficial do Apache Flink em Apache Flink Architecture.
Recursos do Apache Flink
-
Análise de fluxo e lote: Suporta tanto processamento em tempo real quanto em lote.
-
Aplicações orientadas a eventos: Ideal para sistemas que reagem a eventos em tempo real.
-
Alta performance: Projetado para ser rápido, com baixa latência e alto throughput.
Quando usar o Apache Flink
-
O Apache Flink é Ideal para aplicações que exigem processamento de fluxo de dados em tempo real e análise de eventos.
-
É Recomendado para cenários com requisitos de tolerância a falhas e garantias de consistência de dados.
-
É Adequado para sistemas que necessitam de processamento de dados em grande escala e com baixa latência.
Quando o Apache Flink não se aplica
-
O Apache Flink não é a melhor opção para projetos simples de manipulação de dados onde soluções mais leves, como scripts ou ferramentas de ETL tradicionais, seriam suficientes.
-
Pode ser excessivo para aplicações que não requerem recursos avançados de processamento de fluxo de dados ou análise em tempo real.
-
É menos eficiente para tarefas onde o processamento em lote, sem a necessidade de tratamento em tempo real, é suficiente.
Principais diferenças entre Apache Spark e apache Flink
-
Modelo de Processamento: Uma das principais diferenças entre as duas ferramentas é o modelo de processamento. O Spark usa o modelo de processamento de dados RDD (Resilient Distributed Datasets) - uma coleção distribuída e imutável de objetos. O Apache Flink usa o modelo de processamento de dados baseado em fluxos - uma coleção de eventos processados em tempo real à medida que chegam.
-
Velocidade: O Apache Flink geralmente é mais rápido que o Apache Spark para processamento de dados em tempo real, isto porque seu modelo de processamento elimina a necessidade de transformar dados em RDDs antes de processa-los.
-
Tolerância a falhas: Ambas as ferramentas são tolerantes a falhas, mas Spark usa um mecanismo de checkpointing baseado em disco para manter a integridade dos dados e Flink usa uma abordagem baseada em memória, armazenando os dados em cache, o que permite uma recuperação mais rapida no caso de falhas.
-
Suporte a eventos complexos: O Apache Flink oferece suporte nativo a processamento de eventos complexos, o que permite a análise de padrões e correlações em fluxos de dados em tempo real, ao contrário do Spark que requer bibliotecas adicionais e ajustes de configuração.
Em suma, o Apache Spark é frequentemente usado para processamento de dados em lote e aplicações que não exigem uma latência muito baixa, como análise de logs e processamento de dados históricos. O Apache Flink é frequentemente usado para processamento de dados em tempo real, como análise de fraudes e monitoramento de IoT.
Principais diferenças entre Apache Storm e apache Flink
A comparação entre Apache Flink e Apache Storm inclui vários aspectos:
-
Uso: Flink é mais para processamento unificado de lote e fluxos, enquanto Storm é focado em processamento de fluxo em tempo real.
-
Processamento de Dados: Apache Flink oferece processamento de dados em lote e em fluxo; Storm é ótimo para processamento de fluxo.
-
Transformação de Dados: Apache Flink tem opções ricas para transformação de dados; Storm é mais limitado.
-
Suporte a Aprendizado de Máquina: Apache Flink suporta o aprendizado de Máquina, enquanto o Apache Storm não.
-
Linguagem de Consulta: Apache Flink usa uma linguagem semelhante ao SQL; Storm não tem linguagem de consulta nativa.
-
Modelo de Implantação: Ambos oferecem diferentes opções de implantação.
-
Integração com Outros Serviços: Ambos se integram bem com outros serviços.
-
Escalabilidade: Apache Storm destaca-se em alta escalabilidade.
-
Desempenho e Confiabilidade: Ambos têm bom desempenho e são confiáveis.
Boas Práticas para Apache Flink
-
Gerenciamento Eficiente de Estado: Estruture e gerencie estados de forma eficiente para otimizar desempenho e garantir a consistência dos dados.
-
Otimização de Desempenho: Monitore métricas de desempenho, faça ajustes finos em configurações e utilize estratégias de particionamento de dados para maximizar a eficiência.
-
Estratégias de Recuperação de Falhas: Implemente estratégias robustas de checkpointing e recuperação para garantir a tolerância a falhas.
-
Escalabilidade e Balanceamento de Carga: Desenvolva aplicações com escalabilidade em mente, garantindo um balanceamento efetivo da carga entre os nodos do cluster.
-
Testes e Validação: Realize testes extensivos para garantir a confiabilidade e a precisão das aplicações Flink em diferentes cenários.
-
Atualizações e Manutenção: Mantenha-se atualizado com as últimas versões e práticas recomendadas do Flink para aproveitar melhorias e correções.
Linguagem do Apache Flink
O Apache Flink é predominantemente utilizado com a linguagem de programação Java. Também oferece suporte a Scala, uma vez que a sua API Scala se integra perfeitamente com a API Java. Além disso, para operações de consultas de dados, o Flink suporta SQL através de sua API de Table e SQL. Essa flexibilidade permite que os desenvolvedores escolham a linguagem que melhor se adapta às suas necessidades e preferências.
Fontes: