Apache Solr
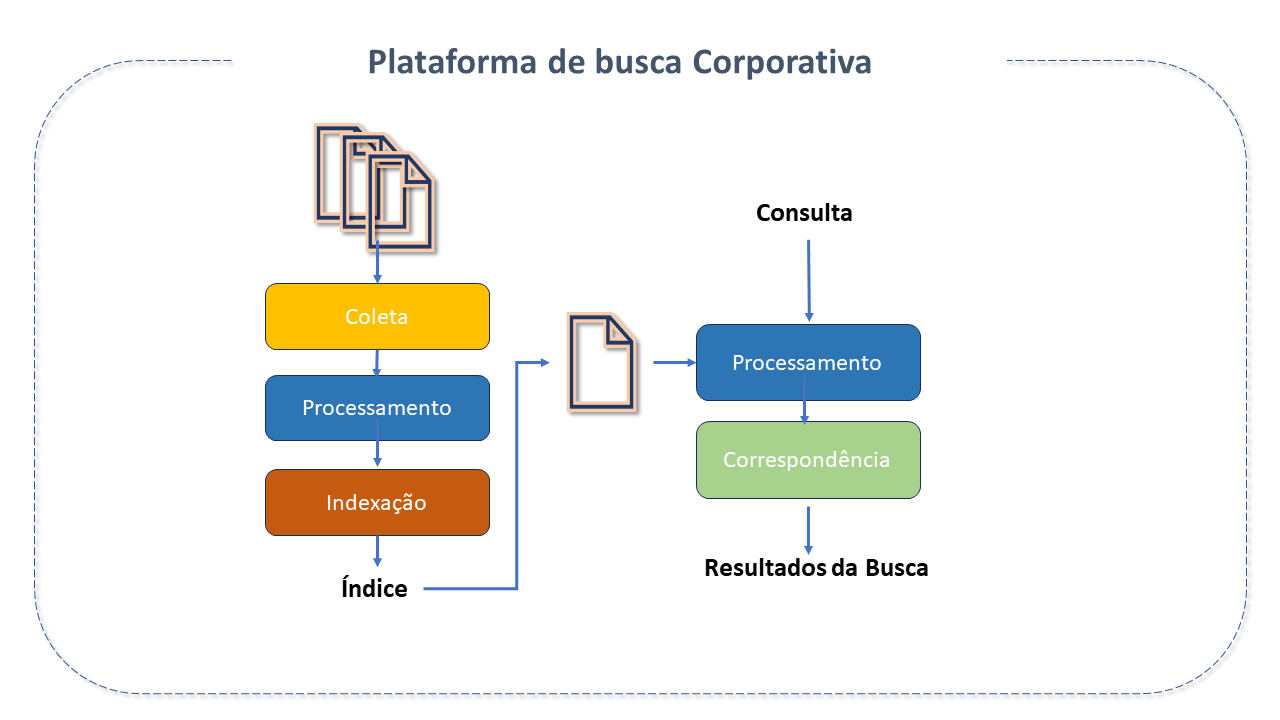
Plataforma de Busca Corporativa
Plataformas de Busca Corporativa têm a função de criar uma função de pesquisa segura, poderosa e fácil de usar.
Quando aplicadas a contextos de negócios, geralmente se integram a soluções da inteligência de negócios e gerenciamento de dados, e são usadas para "limpar" e estruturar dados, tornando as informações mais fáceis de localizar, podendo extrair informações de fontes distintas, como CRM, ERP, etc.
Para se qualificar como uma plataforma de pesquisa corporativa, é necessário que o produto:
-
Trate informações de distintas fontes, tipos e formatos de dados.
-
Indexe ou arquive dados.
-
Forneça opções de pesquisa inteligente.
-
Ofereça uma interface para pesquisa e recuperação de dados.
-
Permita que usuários refinem suas pesquisas por meio de filtros avançados.
-
Defina permissões para acesso a informações.
Características do Apache Solr
O Apache Solr é uma plataforma de pesquisa corporativa de código aberto, construída sobre o Apache Lucene, projetada para recuperação de documentos.
O Apache Solr foi criado em 2004 por Yonik Seeley, na CNET Networks, como um projeto interno para adicionar capacidade de pesquisa ao site da empresa.
-
Em janeiro de 2006 seu código fonte foi doado à Apache Software Foundation e, em 2007, já era considerado um projeto autônomo de nível superior(TLP), tendo crescido continuamente com recursos acumulados, atraindo usuários, colaboradores e commiters.
-
Foi lançado pela Apache em 2008, na versão 1.3 e, em 2010, fundiu-se com o Lucene(seu esquema de versão foi alterado em 2011 para corresponder com o do Lucene).
-
Em 2020 a Bloomberg doou o operador Solr para o projeto Lucene/Solr, o que viabilizou a implantação e execução do Solr no Kubernetes.
-
Em 2021 o Solr foi estabelecido como um projeto Apache separado(TLP), independente do Lucene. Sua primeira versão independente foi a 9.0.
O Solr é amplamente usado para casos de uso de pesquisa e análise corporativa. É desenvolvido de forma aberta e colaborativa pelo Projeto Apache Solr, na Apache Software Foundation. Possui uma comunidade de desenvolvimento muito ativa com lançamentos regulares.
Dentre suas principais características, destacamos:
-
Recursos de busca Advanced Full-Text: Habilitando recursos avançados de busca, incluindo correspondência de frases, uso de wildcards para flexibilizar as pesquisas, além de suportar junções e agrupamentos em qualquer tipo de dado.
-
Otimizado para tráfico de alto volume: Tendo sido comprovado em escalas extremamente grandes em todo o mundo.
-
Interfaces abertas: Baseadas em padrões XML, JSON e HTTP.
-
Interfaces de Administração abrangentes: Contando com uma interface de usuário administrativa responsiva integrada para facilitar o controle de suas instâncias.
-
Facil monitoramento: Publicando cargas de dados métricos via JMX.
-
Altamente escalável e tolerante a falhas :
-
Construido no Apache Zookeeper, torna fácil escalar para mais ou para menos.
-
Oferece replicação, distribuição, rebalanceamento e tolerância a falhas.
-
-
Flexível e adaptável com configuração simples: Configurações de esquema flexíveis, que permitem o armazenamento de quase qualquer tipo de dado no Solr.
-
Indexação near Real-time: Permitindo que alterações sejam vistas em qualquer tempo.
-
Arquitetura de Plugin extensível: Publica muitos pontos de extensão que facilitam a incorporação de plugins de índice e query time, permitindo( por ser uma licença open-source), que seu código seja alterado à vontade.

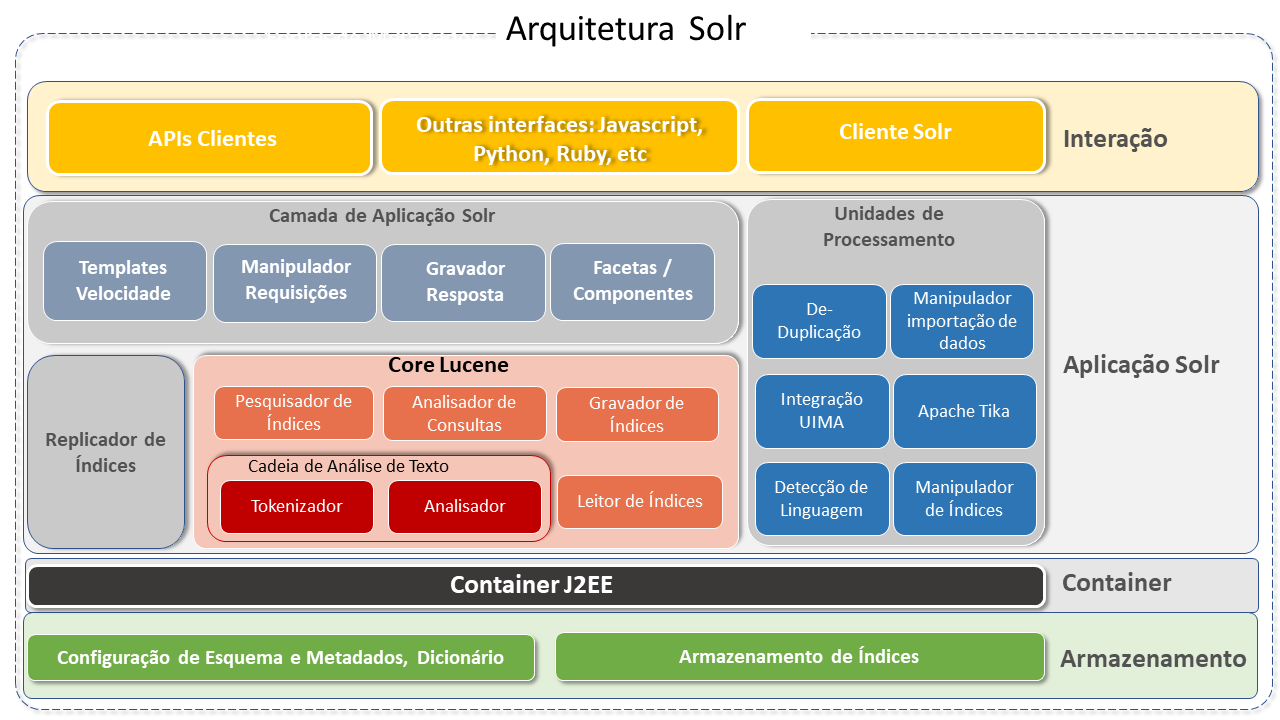
Arquitetura do Apache Solr
O Apache Solr foi projetado para escalabilidade e tolerância a falhas. É executado como um servidor de pesquisa de texto autônomo.
Apache Solr executa sobre a biblioteca de software Lucene que é, de fato, a engine que o potencializa. O núcleo Solr é uma instância do índice Lucene, onde ficam todos os arquivos de configuração necessários para usá-lo. A Biblioteca de pesquisa Lucene Java é utilizada para indexação e pesquisa de texto completo e possui APIs HTTP/XML e JSON semelhantes a REST que tornam Solr utilizável nas linguagens de programação mais populares.
Sua configuração externa permite que se adapte a muitos tipos de aplicativos sem codificação Java e sua arquitetura de plug-in oferece suporte a personalizações mais avançadas.
As consultas SOLR são URLs de solicitação HTTP simples e as respostas são um documento estruturado no formato JSON, XML, CSV ou outro. Os documentos (indexing) são colocados nele via JSON, XML, CSV ou binário sobre HTTP. É consultado via HTTP GET e recebe resultados JSON, XML, CSV ou binário.
Solr executa numa arquitetura não-escrava, pois todo nó é seu próprio master. Os nós usam Zookeeper para aprender sobre o estado do Cluster e cada nó (JVM) pode hospedar vários núcleos (onde o Lucene é executado).
As consultas são configuradas e gerenciadas nos arquivos schema.xml e solrconfig.xml.
Os principais componentes da arquitetura Apache Solr são:
-
Request Handler(manipulador de requisições): As requisições recebidas no Apache Solr são processadas pelo Request Handler. A requisição pode ser de consulta ou atualização de índice. Baseada na requisição, o request handler é selecionado. Geralmente, há o mapeamento do manipulador para um end-point URI por meio do qual a requisição será atendida.
-
Search Handler (Componente de Busca): Provê o recurso de busca ao Apache Solr. Podendo ser um spell checking, consulta, faceting, hit highlighting, etc.
-
Query Parsers(Analisadores de Consulta): Realizam a análise das consultas e verificam se existem erros de sintaxe. Após a análise, traduz as consultas em um formato compreendido pelo Lucene. O Solr suporta vários query parsers.
-
Response Writer(Gravador de resposta): É o componente que gera a saída formatada para a consulta do usuário. Os formatos suportados são XML, JSON, CSV, etc. Existem diferentes response writers para cada tipo de respostas.
-
Analisador / tokenizador: Lucene reconhece dado na forma de tokens. O Apache Solr analiza o conteúdo, divide-o em tokens e repassa estes tokens para o Lucene. Um Analisador no Apache Solr examina o texto de campos e gera um "fluxo de token". Um tokenizador divide o fluxo de token preparado para o analizador em tokens.
-
Update Request Processors(Processadores de Requisições de Update): Toda requisição de "update"(atualização) executará por meio de um conjunto de plugins (assinatura, registro, indexação), coletivamente conhecidos como "processador de requisição de atualização". Este processador é responsável por modificações como "remoção de campo, adição de campo, etc."
Terminologia do Apache Solr
-
Cluster: Nós Solr operando entre si, de forma coordenada, por meio do Zookeeper, e gerenciados como uma unidade. Um Cluster pode conter várias coleções.
-
Coleções: Um ou mais documentos agrupados em um índice lógico único usando uma única configuração e Schema. Na nuvem, a coleção pode ser dividida em múltiplos fragmentos lógicos, que, por sua vez, podem ser distribuídos ao longo de vários nós ou em um único nó.
-
Nó: Na nuvem Solr, cada instância única do Solr é considerada um nó.
-
Commit: que viabiliza as mudanças de forma permanente no índice.
-
Core: Uma instânciaindividual do Solr (que representa um índice lógico). Vários cores podem executar em um único nó.
-
Shard(fragmento): É uma partição lógica da coleção que possui um subconjunto de documentos dela, de forma que cada documento em uma coleção esteja contido exatamente em um Shard.
Quando um documento é enviado a um nó para indexação, o ssitema primeiro determina a qual "shard" o documento pertence, e, em seguida, qual nó hospeda seu Líder, encaminhando o documento para este líder para indexação, que, por sua vez encaminhará para todas as outras réplicas.
-
Replication(Replicação): Quando o índice é muito grande para uma única maquina e há um volume de consultas que "shards" únicos não possam acompanhar, é o momento de replicar cada "shard".
No núcleo Solr, a réplica é uma cópia do shard que é executada em um nó.
-
Líder: É a réplica do shard que distribui as requisições do Solr Cloud para as demais réplicas.
Recursos do Apache Solr
O Solr oferece recursos ricos e flexíveis para pesquisa. Seus principais recursos incluem:
-
Pesquisa de texto: Empoderado pelo Lucene, o Solr permite recursos de correspondência como frases, wildcards, joins, agrupamentos e outros em qualquer tipo de dado.
-
Highlighting(Realce de ocorrências): Permite que fragmentos de documentos que correspondam à consulta sejam incluídos na sua resposta.
-
Faceting(Pesquisa facetada): é a organização dos resultados da pesquisa em categorias com base em termos indexados.
-
Indexing (Indexação em tempo real): O Solr permite que seja criado um índice com muitos campos distintos ou tipos de entrada. Um índice Solr pode aceitar dados de muitas fontes diferentes, como XML, CSV ou dados extraídos de tabelas em bancos de dados e arquivos em formatos comuns como Work ou PDF.
-
Result Collapsing and Expanding(Recolhimento e Expansão de Resultados): Agrupa documentos (recolhendo o conjunto de resultados) segundo parametros e provê acesso ao documento no agrupamento "recolhido" para uso em "display" ou aplicativo.
-
SpellChecking: Projetado para fornecer sugestões de consulta em linha com base em outros termos similares.
-
Integração com banco de dados
-
Recursos NoSQL e
Alguns dos sites mais famosos da Internet usam Solr, como o Macy, Ebay, Zappo.
Boas Práticas para o Apache Solr
-
Campos indexados O uso de armazenamento em nuvem pode ser bastante otimizado por meio do controle do número de campos indexados .
Índices representam um fator crítico entre qualidade, performance e custo e, em grande quantidade, pode degradar performance e incrementar custos.
Na definição de campos, procure não marcar campos como indexed=true se eles não são usados numa consulta.
O número de campos indexados aumenta:
-
o uso de memória durante a indexação.
-
o tempo de mesclagem de segmentos.
-
o tempo de otimização .
-
o tamanho do índice.
-
-
Armazenamento de campos Recuperar campos armazenados do resultado de consulta pode ser oneroso. Esse custo é afetado pelo número de bytes armazenados por documento. Quanto maior a contagem de bytes , mais esparsa será a distribuição dos documentos no disco - o que demandará mais largura de banda de E/S para recuperar os campos desejados. Eses custos aumentam nas implementações em nuvem. Obviamente, seu uso deve avaliar qualidade, desempenho e custo.
-
Utilização do Cache Solr Solr armazena em cache vários tipos de informações para garantir que consultas semelhantes não se repitam desnecessariamente. O Document Cache ajuda a melhorar o tempo para atender solicitações.
Existem três tipos principais de cache:
-
Query cache: armazena IDs de documentos retornados pelas consultas.
-
Filter cache: armazena filtros criados pelo Solr em resposta aos filtros adicionados às consultas.
-
Document cache: armazena os campos do documento solicitado quando os resultados das consultas são mostrados.
-
-
Autowarming A ativação do autowarming pode incrementar de forma significativa a performance de uma pesquisa para qualquer dos três tipos de cache. Ao incrementar o autowarmCount, o Solr irá pré-preencher ou realizar "autowarm" no cache com os objetos de cache criados pelo resultado da busca. Esta configuração indica o número de itens em cache que serão copiados para o novo "buscador". _
-
Expressões Streaming O Solr oferece uma linguagem de processamento de streams simples, mas poderosa para o Solr Cloud. Expressões de streaming são um conjunto de funções que podem ser combinadas para executar muitas tarefas de computação paralela.
-
Heap da Memória JVM O heap é uma área da memória em que são armazenados os objetos da aplicação, criados a partir de classes (com semântica de referência). Nele são alocados objetos referenciados em algum lugar.
Esta área é gerenciada pelo garbage collector e vai ocupando espaços conforme a necessidade. O GC, em algum momento futuro, vai liberar os espaços quando os dados de uma determinada porção não são mais necessários.
No caso da memória JVM (Java Virtual Machine), boa parte da alocação já é reservada com antecedência pelo GC, que tenta administrar a memória da melhor forma possível.
As configurações de heap da memória JVM afetam diretamente a utilização de recursos do sistema.Em um ambiente de "nuvem" o uso de recursos e custos podem aumentar rapidamente, o que pode afetar diretamente a performance e o sucesso ou falha da implementação de uma busca.
-
Adicionando espaço suficiente: Várias ferramentas, geralmente incluídas nas instalações padrão Java mostram a quantidade mínima de memória consumida pela JVM ao executar o Solr (inclusive jconsole).
Sem memória suficiente para o heap, a JVM pode aumentar o consumo de recursos devido à execução frequente do processo de garbage collection(coleta de lixo).
É recomendável um adicional de 25% a 50% sobre a memória mínima necessária para operar com desempenho máximo.
-
Memória S.O.: É necessário cuidado na alocação de heap de memória JVM, pois Solr usa extensivamente o componente org.apache.lucene.store.MMapDirectory. Este componente aproveita o Sistema Operacional(S.O.) que é usado pelo componente MMapDirectory.
Desta forma, quanto mais heap de Memória JVM for alocada, menos memória estará disponível para o Sistema operacional, o que também prejudica o desempenho da pesquisa.
É necessário encontrar um ponto de equilibrio.
-
Tamanho ideal do _heap de memória JVM: Um intervalo entre 8 e 16 Gb é adequado. Recomenda-se iniciar com o menor valor e executar testes, monitorando o uso da memória, e ajustando, gradualmente, o tamanho, até alcançar o tamanho ideal.
-
Garbage Collector: (Coleta de lixo) É um termo usado para o processo em que a memória liberada em um programa Java retorna ao "pool" de memória para reutilização.
O coletor utilizado antes da versão 9 do Java era o ParallelGCf. O Coletor G1GC opera de forma multiencadeada simultânea a aborda problemas de latência existentes no ParallelGC.
Recomenda-se, portanto, seu uso.
Além disso, o script de controle do Solr vem com um conjunto de configurações de coleta de lixo Java pré-configuradas que funcionam bem para várias cargas de trabalho distintas. Mas estas configurações podem não funcionar tão bem para algum uso específico.
Neste caso, as configurações do GC podem ser alteradas, o que também deve ser feito com a variável GC_TUNE no arquivo /etc/default/solr.in.sh.
-
Ajustes finos recomendados na configuração de produção
-
Configurações de memória e GC: Por default, o script bin/solr configura o tamanho máximo de heap Java para 512M (-Xmx512m), o que é um número razoável para começar a trabalhar com Solr.
Para a produção, é adequado ajustar o tamanho máximo baseado nos requisitos de memória dos aplicativos de busca. Valores entre 10 e 20 Gb são comuns. Para mudar estas configurações, use a variável SOLRJAVAMEM:
solr_java_mem="-Xms10g -Xmx10g" -
Shutdown por falta de memória: O script bin/solr registra script bin/oom_solr.sh a ser chamado pela JVM se ocorrer um erro OutOfMemory, que emitirá um kill -9 para o processo Solr.
Esse comportamento é recomendado ao executar no modo SolrCloud para que o Zookeeper seja imediatamente notificado de que um nó está apresentando um erro irrecuperável.
É recomendável inspecionar o conteúdo do script /opt/solr/bin/oom_solr.sh para se familiarizar com as ações que o script executará se for chamado pela JVM.
-
SolrCloud: Para executar o Solr no modo SolrCloud é necessário definir a ZK_HOST no arquivo de inclusão para apontar para o conjunto Zookeeper.
A execução do Zookeeper incorporado não é suportada em ambientes de produção. Se um conjunto Zookeeper estiver hospedado, por exemplo, em três hosts na porta cliente padrão 2181(zk1, zk2, zk3), será necessário definir:
zk_host=zk1,zk2,zk3Quando a variável ZK__HOST for definida, o Solr iniciará no modo "nuvem".
-
Zookeeper: Ao usar uma instância do Zookeeper compartilhada por outros sistemas, é recomendável isolar a "árvore" SolrCloud znode usando o suporte chroot do Zookeeper.
Para garantir que todos os znodes criados pelo SolrCloud sejam armazenados em /solr, por exemplo, use:
zk_host=zk1,zk2,zk3/solrAntes de usar um chroot pela primeira vez, é necessário criar o caminho raiz (znode) no Zookeeper usando o script de controle Solr. O Comando mkroot pode ser usado:
bin/solr zk mkroot /solr -z <ZK_node>:<ZK_PORT> -
Hostname Solr: Use a variável SOLR_HOST no arquivo de inclusão para definir o nome do host do servidor Solr.
solr_host=solr1.example.comIsto é especialmente recomendável ao executar no modo SolrCloud, pois determina o endereço do nó quando ele se registra no Zookeeper.
-
Substituição de configurações em solrconfig.xml: Solr permite que as propriedades de configuração sejam substituídas usando propriedades do sistema Java passadas na inicialização por meio da sintaxe -Dproperty=value.
-
Executando vários nós Solr por host O bin/solr é capaz de executar várias instâncias em uma máquina, mas para uma instalação típica, essa configuração não é recomendada. Recursos extras de CPU e memória serão necessários para cada instância adicional.
-
Esta regra não se aplica quando se discute escalabilidade extrema. A execução de vários nós Solr em um host é uma boa alternativa quando queremos reduzir a necessidade de heaps extremamente grandes. Para mais detalhes veja aqui.
-