Banco de Dados
Modelos de Banco de Dados
Relacional
Fundamentado por E.F. Codd (1970), cuja proposta envolve uma abordagem intuitiva e direta para representar dados, o modelo relacional permite a representação eficaz de relacionamentos entre os dados, facilitando consultas complexas e garantindo a integridade dos dados.
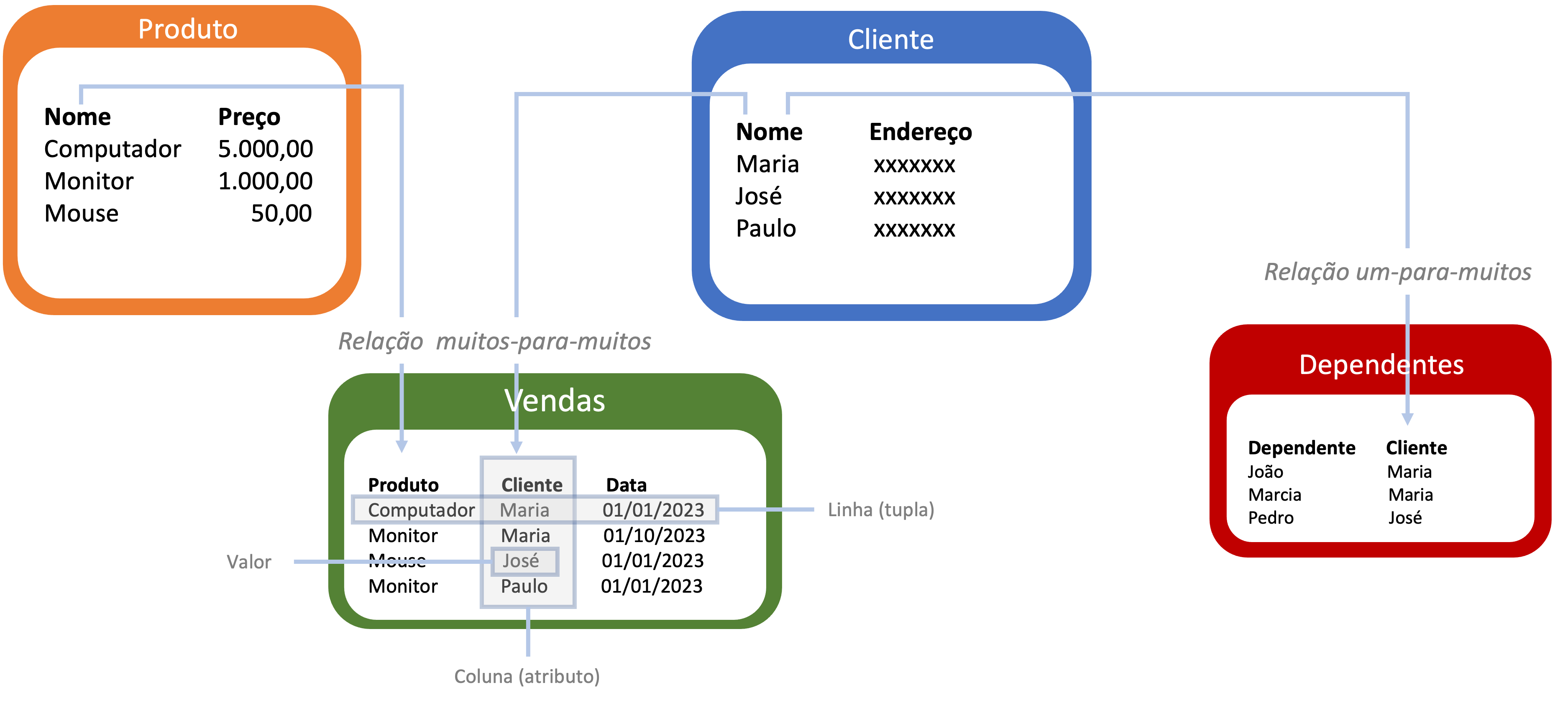
No modelo relacional os dados são organizados em tabelas (entidades e relações), compostas de colunas e linhas (tuplas), com valores de identificação únicos para cada linha (chaves primárias). Cada linha da tabela tem o mesmo conjunto de colunas nomeadas e cada coluna possui um tipo de dado específico. As chaves que identificam as linhas são usadas para definir os relacionamentos entre as tabelas.
As tabelas em modelos relacionais possuem relacionamentos entre si de um para um, um para muitos e muitos para muitos. Geralmente, um relacionamento de muitos para muitos é implementado com uma tabela adicional (tabela de associação), contendo as chaves primárias das tabelas envolvidas no relacionamento.
Entre os Sistemas de Gerenciamento de Banco de Dados Relacionais (SGBDR) mais conhecidos estão o PostgreSQL, Oracle, MySQL, Microsoft SQL Server, IBM DB2 e o SQLite.
Orientado a Objetos
Em um modelo orientado a objetos os dados são representados como objetos, seguindo os princípios da programação orientada a objetos. Esta abordagem encapsula dados e comportamentos em entidades, promovendo a modularidade e a reusabilidade.
Um objeto é uma instância de uma classe (entidade), a qual atributos (dados), métodos (ações) e associações (relacionamentos entre as classes).
Exemplos incluem CACHE, ZOPE e GemStone.
Objeto-Relacional
O modelo objeto-relacional, ou modelo relacional estendido, combina características do modelos relacional e orientados a objetos. Mantendo a eficiência dos dados em tabelas que se relacionam, esses modelos incorporam funcionalidades de orientação a objetos, como herança e tipos personalizados.
PostgreSQL
O PostgreSQL, componente principal do PostgreSYS, é um SGBD de código aberto amplamente reconhecido pela sua robustez e versatilidade. Surgiu a partir do projeto Postgres, desenvolvido pelo Departamento de Ciência da Computação da Universidade da Califórnia, e evoluiu para suportar uma gama ampla de funcionalidades, incluindo:
-
Conformidade com SQL e Recursos Avançados: o PostgreSQL não só cumpre com a maior parte do padrão SQL, mas também oferece recursos avançados para consultas complexas, chaves estrangeiras, transações, views, triggers, e procedimentos armazenados. Isso torna o PostgreSQL extremamente flexível e poderoso para diversos casos de uso.
-
Extensibilidade e Suporte a Tipos de Dados Personalizados: Uma das características notáveis do PostgreSQL é a sua extensibilidade. Os usuários podem definir seus próprios tipos de dados, índices personalizados, e até escrever funções em diferentes linguagens de programação. Essa extensibilidade permite que ele seja adaptado para atender às necessidades específicas de quase qualquer aplicativo de banco de dados.
-
Robustez e Confiabilidade: O PostgreSQL é conhecido por sua alta estabilidade e confiabilidade. Ele possui recursos como a capacidade de lidar com grandes volumes de dados, um sistema de transação ACID (Atomicidade, Consistência, Isolamento, Durabilidade) robusto, e um forte mecanismo de recuperação após falhas. Essas características fazem dele uma escolha confiável para sistemas críticos.
-
Segurança e Conformidade: O PostgreSQL oferece uma excelente segurança de dados. Ele suporta autenticação forte, controle de acesso granular, encriptação de dados em repouso e em trânsito, e muitas outras funcionalidades de segurança. Isso torna o PostgreSQL adequado para aplicações onde a segurança dos dados é uma grande preocupação.
-
Liberdade Tecnológica: PostgreSQL é um software de código aberto distribuído sob a PostgreSQL License, uma licença de software livre. Essa licença é semelhante à licença MIT em termos de permissividade. Ela permite a liberdade de usar, modificar, distribuir e estudar o software sem preocupações sobre o pagamento de licenças ou restrições de uso impostas pelo fornecedor. Esta característica torna o PostgreSQL particularmente atraente para empresas e desenvolvedores que desejam um sistema de gerenciamento de banco de dados poderoso sem os custos de licenciamento associados a muitos outros produtos de banco de dados. A natureza livre da licença também estimula uma comunidade vibrante e ativa, que contribui constantemente para a evolução e melhoria do PostgreSQL.
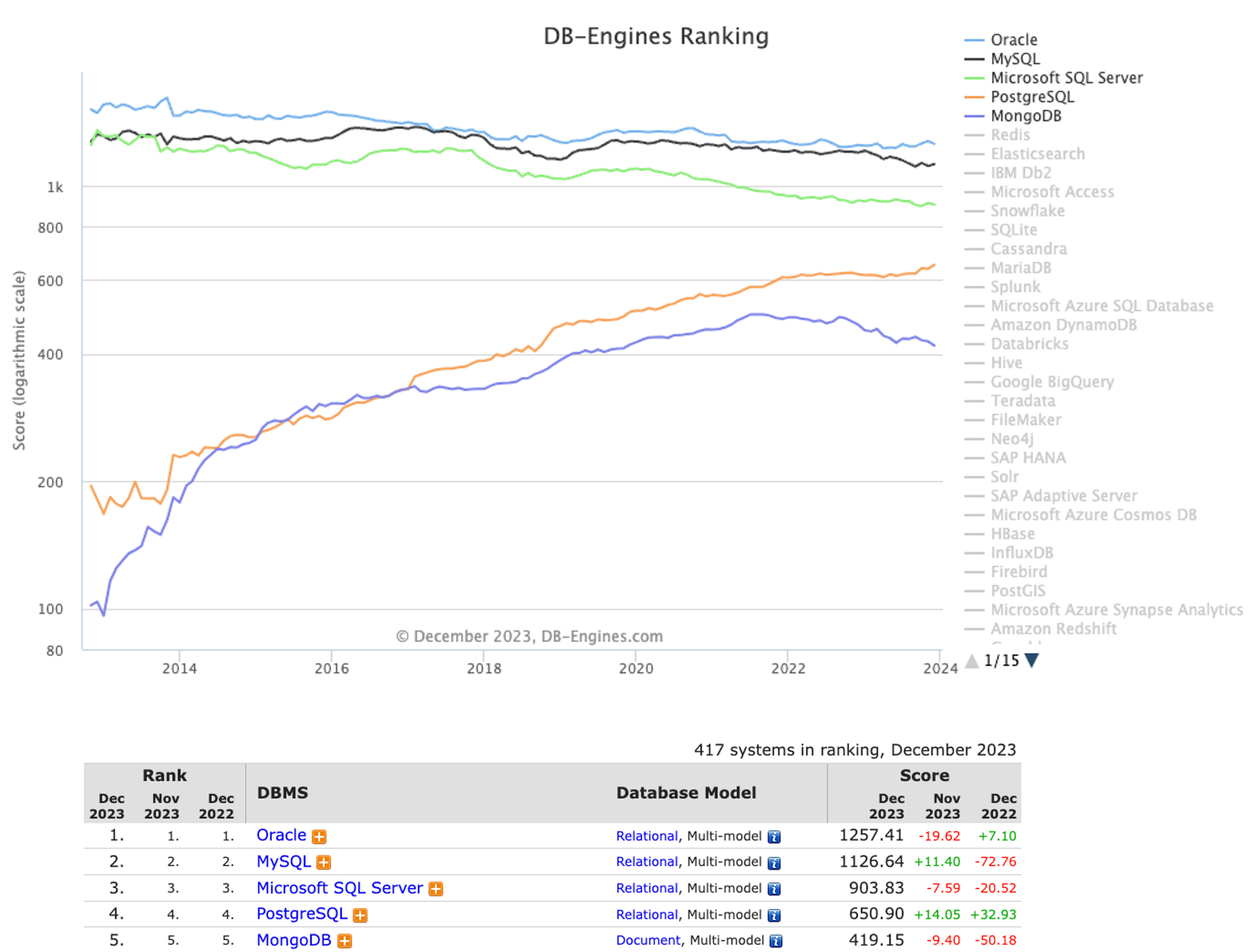
Com mais de 30 anos de desenvolvimento e evolução contínua, o PostgreSQL é adotado por diversos setores do mundo inteiro e considerado a escolha certa para ambientes de bancos de dados que exigem grande confiabilidade, robustez e desempenho.
De acordo com o site db-engines.com, em dezembro de 2023 o PostgreSQL era o segundo SGBD de código aberto mais utilizado do mundo e o quarto mais popular.
