Apache Superset
Visualização
A visualização de dados consiste na representação gráfica de informações e dados. Por meio de elementos visuais, pode-se facilmente contar a história sobre um dado específico, compilando-o em um formato mais compreensível, destacando tendências e exceções, eliminando elementos irrelevantes e levando a novos "insights".
Com o advento do "Big Data", tornou-se uma ferramenta incrivelmente relevante para interpretar e entender o volume de dados gerados diariamente.
Existem diversas ferramentas para visualização de dados, dentre elas, o Apache Superset, uma ferramenta simples, fácil de usar, que oferece uma gama de opções para todos os níveis de habilidade.
É uma das melhores ferramentas de exploração de dados e aprendizado de máquina. Além disso, oferece uma interface de usuário muito amigável a um custo muito mais barato.
Características do Apache Superset
Construído sobre tecnologias populares de código aberto, como o JDBC(que fornece a conexão para consultas SQL com recursos analíticos) e o H2O (que permite a exploração de dados por meio de modelos preditivos e visualizações interativas) seus recursos principais viabilizam a visualização, exploração e análise de dados.
Apache Superset é um aplicativo web de inteligência de negócios (BI). É rápido, leve, intuitivo e repleto de opções que facilitam a exploração e visualização de dados por usuários com qualquer conjunto de habilidades, desde gráficos de pizza simples até gráficos geoespaciais altamente detalhados.
Foi criado por Maxime Beauchemin, Engenheiro de dados, CEO e fundador da PRESET, que usou um hackathon interno do Airbnb(evento que reúne programadores, designers e outros profissionais ligados ao desenvolvimento de software para uma maratona de programação) para criar uma ferramentade BI a partir do zero.
O projeto, denominado "Caravel" inicialmente, tornou-se o Apache Superset. Rapidamente adotado por dezenas de empresas, assumiu cada vez mais casos de uso. Foi estabelecido como projeto de código aberto completo e incubado com a Apache Software Foundation em 2016. Hoje, é a principal plataforma analítica de código aberto, com uma das comunidades de crescimento mais rápido do GitHub.
Dentre suas principais características podemos citar:
-
Interface Intuitiva: Possibilitando a visualização de conjuntos de dados e criação de painéis interativos.
-
SQL IDE: Possibilitando o preparo de dados para visualização, incluindo um rico navegador de metadados.
-
Segurança: É uma das suas principais vantagens, pois oferece controle total sobre o acesso a dados. Permite a adição de usuários ao Banco de Dados, o fornecimento de acesso e o rastreamento de comportamentos.
-
Camada Semântica Leve: Capacitando analistas de dados a definir rapidamente dimensões e métricas personalizados.
-
Suporte à maioria dos Bancos de Dados que "falam" SQL.
-
Cache e consultas assíncronas "in memory".
-
Modelo de Segurança extensível: Com controle total de acesso ao dado, permitindo a configuração de regras complexas sobre quem pode acessar quais recursos e conjuntos de dados do produto.
-
Integração com os principais backends de autenticação: Como OpenID, LDAP, OAuth, Remote_user, etc.
-
Capacidade de adicionar plug-ins de visualização personalizados.
-
API para customização programática.
-
Arquitetura Cloud Native
-
Desenhada para Alta Disponibilidade e _Escala para ambientes grandes e distribuídos.
-
Flexível na escolha de:
-
Web Server (Gunicorn, Nginx, Apache),
-
Database para Metadados (MySQL, PostGres, MariaDB, etc),
-
Fila de mensagens (Redis, RabbitMQ, SQS, etc),
-
Backend de Resultados (S3, Redis, Memcached, etc),
-
Camada de Cache (Memcached, Redis, etc.)
-
-
-
Trabalha muito bem dentro de Containers.
-
Permite a criação de Queries Interativas: Com seleção de database, tabelas e schema.
-
Não exige conhecimento de código: É desenhado para pessoas que não conhecem código, como analistas de negócio e financeiros.
-
Acessível por Web e aplicativo: Que operam de modo independente.
Arquitetura do Apache Superset
O Apache Superset baseia-se na metodologia Dataset-Centric (arquitetura centrada em consultas e em semântica). Esta arquitetura promove o uso de conjuntos de dados semelhantes a um Dataframe, ou seja, uma esrutura tabular enriquecida que contém um subconjunto de características semânticas.
O Apache Superset pode ser executado no modo sequencial ou distribuído. No modo sequencial, apenas executa consultas com duração inferior a 60 segundos. No modo distribuído, o superset distribui as consultas entre workers.
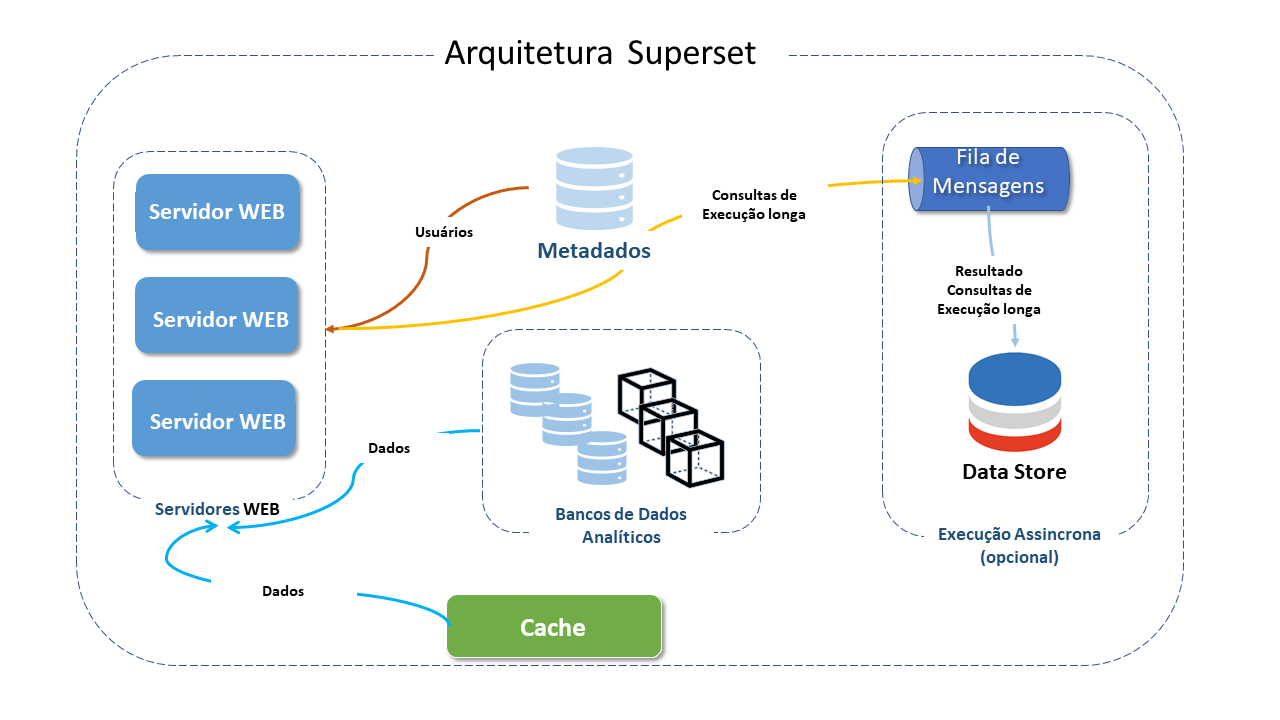
Os principais componentes envolvidos na solução do Apache Superset são:
-
Web Servers(Servidores Web): Aplicativo flask python usado para conectar-se a qualquer banco de dados. O Superset permite a escolha do Web Server e integra-se com várias opções, como Gunicorn, NGINX, Apache HTTP. Os web servers Superset e os workers Superset Celery (opcional) podem expandir-se para quantos servidores quanto forem necessários.
-
Metadata database (Database de Metadados): O Superset permite a escolha do mecanismo de banco de dados de metadados e integra-se com várias opções, como MySQL, Postgres, MariaDB, etc).
-
Cache layter Camada Cache: O Superset permite a escolha da camada de cache e integra-se com várias opções como Memcached, Redis, etc.
-
Message queue for async queries (Fila de mensagens para consultas assíncronas): O Superset permite a escolha da fila de mensagens e integra-se com várias opções como S3, Redis, Memcached, etc.
-
Results Backend (Backend de Resultados):
-
Dashboard e Slices O Dashboard é uma interface do usuário que permite a visualização de vários gráficos e dados. Cada seção dentro do Dashboard é chamada Slice, que, por sua vez, podem estar em diversos formatos: texto, gráfico, ou, por exemplo, uma função.
-
SQL Lab SQL Lab é um IDE SQL com uma ampla gama de recursos, com o qual é possível converter dados em gráficos, por exemplo.
Superset funciona muito bem com serviços de métricas e estatísticas como NewRelic , StatsD, DataDog e tem capacidade de executar cargas de trabalho analíticas nas tecnologias de Banco de Dados mais populares.
Atualmente, é executado em escala em muitas empresas, como, por exemplo, no ambiente de produção do Airbnb, onde, dentro de kubernetes, atende mais de 600 usuários ativos diários que visualizam mais de 100 mil gráficos por dia.
Os principais setores e empresas que adotam o Superset podem ser vistos aqui.
Recursos do Apache Superset
O Superset dispõe de vários recursos, entre eles:
-
Visualizações personalizadas.
-
Consultas SQL na Guia SQL para investigação de dados.
-
Construção de visualização sem código, ou o SQL IDE para integração e análise de dados rápidas.
-
Ingestão de dados leve e escalável que funciona na infraestrutura de dados existente, sem demandar uma camada de ingestão separada.
-
Camada semântica básica, onde é possível controlar como as fontes de dados são exibidas e tratadas.
Integração com Databases
Superset provê funcionalidades para conexão com vários databases. Conecta-se com quase todos os principais bancos de dados, o que facilita a visualização e análise de seus dados. É compatível com Apache Spark SQL, PostgreSQL , GoogleSheets, Amazon Athena, Amazon Redshift, Azure MS SQL, etc.
Tipos de Visualização
O Apache Superset fornece uma ampla varidade de graficos, tabelas e layouts. Alguns exemplos são:
-
Gráfico de Dispersão.
-
Grids.
-
Polígonos.
-
Path.
-
Screen Grids.
-
Acrs
Linguagem do Apache Superset
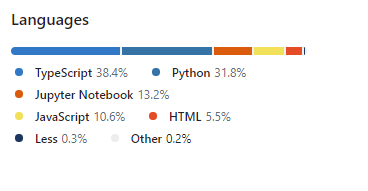
Apache superset é quase inteiramente construído sobre Python, usando Typescript, e flask app builder internamente. Suporta python version > 3.6 e pode ser instalado em uma variedade de métodos. Os mais comuns são:
-
localmente: onde o Python deve ser instalado primeiro e então o pip instala as dependências.
-
virtualmente: É fortemente recomendada a instalação em um ambiente virtual. O pyenv-virtualenv pode ser instalado se o pyenv estiver sendo usado.
-
Docker: O meio mais simples de experimentar o Superset localmente é usando o Docker e o Docker Compose em Linux ou Mac OSX.
Fontes: