Database
Database Models
Relational
Founded in 1970 by E.F. Codd, who proposed an intuitive and straightforward approach to representing data, the relational model allows for the effective representation of relationships between data, facilitating complex queries and ensuring data integrity.
In the relational model, data is organized into tables (entities and relationships), consisting of columns and rows (tuples), with unique identifying values for each row (primary keys). Each row in a table shares the same set of named columns, and each column has a specific data type. The keys that identify the rows are used to define relationships between tables.
Tables in relational models can have one-to-one, one-to-many, and many-to-many relationships. Typically, a many-to-many relationship is implemented with an additional table (association table) that contains the primary keys of the related tables.
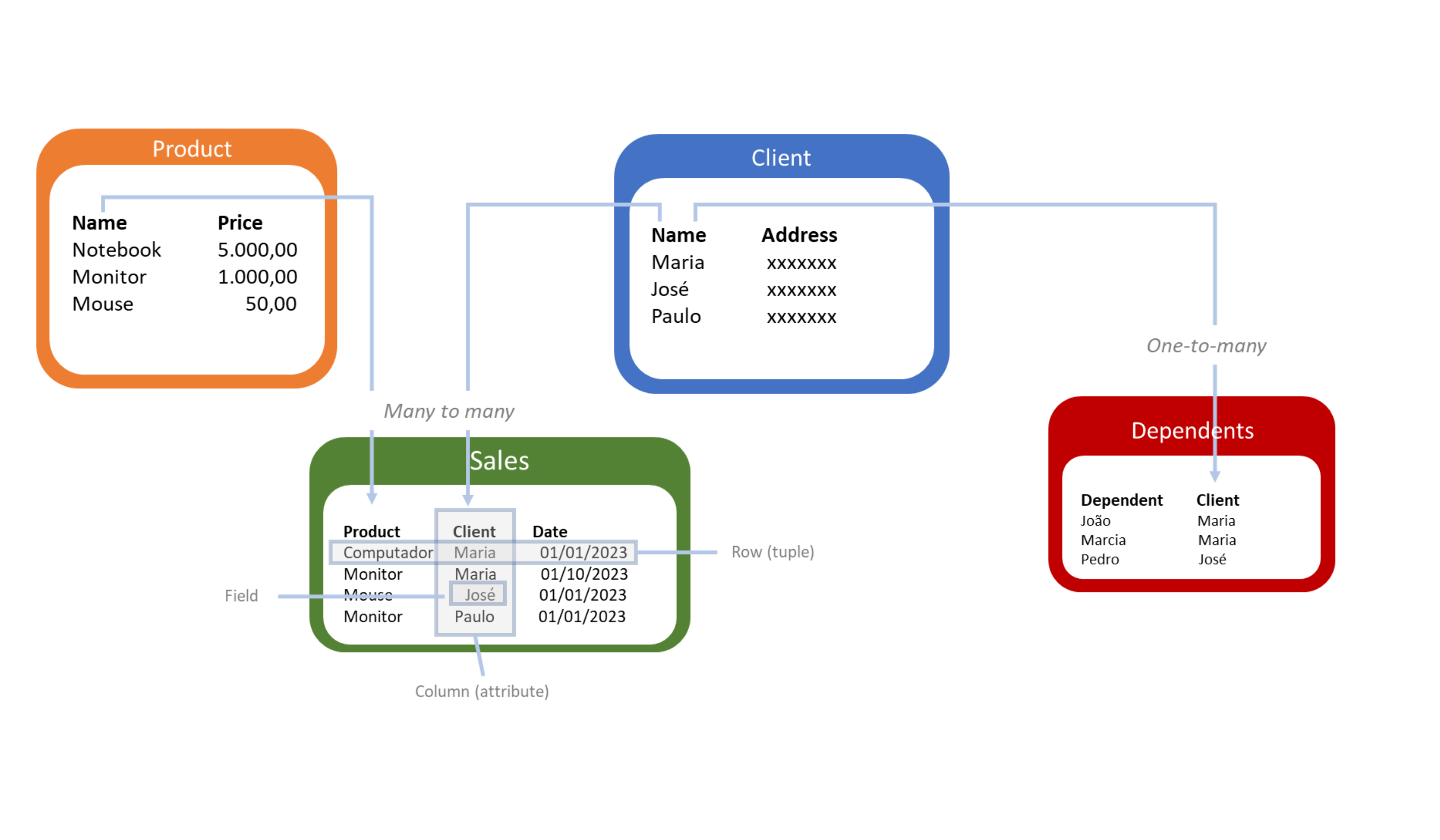
The most popular relational database management systems (RDBMS) include PostgreSQL, Oracle, MySQL, Microsoft SQL Server, IBM DB2, and SQLite.
