Tez
Distributed task execution framework
Apache Tez is a distributed task execution framework built on top of Hadoop YARN (Yet Another Resource Negotiator). It was created to replace classic MapReduce, providing a more flexible, efficient, and faster execution model for large-scale data-processing applications.
What Apache Tez does
- Executes DAGs (Directed Acyclic Graphs), where each node represents a task (map, reduce, intermediate transforms) and each edge defines the data flow.
- Provides an efficient orchestration layer, reducing HDFS reads/writes and optimizing cluster resource usage.
- Serves as the default execution engine for Apache Hive, accelerating complex SQL queries.
- Replaces heavy, rigid processes with shorter, optimized data pipelines.
Key characteristics of Apache Tez
- DAG-based execution: more flexible than the fixed Map → Shuffle → Reduce model.
- Low latency: avoids unnecessary disk and HDFS access.
- YARN container reuse: lowers scheduling and task startup overhead.
- Native support for multiple communication patterns (one-to-one, broadcast, scatter-gather).
- Integration with higher-level tools such as Hive, Pig, and custom Java applications.
- Detailed monitoring via Web UI and logs.
- Fault tolerance inherited from YARN.
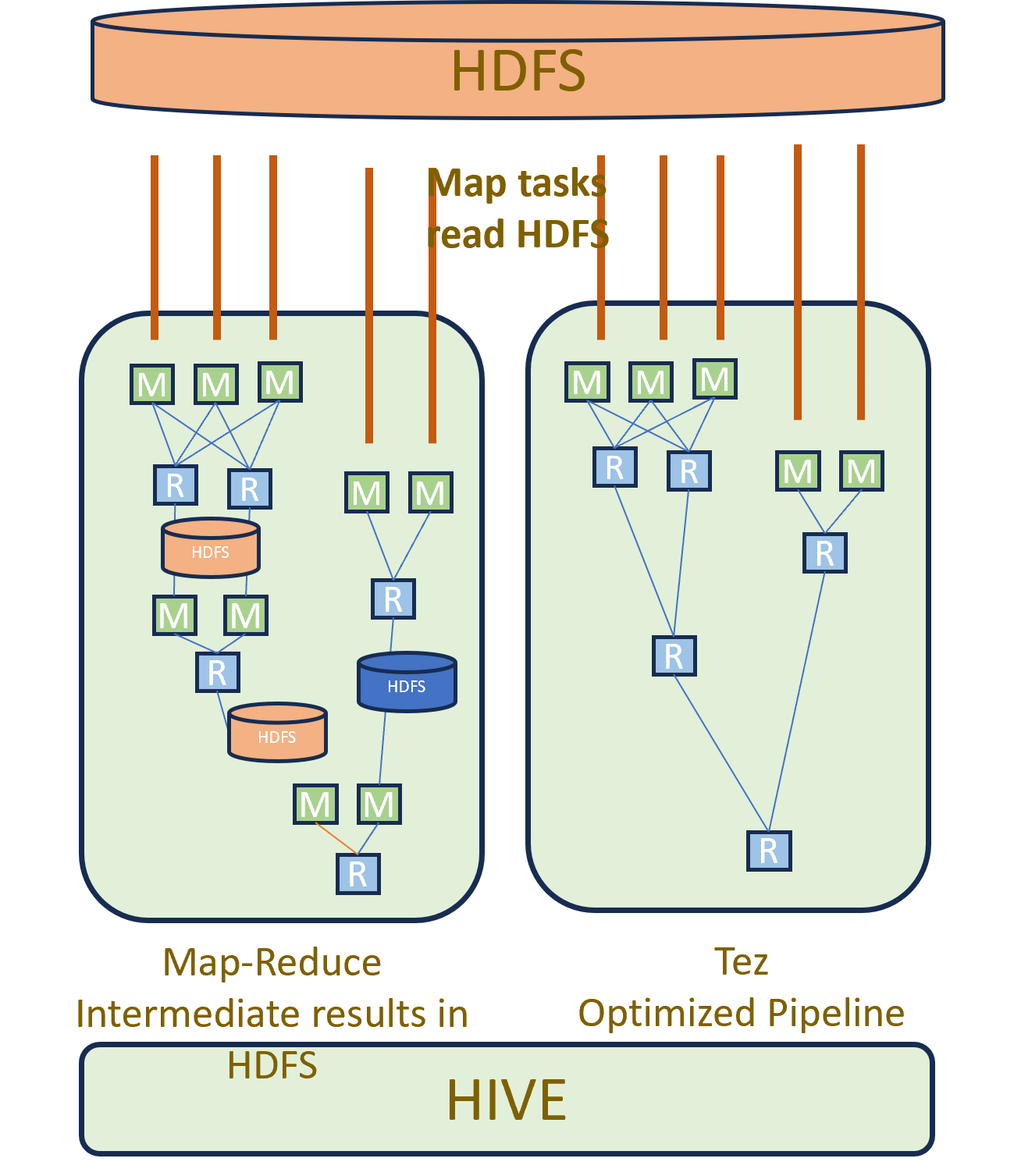
MapReduce vs. Apache Tez
MapReduce accesses disk/HDFS multiple times along its data flow (Mapper → Shuffle & Sort → Reducer). It reads and writes data (or modified data) at each step, leading to 5–6 disk accesses for a single MapReduce job.
Tez, in contrast, reads data from disk, performs all stages, keeps intermediate results in memory, applies vectorization (processes batches of rows rather than one at a time), and then produces the output.
While MapReduce performs multiple reads/writes to HDFS, Tez avoids unnecessary HDFS access.
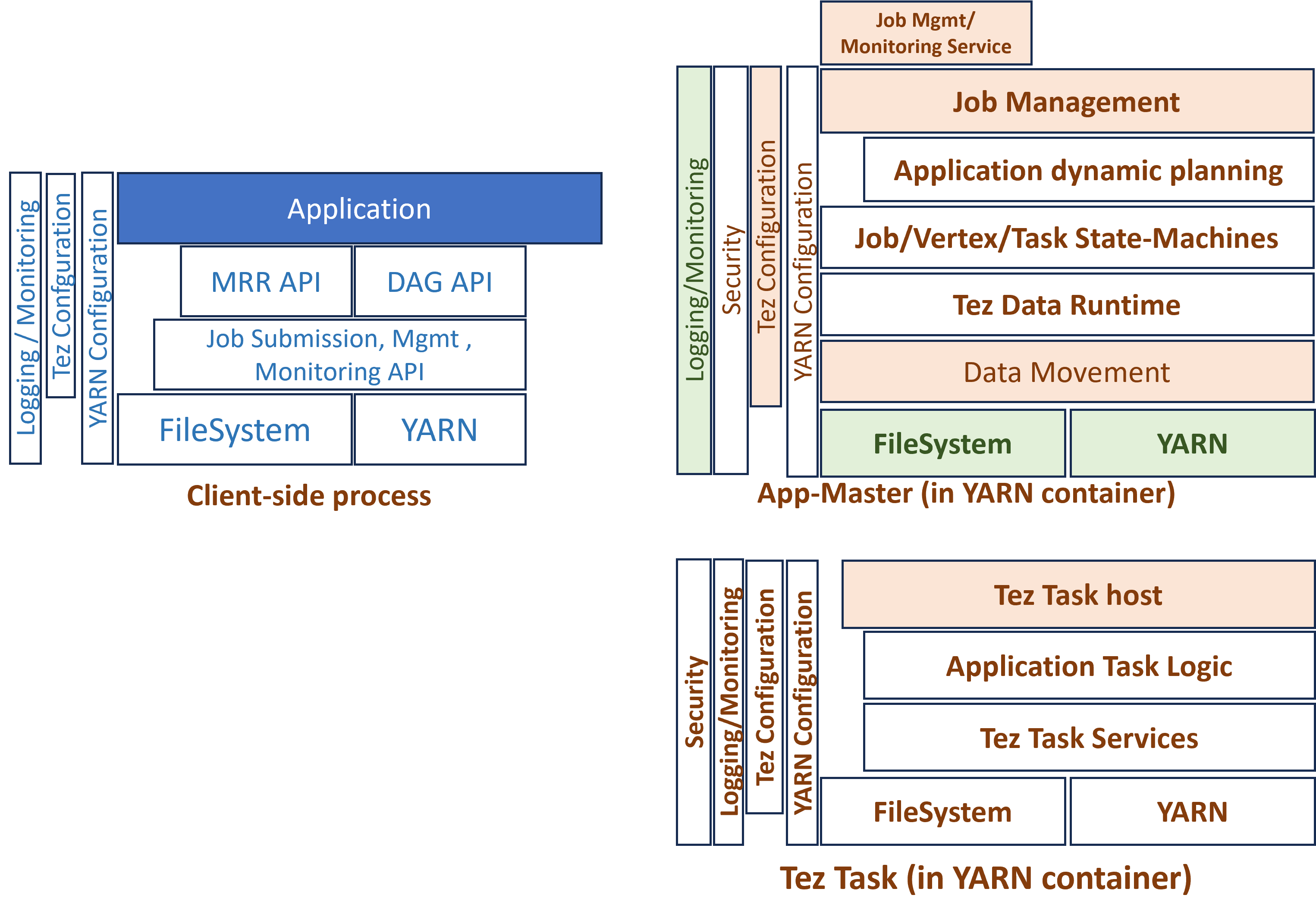
Apache Tez architecture
Tez architecture rests on three pillars:
-
YARN Resource Manager
Manages cluster resources (CPU, memory).
Allocates containers for Tez applications.
-
Tez Application Master (AM)
One dedicated instance per DAG application.
Coordinates task execution and manages the pipeline.
Tracks progress, failures, and dependencies.
-
DAG and Tasks
Each submitted application is described as a DAG.
Tasks are distributed across vertices (logical operations) and edges (data connections).
Execution is dynamic: containers can be reused between tasks.
Apache Tez capabilities
- Programmatic APIs to build custom DAGs.
- Extensibility: developers can define custom partitioning, sorting, and communication strategies.
- Integration with SQL engines (Hive and Pig).
- Tez UI: visualize running DAGs, step timing, and bottlenecks.
- Advanced tuning options (memory, parallelism, shuffle, container reuse).
Best practices
- Tune parallelism to data volume to avoid both underutilization and overload.
- Enable container reuse for repetitive workloads (reduces startup overhead).
- Monitor shuffle bottlenecks: memory and compression tuning make a big difference.
- Use intermediate compression to reduce network traffic.
- Align with Hive/Pig configs: many Tez optimizations depend on the upper layer.
When to use Apache Tez
- Complex SQL queries in Hive (as a MapReduce replacement).
- Pipelines with multiple stages in dynamic DAGs.
- Custom Java applications needing optimized parallel execution on YARN.
- Interactive Big Data scenarios where seconds of latency matter.
When not to use Apache Tez
- Simple batch jobs where DAG configuration overhead doesn’t pay off.
- Small clusters, without YARN, or where MapReduce is sufficient.
- Real-time streaming requirements (typical for Kafka Streams or Flink).
Project details (Tez)
Java is the primary implementation language for Tez and its APIs.
DAG APIs are written in Java, but users usually consume Tez indirectly via Hive or Pig (SQL or declarative scripts).
Sources: