Apache NiFi
Automação de Dataflows
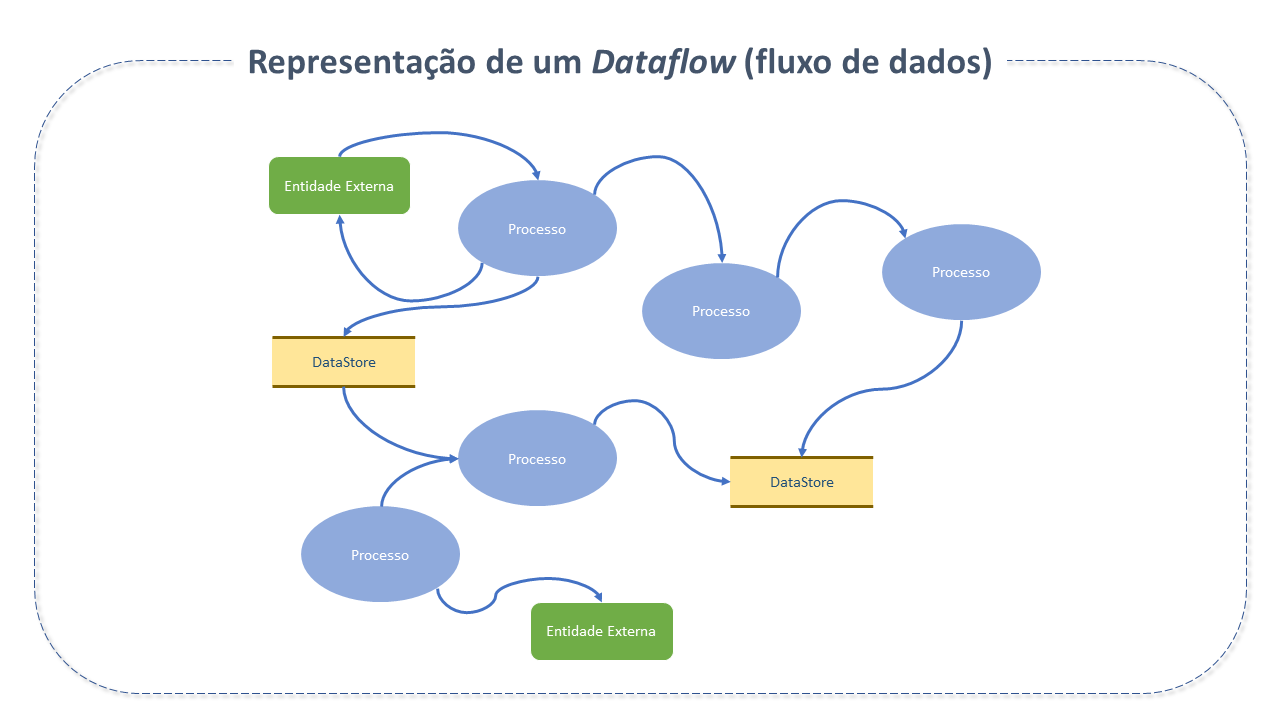
Automação de fluxos de dados é um paradigma de software baseado na idéia de computação como um gráfico direcionado, representando o fluxo automatizado e gerenciado da informação entre sistemas.
A automação de fluxos de dados auxilia na captura, construção e colaboração em escala por meio de ferramentas automatizadas, garantindo maior eficiência dos sistemas por meio de relatórios otimizados e controláveis.
