Tez
Framework de execução de tarefas distribuídas
O Apache Tez é um framework de execução de tarefas distribuídas construído sobre o YARN (Yet Another Resource Negotiator) do Hadoop. Ele foi criado para substituir o antigo MapReduce, oferecendo um modelo de execução mais flexível, eficiente e rápido para aplicações de processamento em larga escala
O que faz o Apache Tez
-
Permite a execução de DAGs (Directed Acyclic Graphs), onde cada nó representa uma tarefa (map, reduce, transformações intermediárias) e cada aresta define o fluxo de dados.
-
Fornece uma camada de orquestração eficiente, reduzindo o número de leituras/escritas no HDFS e otimizando o uso de recursos no cluster.
-
É a base de execução padrão do Apache Hive, acelerando consultas SQL complexas.
-
Substitui processos pesados e rígidos por pipelines de dados mais curtos e otimizados.
Principais Características do Apache Tez
-
Execução baseada em DAGs: maior flexibilidade em relação ao modelo fixo Map → Shuffle → Reduce.
-
Baixa latência: reduz acessos desnecessários ao disco e ao HDFS.
-
Reutilização de containers YARN: diminui overhead no agendamento e na inicialização de tarefas.
-
Suporte nativo a múltiplos padrões de comunicação (1-para-1, broadcast, scatter-gather).
-
Integração com ferramentas de alto nível como Hive, Pig e aplicações customizadas em Java.
-
Monitoramento detalhado via WebUI e logs
-
Suporte a falhas herdado do YARN.
MapReduce vs. Apache Tez
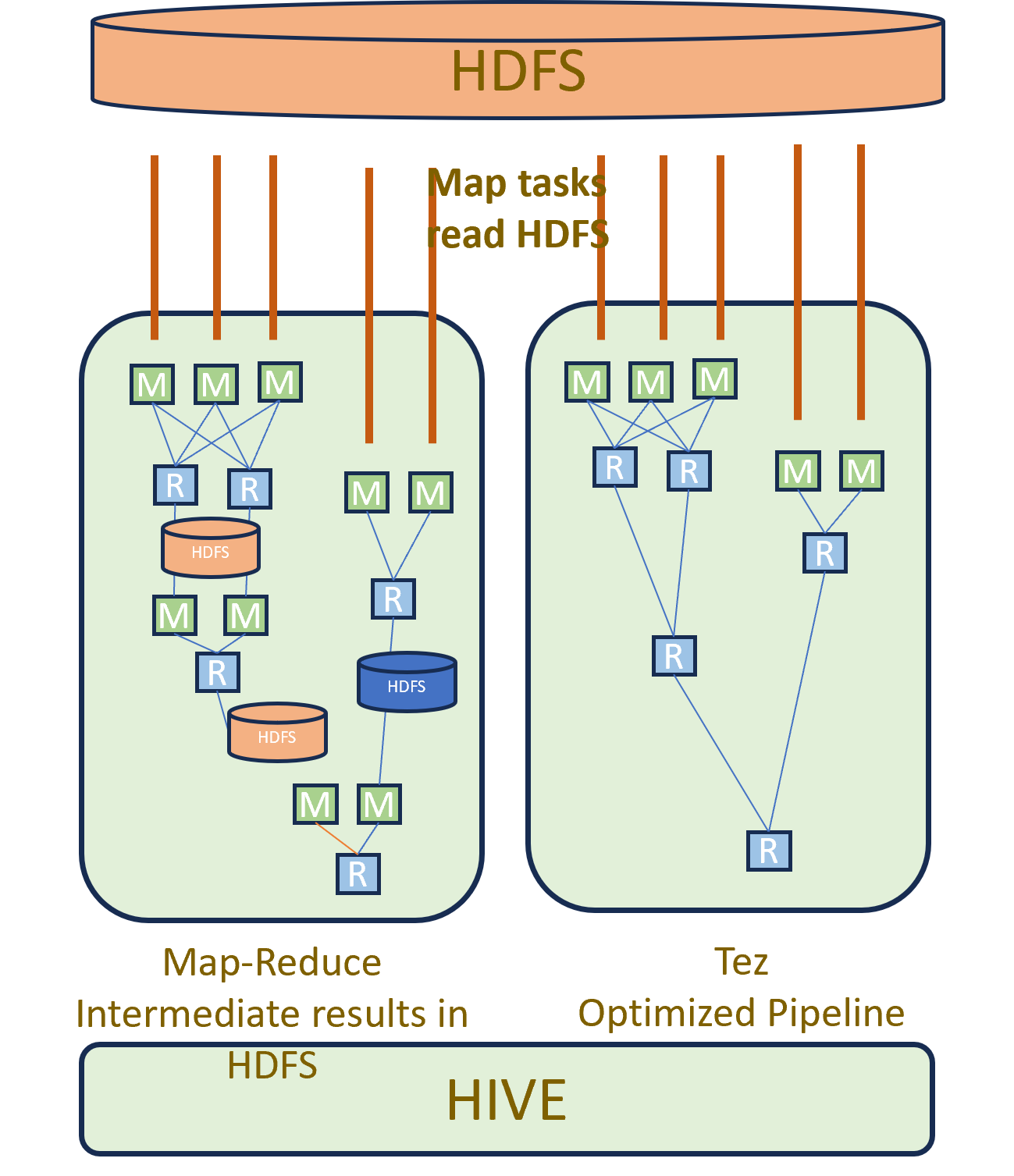
