Delta Lake
Estrutura de Armazenamento
Nas arquiteturas modernas de dados, a camada de armazenamento é a base que permite guardar grandes volumes de dados de forma escalável e económica. Utiliza sistemas como Amazon S3, Azure Data Lake Storage ou HDFS para armazenar ficheiros em formatos como Parquet, ORC ou Avro. Contudo, esta camada não impõe estrutura, controlo de versão, validação de esquema ou transações — apenas armazena dados.
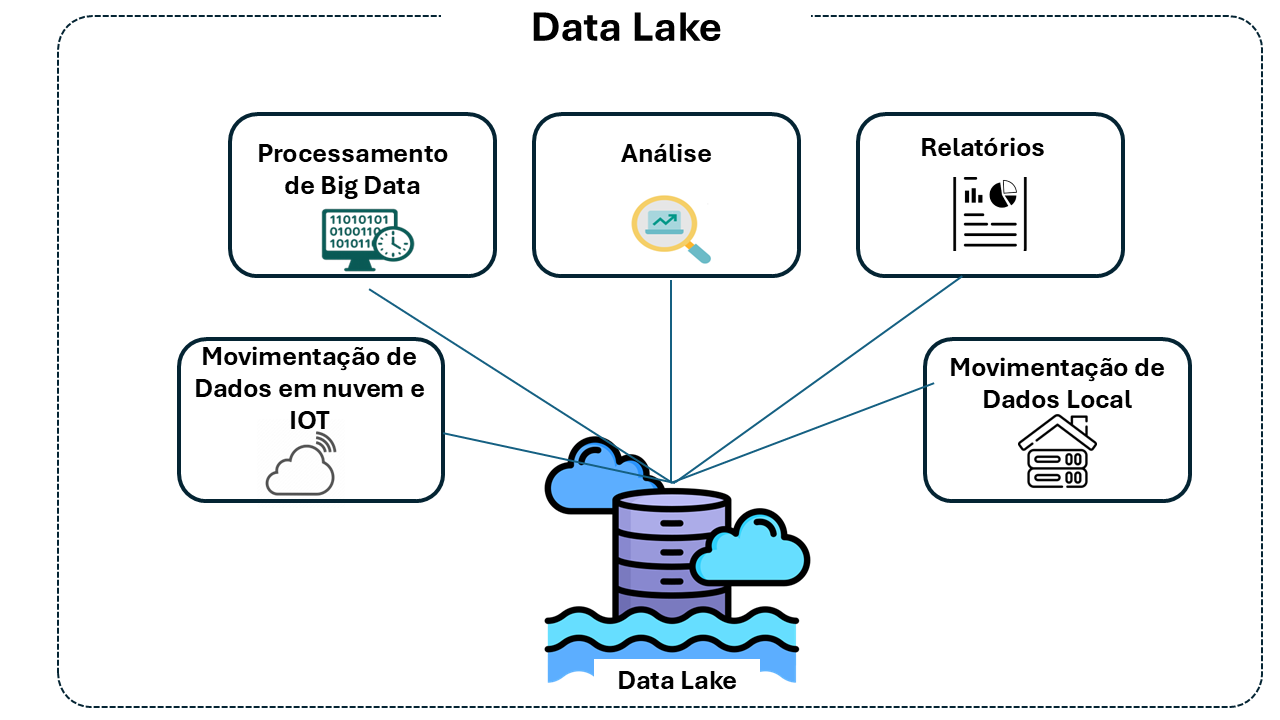
Sobre esta base, surgiu o conceito de Data Lake: uma arquitetura concebida para armazenar dados brutos em larga escala, provenientes de múltiplas fontes e em diferentes formatos. A promessa dos data lakes foi centralizar tudo num único local — facilitando análises futuras, integrando dados variados e reduzindo custos. Tornaram-se populares em projetos de ciência de dados e pipelines de ingestão massiva.
Porque os Data Lakes se Tornaram Populares
Mesmo com limitações técnicas, os data lakes tornaram-se populares pela sua flexibilidade e economia. Permitem:
- Armazenar os dados no seu formato original, sem necessidade de modelação prévia.
- Capturar dados em batch e em tempo real, com escalabilidade praticamente ilimitada.