Características do Apache NiFi
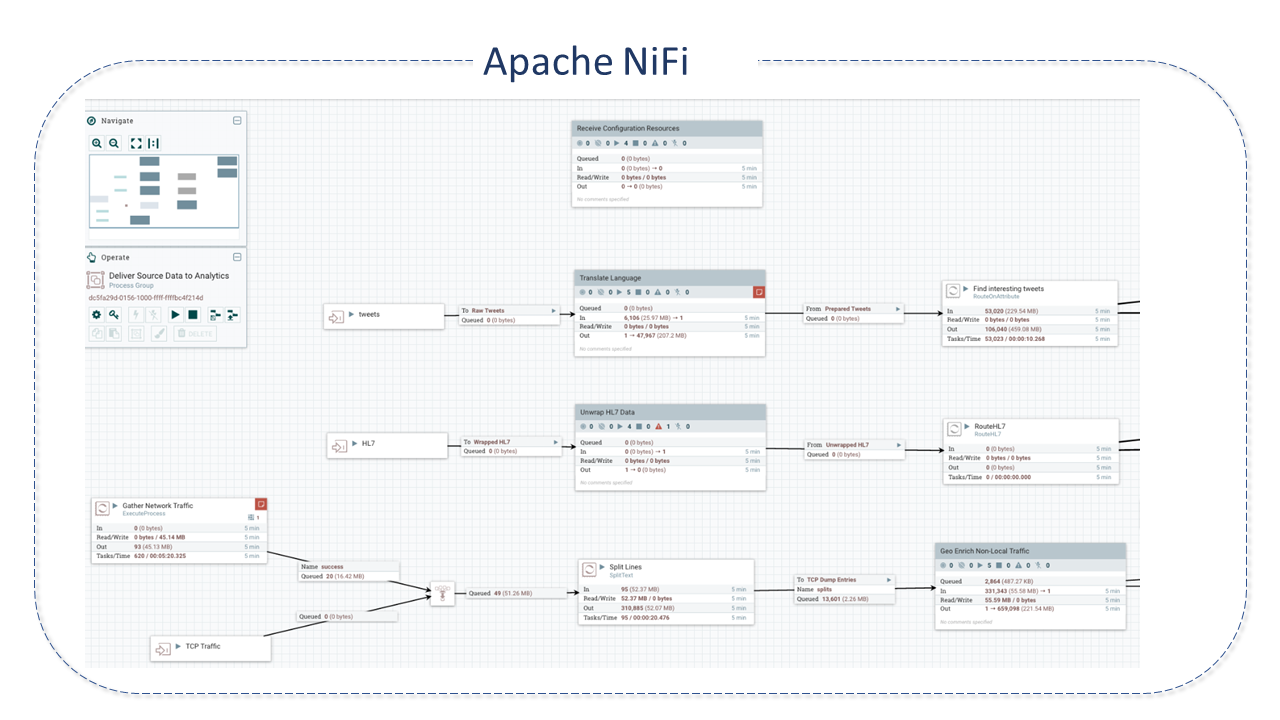
O NiFi foi construído para automatizar fluxos de dados("Dataflows"), suportar e atender o nível de rigor necessário para alcançar conformidade, privacidade e segurança na troca de dados entre sistemas.
NiFi tem se tornado especialmente valioso para as soluções de ponta que têm surgido ao longo dos últimos anos, para as quais o Dataflow é vital, como o SOA (Service Oriented Architecture), APIs(Application Protocol Integration), IOT (Internet of things) e Big Data.
Os conceitos de design fundamentais do Apache NiFi relacionam-se intimamente com as ideias de Programação baseada em Fluxos (Flow Based Programming - fbp).
| Termo NiFi | Termo FBP | Descrição |
|---|---|---|
FlowFile |
Informação do Pacote |
O FlowFile representa cada objeto movido entre/para os sistemas . O NiFi mantém o controle do mapa de strings do atributo par "key/value" e seu conteúdo associado de zero ou mais bytes. |
Processador FlowFile |
Caixa preta (Black Box) |
São os Processadores que executam, de fato, o trabalho. O processador executa uma combinação de roteamento, transformação ou mediação entre sistemas. Processadorees têm acesso a atributos de um FlowFile e seu conteúdo stream. Podem operar em zero ou mais FlowFiles de uma unidade de trabalho e também realizar o Commit ou Rollback. |
Connection |
Bounded Buffer |
Conexões provêem a ligação real entre processadores. Agem como filas e viabilizam a interação entre vários processos em diferentes níveis. Estas filas podem ser priorizadas dinamicamente e podem ter limites superiores na carga, o que habilita backpressure. |
Flow Controller |
Scheduler |
Provê threads para as extensões serem executadas e gerencia o schedule de quando as extensões recebem recursos para execução.. |
Este modelo de design torna a Plataforma NiFi muito efetiva para construção de dataflows poderosos e escaláveis, habilitando :
-
A criação visual e gerenciamento de gráficos direcionados(com sentidos associados à cada aresta) de processadores.
-
Alta taxa de transferência e um buffer de dados natural, apesar das flutuações no processamento e nas taxas de fluxo.
-
Modelos altamente concorrentes, com a capacidade de executar várias tarefas distintas simultâneamente (ou aparentemente simultâneas), permitindo que o desenvolvedor se despreocupe das complexidades típicas deste tema.
-
O Desenvolvimento de componentes coesos, com baixo acoplamento, reutilizáveis em outros contextos e unidades testáveis.