O MapReduce acessa o disco/HDFS várias vezes ao longo do fluxo de dados (Mapper → Shuffle & Sort → Reducer). Ele lê e escreve dados (ou dados modificados) em cada uma dessas etapas, resultando em 5–6 acessos ao disco para um único job de MapReduce.
Já o Tez lê os dados do disco, executa todas as etapas, mantém resultados intermediários em memória, aplica vetorização (processa lotes de linhas em vez de uma por vez) e então produz a saída.
Enquanto o MapReduce realiza múltiplas leituras/gravações no HDFS, o Tez evita acessos desnecessários ao HDFS.
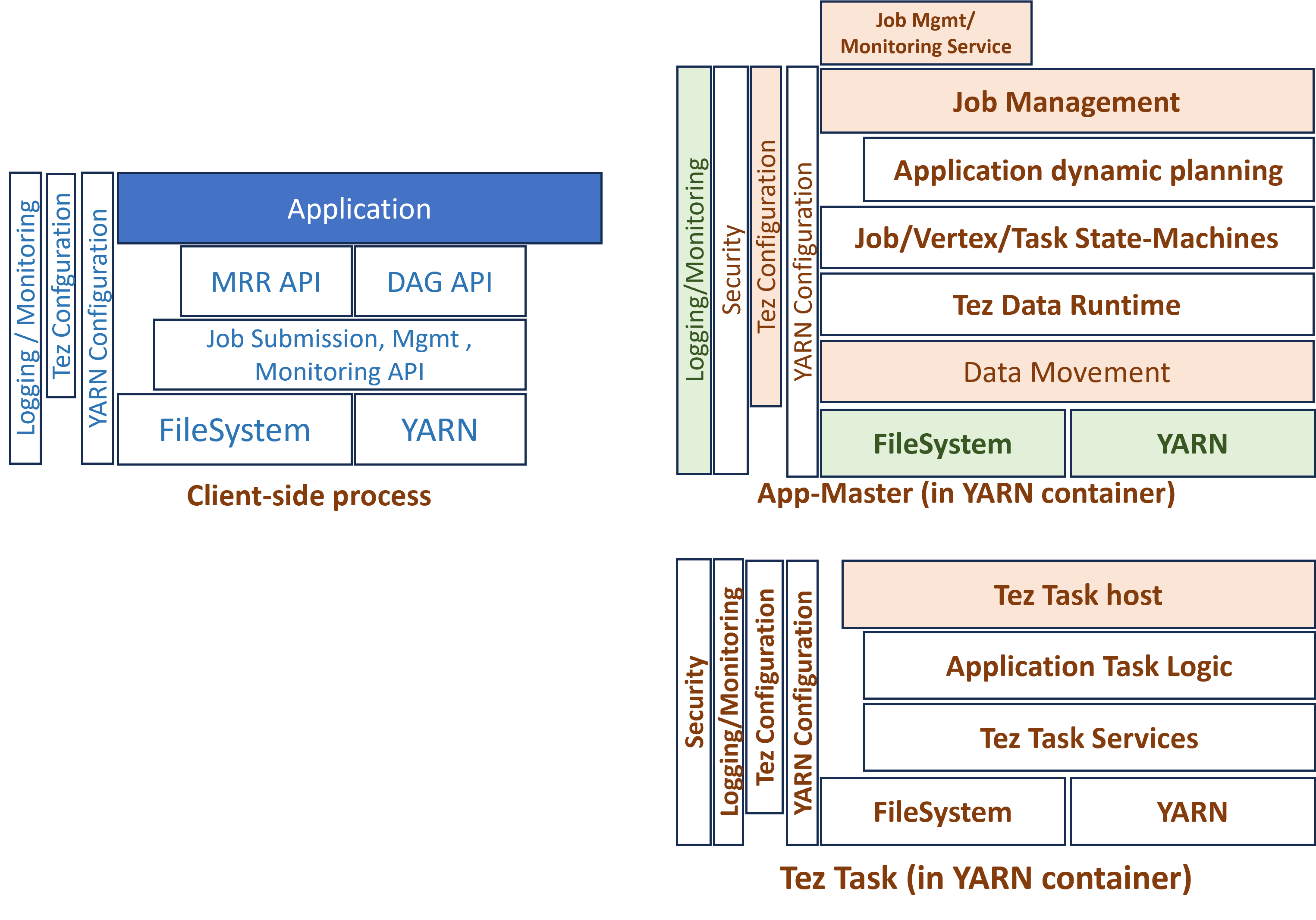
Arquitetura do Apache Tez
A arquitetura do Tez se apoia em três pilares:
-
YARN Resource Manager
Responsável por gerenciar os recursos do cluster (CPU, memória).
Aloca containers para as aplicações Tez.
-
Tez Application Master (AM)
Instância dedicada por aplicação DAG.
Coordena a execução das tarefas e gerencia o pipeline.
Mantém informações sobre progresso, falhas e dependências.
-
DAG e Tasks
Cada aplicação submetida ao Tez é descrita como um DAG.
Tarefas são distribuídas em vertices (operações lógicas) e edges (conexões de dados).
Execução é dinâmica: containers podem ser reaproveitados entre tarefas.
Recursos do Apache Tez
-
APIs programáticas para criação de DAGs customizados.
-
Extensibilidade: desenvolvedores podem definir estratégias próprias de particionamento, ordenação e comunicação.
-
Integração com motores SQL (Hive e Pig).
-
Tez UI: interface para visualização de DAGs em execução, tempos de cada etapa e gargalos.
-
Configuração avançada para otimização (memória, paralelismo, shuffle, reuso de containers).
Boas práticas
-
Ajustar paralelismo de acordo com o volume de dados para evitar tanto subutilização quanto sobrecarga.
-
Habilitar reuso de containers para workloads repetitivos (reduz overhead de inicialização).
-
Monitorar gargalos no shuffle: tuning de memória e compressão faz grande diferença.
-
Usar compressão intermediária para reduzir tráfego de rede.
-
Alinhar com Hive/Pig configs: muitas otimizações de Tez dependem da camada superior.
Quando usar o Apache Tez
-
Em consultas SQL complexas no Hive (substitui MapReduce).
-
Quando é necessário pipeline de dados com múltiplas etapas em DAGs dinâmicos.
-
Para aplicações customizadas em Java que demandam execução paralela otimizada sobre YARN.
-
Em cenários de Big Data interativo, onde a latência de segundos importa.
Quando não usar o Apache Tez
-
Em jobs simples de batch onde o overhead de configurar DAGs não compensa.
-
Em clusters pequenos, sem YARN, ou onde MapReduce já é suficiente.
-
Quando há exigência por streaming em tempo real (caso de uso típico de Kafka Streams ou Flink).
Detalhes do Projeto Tez
Java é a linguagem principal usada para implementar o Tez e suas APIs.
APIs para DAGs são escritas em Java, mas normalmente o Tez é consumido indiretamente por usuários através do Hive ou Pig (SQL ou scripts declarativos).
Fontes: