Bancos de Dados Vetoriais
Sistema especializado para armazenar, gerenciar e consultar dados de alta dimensionalidade (vetores/embeddings). Diferente de bancos tradicionais que buscam correspondências exatas, bancos vetoriais encontram dados por similaridade, sendo fundamentais para aplicações de IA como busca semântica, sistemas de recomendação e LLMs.
Conceitos Fundamentais
Vetor: Lista de números representando coordenadas em espaço multidimensional.
- Exemplo:
[12, 13, 19, 8, 9] - Assim como (x, y) define um ponto 2D, vetores definem pontos em espaços de centenas ou milhares de dimensões
Embedding: Representação numérica vetorial de dados (texto, imagem, áudio) gerada por modelos de Machine Learning.
- Dados semanticamente similares geram embeddings próximos no espaço vetorial
- Exemplo: "previsão do tempo" e "vai chover?" têm embeddings numericamente próximos
Funcionamento
O processo de busca por similaridade envolve duas etapas:
1. Indexação
- Dado bruto (texto, imagem, produto) é processado por modelo de ML
- Modelo gera vetor numérico (embedding) capturando características do dado
- Vetor é armazenado com referência ao dado original
- Vetores semanticamente similares são organizados próximos no espaço
2. Busca
- Consulta é convertida em vetor numérico (embedding) usando o mesmo modelo de ML
- Algoritmos otimizados calculam as distâncias entre vetores
- Sistema retorna dados originais dos vetores mais próximos
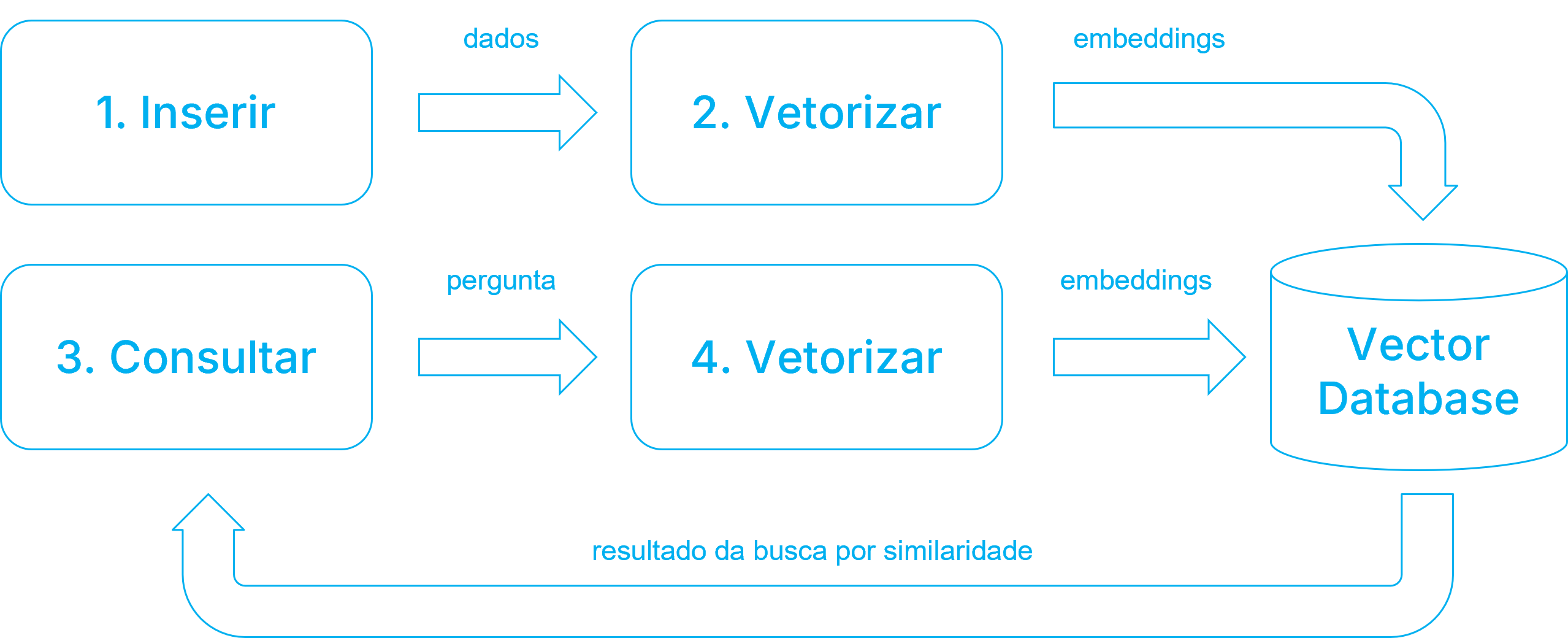
A vetorização do dado (geração do embedding) é feita uma vez, durante a indexação, e os vetores são armazenados no banco de dados vetorial.