- Servir múltiplos perfis e ferramentas de utilizador, suportando análise ad hoc, machine learning, relatórios e dashboards.
- Consolidar e democratizar o acesso a dados, quebrando silos de sistemas legados.
Limitações dos Data Lakes
Apesar das vantagens, os data lakes tradicionais não oferecem os controlos necessários para ambientes analíticos fiáveis:
- Sem transações ACID: múltiplas escritas podem gerar inconsistência ou corrupção.
- Sem controlo de versões dos dados: não é possível consultar ou restaurar um estado anterior da tabela.
- Sem validação de consistência de esquemas: erros estruturais podem passar despercebidos, comprometendo as análises.
- Sem otimizações de desempenho para consultas: ficheiros pequenos e desorganizados afetam o tempo de resposta.
Estas limitações impedem os data lakes de serem uma base confiável para aplicações analíticas críticas. Para ultrapassar estas deficiências, foi criada uma nova camada — o Delta Lake.
O que é o Delta Lake
O Delta Lake é uma camada transacional que atua sobre um data lake existente. Não substitui o data lake — complementa-o. Ao adicionar transações ACID, controlo de versões, gestão de esquemas e integração com ferramentas como Apache Spark, o Delta Lake transforma os data lakes brutos numa plataforma mais robusta, fiável e auditável — conhecida como Lakehouse1.
Funcionalidades do Delta Lake
O Delta Lake introduz funcionalidades essenciais que resolvem as falhas dos data lakes tradicionais e permitem uma arquitetura de dados escalável e fiável. Entre os principais destaques estão:
-
Transações ACID: garantem atomicidade, consistência, isolamento e durabilidade mesmo em ambientes distribuídos. Leituras e escritas são seguras e previsíveis.
-
Controlo de Versões e Time Travel: todas as alterações são automaticamente versionadas, permitindo consultas a estados anteriores, rollback e auditorias históricas.
-
Gestão e Validação de Esquemas: evita a ingestão de dados com estruturas incorretas. O esquema pode evoluir de forma controlada sem comprometer a integridade da tabela.
-
Unificação de Batch e Streaming: a mesma tabela Delta pode receber dados batch e streaming, garantindo consistência entre os modos de ingestão.
-
Desempenho Otimizado para Consultas: técnicas como compactação de ficheiros pequenos, ordenação por colunas (Z-order) e data skipping aceleram significativamente as consultas.
-
Integração com o Ecossistema Spark: permite operações SQL, APIs estruturadas e processamento em tempo real diretamente sobre tabelas Delta.
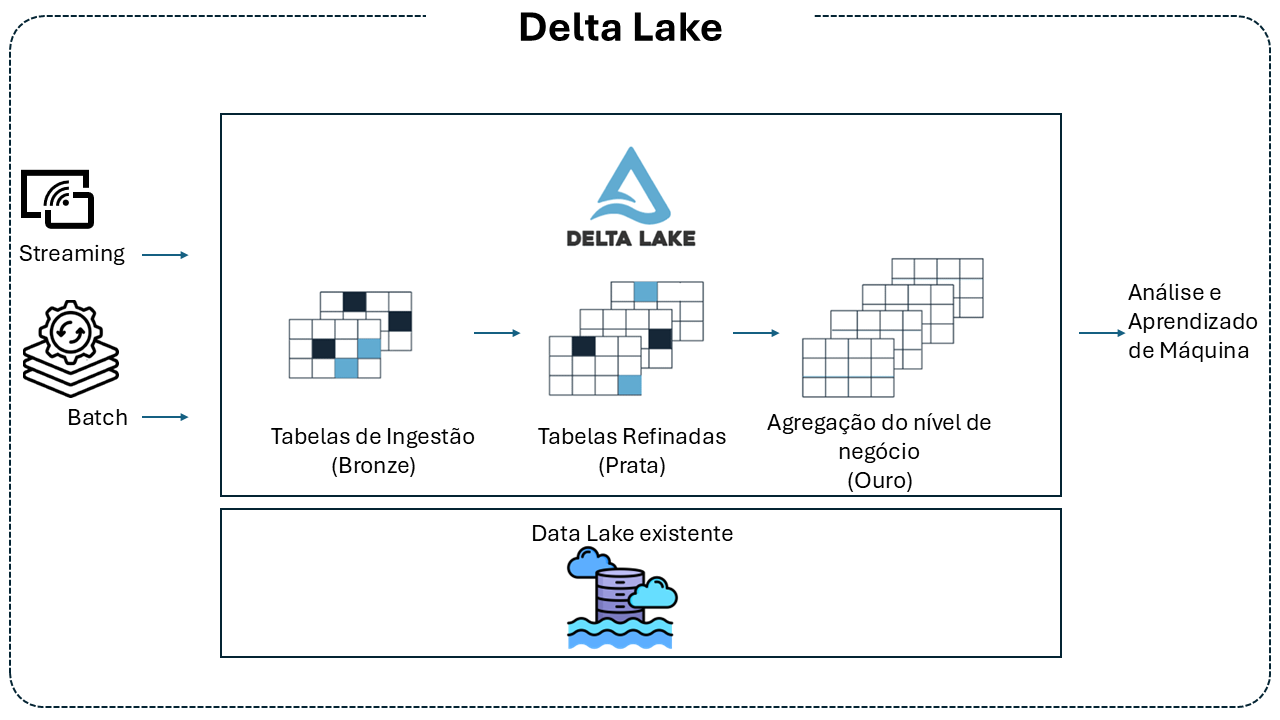
Arquitetura do Delta Lake
A arquitetura do Delta Lake apoia-se no data lake tradicional, introduzindo uma camada transacional que garante fiabilidade e desempenho. Esta camada é composta por três elementos principais:
-
Camada de Armazenamento: utiliza o mesmo repositório do data lake, como Amazon S3, Azure Data Lake Storage ou HDFS, onde os dados são armazenados em formato Parquet. Esta camada física continua a oferecer escalabilidade e economia.
-
Delta Log: um log de transações que regista todas as alterações efetuadas nas tabelas. Este log possibilita o controlo de versões, garantindo que cada modificação seja rastreada e permitindo funcionalidades de time travel e auditoria.
-
Tabelas Delta: são a abstração lógica que une os dados armazenados e o Delta Log. Através desta integração, as tabelas Delta oferecem transações ACID, gestão e evolução de esquemas, além da unificação de ingestão batch e streaming.
Como Funciona o Delta Lake
O Delta Lake atua continuamente sobre o armazenamento físico, gerindo alterações de dados e garantindo transações seguras e rastreáveis. O seu funcionamento organiza-se em três áreas principais:
Ingestão de Dados
O Delta Lake suporta múltiplos modos de ingestão:
-
Streaming: integra-se com o Apache Spark Structured Streaming para ingestão contínua, permitindo atualizações em tempo real com semântica exactly-once.
-
Batch: suporta ingestão em grande escala com operações como
MERGE,UPDATE,DELETEeINSERT, sem comprometer a integridade das tabelas.
Processamento de Consultas
As tabelas Delta podem ser consultadas através de:
- SQL: para consultas interativas ou analíticas diretamente sobre dados versionados.
- APIs de alto nível: compatíveis com as APIs do Apache Spark (DataFrame, SQL, Structured Streaming).
- Time Travel: é possível navegar no Delta Log e consultar o estado dos dados em qualquer ponto no tempo.
Gestão de Dados
O Delta Lake oferece mecanismos de otimização contínua:
- Compactação de Ficheiros Pequenos: operações como
OPTIMIZEreorganizam os dados para melhorar o desempenho das consultas. - Ordenação Z-order: organiza os dados por colunas de alta seletividade, reduzindo custos de leitura.
- Limpeza de Dados Obsoletos: com
VACUUM, ficheiros não referenciados são removidos com segurança, libertando espaço e mantendo o desempenho.
Estas funcionalidades trabalham de forma integrada, mantendo a integridade dos dados mesmo sob alta concorrência ou ingestão contínua.
Capacidades do Delta Lake
- Transações ACID com Spark: níveis de isolamento serializáveis garantem que os leitores nunca vejam dados inconsistentes.
- Gestão Escalável de Metadados: utiliza o processamento distribuído do Spark para gerir metadados de tabelas com petabytes de dados e biliões de ficheiros.
- Unificação de Streaming e Batch: uma tabela Delta é simultaneamente uma tabela batch e uma fonte/sumidouro de streaming. Ingestão contínua, backfill batch e consultas interativas funcionam de forma integrada.
- Validação de Esquema: lida automaticamente com variações de esquema para evitar inserção de registos inválidos durante a ingestão.
- Time Travel: versionamento de dados permite rollback, auditoria histórica completa e experiências de machine learning reproduzíveis.
- Upserts e Deletes: suporta operações de
merge,updateedelete, ideais para cenários como change data capture, slowly changing dimensions (SCD) e upserts em streaming. - Ecossistema de Conectores: estão disponíveis conectores para ler e escrever em tabelas Delta a partir de engines como Apache Spark, Flink, Hive, Trino, AWS Athena, entre outros.
Quando Utilizar Delta Lake
O Delta Lake é indicado para cenários que requerem:
- Dados em vários formatos provenientes de diversas fontes;
- Utilização dos dados em várias tarefas posteriores distintas, como análise, ciência de dados, aprendizagem automática, etc.;
- Flexibilidade para executar diversos tipos de consultas sem a necessidade de formular as perguntas antecipadamente;
- Processamento de Dados em Tempo Real: ingestão e análise em tempo real com garantias de consistência.
- Gestão de Grandes Volumes de Dados: suporta petabytes de dados com desempenho otimizado.
- Necessidade de Auditoria e Versionamento: acesso a versões anteriores dos dados para auditoria e recuperação.
Quando Delta Lake Pode Não Ser a Melhor Escolha
O Delta Lake pode não ser a melhor opção para:
- Sistemas OLTP de Alta Concorrência: aplicações que requerem transações de baixa latência e alta concorrência podem beneficiar mais de bases de dados relacionais tradicionais.
- Necessidade de Suporte a Constraints Complexas: como chaves estrangeiras e triggers, que não são suportadas nativamente pelo Delta Lake.
Interação com Apache Spark
O Delta Lake é totalmente compatível com as APIs do Apache Spark e foi concebido para integração completa com o Structured Streaming, permitindo operações unificadas sobre dados batch e streaming e suportando processamento incremental escalável. Permite:
- Ingestão e Processamento em Tempo Real: com Spark Structured Streaming.
- Consultas SQL e Operações DML: com suporte a transações ACID.
- Otimizações de Desempenho: tirando partido das capacidades de processamento distribuído do Spark.
Diferenças Entre Delta Lake e RDBMS Tradicionais
- Armazenamento: o Delta Lake usa ficheiros Parquet em sistemas de ficheiros distribuídos, enquanto os RDBMS usam blocos de armazenamento.
- Transações: o Delta Lake fornece transações ACID em ambientes distribuídos; os RDBMS em sistemas centralizados.
- Evolução de Esquema: o Delta Lake permite evoluções flexíveis, enquanto os RDBMS exigem alterações estruturais mais rígidas.
Boas Práticas com Delta Lake
- Compactação de Ficheiros: usar o comando
OPTIMIZEpara melhorar o desempenho. - Ordenação Z-order: aplicar em colunas frequentemente filtradas.
- Gestão de Versões: usar time travel para auditorias e recuperação de dados.
Detalhes do Projeto Delta Lake
- Linguagem de Programação: desenvolvido em Scala e Java.
- Licença: código aberto sob licença Apache 2.0.
- Integração: compatível com Apache Spark, Flink, Presto, Trino, entre outros.
TDP Kubernetes
Este componente também está disponível na edição TDP Kubernetes desde a versão 3.0.
A versão actual é 4.0.1, distribuída pelo Helm Chart tdp-deltalake v3.0.1.
Para detalhes de configuração, consulte a documentação no TDP Kubernetes.
Fontes
Footnotes
-
A arquitetura lakehouse combina as vantagens dos data lakes e dos data warehouses numa única plataforma. Usa o armazenamento económico e escalável de um data lake, oferece transações ACID, versionamento, validação de esquema e catálogos como num data warehouse, suportando processamento batch e streaming num mesmo local, além de permitir SQL e machine learning sobre os mesmos dados. ↩