Arquitetura
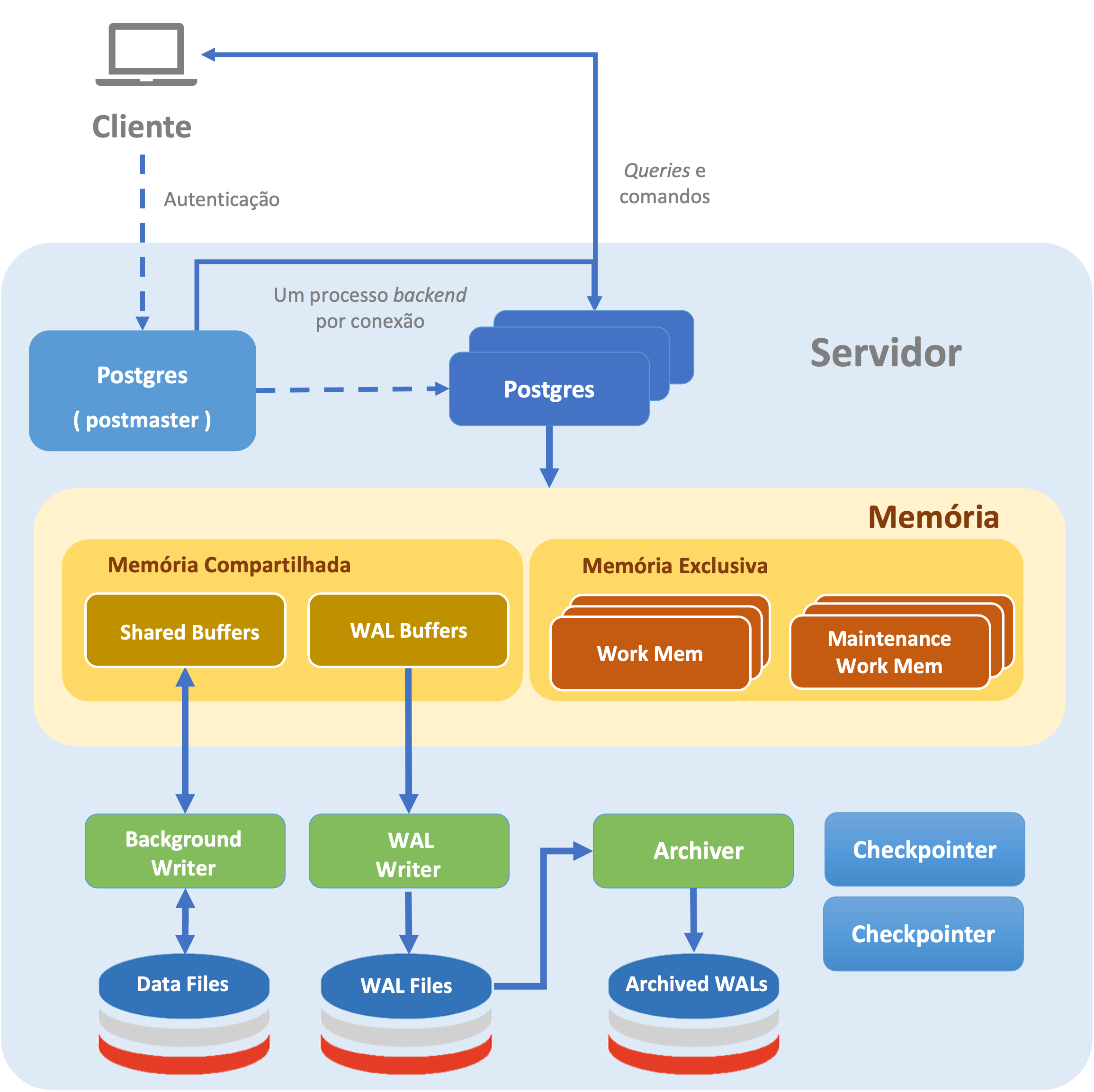
Nesta seção exploramos os principais conceitos presentes na arquitetura do PostgreSQL, ilustrada na imagem a seguir.
-
Cliente: Representa sistemas e aplicações que se conectam no banco de dados para executar operações, como interfaces de linha de comando, aplicações web, ferramentas de monitoramento, e etc.
-
Servidor: Representa a instância de banco de dados PostgreSQL, contemplando processos, áreas de memória, diretórios e arquivos.
Processos
-
Postgres: O Postgres, ou postmaster, é o principal processo do serviço da instância PostgreSQL. Iniciado em foreground ao iniciarmos o cluster, é responsável por gerenciar os processos utilitários e por escutar as solicitações de conexão dos clientes, criando um novo processo de backend para cada conexão.
-
WAL Writer: O WAL Writer é um processo em background que escreve periodicamente registros do WAL da memória para o disco. Esse processo é essencial para garantir a durabilidade das transações e ajudar na eficiência do sistema, reduzindo a carga de I/O durante as operações de checkpoint. Ele assegura que os dados críticos sejam salvos continuamente.
-
Archiver: O Archiver é um processo em background responsável por arquivar os WAL para um local seguro. Isso é crucial para a recuperação de desastres e replicação. O Archiver é ativado quando o WAL chega ao fim de um segmento e precisa ser armazenado de forma persistente.