Durante a consulta, o texto de busca é vetorizado e o banco de dados vetorial calcula a similaridade entre o vetor de busca e os vetores armazenados.
Casos de Uso
| Aplicação | Descrição | Exemplos |
|---|---|---|
| Busca Semântica | Encontra informações contextualmente relevantes independente de palavras-chave exatas | Busca por imagens, recomendação de artigos, busca em documentos |
| Sistemas de Recomendação | Sugere itens similares baseado em características e preferências | Produtos, músicas, filmes, conteúdo |
| ML/Deep Learning | Memória de longo prazo para modelos - armazena embeddings para consulta rápida | Cache de features, transfer learning |
| LLMs e IA Generativa | Fornece contexto adicional via RAG (Retrieval-Augmented Generation) | ChatGPT com conhecimento externo, assistentes especializados |
Vantagens
Consultar modelos de ML diretamente a cada busca é caro, lento e não escalável. Bancos vetoriais resolvem isso:
| Vantagem | Benefício |
|---|---|
| Eficiência | Dados processados uma vez na indexação; consultas em milissegundos |
| Custo-Benefício | Elimina reprocessamento contínuo pelo modelo de IA |
| Escalabilidade | Suporta bilhões de vetores sem perda de performance |
| Memória Persistente | Armazena conhecimento acessível de forma rápida e contextual |
pgvector
Extensão open-source que adiciona suporte a operações vetoriais e busca por similaridade no PostgreSQL, permitindo armazenar, indexar e consultar dados vetoriais diretamente no banco de dados.
Recursos principais:
- Armazenamento eficiente de vetores densos
- Busca rápida por similaridade com múltiplos operadores de distância
- Integração nativa com o planejador de consultas do PostgreSQL