Object-Oriented
In an object-oriented model, data is represented as objects, following the principles of object-oriented programming. This approach encapsulates data and behavior into entities, promoting modularity and reusability.
An object is an instance of a class (entity) that has attributes (data), methods (actions), and associations (relationships between classes).
Examples include CACHE, ZOPE, and GemStone.
Object-Relational
The object-relational model, or extended relational model, combines features of both relational and object-oriented models. These models maintain the efficiency of data in tables that are related to each other, and include object-oriented features such as inheritance and user-defined types.
PostgreSQL
PostgreSQL, the core component of PostgreSYS, is an open source DBMS widely recognized for its robustness and versatility. It originated from the Postgres project, developed by the Computer Science Department at the University of California, and has evolved to support a wide range of features, including:
-
SQL Compliance and Advanced Features: PostgreSQL not only conforms to most of the SQL standard but also provides advanced features for complex queries, foreign keys, transactions, views, triggers, and stored procedures. This makes PostgreSQL extremely flexible and powerful for various use cases.
-
Extensibility and Support for Custom Data Types: One of the remarkable features of PostgreSQL is its extensibility. Users can define their own data types, custom indexes, and even write functions in different programming languages. This extensibility allows it to be tailored to the specific needs of almost any database application.
-
Robustness and Reliability: PostgreSQL is known for its high stability and reliability. It has the ability to handle large amounts of data, a robust ACID (Atomicity, Consistency, Isolation, Durability) transaction system, and a strong recovery mechanism after failures. These features make it a reliable choice for critical systems.
-
Security and Compliance: PostgreSQL provides excellent data security. It supports strong authentication, granular access control, data encryption at rest and in transit, and many other security features. This makes PostgreSQL suitable for applications where data security is a major concern.
-
