Apache Zeppelin
Notebook
Tipicamente usado por cientistas de dados para experimentos e tarefas de exploração, o notebook é uma ferramenta de computação interativa, na qual usuários gravam e executam código, visualizam os resultados e compartilham "insights".
O conceito foi criado por Stephan Wolfrom, cientista da computação e físico, que apresentou o Mathematica - a primeira interface computacional para notebook. Desde então, a ferramenta se proliferou e passou da "academia" para a indústria.
Apache Zeppelin é um "notebook" baseado na web que fornece recursos de ingestão, exploração, visualização, compartilhamento e colaboração interativa de dados para HADOOP e Spark.
O Apache Zeppelin começou com um projeto nomeado Zeppelin, da empresa ZEPL (anteriormente conhecida como NFLabs), comandada por Moon Sool Lee. Em 2014 tornou-se um projeto de incubadora na fundação de software Apache e logo, em 2016, se tornou um projeto de alto nível na Apache.
Segundo seus criadores a denominação de "notebook" dada ao Zeppelin é uma analogia a um caderno de anotações, baseando suas funções em "parágrafos".
Características do Apache Zeppelin
Os notebooks interativos do Zeppelin permitem que engenheiros, analistas e cientistas de dados tenham um melhor aproveitamento no trabalho com dados. Desta forma, pode ser visto como uma interface que conecta usuários com as tecnologias que desejam utilizar para tratamento de dados.
O Zeppelin é muito útil para trabalhar de forma interativa com workflows na ciência de dados, desenvolvendo, organizando e executando análises e visualizando seus resultados, sem a necessidade de utilizar a linha de comando ou consultar detalhes do Cluster.
Oferece, ainda, suporte a back-ends de vários idiomas e um ecossistema crescente de fonte de dados.
-
Back-end de vários idiomas: O software se destaca pela sua capacidade de integrar diversas outras tecnologias através de uma funcionalidade denominada interpreter, que é uma camada para integração de backend (que trabalha "por trás" da aplicação), sendo que já possui mais de 20 interpretadores em seu pacote de distribuição oficial.
Dentre os diversos interpretadores que suporta, podemos citar o Apache Spark, Python, JDBC, Marckdown e Shell.
-
Integração com Apache Spark: O Zeppelin está integrado ao Apache Spark. Não há necessidade de criar um módulo, plug-in ou biblioteca separada para ele. Esta integração fornece:
-
SparkContext e SQLContext automáticos.
-
Carga de "dependência" JAR em tempo de execução a partir do sistema de arquivos local ou repositório "Maven".
-
Cancelamento de trabalho com exibição do progresso.
-
-
Visualização de Dados: Alguns gráficos básicos também podem ser utilizados.
As visualizações não se limitam a query SPARKSQL.
Qualquer saída de qualquer linguagem "backend" pode ser reconhecida e visualizada.
-
Gráficos dinâmicos: Apache Zeppelin agrega valores e os mostra em gráficos dinâmicos. Com um simples drag-and-drop. é possível criar um gráfico com múltiplos valores agregados incluindo soma, contagem, média, minimos e máximos.
-
Formulários dinâmicos: O Apache Zeppelin pode criar dinamicamente alguns formulários de entrada em seu notebook.
-
-
Colaboração de Notebook e Parágrafos: A URL do notebook pode ser compartilhada e, em seguida, o Zeppelin pode transmitir todas as alterações em tempo real, bem como a colaboração no Google Docs.
Pode, ainda, fornecer uma URL para exibir apenas o resultado, numa página sem menu ou botão, dentro do Notebook, que pode ser incorporada facilmente como um iframe no site do usuário.
-
100% Opensource : O Apache Zeppelin é licenciado Apache2. Possui uma comunidade de desenvolvimento muito ativa.