-
WAL Sender: O WAL Sender é um processo em background dedicado à replicação. Ele é responsável por enviar registros do WAL para os servidores de réplica em um ambiente de replicação assíncrona ou síncrona. Este processo é crucial para garantir a consistência de dados e a alta disponibilidade em configurações de banco de dados distribuídos.
-
WAL Receiver: O WAL Receiver é um processo em background executado em servidores de réplica. Ele recebe registros do WAL enviados pelo processo WAL Sender do servidor primário. Esse processo é essencial para manter a réplica atualizada, aplicando as alterações do banco de dados primário ao secundário em configurações de replicação síncrona ou assíncrona.
-
Background Worker (BgWorker): O Background Worker é um processo projetado para executar diversas tarefas em background. Ele é essencial para a execução de módulos externos, permitindo a extensão de funcionalidades do banco de dados. Além disso, é um componente chave para o paralelismo de consultas, possibilitando uma melhora significativa no desempenho do ambiente ao distribuir o processamento de consultas complexas em múltiplos núcleos ou processadores.
-
Background Writer (BgWriter): O Background Writer é um processo em background responsável por escrever gradualmente as páginas de memória modificadas (dirty pages) para o disco. Esta ação é fundamental para distribuir a carga de I/O ao longo do tempo, melhorando a performance durante os checkpoints e garantindo a integridade e a segurança dos dados, reduzindo o risco de perda em caso de falhas do sistema.
-
Checkpointer: O Checkpointer é um processo em background responsável pela gestão de checkpoints, ou seja, pontos consistentes de sincronização da instância de banco de dados no disco. Durante um checkpoint, as páginas de dados modificadas (dirty pages) são escritas no disco, assim como os WALs, e o arquivo pg_control é atualizado para refletir o novo estado consistente. Isso assegura a integridade dos dados, a durabilidade das transações e permite a recuperação da instância de banco de dados em caso de falha.
-
Autovacuum: O Autovacuum é um processo essencial para recuperar o espaço ocupado por tuplas obsoletas nos arquivos de dados das tabelas, resultantes de operações de atualização e exclusão. O autovacuum trabalha continuamente em background, monitorando as tabelas para identificar a necessidade de manutenção e executando-a de forma proativa para prevenir a degradação do desempenho.
-
Statistics Collector: O Statistics Collector é responsável pela coleta de dados estatísticos da atividade da instância de banco de dados, como o número de acessos a tabelas e índices, operações de modificação de dados e informações sobre o uso de recursos do sistema. Essas estatísticas são cruciais para o desempenho de consultas, pois permitem que o otimizador de consultas avalie as estratégias de execução mais eficientes baseando-se no comportamento atual das consultas e na distribuição dos dados. Este processo opera em background e é acessado através de views do sistema, fornecendo aos administradores de banco de dados informações valiosas para ajustes e monitoramento do ambiente.
Memória
-
Shared Memory: A Shared Memory, ou memória compartilhada, é uma área de memória reservada para todos os processos da instância PostgreSQL. Essa memória é utilizada para armazenar estruturas de dados cruciais para a operação do sistema, como buffers de dados, informações de controle de transações, locks e caches de metadados.
-
Shared Buffers: Área da memória compartilhada utilizada para armazenar páginas de tabelas e índices lidos do disco. Este cache é compartilhado entre os processos do servidor, permitindo que as consultas acessem rapidamente os dados já carregados para a memória.
-
WAL Buffers: Área da memória compartilhada utilizada para armazenar temporariamente os registros de WAL (Write-Ahead Logging) antes de serem escritos no disco.
-
-
Process Memory ou Backend Memory: Área de memória exclusiva para processos de backend, sejam eles conexões de clientes ou processos utilitários. A quantidade de memória alocada para cada processo é determinada por parâmetros de configuração do servidor.
-
work_mem: Parâmetro de configuração do servidor que determina a quantidade de memória a ser utilizada por operações internas de ordenação (ORDER BY, DISTINCT, MERGE JOINS) e hash antes de recorrer a arquivos temporários em disco (spill).
-
temp_buffers: Parâmetro de configuração do servidor que limita o tamanho de buffers temporários, por sessões, usados para tabelas temporárias.
-
maintenance_work_mem: Parâmetro de configuração do servidor que limita a quantidade de memória para operações de manutenção da instância de banco de dados, como VACUUM, INDEX REBUILD e ALTER TABLE.
-
autovacuum_work_mem: Parâmetro de configuração do servidor que especifica exclusivamente a quantidade de memória utilizada por cada processo do autovacuum.
-