- Suporte a indexação especializada (IVFFlat e HNSW)
Tipo de Dado vector
O pgvector introduz o tipo de dado vector(n), onde n representa o número de dimensões.
Características:
- Dimensionalidade: Através do parâmetro
né possível especificar a dimensionalidade do vetor (ex:vector(1536)para modelos de embeddings da OpenAI). Quando omitido, a coluna aceita vetores de qualquer dimensão. - Armazenamento: Formato binário compacto nas páginas de dados do PostgreSQL
- Validação: Se
nfor especificado, garante consistência dimensional em todas as entradas
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding VECTOR(1536) -- OpenAI text-embedding-ada-002
);
INSERT INTO documents (content, embedding)
VALUES ('Exemplo de texto', '[0.1, 0.2, ..., 0.9]');
Operadores para Cálculo da Distância entre Vetores
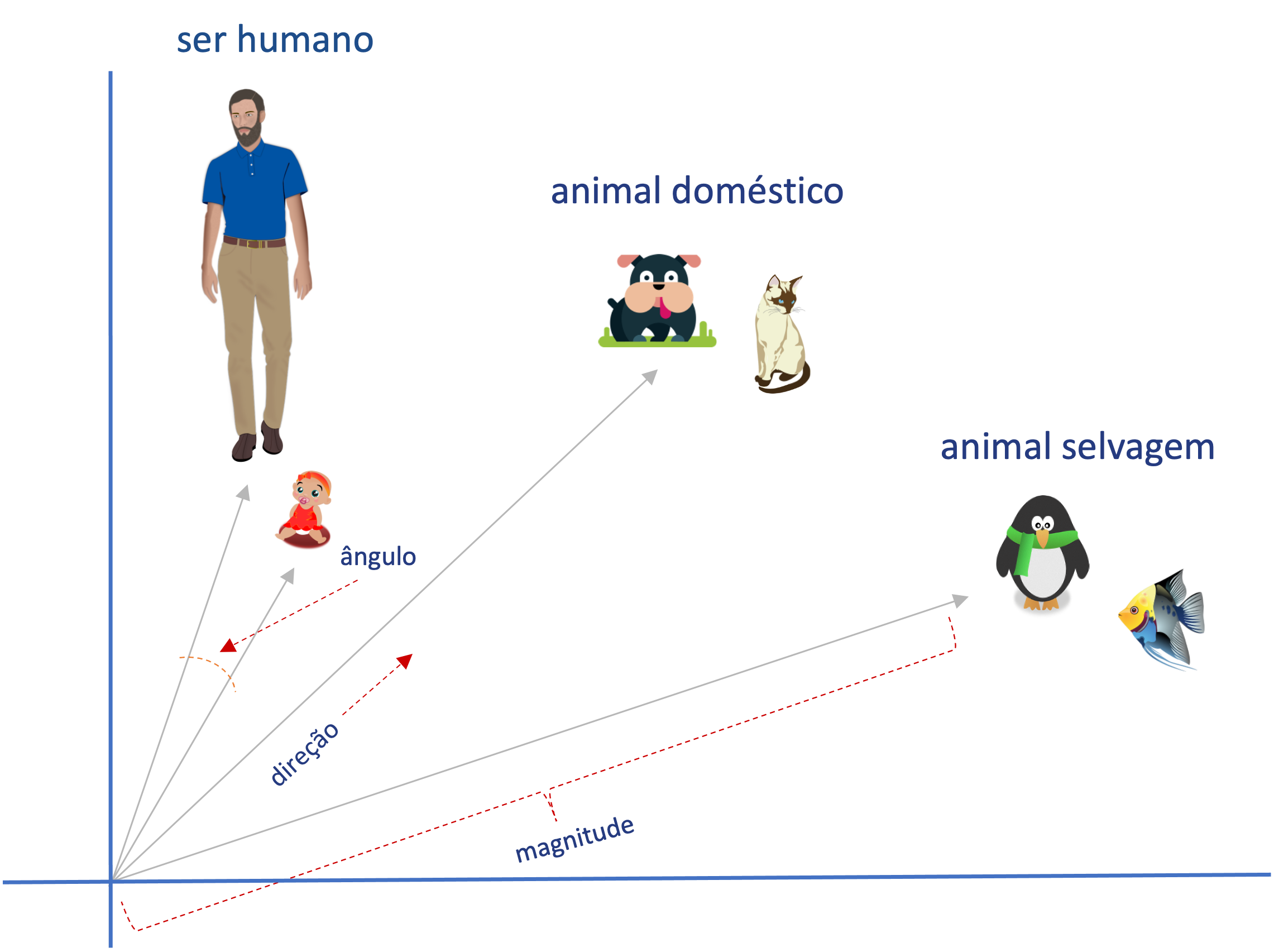
A busca por similaridade cálcula a distância entre vetores considerando três aspectos principais:
-
Magnitude (tamanho): É a medida do comprimento do vetor. Quanto maior o valor numérico, maior a magnitude do vetor. Em coordenadas bidimensionais, por exemplo, um vetor com magnitude maior será mais "longo" que um com magnitude menor.
-
Direção (orientação): É a direção em que o vetor aponta. Em coordenadas bidimensionais, um vetor com direção horizontal (ou vertical) aponta para a direita (ou para baixo).
-
Alinhamento (ângulo entre vetores): É o ângulo entre dois vetores. Quanto menor o ângulo entre eles, mais alinhados estão e maior a similaridade. Um ângulo de 0° indica vetores perfeitamente alinhados (mesma direção), enquanto 180° indica vetores opostos.
Na Figura 2, vemos um exemplo de vetores bidimensionais considerando os três aspectos acima.
