HADOOP
Apache HADOOP é uma implementação de código aberto do paradigma MapReduce, o qual define uma arquitetura para realização de processamento distribuído e paralelo de grandes volumes de dados, de modo que possam ser "executados" em vários servidores, usando modelos de programação simples.
|
O paradigma MapReduce expande servidores únicos para muitas máquinas, oferecendo computação e armazenamento locais. A razão para sua escalabilidade é a natureza distribuída da sua solução - uma tarefa inicial complexa é dividida em várias menores, e, então, executada em máquinas diferentes. Posteriormente, o resultado é combinado para gerar a solução da tarefa inicial. 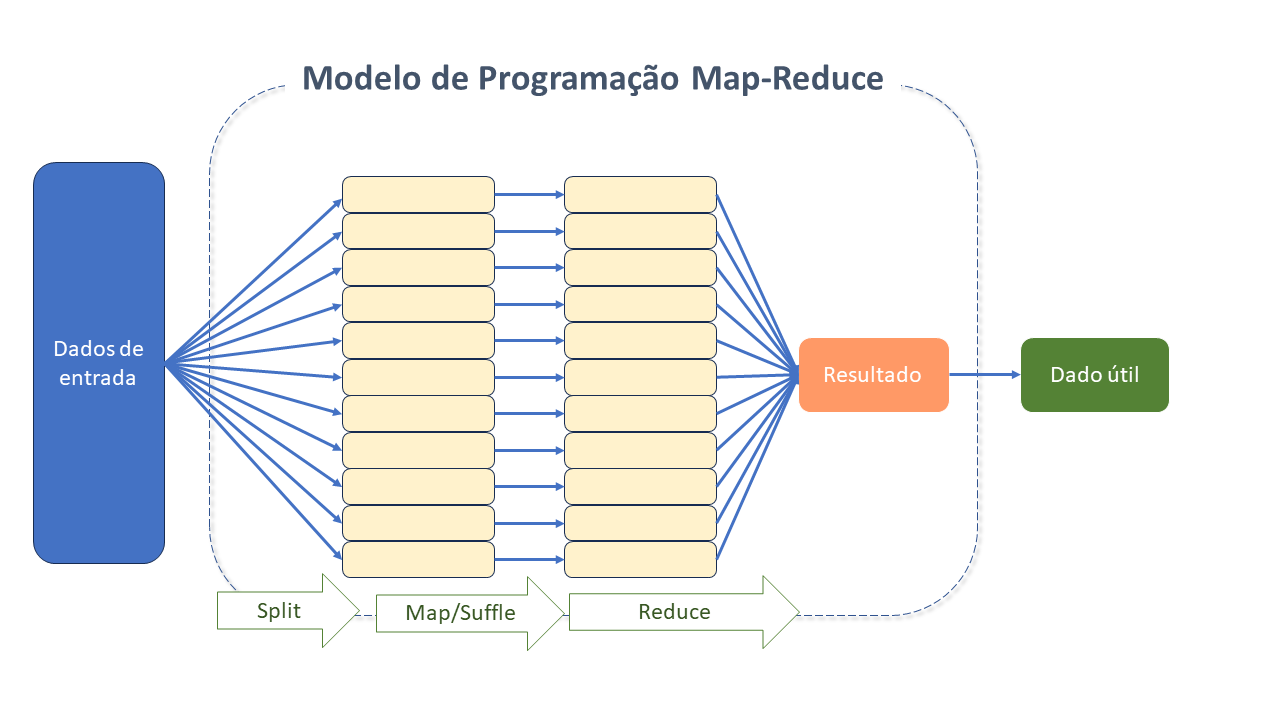
|
O Apache HADOOP surgiu em 2006, a partir de uma solução de busca na Web denominada Nutch Distributed File System(NDFS) que, segundo seus criadores, Doug Cutting e Mike Cafarella, teve sua gênese no documento Google File System, publicado em outubro de 2003.
O Apache Hadoop, bem como seu conjunto de soluções vinculadas, é uma das implementações mais populares e performáticas atualmente utilizadas para solucionar desafios relacionados à coleta, armazenamento e análise de dados, sejam estruturados ou não, estáticos ou tempo real.