-
A Simplificação de funções criticas de dados, como contrapressão("back-pressure") e "pressure release", tornando-se naturais e intuitivas (por meio do recurso constrained connections).
-
O Tratamento de erros de forma tão natural quanto o "caminho feliz".
-
Facil compreensão e rastreamento de pontos onde o dado "entra" e "sai" do sistema.
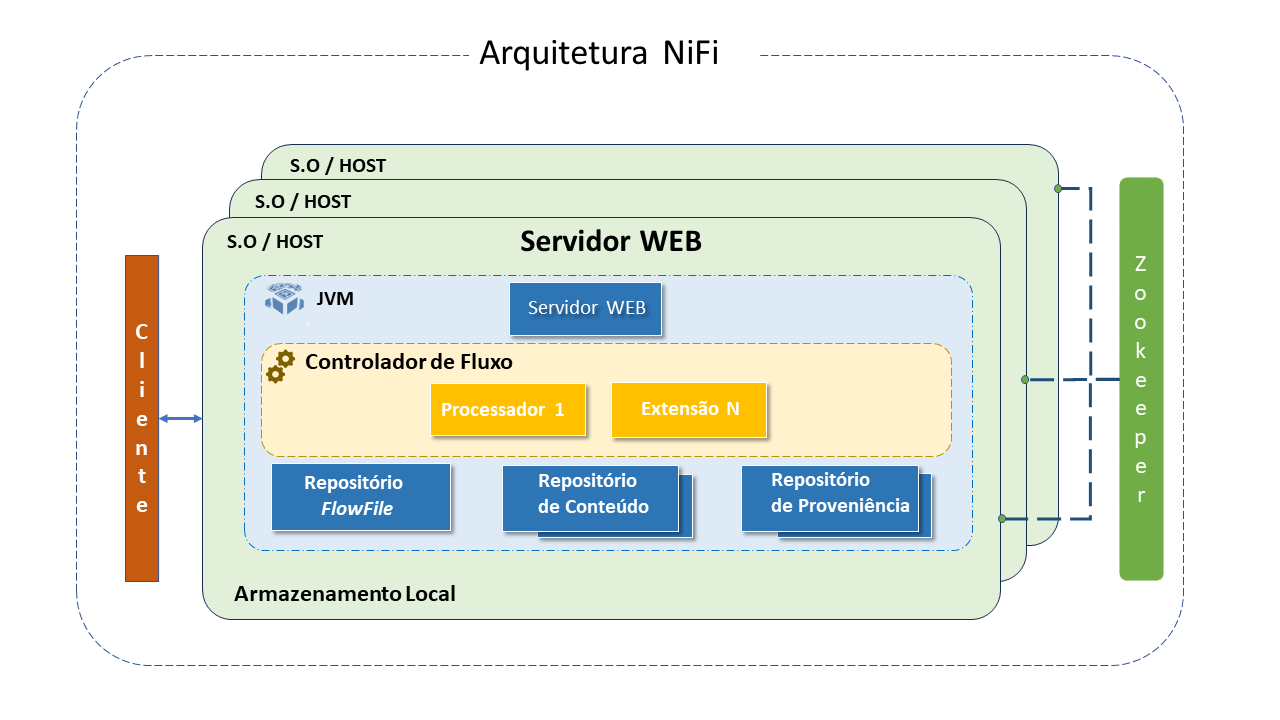
Arquitetura do Apache NiFi
O NiFi é executado dentro de uma máquina virtual JVM, em um sistema operacional host. Seus principais componentes na JVM são:
-
Web Server (Servidor Web) : executa o controle visual e monitora os eventos. Hospeda o comando HTTP-based e a API de Controle.
-
Flow Controller (Controlador de Fluxos): o "cérebro" da operação. Provê threads para as extensões serem executadas e gerencia o schedule de quando as extensões recebem recursos para execução.
-
Extensions (Extensões): Plugins que permitem a interação entre o NiFi e outros Sistemas.
O NiFi provê vários pontos de "extensão" para que desenvolvedores possam adicionar funcionalidades. Todos operam e executam dentro da JVM.
Os pontos de extensão incluem:
-
Processor (processador): A interface processador provê acesso aos FlowFiles, seus atributos e conteúdos.
-
ReportingTask: Provê métricas, informações de monitoramento e do estado interno do NiFi para endpoints como arquivos de log, email e web services remotos.
-
ParameterProvider: Provê parâmetros para uso por fontes externas.
-
ControllerService: Fornece mecanismo para criar serviços compartilhados entre todos os Processadores, ReportingTasks e outros ControllerServices em uma única JVM.
-
FlowFilePriorizer: Fornece um mecanismo pelo qual os FlowFiles em uma fila podem ser priorizados ou classificados, para posterior processamento em uma ordem mais eficaz em caso de uso específico.
-
AuthorityProvider: Determina quais privilégios e funções, se houver, devem ser concedidos a um determinado usuário.
-
-
Repositório FlowFile: É onde NiFi mantém/rastreia o status do FlowFile ativo. A implementação do repositório é "plugável". O "default" é um log write-ahead persistente localizado em uma partição do disco específica.
-
Repositório de Conteúdo: É onde estão são mantidos os dados "em trânsito". É "plugável". A abordagem default é um mecanismo simples, que armazena blocos de dados no file system. Mais de um local de armazenamento do file system pode ser especificado, visando obter diferentes partições envolvidas na redução da contenção em qualquer volume único.
-
Repositório de Proveniência: Armazena todas as informações sobre a proveniência dos dados que circulam pelo sistema. O repositório é "plugável" com a implementação default sendo para usar um ou mais volumes de discos físicos. Dentro de cada local o dado de evento é indexado e habilitado para busca.
O NiFi também está habilitado a operar dentro de um Cluster.
Desde a versão NiFi 1.0 , o NiFi emprega o paradigma de Zero-Leader : cada nó do Cluster NiFi executa as mesmas tarefas no dado, mas cada um operando em um conjunto distinto de dados.
O Apache Zookeeper elege um nó único como Coordenador. Todos os nós do Cluster reportam heartbeat e status para o Coordenador, que fica responsável por desconectar e conectar nós.
Adicionalmente, todo Cluster tem um Nó primario, também eleito pelo Zookeeper.
O failover é tratado automaticamente pelo Zookeeper.
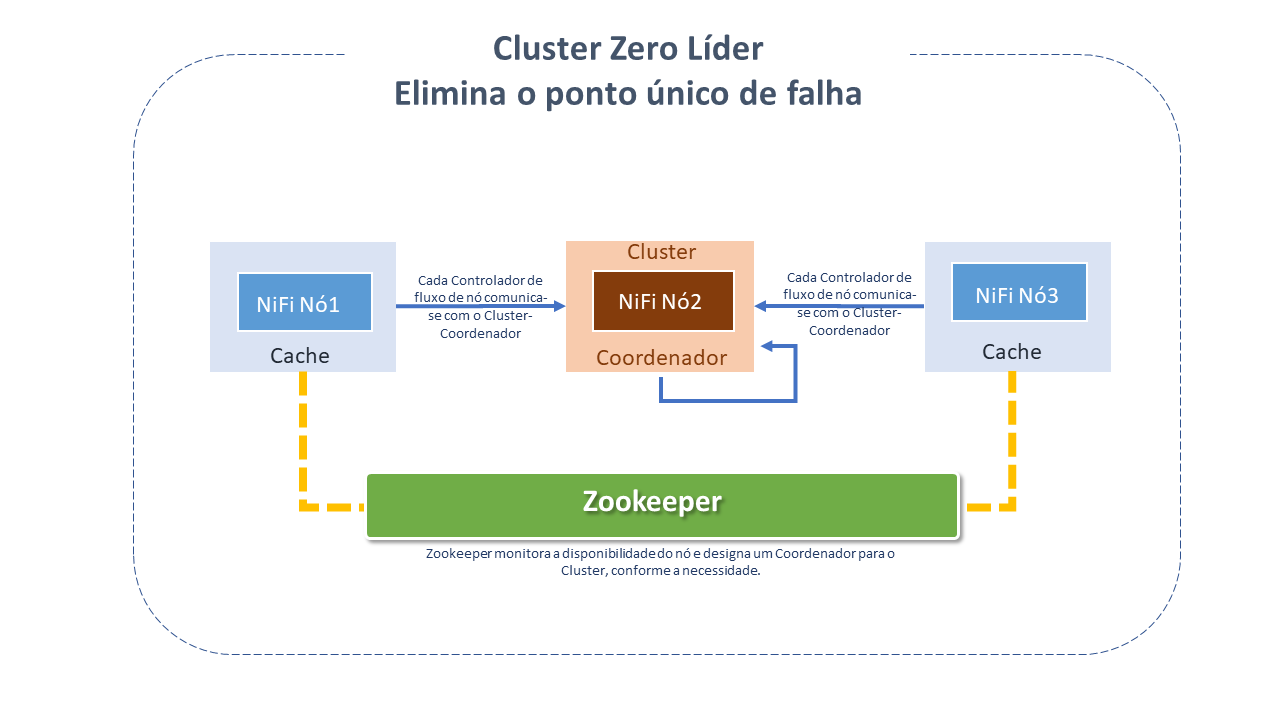
Assim como o gerenciador de Dataflow, a interação com o Cluster NiFi pode se dar por meio de interface para o usuario (UI) de qualquer nó. Qualquer alteração é replicada para todos os nós no Cluster, permitindo múltiplos entry-points
Expectativas de Performance
O Apache NiFi foi projetado para aproveitar totalmente os recursos do sistema host em que está operando. Essa maximização de recursos é particularmente forte em relação à CPU e disco.
-
I/O: As taxas de transferência ou latência podem variar em função da configuração do sistema. Considerando que há abordagens "plugáveis" para a maior parte dos subsistemas NiFi, a performance dependerá da implementação. Considere usar as implementações padrão prontas para uso.
Podemos assumir uma taxa de "read/write" de 50MB por segundo em discos RAID modestos dentro de um servidor comum. Para grandes classes de dataflows, o NiFi está habilitado a alcançar 100MB por segundo ou mais de taxa de transferência (throughput), pois é esperado um crescimento linear para cada partição fisica e repositório de conteúdo adicionado ao NiFi.
-
CPU: O controlador de fluxos aloca e gerencia threads para os processadores. Age como um "engine" ditando quando um processador receberá a "thread" para executar.
Além disso, permite adicionar serviços de controlador, que facilitam o gerenciamento de recursos, como conexões de Banco de Dados ou credenciais de provedor de serviços em nuvem.
Os serviços do controlador são daemons(executados em segundo plano) e fornecem configuração, recursos e parâmetros para os processadores executarem.
O número ideal de threads a serem usados depende dos recursos do sistema "host" em termos de números de núcleos, se esse sistema está executando outros serviços e a natureza do processamento no fluxo.
Para fluxos de I/O pesado é razoável disponibilizar muitas dezenas de threads.
-
RAM NiFi reside na JVM e é limitado pelo espaço de memória fornecido por ela.
A coleta de lixo da JVM torna-se um fator muito importante tanto para restringir o tamanho total do heap quanto para otimizar a execução da aplicação ao longo do tempo.
Jobs NiFi podem ser intensivos em I/O quando lendo o mesmo conteúdo regularmente. Configure um disco grande o suficiente para otimizar a performance.
Recursos mais interessantes do Apache NiFi
-
NiFi Registry É um subprojeto do Apache NiFi - uma aplicação complementar que provê "localização centralizada" para armazenamento e gestão de recursos compartilhados por uma ou mais instâncias do NiFi ou MiNiFi.
Disponibiliza os seguintes recursos:
-
Implementação de Flow Registry para armazenar e gerenciar fluxos versionados.
-
Integração com NiFi para permitir armazenamento, retenção e atualização de fluxos versionados do Flow Registry.
-
Administração do Registry para definição de usuários, grupos e políticas.
A primeira implementação do Registry oferece suporte a fluxos versionados. Fluxos de dados em nível de grupo de processo criados em NiFi podem ser colocados sob controle de versão e armazenados em um registro. O registro organiza onde os fluxos são armazenados e gerencia as permissões para acessá-los, criá-los, modificá-los ou excluí-los.
A interface de Usuário(UI) do NiFi Registry exibe os recursos compartilhados disponíveis e fornece mecanismos para criar e administrar usuários/grupos, buckets e políticas). Após o NiFi Registry instalado, um navegador da Web compatível pode ser utilizado para visualizar a UI.
Buckets são containers que armazenam e organizam itens versionados, como fluxos e bundles(artefatos binários contendo uma ou mais extensões que podem ser executadas em NiFi ou MiNiFi). No momento os navegadores Chrome, Firefox e Safari são suportados.
Para os navegadores não suportados, embora não estejam testados ativamente, é possível a execução com êxito. Além disso, a interface do usuário foi projetada como uma experiência de desktop e atualmente não é compatível com navegadores móveis.
Para navegadores com tamanho variável, a UI fica visivel. A interface do usuário possui um design responsivo que permite a rolagem pelas telas conforme necessário em tamanhos menores ou ambientes de tablet.
-
-
MiNiFi É um subprojeto do Apache NiFi - abordagem de coleta de dados complementar que suplementa os princípios básicos do NiFi no gerenciamento de fluxo de dados, com foco na coleta de dados na origem da sua criação.
O Apache NiFi MiNiFi fornece os seguines recursos:
-
Tamanho pequeno e baixo consumo de recursos.
-
Gestão centralizada de agentes.
-
Geração de proveniência de dados com toda a cadeia de custódia da informação.
-
Integração com NiFi para gerenciamento de fluxo de dados subsequente.
O MiNiFi funciona como um agente que age imediatamente ou diretamente adjacente a sensores, sistemas ou servidores de origem.
-
-
Gerenciamento de Fluxos
-
Entrega Garantida: A filosofia principal do NiFi é que, mesmo em altíssima escala, a entrega garantida é a regra. Isto é alcançado pelo uso eficaz do WAL(log de gravação antecipada) e repositorio de conteúdo persistentes. Juntos eles são desenhados para permitir altas taxas de transações, distribuição de carga efetiva, copy-on-write e para "jogar" com as forças dos tradicionais read-writes no disco.
-
Data Buffering w/ Back Pressure e Pressure Release: NiFi suporta o armazenamento em buffer de todos os dados da fila e tem a capacidade de fornecer back pressure àquelas filas que atingiram os limites ou para "envelhecer" os dados quando atingem uma idade especificada (seu valor pereceu).
-
Enfileiramento priorizado: NiFi permite configurar um ou mais esquemas de priorização para a recuperação de dados de uma fila. O default é "primeiro o mais antigo" mas há momentos em que dados "mais novos", maiores, ou algum outro esquema personalizado são a regra.
-
Flow Specific QoS: (latência vs trroughput, baixa tolerância, etc.): Há pontos no Dataflow onde o dado é absolutamente crítico e intolerante a falhas. Há ainda momentos em que devem ser processados e entregues em segundos para gerar algum valor. NiFi habilita o refinamento da configuração de fluxo.
-
-
Facilidade de uso:
-
Comando e Controle Visual: Dataflows podem se tornar complexos. Proporcionar uma boa expressão visual pode ajudar a reduzir a complexidade e identificar áreas que precisam ser simplificadas. NiFi habilita o estabelecimento visual de Dataflows em tempo real. Mudanças no dataflow entram em vigor imediatamente. As alterações são refinadas e isoladas nos componentes impactados. Não é necessário interromper um fluxo inteiro ou conjunto de fluxos apenas para realizar uma modificação específica.
-
Templates: Dataflows tendem a ser altamente orientados a padrões e embora existam muitos caminhos diferentes para solucionar um problema, o compartilhamento de boas práticas por especialistas no assunto beneficia a todos, além de permitir que os próprios especialistas se beneficiem com a colaboração dos demais.
-
Proveniência de dados: NiFi registra, indexa e disponibiliza automaticamente dados de proveniência à medida que os objetos fluem pelo sistema, mesmo em fan-in, fan out, transformações e outros. Estas informações se tornam extremamente criticas no suporte à conformidade, solução de problemas, otimizações e outros cenários.
-
Recovery/gravação de buffer contínuo de histórico refinado: O repositório de conteudo NiFi é desenhado para agir como um buffer contínuo do history. Dado é removido do repositório de conteúdo apenas quando "envelhece" ou quando é necessário mais espaço. Isto combinado com capacidade de proveniência cria uma base incrivelmente útil para permitir o "click-to-content", download de conteúdo, reprodução, tudo num ponto específico do ciclo de vida de um objeto o qual pode abranger gerações.
-
-
Segurança:
-
System to System: Um Dataflow só é bom se for seguro. NiFi, em qualquer ponto do Dataflow, oferece troca segura com o uso de protocolos de criptografia como SSL bidirecional. Adicionalmente, permite que o fluxo criptografe e descriptografe o conteúdo e use chaves compartilhadas ou outros mecanismos em ambos os lados da equação remetente/destinatário.
-
User to System: NiFi permite a autenticação SSL bidirecional e provê autorização "plugável" para controlar o acesso pelo usuário em niveis específicos (somente leitura, gerenciador de fluxo de dados, administrador). Se um usuário inserir uma propriedade confidencial (como uma senha) no fluxo, ela será imediatamente criptografada no lado do servidor e nunca mais exposta no lado do cliente, mesmo em seu formato criptografado.
-
Autorização multi-locatário: O nivel de autoridade de um Dataflow é aplicado a cada componente, viabilizando que usuário admin tenha um nivel refinado de controle de acesso. Significa que cada cluster NiFi é capaz de lidar com os requisitos de uma ou mais organizações. Comparada a topologias isoladas, a autorização multi-locatário permite um modelo de autoserviço para gestão do dataflow e que cada time ou organização gerencie fluxos com total consciência do restante do fluxo, para os quais não têm acesso.
-
-
Arquitetura extensivel:
-
Extensão: NiFi é construído para extensão, e como tal, é uma plataforma na qual os processos de Dataflow podem ser executados e interagir de maneira repetitiva e previsivel.
-
Isolamento do Carregador de classe (classloader): Para qualquer sistema baseado em componentes, problemas de dependência podem ocorrer. NiFi endereça isto provendo um modelo de carga de classe personalizado, garantindo que cada pacote de extensão seja exposto a um conjunto muito limitado de dependências. Como resultado, extensões podem ser construídas sem se preocupar se podem entrar em conflito com outra extensão. O conceito destes pacotes de extensão é chamado "arquivos NiFi".
-
Protocolo de comunicação Site-to-Site: O protocolo de comunicação preferencial entre instâncias NiFi é o Protocolo NiFi Site-to-Site (s2s). S2S facilita a transferência de dados de uma instância NiFi para outra de forma eficiente e segura. As bibliotecas do cliente NiFi podem ser facilmente construídas e agrupadas em outros aplicativos ou dispositivos para se comunicar com o NiFi via S2S. Tanto o protocolo baseado em socket quanto o HTTP(s) são suportados no S2S como o protocolo de transporte subjacente, tornando possível incorporar um servidor proxy na comunicação S2S.
-
-
Modelo flexivel de escala:
-
Scale-out: (Expansão / Clustering)* NiFi é desenhado para escalabilidade horizontal por meio do uso de clustering de vários nós. Se um único nó for provisionado e configurado para lidar com centenas de MB por segundo, um Cluster modesto pode ser configurado para lidar com GB por segundo. Isto traz desafios de balanceamento de carga e failover entre NiFi e os sistemas dos quais obtem dados. O uso de protocolos baseados em filas assíncronas, como serviços de mensagem, kafka, etc. pode ajudar. O recurso site-to-site também é muito eficaz, pois é um protocolo que permite que o NiFi e um cliente (incluindo outro Cluster) conversem entre si, compartilhem informações sobre carregamento e troquem dados portas autorizadas específicas.
-
Scale-up e down: NiFi é também desenhado para scale-up e scale-down de uma maneira muito flexível. Em termos de "throughput", do ponto de vista da estrutura NiFi, é possível aumentar o número de tarefas simultâneas, no processador, na guia agendamento, durante a configuração. Isso permite que mais processos sejam executados simultaneamente, provendo grande throughput. Do outro lado do espectro, o NiFi pode ser dimensionado para execução em dispositivos de ponta, onde os recursos de hardware são limitados.
-
Diferença entre Apache Airflow e Apache NiFi:
Por natureza, o Airflow é uma estrutura de "orquestração" e não uma estrutura de processamento de dados.
Enquanto o objetivo principal do NiFi está relacionado à categoria de "stream processing"(processamento de fluxos), automatizando a transferência de dados entre dois sistemas, o Airflow está mais relacionado à "Workflow manager"(Gerenciamento de Workflows).
Importante ressaltar que as duas ferramentas não são mutuamente exclusivas e ambas oferecem recursos interessantes que auxiliam na solução de silos de dados( repositórios de dados isolados dentro da organização, sob o controle de um departamento, por exemplo).
O NiFi é uma ferramenta perfeita para Big Data. Não há melhor escolha quando se trata do tipo de pipeline "configure e esqueça".
O Airflow, por outro lado, é perfeito para agendamento de tarefas específicas, configuração de dependências e gerenciamento de fluxos de trabalho programáticos. Permite, com facilidade, a visualização de dependências, código, tarefas de gatilho, progresso, logs e status de sucesso de pipelines de dados.
Boas Práticas para o Apache NiFi
-
Ambientes separados para desenvolvimento
-
Considere o Usuário Um dos conceitos mais importantes no desenvolvimento de um "processador" ou qualquer outro componente é a experiência do usuário:
-
A documentação sempre deve ser fornecida para que todos possam utilizar o componente com facilidade.
-
Consistência (convenções de nomenclatura), simplicidade e clareza são princípios fundamentais para tornar esta experiência adequada.
-
-
Coesão e Reutilização Para criar uma unidade única e coesa, desenvolvedores são tentados a combinar várias funções em um único processador.
Adotar a abordagem de formatar dados para um ponto de extremidade específico e, em seguida enviá-los para este ponto no mesmo processador pode não ser vantajoso, pois:
-
pode tornar o processador muito complexo.
-
Se o processador não conseguir se comunicar com um serviço remoto, encaminhará os dados para um relacionamento failure e ficará responsável por realizar a tradução dos dados novamente, e novamente…
-
Se tivermos 5 diferentes processadores traduzindo dados de entrada em novo formato antes de enviá-los, teremos uma grande quantidade de codigo duplicado. Se o esquema mudar, muitos processadores devem ser atualizados.
-
Estes dados intermediários são descartados quando o processador termina de enviar para o serviço remoto. O formato intermediário pode ser útil para outros processadores.
Para evitar estes problemas e tornar os processadores mais reutilizáveis, um processador deve sempre seguir o principio: "fazer uma única coisa e fazê-lo bem". Ele deve ser dividido em dois processadores separados: um para converter os dados do formato X para Y e outro para enviar dados ao recurso remoto.
-
-
Convenções de Nomenclatura Para fornecer uma aparência consistente aos usuários, é aconselhável que os processadores mantenham as convenções de nomenclatura padrão:
-
Processadores que extraem dados de um sistema remoto são denominados:
-
Get<Service> (pesquisam dados de fontes arbitrárias por meio de protocolo conhecido, como GetHTTP, GetFTP) ou
-
Get<Protocol> (pesquisam dados de um serviço conhecido como GetKafka).
-
-
Processadores que enviam dados para um sistema remoto são denominados:
-
Put<Service> ou
-
Put<protocolo>.
-
-
Nomes de relacionamentos são caixa baixa e usam espaço para delinear palavras.
-
Nomes de propriedade devem usar palavras significativas, como o título de um livro.
-
-
Anotações de comportamento do Processador: Ao criar um processador, o desenvolvedor deve fornecer dicas para a estrutura como utilizá-lo com mais eficiência.
Isto é feito aplicando anotations à classe do processador.
As anotações que podem ser aplicadas estão em três sub-pacotes de arquivos _org.apache.nifi.annotation.
-
subpacote documentation : Fornecem documentação ao usuário.
-
Subpacote lifecycle: Instruem a estrutura sobre quais métodos devem ser chamados no processador para responder aos eventos de ciclo de vida apropriados.
-
Subpacote behavior: Ajudam a estrutura a entender como interagir com o processador em termos de agendamento e comportamento geral.
As seguintes anotações do pacote podem ser usadas para modificar como a estrutura lidará com seu processador (para obter mais detalhes, clique aqui):
-
EventDriven: instrui a estrutura de que o processador pode ser agendado usando a estrategia de agendamento orientada a eventos.
-
SideEffectFree: indica que o processador não tem nenhum efeito colateral externo ao NiFi.
-
SupportsBatching: indica que não há problema em a estrutura agrupar várias confirmações de ProcessSession em uma única confirmação.
-
TriggerSerially: impede que o usuário agende mais de uma thread concorrente para executar o método onTrigger de uma vez.
-
PrimaryNodeOnly: restringe a execução do processador apenas no Primary Node.
-
TriggerWhenAnyDestinationAvailable: Indica que o processador deve ser executado se algum relacionamento estiver "disponível" mesmo se uma das filas estiver cheia.
-
TriggerWhenEmpty: ignora o tamanho das filas de entrada e aciona o processador, independentemente de haver ou não dados em uma fila de entrada.
-
InputRequirement: ao fornecer um valor por meio desta anotação (INPUT_REQUIRED, INPUT_ALLOWED ou INPUT_FORBIDDEN), a estrutura saberá quando deve ser invalidada ou se o usuário deve ou não ser capaz de estabelecer uma conexão com o processador.
-
-
Buffer de Dados O NiFi fornece uma capacidade genérica de processamento de dados. Os dados podem estar em qualquer formato.
Os processadores geralmente são escalonados com vários threads.
Um erro comum dos desenvolvedores é armazenar em buffer todo o conteúdo de um FlowFile na memória.
Salvo em casos em que é absolutamente necessário, isso deve ser evitado, a menos que se conheça o formato dos dados.
Em vez de armazenar esses dados em buffer na memória, é aconselhável avaliar os dados à medida em que são transmitidos do Repositório de Conteúdo (ou seja, o conteúdo do inputStream fornecido pelo retorno de chamada do _ProcessSession.read).