O pgvector fornece três operadores principais para cálculo de distância entre vetores:
| Operador | Nome | Descrição | Uso Recomendado |
|---|---|---|---|
<-> | Distância Euclidiana (L2) | Distância em linha reta entre vetores | Imagens, coordenadas geográficas |
<=> | Distância de Cosseno | Ângulo entre vetores (direção) | Embeddings de texto (mais comum) |
<#> | Produto Interno | Projeção de um vetor sobre outro | Sistemas de recomendação |
Vejamos um exemplo prático:
-- Criar tabela com vetores 2D
CREATE TABLE items (
id SERIAL PRIMARY KEY,
nome TEXT,
categoria TEXT,
embedding VECTOR(2)
);
-- Inserir dados de exemplo
INSERT INTO items (nome, categoria, embedding) VALUES
('Homem', 'Ser Humano', '[2, 8]'),
('Criança', 'Ser Humano', '[3, 7]'),
('Cachorro', 'Animal Doméstico', '[6, 7]'),
('Gato', 'Animal Doméstico', '[7, 7.5]');
-- Buscar os 3 itens mais próximos do vetor do 'Homem' ([2, 8]) usando Distância Euclidiana
SELECT nome, categoria, embedding <-> '[2, 8]' AS distancia
FROM items
ORDER BY distancia
LIMIT 3;
Resultado:
| nome | categoria | distancia |
|---|---|---|
| Homem | Ser Humano | 0 |
| Criança | Ser Humano | 1.4142 |
| Cachorro | Animal Doméstico | 4.1231 |
Índices para Busca Vetorial
Para evitar buscas sequenciais em tabelas com milhões de vetores, o pgvector oferece índices ANN (Approximate Nearest Neighbor) que aceleram significativamente as buscas por similaridade.
IVFFlat (Inverted File with Flat Compression)
Índice baseado em clustering que particiona o espaço vetorial usando k-means. Durante a consulta, busca apenas nos clusters mais próximos ao vetor de entrada.
Características:
- Requer fase de treinamento durante a criação, ou seja, inserção prévia dos vetores
- Busca aproximada com trade-off precisão/velocidade
- Menor uso de memória e construção rápida
-- Criação (lists ≈ sqrt(total_rows))
CREATE INDEX items_embedding_idx ON items
USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
-- Configuração de busca
SET ivfflat.probes = 10; -- Número de clusters a verificar
-- Consulta
SELECT id, content FROM items
ORDER BY embedding <-> '[1, 2, 4]' LIMIT 5;
Parâmetros:
| Parâmetro | Descrição | Recomendação |
|---|---|---|
lists | Número de clusters | sqrt(rows) para datasets grandes |
probes | Clusters verificados na busca | 10 (ajustar para precisão/velocidade) |
HNSW (Hierarchical Navigable Small World)
Índice de grafo hierárquico que navega por múltiplas camadas para encontrar vizinhos próximos. Oferece maior precisão que IVFFlat.
Características:
- Sem fase de treinamento
- Alta precisão (recall > 95%)
- Maior uso de memória e construção mais lenta
-- Criação
CREATE INDEX items_embedding_hnsw_idx ON items
USING hnsw (embedding vector_l2_ops)
WITH (m = 16, ef_construction = 64);
-- Configuração de busca
SET hnsw.ef_search = 40; -- Lista dinâmica durante consulta
-- Consulta
SELECT id, content FROM items
ORDER BY embedding <-> '[1, 2, 4]' LIMIT 5;
Parâmetros:
| Parâmetro | Descrição | Valor Padrão | Recomendação |
|---|---|---|---|
m | Conexões por camada | 16 | 16-32 |
ef_construction | Qualidade da construção | 64 | 64-200 |
ef_search | Precisão da busca | 40 | 40-400 |
Comparação de Índices
| Critério | IVFFlat | HNSW |
|---|---|---|
| Precisão | Moderada (80-95%) | Alta (>95%) |
| Velocidade | Rápida | Rápida e consistente |
| Memória | Moderada | Alta |
| Construção | Rápida | Lenta |
| Uso recomendado | Datasets grandes, prototipagem | Produção, alta precisão |
Fonte: https://github.com/pgvector/pgvector
pgembed
Enquanto extensões como o pgvector preparam o PostgreSQL para armazenar e consultar dados vetoriais, o processo de gerar esses vetores - a vetorização (embedding) - ainda precisa ser executado separadamente.
Normalmente, esse processo exige que uma aplicação ou pipeline se comunique com um modelo de Machine Learning externo, como os oferecidos pela OpenAI, ou localmente, com modelos disponíveis no Ollama. O que pode exigir um conhecimento técnico mais amplo do time de dados ou o envolvimento de diversos profissionais com expertises variadas.
Em muitos dos casos, projetos focados na validação do Minimum Viable Product (MVP) optam por desenvolver funções no próprio PostgreSQL que consomem serviços de vetorização e facilitam essa atividade.
Contudo, é comum que as boas práticas, como o uso de dados em lotes para a redução do tráfego em rede, gestão do consumo de memória, configurações de segurança e mecanismos de resiliência, sejam negligenciados nessa abordagem.
Visando fornecer um conjunto de funções para vetorização de dados no PostgreSQL, com foco em desempenho, segurança e resiliência, a Tecnisys desenvolveu a extensão pgembed.
Funções de Vetorização
Após instalar e criar a extensão pgembed, serão disponibilizadas no esquema pgembed do banco de dados diversas funções para a vetorização de dados, organizadas pelo fornecedor da API de embedding e pelo tipo do dados de entrada:
| Fornecedor | Linha de Texto Única | Conjunto de Linhas | Tabela |
|---|---|---|---|
| Ollama (local) | embed_ollama | embed_batch_ollama | embed_table_ollama |
| OpenAI | embed_openai | embed_batch_openai | embed_table_openai |
| Custom APIs | embed_custom | embed_batch_custom | embed_table_custom |
Tipos de Funções:
- Linha de Texto Única (
embed_*): Gera o embedding para uma única linha de texto. Por exemplo:SELECT pgembed.embed_openai('Hello, world!', 'text-embedding-3-small'); - Conjunto de Linhas (
embed_batch_*): Processa múltiplas linhas de texto e retorna uma lista de vetores. Por exemplo:SELECT * FROM pgembed.embed_batch_openai(ARRAY['Hello, world!', 'Hello, PostgreSQL!'], 'text-embedding-3-small'); - Tabela (
embed_table_*): Lê coluna de texto de uma tabela e atualiza automaticamente a coluna de embeddings correspondente, eliminando a necessidade de operações manuais de atualização. Por exemplo:SELECT * FROM pgembed.embed_table_openai(
'public', -- schema
'tb_documents', -- table name
'content', -- content column
'embedding', -- embedding column
FALSE, -- regenerate: only update NULL embeddings (default: FALSE)
1000, -- batch_size
'text-embedding-3-small' -- model
);
Parâmetros Avançados
Além dos parâmetros obrigatórios, as funções da extensão pgembed possuem diversos parâmetros avançados extremamente úteis, tais como:
- Timeout da requisição (
timeout, default 60s) - Se o certificado SSL deve ser verificado (
verify_ssl, default TRUE) - Se o texto deve ser truncado caso exceda o tamanho do contexto (
trucante, default TRUE, para modelos do Ollama) - JSON para opções avançadas de cada modelo (
options, para modelos do Ollama) - Número de dimensões dos embeddings gerados (
dimensions, para modelos da OpenAI) - Formato de codificação dos embeddings retornados (
encode_format, para modelos da OpenAI)
Segurança e Resiliência
No quesito segurança e resiliência, a extensão pgembed disponibiliza parâmetros que podem ser configurados no nível do usuário, sessão e banco de dados, tais como:
pgembed.openai_api_keyoupgembed.custom_api_keypara definir a API key utilizada na requisição do serviçopgembed.url_allowlistpara definir a lista de URL autorizadas. Por padrão: localhost, 127.0.0.1, 0.0.0.0 (qualquer porta), *.openai.com e api.openai.compgembed.max_retries,pgembed.initial_backoff_ms,pgembed.max_backoff_mspara controle de tentativaspgembed.circuit_breaker_thresholdepgembed.circuit_breaker_reset_timeout_spara evitar que falhas em cascata bloqueiem temporariamente solicitações para serviços indisponíveis