Technical Freedom: PostgreSQL is open source software distributed under the PostgreSQL License, a free software license. This license is similar to the MIT license in terms of permissiveness. It allows the freedom to use, modify, distribute, and study the software without worrying about royalties or vendor-imposed restrictions on Use. This feature makes PostgreSQL particularly attractive to companies and developers who want a powerful database management system without the licensing costs associated with many other database products. The free nature of the license also encourages a vibrant and active community that continually contributes to the development and PostgreSQL improvement.
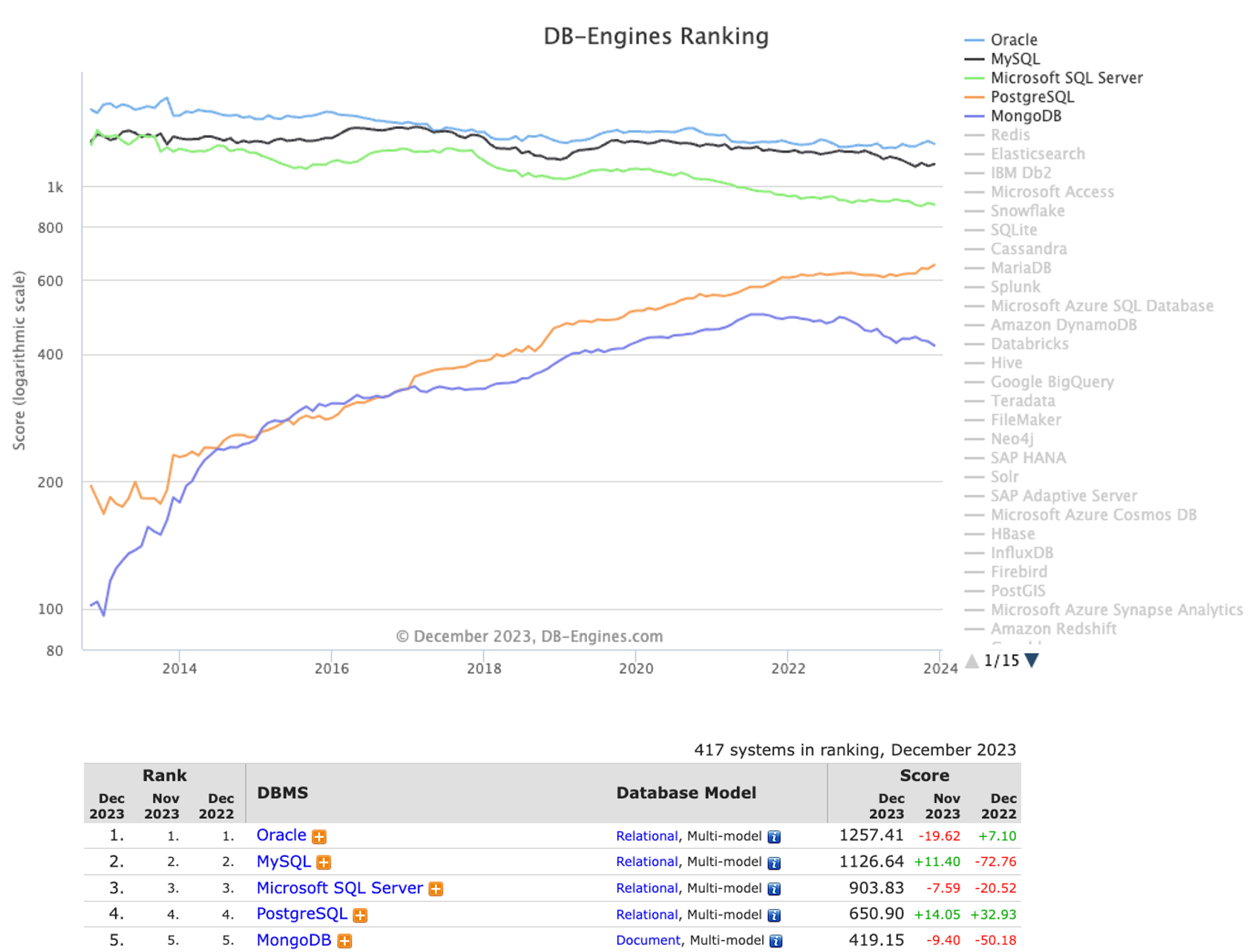
With over 30 years of continuous development and evolution, PostgreSQL has been adopted by various industries worldwide and is considered the right choice for database environments that require high reliability, robustness and performance.
According to db-engines.com, PostgreSQL was the second most widely used open source DBMS in the world in December 2023, and the fourth most popular.
Architecture
In this section, we will explore the main concepts present in the PostgreSQL architecture, which is illustrated in the following image.
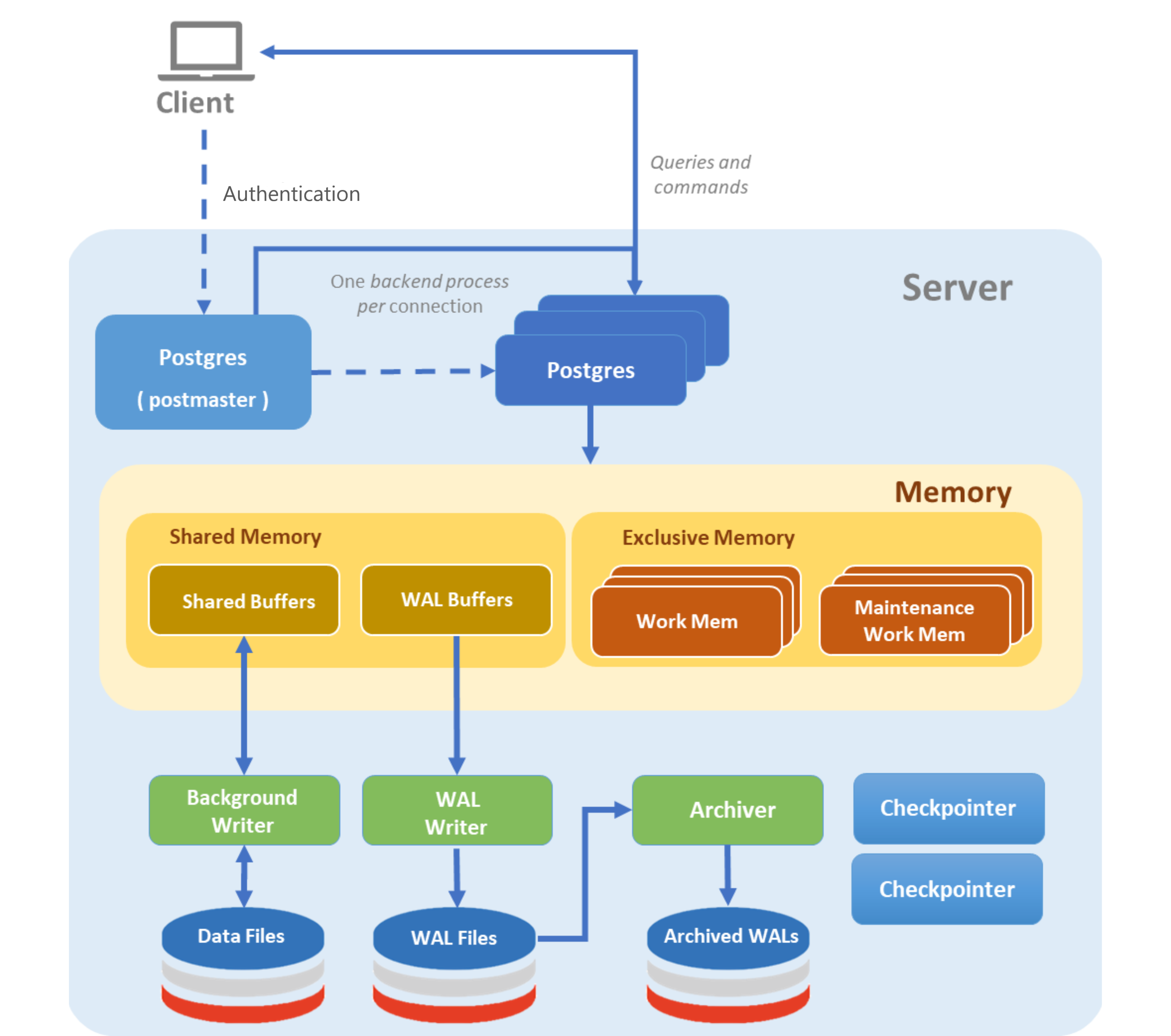
Client
Represents systems and applications that connect to the database to perform operations, such as command line interfaces, web applications, monitoring tools, etc.
Server
Represents the PostgreSQL database instance, including processes, storage, directories, and files.
Processes
-
Postgres: Postgres (also known as postmaster) is the main service process of the PostgreSQL instance. Started in the foreground when the cluster is started, it is responsible for managing utility processes and listening for connection requests from clients, creating a new backend process for each connection.
Background Processes
-
WAL Writer: Periodically writes Write-Ahead Logging (WAL) records from memory to disk. It ensures transaction durability and improves system efficiency by reducing I/O load during checkpoints, continuously backing up critical data.
-
Archiver: Archives WAL files to a secure location, essential for disaster recovery and replication. It is triggered when a WAL segment is complete and needs to be stored persistently.
-
WAL Sender: Sends WAL records to replica servers in asynchronous or synchronous replication setups. It plays a key role in maintaining data consistency and enabling high availability in distributed environments.
-
WAL Receiver: Runs on replica servers and receives WAL records from the WAL sender on the primary. It ensures the replica stays up to date by applying changes received from the primary instance.
-
Background Worker (BgWorker): Executes various background tasks, including running external modules that extend database functionality. It also enables query parallelism by distributing the execution of complex queries across multiple CPU cores.
-
Background Writer (BgWriter): Incrementally writes modified memory pages (dirty pages) to disk. This process helps distribute the I/O load, improves checkpoint performance, and ensures data integrity, reducing the risk of data loss during failures.
-
Checkpointer: Manages checkpoints - consistent synchronization points on disk. During a checkpoint, dirty pages and WALs are flushed to disk, and pg_control is updated to reflect the new state, ensuring durability and enabling recovery after a failure.
-
Autovacuum: Reclaims space occupied by obsolete tuples resulting from update and delete operations. It continuously monitors tables and performs maintenance proactively to prevent performance degradation.
-
Statistics Collector: Gathers performance and activity metrics about the instance, such as table and index accesses, data modifications, and resource usage. These statistics are critical for query planning and optimization. The data is exposed via system views for analysis and tuning.
-
Memory
-
Shared Memory: A memory area reserved for all PostgreSQL instance processes. It stores critical system data structures such as data buffers, transaction control information, locks, and metadata caches.
-
Shared Buffers: A portion of shared memory used to cache pages of tables and indexes read from disk. This cache is accessible to all server processes, allowing faster query execution by reusing data already in memory.
-
WAL Buffers: A portion of shared memory used to temporarily store Write-Ahead Logging (WAL) records before they are flushed to disk.
-
-
Process Memory or Backend Memory: Memory allocated individually to backend processes, including client sessions and utility processes. Its size is defined by server configuration parameters.
-
work_mem: Defines the amount of memory used for internal operations such as ORDER BY, DISTINCT, and MERGE JOIN, before falling back to disk-based temporary files (spill).
-
temp_buffers: Limits the amount of memory allocated per session for temporary tables.
-
maintenance_work_mem: Specifies the memory available for maintenance tasks like VACUUM, CREATE INDEX, and ALTER TABLE.
-
autovacuum_work_mem: Specifically defines the amount of memory allocated to each autovacuum process.
-