Benefícios do Apache HADOOP
-
Escalabilidade: Hadoop obtém escalabilidade de forma relativamente simples por meio de pequenas modificações em arquivos de configuração. O esforço para preparo de um ambiente com mil máquinas não é muito maior do que com 10. As limitações ficam por conta dos recursos, espaço em disco e capacidade de processamento disponíveis.
-
Simplicidade: HADOOP gerencia questões relativas à computação paralela, como tolerância a falhas, escalonamento e balanceamento de carga. Suas operações se resumem a mapeamento (Map) e junção (Reduce), o que o mantém com foco na abstração e processamento de tarefas no modelo de programação MapReduce.
-
Baixo Custo/economia:
-
Como software livre, dispensa aquisição de licenças e contratação de pessoal especializado.
-
Pode realizar processamento de dados em máquinas e redes convencionais.
-
Permite a execução de aplicações "na nuvem", sem a necessidade de implantar seu próprio aglomerado de máquinas.
-
-
Código Aberto: Conta com uma comunidade ativa que envolve muitas empresas e programadores independentes compartilhando conhecimento, promovendo melhorias e colaborando com a sua qualidade. Este trabalho colaborativo promove atualizações e correções mais tempestivas e com maior qualidade, uma vez que a produção individual é avaliada por todos.
-
Alta disponibilidade: O HADOOP não depende de hardware para entregar alta disponibilidade. Suas bibliotecas foram construídas para detectar e lidar com falhas na camada do aplicativo, fornecendo, assim, alta disponibilidade em um Cluster de computadores.
Arquitetura do Apache HADOOP
Os componentes-chave do HADOOP são o MapReduce e o HDFS. Com sua evolução, novos subprojetos foram incorporados, visando solucionar problemas específicos.
Principais componentes do Apache HADOOP
-
Hadoop Common: É o 'pilar" do HADOOP: onde fica armazenado um conjunto predefinido de utilitários e bibliotecas que podem ser usados por outros módulos dentro do Ecossistema HADOOP (arquivos e scripts Java Archive (JAR) ).
-
HDFS É um Sistema de arquivos distribuídos, escalável, projetado para armazenar arquivos muito grandes e fornecer acesso de alta capacidade. Provê acesso com alto "throughput" (taxa de transferência) aos dados de aplicativos.
A ideia que norteia sua solução é garantir escalabilidade e confiabilidade ao processamento paralelo, utilizando o conceito de réplicas e blocos (com tamanho fixo de 64MB, em geral, armazenados em mais de um servidor).
-
HADOOP YARN: Responsável pelo gerenciamento e agendamento dos recursos computacionais do Cluster;
-
HADOOP MapReduce: É uma estrutura de software criada para processar grandes quantidades de dados. Uma excelente solução para processamento paralelo de dados.
Cada tarefa é especificada em termos de funções de mapeamento e redução. Ambas as tarefas rodam em paralelo, no Cluster, enquanto o sistema de armazenamento necessário é fornecido pelo HDFS.
Subprojetos do Apache HADOOP
A necessidade de novas alternativas para promover um processamento mais rápido e eficaz que os SGBD tradicionais aproximou grandes empresas da Plataforma, que, por se tratar de um projeto de código aberto, recebeu grandes estímulos.
Com o surgimento de novas necessidades, novas ferramentas foram criadas para serem executadas sobre o HADOOP. Conforme se consolidavam, passavam a integrá-lo. Foram essas contribuições que colaboraram com a rápida evolução do Apache HADOOP.
Abaixo as principais ferramentas do Ecossistema HADOOP, que compõem a Plataforma Tecnisys Data Platform (TDP):

Evolução do Apache HADOOP
Veja aqui o Timeline - com a evolução do Apache HADOOP
| Ano | Evento |
|---|---|
2003 |
Lançado artigo de pesquisa para o sistema de arquivos do Google |
2004 |
Lançado artigo de pesquisa para MapReduce |
2006 |
JIRA, lista de discussão, e outros documentos criados para HADOOP |
HADOOP criado a partir do NDFS e MapReduce do Nutch |
|
HADOOP criado movendo ndfs e mapreduce de nutch |
|
Doug Cutting nomeou o projeto HADOOP, com o mesmo nome do elefante amarelo de seu filho |
|
HADOOP Release 0.1.0 |
|
37,9 horas para classificar 1.8 TB de dados em 188 nós |
|
300 máquinas implantadas NO YAHOO para o Cluster HADOOP |
|
600 máquinas implantadas no YAHOO para o Cluster HADOOP |
|
2007 |
Dois Clusters de 1000 máquinas no YAHOO |
HADOOP lançado com HBase |
|
Criado o Apache Pig |
|
2008 |
Aberto JIRA para YARN |
20 Companhias listadas na página no "powered" do HADOOP (usuários do HADOOP) |
|
índice da WEB do YAHOO movido para o HADOOP |
|
Cluster do HADOOP de 10.000 "core" usado para gerar o índice de pesquisa do YAHOO |
|
Primeiro encontro HADOOP |
|
Recorde mundial criado para a classificação mais rápida( um Terabyte de dados em 209 segundos) usando Cluster do HADOOP com 910 nós |
|
HADOOP "bate" o recorde "Terabytes sort" |
|
HADOOP "bate" o recorde "Terabytes sort Benchmark" |
|
Cluster YAHOO com 10TB carregados no HADOOP diariamente |
|
Google afirma classificar 1 terabyte em 68 segundos com sua implementação mapreduce |
|
2009 |
24.000 máquinas com 7 clusters "rodando" no YAHOO |
HADOOP "bate" o recorde "sorting pentabyte storage" |
|
YAHOO afirma classificar 1 terabyte em 62 segundos |
|
Segundo Encontro HADOOP |
|
Core HADOOP renomeado para HADOOP Common |
|
Fundada a distribuição MapR |
|
HDFS torna-se subprojeto separado |
|
MapReduce torna-se subprojeto separado |
|
2010 |
Autenticação Kerberos adicionada ao HADOOP |
Versão estável do Apache HBase |
|
YAHOO processa 70 PB em 4.000 nós |
|
Facebook executa 40 Petabytes em 2.300 Clusters |
|
Apache Hive é lançado |
|
Apache Pig é lançado |
|
2011 |
Lançado o Apache Zookeeper |
Contribuição de 200.000 linhas de código do Facebook, Linkedin, eBay e IBM |
|
Media Guardian Innovation concede prêmio máximo para HADOOP |
|
Hortonworks iniciado por Rob Barbadon e Eric Badleschieler, que eram membros principais do HADOOP no yahoo |
|
42.000 nós de Cluster hadoop no YAHOO, processando Petabytes de dados |
|
2012 |
Comunidade HADOOP inicia integração com YARN |
Encontro HADOOP em San Jose |
|
Lançamento do HADOOP 1.0 |
|
2013 |
YARN em produção |
Lançamento do HADOOP 2.2 |
|
2014 |
Apache Spark se torna projeto de primeiro nível |
Lançamento do HADOOP 2.6 |
|
2015 |
Lançamento do HADOOP 2.7 |
2016 |
Lançamento do HADOOP 2.8 |
2017 |
Lançamento do HADOOP 3.0 |
2018 |
Lançamento do HADOOP 3.1.0 |
2019 |
Lançamento do HADOOP 3.2.0 |
2022 |
Lançamento do HADOOP 3.2.3 |
Configurações e Uso
Diretrizes de Compatibilidade
O Futuro do Apache HADOOP
Em abril de 2021, a Apache Software Foundation anunciou a retirada de 13 projetos relacionados a BigData, dez dos quais faziam parte do Ecossistema Hadoop (Eagle, Sentry, Tajo, etc.).
Esta ação levantou questões sobre o futuro do Apache Hadoop. Entretanto, a Plataforma possui um número representativo de grandes usuários, que continuam a utilizá-lo.
Segundo o Google Trends, o Apache HADOOP atingiu seu pico de popularidade entre 2014 e 2017 e, como em todo ciclo tecnológico, sua popularidade pode sim, entrar em declínio gradualmente em favor de outras ferramentas emergentes. Entretanto, a tecnologia continua progredindo e sua última versão foi lançada em março de 2023.