Arquitetura do Apache Zeppelin
O Apache Zeppelin é dividido em 03 camadas:
-
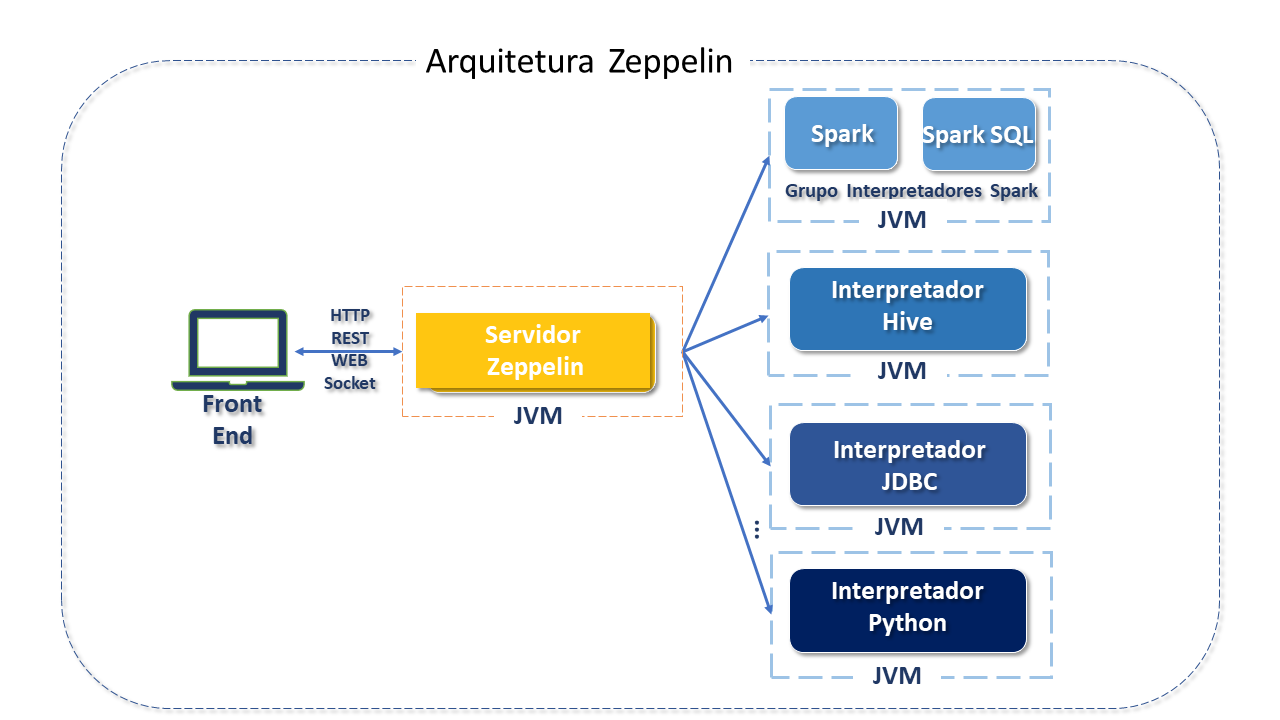
Front-end: A partir de um Web Browser, o utilizador tem contato com o Frontend do Zeppelin, que é baseado em AngularJS (uma plataforma para construção de aplicações web baseada em Ecmascript) e Twitter Bootstrap( um framework CSS) que tornam a interface de aplicação web mais fluida e dinâmica.
A camada de front-end comunica-se com o servidor do Apache Zeppelin por meio de duas interfaces possiveis:
-
REST: Estilo de arquitetura para definir restrições e propriedades do protocolo HTTP e
-
Web Socket: tecnologia para comunicação bidirecional por canais full-duplex - transmissor e receptor podem transmitir dados simultaneamente em ambos os sentidos sobre um único socket TCP.
-
-
Zeppelin Server: O servidor funciona sobre uma Máquina Virtual (JVM - Java Virtual Machine) que também é um interpretador do Notebook.
-
Interpreter: O intérpreter se comunica com um programa que executa em plano de fundo do Zeppelin por meio do Apache Thrift, uma tecnologia que permite definir tipos de dados e interfaces de serviço em um arquivo de definição simples.
Tomando esse arquivo como entrada, o compilador gera o código a ser usado para criar facilmente clientes e servidores RPC que se comunicam facilmente entre as linguagens de programação.
O interpreter é uma funcionalidade que torna o Zeppelin "plugável" a outras tecnologias. Cada processo do interpretador pertence a um grupo de interpretadores que atuam como uma unidade de start e stop do interpretador.
Para conhecer todos os interpretadores que o Apache Zeppelin suporta clique aqui
Visualização de dados com Zeppelin
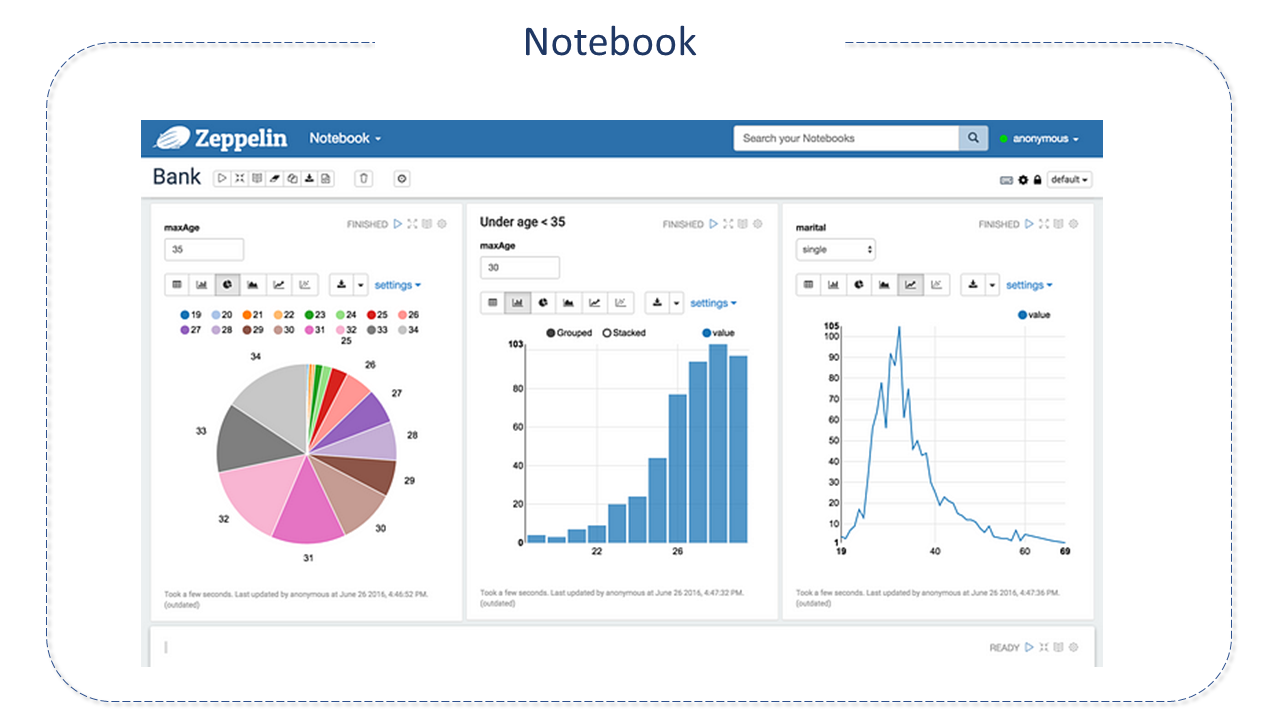
O Notebook é composto por parágrafos.
Cada parágrafo é uma caixa que recebe algum tipo de script pré-definido nos interpretadores.
O texto interpretado possui uma marcação "%" para determinar o interpretador e script a ser executado.
Por meio da interface construída com Angular e Bootstrap, o usuário tem a possibilidade de personalizar sua visualização, colocando os parágrafos em colunas para permitir uma exibição simultãnea do resultado.
A interação entre o utilizador, a ferramenta e os dados é proporcionada pelo front-end.
