Vector Databases
Specialized system for storing, managing, and querying high-dimensionality data (vectors/embeddings). Unlike traditional databases that search for exact matches, vector databases find data by similarity, being fundamental for AI applications such as semantic search, recommendation systems, and LLMs.
Fundamental Concepts
Vector: List of numbers representing coordinates in multidimensional space.
- Example:
[12, 13, 19, 8, 9] - Just as (x, y) defines a 2D point, vectors define points in spaces of hundreds or thousands of dimensions
Embedding: Numerical vector representation of data (text, image, audio) generated by Machine Learning models.
- Semantically similar data generates embeddings close in vector space
- Example: "weather forecast" and "will it rain?" have numerically close embeddings
How It Works
The similarity search process involves two stages:
1. Indexing
- Raw data (text, image, product) is processed by ML model
- Model generates numerical vector (embedding) capturing data characteristics
- Vector is stored with reference to original data
- Semantically similar vectors are organized close in space
2. Search
- Query is converted to numerical vector (embedding) using the same ML model
- Optimized algorithms calculate distances between vectors
- System returns original data from closest vectors
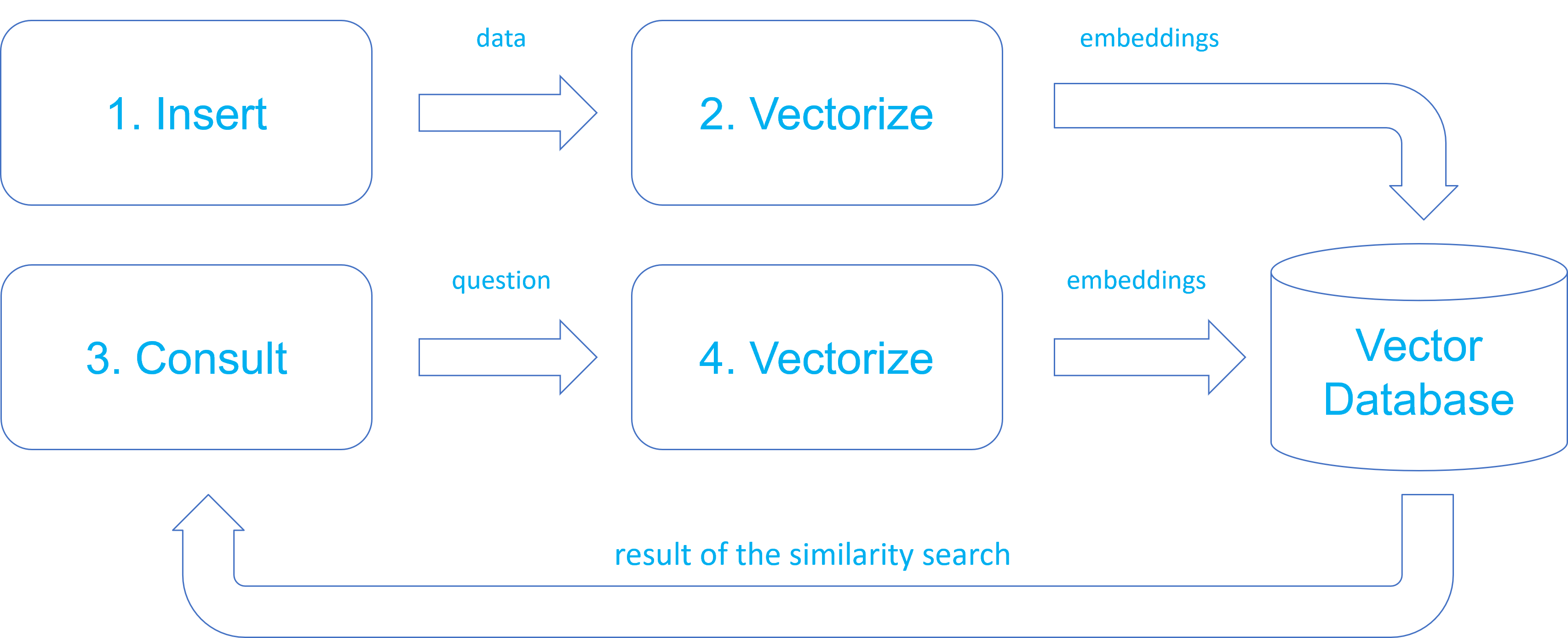
Data vectorization (embedding generation) is done once, during indexing, and vectors are stored in the vector database.
During query, the search text is vectorized and the vector database calculates similarity between the search vector and stored vectors.
Use Cases
| Application | Description | Examples |
|---|---|---|
| Semantic Search | Finds contextually relevant information regardless of exact keywords | Image search, article recommendation, document search |
| Recommendation Systems | Suggests similar items based on characteristics and preferences | Products, music, movies, content |
| ML/Deep Learning | Long-term memory for models - stores embeddings for fast query | Feature cache, transfer learning |
| LLMs and Generative AI | Provides additional context via RAG (Retrieval-Augmented Generation) | ChatGPT with external knowledge, specialized assistants |
Advantages
Querying ML models directly for each search is expensive, slow, and not scalable. Vector databases solve this:
| Advantage | Benefit |
|---|---|
| Efficiency | Data processed once during indexing; queries in milliseconds |
| Cost-Effectiveness | Eliminates continuous reprocessing by AI model |
| Scalability | Supports billions of vectors without performance loss |
| Persistent Memory | Stores knowledge accessible quickly and contextually |
pgvector
Open-source extension that adds vector operations and similarity search support to PostgreSQL, allowing direct storage, indexing, and querying of vector data in the database.
Main features:
- Efficient storage of dense vectors
- Fast similarity search with multiple distance operators
- Native integration with PostgreSQL query planner
- Support for specialized indexing (IVFFlat and HNSW)
vector Data Type
pgvector introduces the vector(n) data type, where n represents the number of dimensions.
Characteristics:
- Dimensionality: Through parameter
nyou can specify vector dimensionality (e.g.,vector(1536)for OpenAI embedding models). When omitted, the column accepts vectors of any dimension. - Storage: Compact binary format in PostgreSQL data pages
- Validation: If
nis specified, ensures dimensional consistency across all entries
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536) -- OpenAI text-embedding-ada-002
);
INSERT INTO documents (content, embedding)
VALUES ('Example text', '[0.1, 0.2, ..., 0.9]');
Operators for Distance Calculation Between Vectors
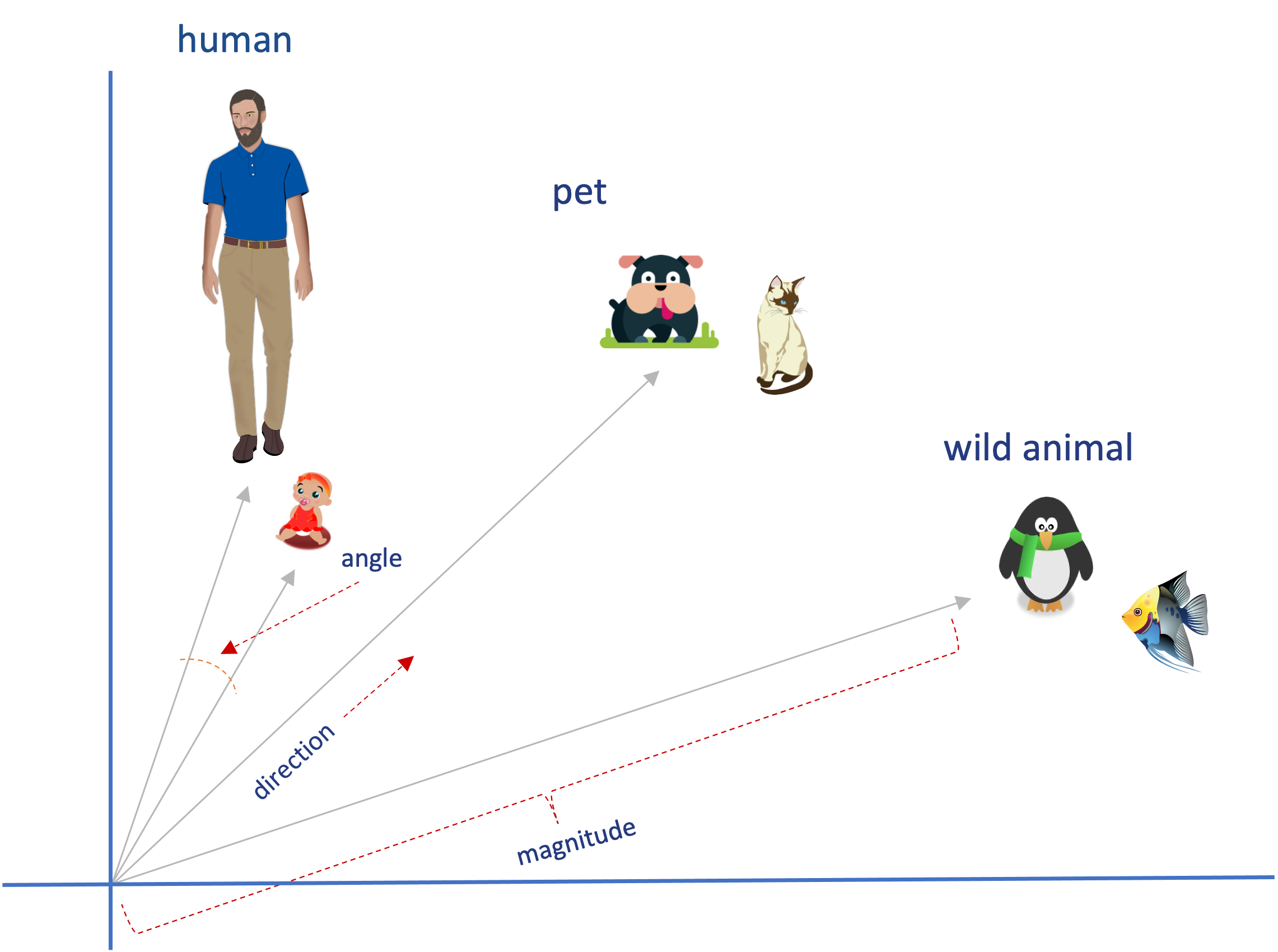
Similarity search calculates distance between vectors considering three main aspects:
-
Magnitude (size): Measure of vector length. Higher numerical value means greater magnitude. In 2D coordinates, for example, a vector with greater magnitude will be "longer" than one with lesser magnitude.
-
Direction (orientation): Direction the vector points. In 2D coordinates, a vector with horizontal (or vertical) direction points right (or down).
-
Alignment (angle between vectors): Angle between two vectors. Smaller angle means more aligned and greater similarity. 0° angle indicates perfectly aligned vectors (same direction), while 180° indicates opposite vectors.
In Figure 2, we see an example of 2D vectors considering the three aspects above.
pgvector provides three main operators for distance calculation between vectors:
| Operator | Name | Description | Recommended Use |
|---|---|---|---|
<-> | Euclidean Distance (L2) | Straight-line distance between vectors | Images, geographic coordinates |
<=> | Cosine Distance | Angle between vectors (direction) | Text embeddings (most common) |
<#> | Inner Product | Projection of one vector onto another | Recommendation systems |
Let's see a practical example:
-- Create table with 2D vectors
CREATE TABLE items (
id SERIAL PRIMARY KEY,
nome TEXT,
categoria TEXT,
embedding VECTOR(2)
);
-- Insert sample data
INSERT INTO items (nome, categoria, embedding) VALUES
('Man', 'Human Being', '[2, 8]'),
('Child', 'Human Being', '[3, 7]'),
('Dog', 'Domestic Animal', '[6, 7]'),
('Cat', 'Domestic Animal', '[7, 7.5]');
-- Search for the 3 items closest to 'Man' vector ([2, 8]) using Euclidean Distance
SELECT nome, categoria, embedding <-> '[2, 8]' AS distancia
FROM items
ORDER BY distancia
LIMIT 3;
Result:
| nome | categoria | distancia |
|---|---|---|
| Man | Human Being | 0 |
| Child | Human Being | 1.4142 |
| Dog | Domestic Animal | 4.1231 |
Indexes for Vector Search
To avoid sequential searches in tables with millions of vectors, pgvector offers ANN (Approximate Nearest Neighbor) indexes that significantly speed up similarity searches.
IVFFlat (Inverted File with Flat Compression)
Clustering-based index that partitions vector space using k-means. During query, searches only in clusters closest to input vector.
Characteristics:
- Requires training phase during creation, i.e., prior vector insertion
- Approximate search with precision/speed trade-off
- Lower memory usage and fast construction
-- Creation (lists ≈ sqrt(total_rows))
CREATE INDEX items_embedding_idx ON items
USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
-- Search configuration
SET ivfflat.probes = 10; -- Number of clusters to check
-- Query
SELECT id, content FROM items
ORDER BY embedding <-> '[1, 2, 4]' LIMIT 5;
Parameters:
| Parameter | Description | Recommendation |
|---|---|---|
lists | Number of clusters | sqrt(rows) for large datasets |
probes | Clusters checked in search | 10 (adjust for precision/speed) |
HNSW (Hierarchical Navigable Small World)
Hierarchical graph index that navigates multiple layers to find close neighbors. Offers higher precision than IVFFlat.
Characteristics:
- No training phase
- High precision (recall > 95%)
- Higher memory usage and slower construction
-- Creation
CREATE INDEX items_embedding_hnsw_idx ON items
USING hnsw (embedding vector_l2_ops)
WITH (m = 16, ef_construction = 64);
-- Search configuration
SET hnsw.ef_search = 40; -- Dynamic list during query
-- Query
SELECT id, content FROM items
ORDER BY embedding <-> '[1, 2, 4]' LIMIT 5;
Parameters:
| Parameter | Description | Default Value | Recommendation |
|---|---|---|---|
m | Connections per layer | 16 | 16-32 |
ef_construction | Construction quality | 64 | 64-200 |
ef_search | Search precision | 40 | 40-400 |
Index Comparison
| Criterion | IVFFlat | HNSW |
|---|---|---|
| Precision | Moderate (80-95%) | High (>95%) |
| Speed | Fast | Fast and consistent |
| Memory | Moderate | High |
| Construction | Fast | Slow |
| Recommended use | Large datasets, prototyping | Production, high precision |
Source: https://github.com/pgvector/pgvector
pgembed
While extensions like pgvector prepare PostgreSQL to store and query vector data, the process of generating those vectors - vectorization (embedding) - still needs to be executed separately.
Normally, this process requires an application or pipeline to communicate with an external Machine Learning model, such as those offered by OpenAI, or locally with models available in Ollama. This may require broader technical knowledge from the data team or involvement of various professionals with varied expertise.
In many cases, projects focused on validating the Minimum Viable Product (MVP) choose to develop functions in PostgreSQL itself that consume vectorization services and facilitate this activity.
However, it's common for best practices, such as using batch data to reduce network traffic, memory consumption management, security configurations, and resilience mechanisms, to be neglected in this approach.
Aiming to provide a set of functions for data vectorization in PostgreSQL, focusing on performance, security, and resilience, Tecnisys developed the pgembed extension.
Vectorization Functions
After installing and creating the pgembed extension, various functions for data vectorization will be available in the pgembed schema of the database, organized by embedding API provider and input data type:
| Provider | Single Text Line | Row Set | Table |
|---|---|---|---|
| Ollama (local) | embed_ollama | embed_batch_ollama | embed_table_ollama |
| OpenAI | embed_openai | embed_batch_openai | embed_table_openai |
| Custom APIs | embed_custom | embed_batch_custom | embed_table_custom |
Function Types:
- Single Text Line (
embed_*): Generates embedding for a single text line. For example:SELECT pgembed.embed_openai('Hello, world!', 'text-embedding-3-small'); - Row Set (
embed_batch_*): Processes multiple text lines and returns a list of vectors. For example:SELECT * FROM pgembed.embed_batch_openai(ARRAY['Hello, world!', 'Hello, PostgreSQL!'], 'text-embedding-3-small'); - Table (
embed_table_*): Reads text column from a table and automatically updates corresponding embeddings column, eliminating need for manual update operations. For example:SELECT * FROM pgembed.embed_table_openai(
'public', -- schema
'tb_documents', -- table name
'content', -- content column
'embedding', -- embedding column
FALSE, -- regenerate: only update NULL embeddings (default: FALSE)
1000, -- batch_size
'text-embedding-3-small' -- model
);
Advanced Parameters
Besides mandatory parameters, pgembed extension functions have several extremely useful advanced parameters, such as:
- Request timeout (
timeout, default 60s) - Whether SSL certificate should be verified (
verify_ssl, default TRUE) - Whether text should be truncated if it exceeds context size (
truncate, default TRUE, for Ollama models) - JSON for advanced options for each model (
options, for Ollama models) - Number of dimensions of generated embeddings (
dimensions, for OpenAI models) - Encoding format of returned embeddings (
encode_format, for OpenAI models)
Security and Resilience
Regarding security and resilience, the pgembed extension provides parameters that can be configured at user, session, and database level, such as:
pgembed.openai_api_keyorpgembed.custom_api_keyto define API key used in service requestpgembed.url_allowlistto define list of authorized URLs. By default: localhost, 127.0.0.1, 0.0.0.0 (any port), *.openai.com and api.openai.compgembed.max_retries,pgembed.initial_backoff_ms,pgembed.max_backoff_msfor retry controlpgembed.circuit_breaker_thresholdandpgembed.circuit_breaker_reset_timeout_sto prevent cascading failures from temporarily blocking requests to unavailable services