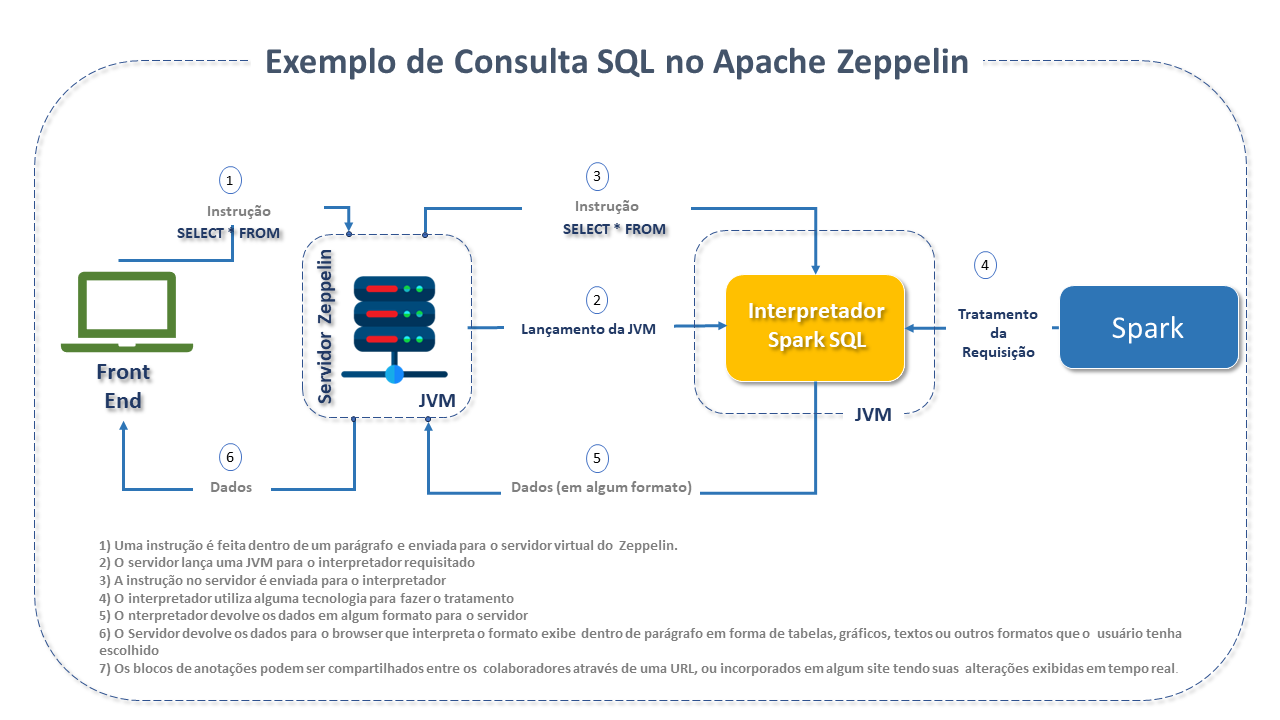
A figura abaixo é um exemplo do fluxo de funcionamento do Zeppelin, utilizando um Backend Spark para fazer o tratamento de uma consulta SQL.
Boas Práticas para o Apache Zeppelin
-
Instalação e Versões: É recomendável a instalação do Zeppelin com Ambari e sempre uso o da última versão do Zeppelin, garantindo, assim, alinhamento com correções de segurança e estabilidade.
-
Escolhas de implementação: Embora qualquer nó possa ser selecionado, o melhor local para instalar o Zeppelin é um nó gateway, quando o Cluster estiver com o firewall desligado e for protegido externamente.
-
Requisitos de Hardware: Mais memória e mais núcleos são sempre uma boa opção: o minimo de 64 Gb e 8 núcleos. Número de usuários: Um nó Zeppelin pode suportar de 8 a 10 usuários. Para mais usuários, várias instâncias podem ser configuradas.
-
Segurança: Como qualquer software, a segurança depende da matriz de ameaças e das opções de implantação :
-
Autenticação
-
Kerberizar o Cluster usando Ambari
-
Configurar Zeppelin para alavancar o LDAP corporativo
-
Não usar autenticação baseada em usuário local do Zeppelin, exceto para demonstrações.
-
-
Interpretadores:
-
Evite usar interpretador Shell, pois o isolamento de segurança não é o ideal.
-
Não use a IU do interpretador para representações. Funciona apenas para interpretadores Livy e JDBC(Hive).
-
Os usuários devem reiniciar suas proprias sessões do interprete a partir do botão da página do Notebook, e não na página do intérprete, que reiniciaria as sessões para todos os usuários.
-
Aproveite o interpretador Livy para trabalhos do Spark no Cluster, pois ele fornece propagação de identidade ideal.
-
Escolhendo os interpretadores: Por default, Zeppelin registrará e mostrará todos os interpretadores abaixo da pasta $ZEPPELIN_HOME/interpreters. Mas existe a possibilidade de especificar quais interpretadores devem ser incluídos ou excluidos por meio das propriedades zeppelin.interpreter.include e zeppelin_interpreter.exclude. Apenas um deles pode ser especificado.
-
É possível a criação de um novo interpretador e a tarefa é simples. Basta estender a classe abstrata org.apache.zeppelin.interpreter e implementar alguns métodos.
-
-